PostgreSQL Vacuum에 대한 거의 모든 것
시작하며
PostgreSQL에는 다른 DBMS에서는 볼 수 없는 Vacuum이라는 개념이 존재합니다. Vacuum 개념은 지난 Aurora MySQL vs Aurora PostgreSQL 글에서 잠깐 소개한 적이 있는데요.
PostgreSQL을 운영할 때 Vacuum을 잘 이해하고 적절하게 관리하는 것이 정말 중요하기 때문에 PostgreSQL을 소개해 드린 지 한참 지났지만, Vacuum에 대해 자세히 알아보고자 이 글을 준비했습니다.
사실 Vacuum이 정말 방대한 내용이라 미처 다 다루지 못한 내용도 있지만,
꼭 알아두어야 하는 내용들은 빠짐없이 정리할 수 있도록 노력했으니
차근차근 같이 따라와 주세요!
Vacuum이란?

Scaling PostgreSQL: Check your Vacuum!
처음 Vacuum이라는 단어를 보았을 때 진공청소기가 머릿속에서 바로 연상이 되실 텐데요.
맞습니다!
Vacuum은 PostgreSQL의 진공청소기 역할을 하는 동작입니다.
개발자분들에게 친숙한 GC (Garbage Collector)의 역할을 하는 동작이기도 하고요.
Vacuum은 PostgreSQL의 MVCC 구현 방법이 Oracle이나 MySQL 등 다른 DBMS와 다르고
그 차이로 인해 발생하는 문제점을 해결하기 위한 PostgreSQL만의 특별한 동작인데요.
Vacuum을 DB단에서 자동으로 수행하는 동작을 AutoVacuum이라고 하며
Vacuum & AutoVacuum(이하 Vacuum으로 통일)을 통해 아래 4가지 작업을 수행합니다.
- 임계치 이상으로 발생한 Dead Tuple을 정리하여 FSM (Free Space Map) 으로 반환
- Transaction ID Wraparound 방지
- 통계정보 갱신
- visibility map을 갱신하여 index scan 성능 향상
위 4개의 동작 모두 중요하지만 그 중 특히 중요한 것은
Dead Tuple을 정리하는 동작과 Trasaction ID Wraparound 방지 동작입니다.
이번 글에서는 Vacuum의 개념과 위 두 동작의 의미, 그리고 운영 방법에 대해 아래의 목차 순서대로 살펴보겠습니다.
- MVCC란?
- Vacuum은 왜 필요할까?
- AutoVacuum은 언제 호출될까?
- Vacuum 파라미터는 어떻게 튜닝할까?
- Vacuum이 실패하고 있다면?
MVCC란?
PostgreSQL의 Vacuum 동작을 이해하기 전에 앞서 알아두어야 하는 개념이 MVCC입니다.
서두에 말씀드린 것처럼 Vacuum은 PostgreSQL MVCC의 독특한 구현 방식 덕분에 탄생한 개념이기 때문입니다.
대부분의 DBMS에서 동시성을 위해 제공하는 MVCC(Multi-Version Concurrency Control) 기능은
동시에 여러 트랜잭션이 수행되는 환경에서 각 트랜잭션에게 쿼리 수행 시점의 데이터를 제공하여 읽기 일관성을 보장하고
Read/Write 간의 충돌 및 lock을 방지하여 동시성을 높일 수 있는 기능으로,
모든 MVCC의 기본 원리는 트랜잭션이 시작된 시점의 Transaction ID와 같거나 작은 Transacion ID를 가지는 데이터를 읽는 것입니다.
먼저 많은 분들에게 친숙한 Oracle과 MySQL의 MVCC 동작 방식을 보겠습니다.
Oracle의 MVCC
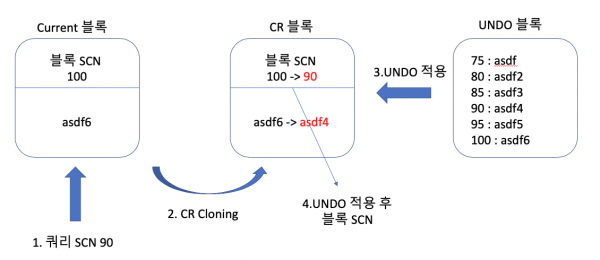
[Oracle MVCC]
Oracle은 UNDO segment(Rollback segment)를 사용하며
쿼리가 시작된 이후에 다른 트랜잭션에 의해 변경된 블록을 만나면 원본 블록으로부터 복사본 블록(CR copy)을 만들고
그 복사본 블록에 UNDO segment를 적용하여 쿼리가 시작된 시점으로 되돌려서 읽는 방식을 사용합니다
MySQL의 MVCC
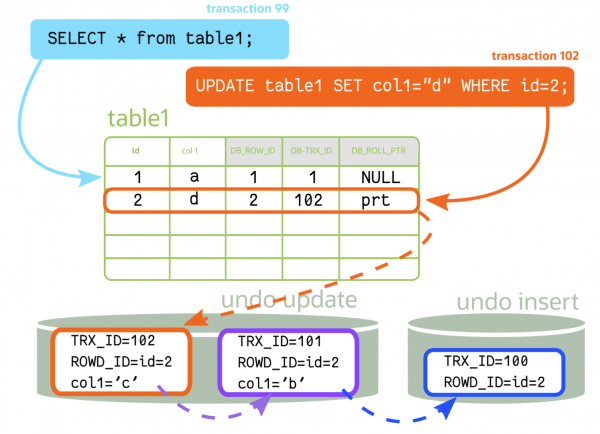
[MySQL MVCC] A graph a day, keeps the doctor away ! – MySQL History List Length
MySQL도 Oracle과 비슷하게 UNDO segment(Rollback segment)를 사용하며
트랜잭션에서 변경된 데이터가 UNDO 영역에 저장되고, 그 뒤의 변경된 내용들은 앞선 내용들을 포인터로 가리키는 형태입니다.
