Aurora MySQL vs Aurora PostgreSQL
들어가며
안녕하세요, 클라우드스토리지개발팀 정지원 입니다.
최근 저희 팀에서는 Aurora MySQL로 운영되고 있던 대량 통계성 DB를 Aurora PostgreSQL로 이관하는 것을 검토중입니다. 그래서 오늘은 준비 과정에서 정리했던 내용들을 공유하고자 합니다.
서비스 특화의 DB를 선택해야 하는 고민
데이터가 누적될수록 특히 통계, 정산 등이 필요한 대량 데이터 작업의 배치 수행 속도는 느려지기 마련입니다. 저희가 관리하고 있는 정산 서비스 또한 그랬는데요, MySQL 환경에서 동작 중인 해당 서비스는 쿼리 개선 작업을 진행하였지만 드라마틱한 효과를 볼 수는 없었습니다.
MySQL에서는 멀티쓰레드 환경 및 제한된 join 방식 제공으로 복잡한 쿼리나 대량 데이터 처리에서는 불리한 요소로 작용합니다. 또한 데이터 크기가 커질수록 테이블의 구조 변경이나 인덱스 생성 작업에도 상당한 시간이 소요되는데요, 이러한 점들을 개선하기 위해 대량 데이터 처리에 특화돼 있다는 PostgreSQL로의 이관을 고민하게 되었습니다.
Aurora MySQL vs Aurora PostgreSQL
우선 이관을 고려하기에 적절할지 파악을 위해 두 DBMS 간 간단하게 기능적, 성능적 차이를 살펴보았습니다.
기능비교
| Aurora MySQL(5.7) | Aurora PostgreSQL(11) | comment | |
|---|---|---|---|
| DB특성 | RDBMS | ORDBMS | PostgreSQL은 객체관계형 DBMS로 개발자는 기존 데이터 type에서 확장된 type형태를 자유롭게 정의하여 사용할 수 있다. 또한 테이블 상속기능이 제공되어 자식 테이블은 부모 테이블로부터 열을 받아 사용할 수 있다. |
| 방식 | 멀티쓰레드 | 멀티프로세스 | |
| 사용환경 | OLTP에 적절 | OLTP, OLAP에 적절 | 단순 CRUD시에는 MySQL에 비해 PostgreSQL의 성능이 조금 떨어진다. PostgreSQL은 복잡한 쿼리를 요구하고 대규모 서비스인 경우에 특화되어 있다. |
| MVCC지원 | Undo Segment 방식 | MGA(Multi Generation Architecture) 방식 | – Undo segment 방식: update 된 최신 데이터는 기존 데이터 블록의 레코드에 반영하고 변경 전 값을 undo 영역이라는 별도의 공간에 저장하여 갱신에 대한 버전관리를 하는 방식이다. – MGA 방식: 튜플을 update할 때 새로운 값으로 replace 처리하는 것이 아니라, 새로운 튜플을 추가하고 이전 튜플은 유효 범위를 마킹하여 처리하는 방식이다. |
| UPDATE 방식 | UPDATE | INSERT & DELETE (check) | PostgreSQL UPDATE시 내부적으로는 새 행이 INSERT되고 이전 데이터는 삭제 표시가 된다. 모든 인덱스에는 행의 실제 위치값에 대한 링크가 표기되어 있는데, 행이 업데이트되면 변경된 위치값에 대한 인덱스 정보도 업데이트가 필요하다. 이런 과정 때문에 UPDATE시에는 MySQL보다 성능이 떨어진다. |
| 지원되는 JOIN | NL JOIN HASH JOIN (5.7 2.06 ~) |
NL JOIN HASH JOIN SORT JOIN |
|
| Parallel Query for SELECT | 지원됨 (5.7 2.09.2~) | 지원됨 (9.6 ~) | |
| Default Transaction Isolation | REPEATABLE READ | READ COMMITTED | |
| 테이블 기본 구성 인덱스 | CLUSTERD INDEX | NON-CLUSTERED INDEX |
성능 개선의 key가 될 수 있는 두 항목이 보이는데요, 바로 ‘Join’과 ‘Parallel query’ 기능입니다. MySQL 8.0에서 정식 지원되는 hash join, parallel query 기능이 저희가 사용하는 Aurora MySQL 5.7 버전에서 일부(또는 조금 다른 방식으로) 지원 되지만, 그마저도 지원불가 조건에 포함되어 활용이 쉽지 않았습니다. 반면 PostgreSQL은 오래전부터(9버전~) 대부분의 select쿼리에서 parallel 기능이 지원되고 있고 다양한 join 방식을 지원하기 때문에 개선이 필요한 정산 쿼리의 성능적인 이점을 기대해 볼 수 있을 것 같습니다.