신규 트랜잭션이 수행되면, 이 포인터로 연결된 리스트들(History List Length)을 쭉 searching하면서 trx_id를 비교하고 자신이 읽을 수 있는 시점의 데이터를 확인하는 방식입니다.
PostgreSQL의 MVCC
반면에 PostgreSQL은 데이터 페이지 내에 변경되기 이전 Tuple과 변경된 신규 Tuple을 같은 page에 저장하고
Tuple별로 생성된 시점과 변경된 시점을 기록 및 비교하는 방식으로 MVCC를 제공합니다.
(PostgreSQL에서는 record 대신 Tuple이라는 용어를 사용합니다)
그리고 Tuple이 생성되거나 변경된 시점을 각 Tuple 내 xmin, xmax라는 메타데이터 field에 기록하여 어떤 Tuple을 읽을 수 있는지 버전 관리를 하게 됩니다.
-
xmin – Tuple을 insert하거나 update하는 시점의 Transaction ID를 갖는 메타데이터입니다.
Insert의 경우 insert된 신규 Tuple의 xmin에 해당 시점의 Transaction ID가 할당되고
UPDATE의 경우 update된 신규 Tuple의 xmin에 해당 시점의 Transaction ID가 할당됩니다. -
xmax – Tuple을 delete하거나 update하는 시점의 Transaction ID를 갖는 메타데이터입니다.
Delete의 경우 변경되기 이전 tupe의 xmax에 해당 시점의 Transaction ID가 할당됩니다.
UPDATE의 경우 변경되기 이전 Tuple의 xmax와 update된 신규 Tuple의 xmin에는 해당 시점의 Transaction ID가 할당되고,
update된 신규 Tuple의 xmax에는 NULL이 할당됩니다.
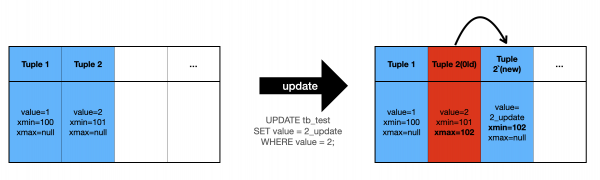
[PostgreSQL MVCC]
즉 위 그림에서는 value=2를 value=2_update로 update하였지만
기존 Old version의 value=2가 그대로 데이터 페이지 내에 저장되어 있는 상태(빨간색 Tuple)에서
New version의 value=2_update를 새로운 Tuple로 Insert하게 됩니다.
그리고 Old version이냐, New version이냐의 판단은 Transacion ID가 저장된 xmin,xmax 값을 비교해서 판단하게 됩니다.
Transacion ID 비교를 통한 MVCC 읽기 일관성에 대해 간단한 예를 살펴보면 다음과 같습니다.
xmin | xmax | value
-------+-------+-----
2010 | 2020 | AAA
2012 | 0 | BBB
2014 | 2030 | CCC
2020 | 0 | ZZZ- Transaction 2015에서는 ‘AAA’, ‘BBB’, ‘CCC’를 볼 수 있습니다.
- ‘ZZZ’는 xmin이 2020으로 미래의 값이므로 볼 수 없습니다.
- Transaction 2021에서는 ‘BBB’, ‘CCC’, ‘ZZZ’를 볼 수 있습니다.
- ‘AAA’는 xmax가 2020으로 2020까지만 존재하던 값으로, 2021에서는 볼 수 없습니다.
- Transaction 2031에서는 ‘BBB’, ‘ZZZ’를 볼 수 있습니다.
- ‘AAA’, ‘CCC’는 각각 xmax가 2020, 2030까지만 존재하던 값으로, 2031에서는 볼 수 없습니다.
Vacuum은 왜 필요할까
1. Vacuum이 필요한 이유 – Dead Tuple 정리
위에서도 간단하게 살펴보았지만 MVCC 구현을 위해 PostgreSQL의 update 동작은 아래와 같이 동작하게 됩니다.
- FSM(FreeSpaceMap, 사용 가능한 공간을 표시한 지도 같은 역할)에 사용 가능한 공간이 있는지 확인, 없으면 FSM을 추가 확보
- FSM의 사용 가능한 공간에 update된 데이터를 기록함(마치 insert처럼 동작함)
- update된 데이터의 저장이 완료되면 update 이전의 원본 Tuple을 가리키던 포인터를 새로 update된 Tuple을 가리키도록 변경함
위 과정에서 update가 완료되면 기존 원본 데이터를 저장한 Tuple은 어디에도 참조되지 않는 Tuple이 되는데
이를 쓸모없는, 죽은 데이터라는 의미로 Dead Tuple이라고 합니다.
문제는 이 Dead Tuple이 자동으로 정리되거나 FSM으로 반환되지 않기 때문에 쓸데없이 공간만 차지할 뿐만 아니라,
쓸데없이 공간만 차지하는 Dead Tuple 때문에 DB는 더 많은 page를 읽게 되고 이는 쿼리 성능에도 악영향을 끼칩니다.
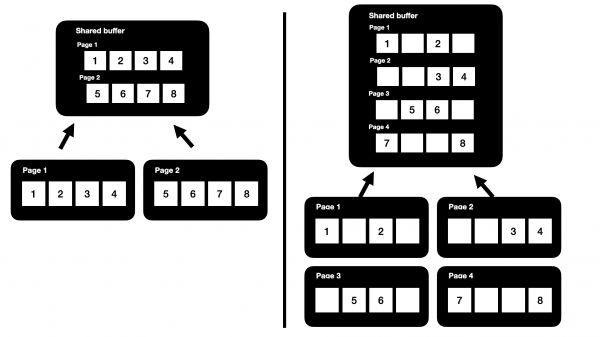
이를 풀어서 다시 얘기해보면,
다른 DBMS에서도 데이터를 읽을 때 block 단위로 메모리에 올리듯이 PostgreSQL도 page 단위로 읽어와 메모리에 올립니다.
다만 PostgreSQL에서는 MVCC 구현 방식의 특성상 Dead Tuple도 같은 page 내에 저장되기 때문에
page에 live Tuple뿐만 아니라 불필요한 Dead Tuple도 포함되어 있습니다.
page의 크기는 default 8KB로 한정되어 있고 Dead Tuple이 쓸모없이 공간만 차지하기 때문에
필요한 live Tuple을 읽기 위해서는 더 많은 page를 읽어야 하고 이는 곧 더 많은 디스크 I/O 발생으로 이어지게 됩니다.
위 그림처럼 dead tuple이 없는 상태(왼쪽)에서는 id 1~8의 데이터를 읽기 위해 단 2개의 페이지만 읽으면 되는데
dead tuple이 많은 상태(오른쪽)에서는 똑같은 데이터를 읽어도 2배의 페이지를 읽어야 하는 것이죠.
즉, Dead Tuple은 테이블 공간의 비효율적 사용으로 인한 디스크 사용률 증가 이슈뿐만 아니라
쿼리 성능에도 악영향을 끼치게 되는 PostgreSQL의 골칫덩이라고 할 수 있는 것입니다.
그리고 Vacuum은 바로 이러한 현상을 방지하고, 또 해결할 수 있는데요.
간단한 테스트를 통해 확인해 보겠습니다.
- Vacuum 수행 전 Dead Tuple이 존재하는 상황
### autovacuum off
testdb=> alter table tb_test set (autovacuum_enabled = off);
ALTER TABLE
### delete 전 count 조회
testdb=> select count(*) from tb_test;
count
----------
10000000
(1 row)
Time: 548.779 ms
### delete 후 count 조회
testdb=> delete from tb_test where ai != 1;
DELETE 9999999
Time: 30142.916 ms (00:30.143)
testdb=> select count(*) from tb_test;
count
-------
1
(1 row)
Time: 497.835 ms
=> 1건을 count하는데도 오래걸림
### Dead Tuple 확인
testdb=> SELECT relname, n_live_tup, n_Dead_tup, n_Dead_tup / (n_live_tup::float) as ratio
FROM pg_stat_user_tables;
relname | n_live_tup | n_Dead_tup | ratio
----------+------------+------------+----------
tb_test | 1 | 9999999 | 9999999
=> Dead Tuple이 9999999개로 증가함, 반면에 live Tuple은 1건
### 테이블 사이즈 조회
testdb=> dt+ tb_test
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+---------+-------+--------+-------------+---------+-------------
public | tb_test | table | master | permanent | 1912 MB |
=> 1건짜리 테이블임에도 거의 2GB인 상황tb_test 테이블은 데이터를 1건 가지고 있지만 조회 속도와 테이블 크기 면에서 무언가 1건 답지 않은 이질감이 듭니다(1건 있는데 0.5초라니).
그 이유는 tb_test는 delete 수행으로 인해 Dead Tuple들이 대량 발생했고 실제 데이터는 1건이지만 1912MB의 큰 테이블로 잔뜩 bloating되어 남아있기 때문입니다(실행 계획도 갱신이 되지 않았고요).
이번에는 vacuum을 수행하고 다시 확인해 보겠습니다.
- vacuum 수행 후 Dead Tuple이 정리된 상황
### autovacuum off
testdb=> alter table tb_test set (autovacuum_enabled = off);
ALTER TABLE
### vacuum 수행 후 Dead Tuple 확인
testdb=> vacuum tb_test;
VACUUM
Time: 11273.959 ms (00:11.274)
testdb=> SELECT relname, n_live_tup, n_Dead_tup, n_Dead_tup / (n_live_tup::float) as ratio
FROM pg_stat_user_tables;
relname | n_live_tup | n_Dead_tup | ratio
----------+------------+------------+-------
tb_test | 1 | 0 | 0
=> Dead Tuple이 0개로 모두 정리됨
### 데이터 조회 속도 및 테이블 사이즈 비교
testdb=> select count(*) from tb_test;
count
-------
1
(1 row)
Time: 9.971 ms
=> 앞에서와 달리 1건 counting이 바로 완료됨
testdb=> dt+ tb_test;
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+---------+-------+--------+-------------+-------+-------------
public | tb_test | table | master | permanent | 1912 MB |
=> vacuum 수행 후 dead tuple은 정리되었지만 테이블 사이즈는 그대로임
### vacuum full 수행 후 테이블 사이즈 확인
testdb=> vacuum full tb_test;
VACUUM
testdb=> dt+ tb_test;
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+---------+-------+--------+-------------+-------+-------------
public | tb_test | table | master | permanent | 40 kB |
=> vacuum full 수행 후에는 테이블 사이즈도 줄어들었음Vacuum 후 Dead Tuple이 모두 정리되었고 테이블 조회 속도 또한 같은 1건을 count 하지만 훨씬 빨라졌음을 확인했습니다 (497ms → 10ms)
그러나 이때 알아두어야 할 것은
Vacuum full이 아닌 단순 Vacuum으로는 물리 디스크로 이미 할당된 크기는 회수 되지 않았다는 점입니다.(경우에 따라 vacuum으로도 회수되는 경우가 있지만 본 글에서는 다루지 않음)
위 테스트 결과에서처럼 vacuum full을 수행했을 때는 tb_test 테이블 사이즈의 경우 40KB로 줄었지만
단순히 vacuum을 수행했을 땐 tb_test의 테이블 사이즈는 1,912MB 그대로였습니다.