성능비교
1. 단순 CRUD 쿼리
예상했던 대로 MySQL이 성능결과가 좋았습니다. 앞서 보신 기능비교 내용처럼 PostgreSQL는 Update시 MySQL과 조금 다른 방식으로 처리되는데요, 변경 전 값을 삭제마크처리 후 변경 후 값을 새 행으로 추가하는 방식으로 작업이 진행됩니다. 이런 구조가 성능차이의 큰 요인으로 작용하는 걸로 보입니다. 그래서 PostgreSQL은 보통 Insert, Select 위주의 서비스에 사용하는 것이 선호되고 있습니다. 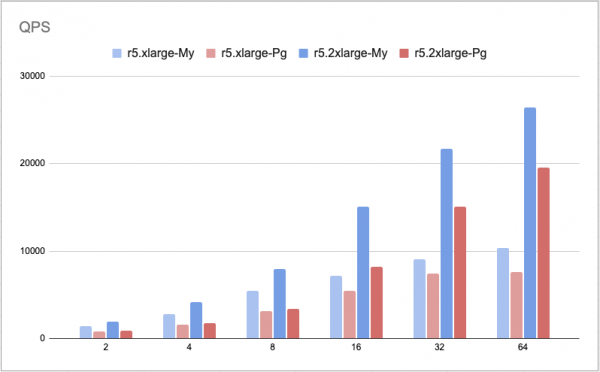
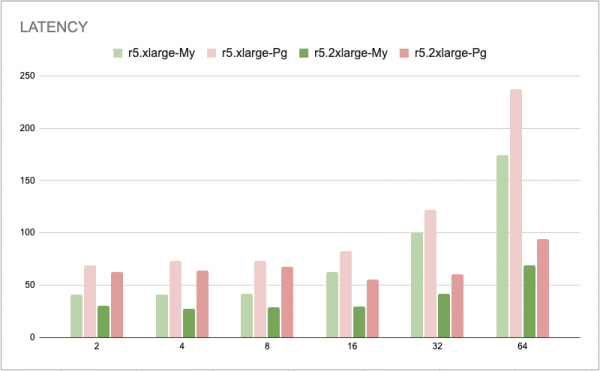
테스트 환경
> Engine Version
MySQL: 5.7.mysql_aurora.2.09.2
PostgreSQL : Aurora PostgreSQL 11.9
> Instance Class
r5.xlarge - r5.2xlarge
> sysbench (qps, latency 테스트)
버전 : sysbench 1.0.15 tpcc
스레드 : 2, 4, 8, 16, 24, 32, 64 개로 단계적으로 늘림
데이터 : 10tables, 100scale -> 약 90GB
2. 복잡한 쿼리
1000만 건 데이터의 조인쿼리를 HASH JOIN으로 비교 실행해 보았습니다.