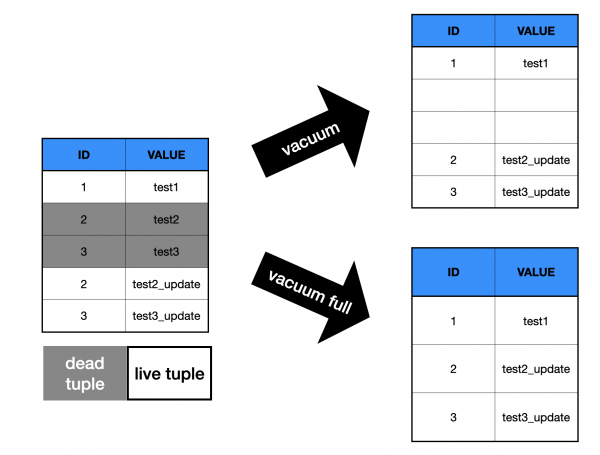
[vacuum 과 vacuum full 차이]
위 그림처럼 일반 Vacuum, AutoVacuum을 수행했을 때는 OS 디스크의 공간 반환까지는 처리되지 못하고
FSM에만 반환되어 이 공간(위에서 흰 빈 공간)을 재사용할 수 있게끔만 처리됩니다.
OS 디스크의 공간 반환까지 처리하려면 vacuum full이라는 작업을 수행해야 하는데,
이 작업은 Access Exclusive Lock을 획득해 DML은 물론 SELECT도 대기하게 되어 운영 중에는 할 수 없는 작업입니다.
(Vacuum, AutoVacuum은 online 작업을 지원하며 DML도 가능합니다, DDL은 불가)
뿐만 아니라 Vacuum full 동작은 대상 테이블을 1벌 더 COPY하는 식으로 동작하기 때문에
디스크 가용량이 여유롭지 못한 상황에서는 시도조차 할 수 없습니다.
[pg_repack]
그래서 수행이 어려운 vacuum full 대신 pg_repack이라는 오픈소스 툴을 사용하기도 합니다.
물론 pg_repack을 사용한다고 하여도, 작업을 위한 여유 디스크 가용량과 작업 도중 여러 번의 Metadata lock이 필요하고 CPU, I/O 등의 부하가 있는 작업인 만큼
서비스의 피크 시간대에 사용하기엔 부담스러울 수 있어 충분한 검토가 필요한 작업입니다.
그렇기 때문에 “나중에 pg_repack으로 조치해야지!”보다는
Vacuum과 관련한 파라미터의 적절한 튜닝과 정책을 잘 세워서 평소에 Dead Tuple 정리를 원활히 하여 불필요한 공간이 늘어나지 않도록 관리하는 것이 가장 중요합니다.
2. Vacuum이 필요한 이유 – Transaction ID Wraparound 방지
방금 살펴본 Dead Tuple 이슈는 DB 성능과 디스크의 비효율적인 사용 이슈를 유발하지만 서비스 중단을 일으킬 정도의 문제는 아닙니다.
그러나 Transaction ID Wraparound 이슈는 다릅니다.
제때 vacuum이 수행되지 않아 Transaction ID 정리가 안 되면 DB의 모든 write 작업이 멈출 수 있는 중요한 이슈라서
DB에서 AutoVacuum을 OFF 해놔도 관련 임계치를 초과하면 DB에서 강제로 수행하게 됩니다.
Transaction ID Wraparound 방지를 위한 AutoVacuum을 살펴보기 전에 중요한 2가지 개념인 Transaction ID와 age에 대해 먼저 살펴보겠습니다.
- Transaction ID 란?
먼저 Transacion ID에 대해 살펴보자면
위에서 PostgreSQL은 데이터 페이지 내에 old version의 Tuple과 new version의 Tuple을 모두 저장하며
Tuple의 xmin, xmax field에 저장된 Transaction ID값 비교를 통해 MVCC를 구현한다고 말씀드렸습니다.
이때 xmin, xmax에 할당된 바이트 수는 각각 4바이트로
약 40억(2^32) 개의 트랜잭션을 표현할 수 있으며 20억 개는 과거, 20억 개는 미래를 위해 사용하게 되는데
만약 Transaction ID를 모두 소진하여 다시 1부터 시작하게 되면 어떻게 될까요?
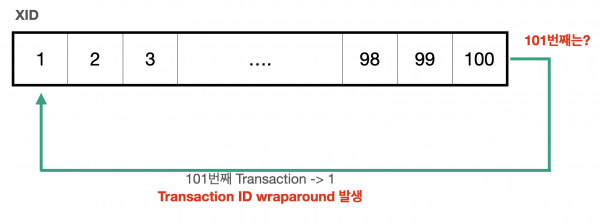
[Transaction ID wraparound]
한 바퀴 돌고 난 뒤의 Transaction ID 1은 기존의 데이터보다 최신 데이터임에도 불구하고
기존의 데이터들은 모두 Transaction ID가 1보다 크기 때문에 과거의 데이터인 기존의 데이터들이 모두 미래에 있는 것처럼 되어 보이지 않게 됩니다.
즉, 과거 데이터들이 모두 손실되는 Transaction ID Wraparound 현상이 발생합니다.
이는 PostgreSQL 입장에서 보면 종말과도 같기 때문에 PostgreSQL의 소스코드에는 다음과 같은 낭만 있는 주석도 있습니다.
엔진설치위치/include/server/access/transam.h
TransactionId oldestXid; /* cluster-wide minimum datfrozenxid */
TransactionId xidVacLimit; /* start forcing AutoVacuums here */
TransactionId xidWarnLimit; /* start complaining here */
TransactionId xidStopLimit; /* refuse to advance nextXid beyond here */
TransactionId xidWrapLimit; /* where the world ends */where the world ends….
그래서 PostgreSQL에서는 Transacion ID를 재사용하기 위해 과거 데이터의 Transaction ID를 계속 증가시키는 게 아니라
특정 시점에서 모두 frozen XID = 2라는 특별한 Transaction ID로 바꿔버립니다.
그리고 이 동작을 freeze 혹은 Anti Wraparound Vacuum라고 합니다.
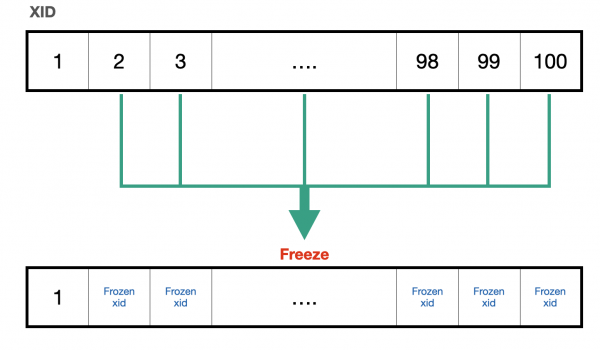
[Anti Wraparound Vacuum]
- age란?
그리고 PostgreSQL의 Transaction ID와 같이 알아야 하는 개념으로 age라는 개념이 있는데
age는 말 그대로 테이블 등 오브젝트와 Tuple의 ‘나이’를 말합니다
테이블 생성 시 혹은 Tuple을 처음 insert 할 때의 age는 1부터 시작하며 해당 테이블에 대한 트랜잭션이 아니더라도 DB에서 트랜잭션이 발생할 때마다 모든 오브젝트와 Tuple의 age가 1씩 증가합니다.
age가 계속 증가하다가 age 관련 특정 파라미터의 임계치에 도달하면 Transaction ID Wraparound를 방지하기 위한
Anti Wraparound Vacuum의 대상이 되고
Anti Wraparound Vacuum이 수행된 후에는 테이블과 Tuple의 age가 다시 회춘하게 됩니다(freezing)
Age는 크게 2가지로 나뉩니다.
- Tuple age
- Table age
Tuple은 Anti Wraparound Vacuum이 수행될 때 freeze 되는 대상 그 자체이며, freeze 대상이 되는 기준은 아래에서 살펴볼 vacuum_freeze_min_age(default 5천만) 설정값보다 age가 높은 Tuple이 대상이 됩니다.
반면에 Table은 Tuple과는 달리 freeze의 대상이 아닙니다. 다만, Table의 age는 이 테이블에 속한 Tuple의 age 중 가장 높은 값으로 설정이 되기 때문에 Tuple의 age를 대표하는 특성이 있습니다.
그렇기 때문에 Table에 속한 Tuple의 age를 모두 찾아볼 필요 없이,
Table의 age만 보고도 ‘아 이 테이블에는 Freezing이 필요한 Tuple가 있구나’ 라는 판단을 할 수 있게 됩니다.
그래서 아래에서 살펴볼 vacuum_freeze_table_age, autoacuum_freeze_table_max_age 이 파라미터들은 Table age를 임계치로 보고 Anti Wraparound Vacuum을 수행합니다.
이 age라는 개념은 PostgreSQL의 MVCC 읽기 일관성에 큰 영향을 끼치는 Transaction ID Wraparound현상을 방지하기 위해 반드시 관리를 해주어야 하며 관련해서는 아래에서 자세히 확인해보겠습니다.
AutoVacuum은 언제 호출될까?
Vacuum 동작을 DB단에서 임계치에 따라 자동으로 수행하는 것이 AutoVacuum이라고 하며, AutoVacuum은 기본적으로 아래 두가지 상황에서 수행됩니다.
- Dead Tuple의 개수의 누적치가 임계치에 도달했을 때
- Table이나 Tuple의 age가 누적되어 임계치에 도달했을 때
그리고 Dead Tuple에 의한 vacuum 은 쿼리의 성능문제, 그리고 물리적인 disk 이슈를 방지하기 위해 수행되는 vacuum이고
age가 임계치에 도달했을 때 수행되는 vacuum은 자칫하면 DB의 동작을 모두 멈추게 할 수 있는 Transaction ID Wraparound 현상을 방지하기 위한 vacuum이라고 위에서 살펴보았습니다.
지금부터는 AutoVacuum이 호출되는 두가지 경우에 대해 하나씩 알아보겠습니다.
1) Dead Tuple의 누적치가 임계치에 도달했을 때
vacuum threshold = autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * number of TuplesDead Tuple 발생량이 위 공식의 결과값만큼 쌓이면 AutoVacuum이 호출되고, 공식을 이루는 파라미터는 아래와 같은 의미를 가집니다.
- 관련 주요 파라미터
testdb=# select name,setting from pg_settings where name in ('autovacuum_vacuum_scale_factor', 'autovacuum_vacuum_threshold');
name | setting
--------------------------------+---------
autovacuum_vacuum_scale_factor | 0.2
autovacuum_vacuum_threshold | 50- autovacuum_vacuum_scale_factor : 테이블의 전체 Tuple 개수 중 설정한 비율만큼의 데이터가 변경되면 해당 테이블에 대해 AutoVacuum을 수행합니다.
- autovacuum_vacuum_threshold : 의미는 autovacuum_vacuum_scale_factor와 동일하지만, 비율이 아니라 테이블 내 변경된 Tuple 개수로 동작합니다.
기본적으로 autovacuum_vacuum_threshold의 값은 50 rows 이고 autovacuum_vacuum_scale_factor는 20%입니다.
즉 table의 Dead Tuple 누적치가 테이블의 모든 행 중 20% + 50개를 초과하는 경우 AutoVacuum 이 호출되어 Dead Tuple을 정리하게 됩니다.
2) Table이나 Tuple의 age가 누적되어 임계치에 도달했을 때
앞에서 Dead Tuple의 누적치에 따라 AutoVacuum이 호출되는 경우를 봤다면
이번에는 테이블이나 Tuple의 age가 임계치에 도달하여 AutoVacuum이 호출되는 경우를 살펴보겠습니다.
freeze, Anti Wraparound Vacuum 동작은 아래 빨간색 체크 표시가 된 2가지 경우에 수행됩니다.
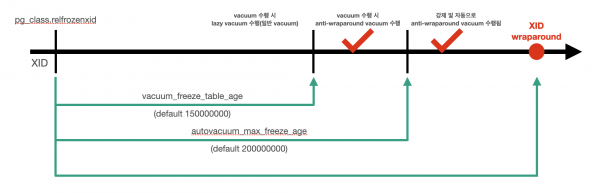
[age별 vacuum 동작]
- 테이블의 age가 autovacuum_freeze_max_age(default 2억) 파라미터 임계치를 초과한 경우
- vacuum_freeze_table_age < 테이블의 age < autovacuum_freeze_max_age
=> 테이블의 age가 위 두 파라미터 값 사이에 속하면서 해당 테이블에 vacuum이 호출되었을 때
- 관련 주요 파라미터
testdb=# select name,setting from pg_settings where name like '%freeze%';
name | setting
-------------------------------------+-----------
autovacuum_freeze_max_age | 200000000
vacuum_freeze_min_age | 50000000
vacuum_freeze_table_age | 150000000- autovacuum_freeze_max_age: 해당 값을 초과하는 age의 테이블에 대해 Anti Wraparound AutoVacuum을 수행함, AutoVacuum을 off해도 강제로 수행됨
- vacuum_freeze_min_age: 해당 값을 초과하는 age의 Tuple을 vacuum 작업 시 Transaction ID freeze 작업의 대상으로 한다. Anti Wraparound AutoVacuum 수행 이후 테이블의 age는 최대 vacuum_freeze_min_age 값으로 설정됨
- vacuum_freeze_table_age: 해당 값을 초과하는 age의 테이블에 대해 vacuum이 호출될 때 frozen 작업도 같이 수행함
- 다수의 테이블들이 autovacuum_freeze_max_age에 걸려서 동시에 Anti Wraparound AutoVacuum이 수행되기 전에, 그전에 vacuum이 호출된 테이블이 Anti Wraparound AutoVacuum으로 돌도록 분산하는 효과
Vacuum 관련 파라미터는 어떻게 튜닝할까
AutoVacuum을 설정하는데 있어 가장 중요한 것은 AutoVacuum이 “적절”한 빈도로 수행되도록 하는 것입니다.
보통 Vacuum 동작은 비용이나 부하가 많이 필요한 작업이기 때문에
“서비스 피크시간 보다는 한가한 새벽시간대 혹은 점검일정 마다 돌리면 안될까?” 라고 생각할 수 있습니다.
이것도 맞는 이야기고 이렇게 해야하는 테이블도 있겠지만,
일반적으로는 Vacuum이 드물게 수행될수록 정리해야 하는 Dead Tuple이나 frozen 작업이 점점 많아져서 오히려 더 큰 부하를 유발하는 상황이 올 수 있습니다.
그렇다고 해서 무작정 Vacuum이 자주 수행되도록 하는 것도
vacuum의 부하가 쿼리 성능에 영향을 끼치고, DDL 수행과 겹치는 경우엔 예상치 못한 metadata lock 대기로 인한 장애 상황 등이 발생할 수 있습니다.
따라서 Vacuum 튜닝은 무작정 최대한 적게 혹은, 최대한 자주 돌도록 튜닝하는 게 아니라
Dead Tuple 정리와 Vacuum의 부하 간 적절한 균형을 찾는 것이 중요합니다.
Vacuum 튜닝에 정답은 없다지만,
그래도 최소 아래 2가지 설정 정도는 PostgreSQL의 default 설정 보다는 서비스에 맞게 모니터링해 보며 설정하는 것을 추천합니다.
1) autovacuum_vacuum_scale_factor & autovacuum_vacuum_threshold
이 파라미터는 변경된 Tuple 개수와 비율로 임계치를 설정하는 의미지만 설명하기 편하게 Tuple 개수 대신 데이터 크기로 비유해보자면,
PostgreSQL의 default 설정에서는
10GB 테이블은 2GB의 Dead Tuple이 발생했을 때,
1TB 테이블은 200GB의 Dead Tuple이 발생했을 때 AutoVacuum이 수행됩니다.
작은 테이블에서는 티가 나지 않겠지만 테이블이 점점 커질수록 AutoVacuum이 수행됐을 때 정리해야 하는 Dead Tuple이 너무 많아지고
부하가 커지는 상황이 발생할 수 있기 때문에 조금 더 자주 수행될 수 있도록 조정이 필요합니다.
- default 설정
- autovacuum_vacuum_threshold = 50
- autovacuum_vacuum_scale_factor = 0.2
- 권장 설정
- autovacuum_vacuum_threshold = 50
- autovacuum_vacuum_scale_factor = 0.1
그리고 특정 문제되는 테이블이 있다면 개별 테이블에 대해 직접 AutoVacuum 임계치를 설정하여 이를 통해 좀 더 세밀한 관리정책을 세우는 것도 추천하는 방법입니다.
ex) ALTER TABLE tb_test SET (autovacuum_vacuum_scale_factor = 0.01, autovacuum_vacuum_threshold= 0 );참고로 PostgreSQL 13버전부터는 insert에 대한 vacuum threshold도 추가되었습니다
2) autovacuum_vacuum_cost_limit & autovacuum_vacuum_cost_delay
- default 설정
- autovacuum_vacuum_cost_limit = 200
- autovacuum_vacuum_cost_delay = 20ms
- 권장 설정
- autovacuum_vacuum_cost_limit = 1000 or autovacuum_vacuum_cost_limit = 200 * (autovacuum_max_workers / 3)
- autovacuum_vacuum_cost_delay = 5ms
이 값이 의미하는 바를 이해하기 위해서는 아래의 파라미터들을 먼저 알아둘 필요가 있습니다.
autovacuum_vacuum_cost_limit = 200
vacuum_cost_delay = 0
vacuum_cost_page_hit = 1
vacuum_cost_page_miss = 10
vacuum_cost_page_dirty = 20- autovacuum_vacuum_cost_limit = 200: AutoVacuum(Vacuum) 이 한 번 수행될 때 마다 해당 Vacuum 프로세스는 200의 credit을 가집니다.
- vacuum_cost_delay = 0: AutoVacuum이 autovacuum_vacuum_cost_limit 만큼 완료되면 다음 AutoVacuum은 이 몇 밀리초 동안 sleep합니다.
- vacuum_cost_page_hit = 1: page_hit (shared_buffer)에 있는 데이터를 Vacuum 할 때 마다 1 의 credit을 소모합니다.
- vacuum_cost_page_miss = 10: page_miss (디스크 영역)에 있는 데이터를 Vacuum할 때마다 10의 credit을 소모합니다.
- vacuum_cost_page_dirty = 20: Dead Tuple을 Vacuum할 때마다 20의 credit을 소모합니다.
주어진 200의 credit 이 모두 소진되면 해당 AutoVacuum 프로세스는 종료됩니다.
그렇기 때문에 이 값이 너무 작으면 AutoVacuum이 Dead Tuple을 충분히 다 정리하지 못한 채 끝나버려서
Dead Tuple이 계속 누적되는 경우가 생길 수 있습니다.
그래서 autovacuum_vacuum_cost_limit 파라미터를 증가시키면 한 번 AutoVacuum이 돌 때 좀 더 오래 돌게 되어
Dead Tuple을 미처 정리하지 못하는 경우가 줄어드는 효과가 있습니다.
참고로, AWS의 RDS 설정은 *GREATEST({log(DBInstanceClassMemory/21474836480)600},200)**
로 설정되어 인스턴스 스펙 별로 자동으로 설정해주고 있습니다.
그 외에도 좀 더 공격적으로 AutoVacuum을 수행하도록 아래 파라미터를 고려해볼 수 있습니다.
3) autovacuum_naptime = 60s → 5s
AutoVacuum 실행 사이의 최소 지연, 즉 term을 deafult 1분에서 초단위로 변경합니다 .
4) autovacuum_max_workers
이 파라미터를 통해 AutoVacuum을 병렬로 수행할 수 있는 worker 수를 2배로 늘린다고
AutoVacuum의 처리량과 성능이 곧바로 2배만큼 늘어나는 것은 아닙니다.
하지만 큰 테이블들의 Vacuum으로 인해 작은 테이블들이 Vacuum을 하지 못하는 현상이 발생했을 때 이 값을 늘리면 효과적일 수 있습니다.
특히 partitioning이 되어 있는 테이블의 경우, 각 파티션별로 AutoVacuum worker들이 할당되어 더 빠른 Vacuum 작업을 수행할 수 있습니다
DB 서버의 CPU 코어 수를 따져 너무 과하게 세팅되지 않도록 설정합니다(CPU N cores / 2 … 4 정도).
AWS RDS의 경우 GREATEST({DBInstanceClassMemory/64371566592},3)
로 설정되어 인스턴스 스펙별로 자동으로 설정해주고 있습니다
5) max_parallel_maintenance_workers
index 생성이나 vacuum 작업을 병렬로 수행합니다.
DB 서버의 CPU 코어 수를 확인하여 너무 과하게 세팅하지 않도록 합니다
default는 2개인데, 해당 작업이 너무 느리면 4개~8개 정도로 설정하면 도움이 될 수 있습니다.
다른 parallel 관련 파라미터(max_parallel_workers, max_parallel_workers_per_gather )도 관련해서 같이 확인해야 합니다.
6) autovacuum_work_mem
힙(테이블)을 스캔할 때 vacuum은 메모리에서 Dead Tuple을 수집하는데,
수집할 수 있는 Dead Tuple 수는 autovacuum_work_mem (maintenance_work_mem)에 의해 결정됩니다
이 파라미터를 통해 vacuum이 주기 당 더 많은 Dead Tuple을 수집하도록 할 수 있습니다.
DB서버의 memory 사이즈를 확인하여 너무 과하게 세팅하지 않도록 합니다.
AWS RDS의 경우 GREATEST({DBInstanceClassMemory/32768},131072)
로 설정되어 인스턴스 스펙별로 자동으로 설정해주고 있습니다
정리해보면 AutoVacuum의 성능 관련하여 튜닝해볼 만한 파라미터는 아래와 같습니다.
- AutoVacuum이 너무 드물게 돌고있다
- autovacuum_vacuum_scale_factor & autovacuum_vacuum_scale_threshold
- autovacuum_vacuum_insert_scale_factor & autovacuum_vacuum_scale_threshold
- AutoVacuum이 너무 느리다
- autovacuum_vacuum_cost_delay
- autovacuum_vacuum_cost_limit
- autovacuum_naptime
- autovacuum_max_workers
- autovacuum_work_mem
- max_parallel_maintenance_workers
Vacuum이 실패하고 있다면?
이렇게 Vacuum이 왜 필요한지 알아보고 언제 동작하는지 또 어떻게 적절하게 튜닝할 수 있을지 까지 알아봤는데
정작 Vacuum이 실패하고 있다면 소용이 없겠죠 ?
AutoVacuum은 흔히 아래 세가지 상황에서 실패합니다.
1) Long transaction이 수행되는 경우
2022-07-26 08:00:47 UTC::@:[10576]:LOG: automatic vacuum of table "prod.product.tb_prod": index scans: 0
pages: 0 removed, 101549 remain, 0 skipped due to pins, 38251 skipped frozen Tuples: 0 removed, 2912025 remain, 1041608 are Dead but not yet removable, oldest xmin: 10674654
buffer usage: 216405 hits, 0 misses, 0 dirtied
avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s
system usage: CPU: user: 0.27 s, system: 0.00 s, elapsed: 1.18 sLong transaction이라 표현했지만 AutoVacuum이 수행되고 있는 시점에 이미 오래 수행중인 쿼리가 있다면 이 경우에 해당합니다.
Dead Tuple은 실제로 더이상 해당 Dead Tuple들을 다른 트랜잭션에서 참조하지 않아야 정리가 가능한데,
long transaction 수행중에 참조되는 Tuple들, 그리고 commit이 안된 idle 상태의 transaction으로 인해 해당 Dead Tuple들을 정리하지 못하는 경우가 발생할 수 있습니다.
위 로그에서는
1041608 are Dead but not yet removable, oldest xmin: 10674654, xmin 10674654 즉 oldest xmin: 10674654, xmin 10674654의 트랜잭션으로 인해 1041608 Dead Tuple들을 정리하지 못했다는 내용을 볼 수 있습니다.
그래서 PostgreSQL에서는 항상 long transaction과 commit이 안된 transaction에 대한 모니터링이 필요하며
statement_timeout , idle_in_transaction_session_timeout 같은 파라미터로 쿼리, 혹은 트랜잭션이 너무 오래 방치되지 않도록 예방하는 것도 하나의 방법입니다.
물론 이 파라미터를 통해 제어하려면 서비스 개발팀과 꼭 협의가 필요합니다.
2) 미사용의 버려진 replication slot이 있을때
이 케이스는 PostgreSQL의 Replication 방식 중 하나인 physical replication slot을 사용하는 streaming replication 구성에서 발생할 수 있습니다.
standby 서버에 복제 지연이 있거나 standby server가 down되는 경우,
replication slot은 복제에 필요한 데이터를 계속 담아두게 되고, 이렇게 남겨진 replication slot은 갖고 있는 데이터가 Dead Tuple로 vacuum 정리되는 것도 방해하게 됩니다.
3) hot_standby_feedback = ON
PostgreSQL Replication 아키텍처에서 발생할 수 있는 이슈로
Master에서는 Dead Tuple로 확인되어 vacuum이 정리한 Tuple이 Replica server에서는 복제 지연이나 Long transaction 수행으로 인해 여전히 그 데이터를 필요로 할 수 있습니다.
이렇게 되면 replication confilct가 발생하기 때문에 PostgreSQL에서는 hot_standby_feedback = ON 설정을 통해
Replica 서버에서 수행한 쿼리와 현재 Replica 서버의 가장 오래된 트랜잭션 정보를 Master로 feedback을 주게 되고, 그때까지 Master는 해당 Dead Tuple을 정리할 수 없게 됩니다.
이런 현상 때문에 AutoVacuum이 Dead Tuple을 정리하지 못하는 상황이 발생할 수 있습니다.
참고로 Aurora PostgreSQL은 hot_standby_feedback = ON가 default이고 변경이 불가능합니다
마치며
PostgreSQL은 MVCC의 구현 방법상의 특징으로 vacuum이라는 동작이 필수이고,
이 vacuum 동작을 DB단에서 여러 파라미터로 설정된 임계치를 통해 자동으로 수행하는 것이 AutoVacuum입니다.
AutoVacuum(vacuum)의 주요 목적으로는 아래 네가지가 있으며
- 임계치 이상으로 발생한 Dead Tuple을 정리하여 FSM (Free Space Map)으로 반환
- Transaction ID Wraparound 방지
- 통계 정보 갱신
- visibility map을 갱신하여 index scan 성능 향상
이번 글에서는 Dead Tuple 정리, Transaction ID Wraparound 방지에 대해 알아보았습니다.
성능과 디스크의 효율적 사용을 위해 Dead Tuple 정리도 중요하지만
DB의 지속적인 운영을 위해서는 vacuum을 통한 Transaction ID Wraparound 방지 작업이 중요하다는 것과
AutoVacuum이 호출되는 경우에 대해 테스트를 해보면서 어떤 경우에 AutoVacuum이 호출되는지, 이 때 어떤 변화가 생기는지에 대해서도 확인해보았습니다.
-
Dead Tuple
- vacuum threshold = autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * number of Tuples
-
Transaction ID (age)
- 테이블 age > autovacuum_freeze_max_age vacuum_freeze_table_age < 테이블 age < autovacuum_freeze_max_age
상황별로 AutoVacuum이 잘 수행될 수 있도록 어떤 파라미터를 수정하면 좋을지에 대해서 살펴보면서 아래 파라미터에 대해 말씀드렸습니다
- AutoVacuum이 너무 드물게 돌고있다
- autovacuum_vacuum_scale_factor / threshold
- autovacuum_vacuum_insert_scale_factor / threshold
- AutoVacuum이 너무 느리다
- autovacuum_vacuum_cost_delay
- autovacuum_vacuum_cost_limit
- autovacuum_naptime
- autovacuum_max_workers
- autovacuum_work_mem
- max_parallel_maintenance_workers
마지막으로는 AutoVacuum이 실패해서 Dead Tuple이 정리되지 않을 수 있는 아래 3가지 케이스에 대해서 살펴보았습니다.
- Long transaction이 수행되는 경우
- 버려진 replication slot이 있을때
- hot_standby_feedback = ON
이렇게 PostgreSQL의 Vacuum은
Oracle이나 MySQL 같은 다른 RDBMS에는 없는 생소한 개념이라 이해하기도 어렵고 신경쓸 것도 정말 많습니다.
PostgreSQL은 여러 강력한 개발 편의성을 제공하는 기능 덕에 개발자분들이 선호하는 DBMS임과 동시에,
Vacuum이라는 허들 때문에 DBA에게는 까다로운 DBMS이기도 합니다.
그러나 애플리케이션과 서비스가 고도화될 수록 서비스에 맞는 적절한 스토리지를 사용하는 게 점점 더 중요해지는 요즘,
Vacuum이라는 허들 때문에 PostgreSQL를 배제하는 것은 아쉽지 않을까요?
이 글이 PostgreSQL을 도입하고 싶지만 Vacuum이라는 낯선 개념 때문에 망설여지는 분들께 조금이나마 도움이 되는 글이기를 바라며 마치겠습니다.