Aurora MySQL에서는 22초 정도 소요된 반면 Aurora PostgreSQL에서는 3초로 7배 이상 빠른 속도를 보여 주었습니다. Aurora MySQL의 일반적인 방식인 Nested loop Join을 선택하는 경우라면 이보다 훨씬 늦어지겠죠. (r5.2xlarge에서 실행 시 2시간 이상 소요)
데이터 세팅
(MySQL)
-- 테이블 생성
mysql> create table users (
id int auto_increment primary key,
id2 int,
Name varchar(100),
Address varchar(512)
);
-- 데이터 INSERT
mysql> insert into users(id2,Name,Address)
select floor(1 + rand() * 50000000),
A.table_name,A.table_name
from information_schema.tables A
cross join information_schema.tables B
cross join information_schema.tables C
cross join information_schema.tables D
limit 10000000;(PostgreSQL)
데이터 INSERT: 동일한 데이터 세팅을 위해 DMS로 데이터를 이관
데이터 조회
(MySQL)
-- hash join 기능 활성화
mysql> SET optimizer_switch='hash_join=on';
Query OK, 0 rows affected (0.02 sec)
-- hash join으로 실행계획이 풀리는 것을 확인
mysql> explain select count(*) from users A inner join users B ON A.id2=B.id2;
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------------------------------------------------+
| 1 | SIMPLE | A | NULL | ALL | NULL | NULL | NULL | NULL | 9757959 | 100.00 | NULL |
| 1 | SIMPLE | B | NULL | ALL | NULL | NULL | NULL | NULL | 9757959 | 10.00 | Using where; Using join buffer (Hash Join Outer table B) |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------------------------------------------------+
2 rows in set, 1 warning (0.03 sec)
-- 22초 소요
select count(*) from users A inner join users B ON A.id2=B.id2;
+----------+
| count(*) |
+----------+
| 18334934 |
+----------+
1 row in set (22.16 sec)(PostgreSQL)
\timing on
-- 이관 된 스키마 확인
psql=> \d users
Table "bm_ord.users"
Column | Type | Collation | Nullable | Default
---------+------------------------+-----------+----------+---------
id | integer | | not null |
id2 | integer | | |
Name | character varying(100) | | |
Address | character varying(512) | | |
Indexes:
"users_pkey" PRIMARY KEY, btree (id)
-- parallel & Hash join 으로 실행계획이 풀리는 것을 확인
psql=> explain select count(*) from users A inner join users B ON A.id2=B.id2;
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=478253.80..478253.81 rows=1 width=8)
-> Gather (cost=478253.59..478253.80 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=477253.59..477253.60 rows=1 width=8)
-> Parallel Hash Join (cost=208305.82..458902.79 rows=7340320 width=0)
Hash Cond: (a.id2 = b.id2)
-> Parallel Seq Scan on users2 a (cost=0.00..140018.03 rows=4162303 width=4)
-> Parallel Hash (cost=140018.03..140018.03 rows=4162303 width=4)
-> Parallel Seq Scan on users2 b (cost=0.00..140018.03 rows=4162303 width=4)
-- 3초 소요
psql=> select count(*) from users A inner join users B ON A.id2=B.id2;
count
----------
18334934
(1 row)
Time: 3146.135 ms (00:03.146)
3. PostgreSQL의 Partial Index
PostgreSQL에는 전체 데이터의 부분집합에 대해서만 인덱스를 생성하는 Partial Index라는 기능이 있습니다. 특정 범위에 대해서만 인덱싱을 할 수 있기 때문에 특히 대량 데이터의 일부 값에 대해 인덱스를 생성할 경우, 인덱스 크기도 작고 관리하는 리소스도 줄일 수 있는 이점이 있습니다. 이런 Partial Index와 MySQL의 일반 B-tree인덱스에 대한 조회속도에도 차이가 있을지 확인해 보았습니다.
데이터 세팅
(MySQL)
-- 테이블 생성
mysql> create table t_coupon
(id bigint auto_increment primary key
,coupon_id varchar(255) comment '쿠폰id'
,use_yn smallint(1) comment '1/0'
,reg_date datetime
,key idx_use_yn (use_yn)
)engine=innodb;
-- 데이터 세팅
mysql> insert into t_coupon_2
select null
, CAST((1000000000000 + (floor(rand() * if(A.DATA_LENGTH = 0,100000,A.DATA_LENGTH )))) AS CHAR)
2)=1,floor(0 + rand() * 2),0),0),0)
, (select case when rand()*100 > 97 then 1 else 0 end)
, A.CREATE_TIME -- ,ifnull(A.CREATE_TIME, now())
from information_schema.tables A
,information_schema.tables B
,information_schema.tables C
,information_schema.tables d
limit 50000000;
-- 데이터 확인
mysql> select count(*) from t_coupon;
+----------+
| count(*) |
+----------+
| 50000000 |
+----------+
mysql> select
sum(case when use_yn = 1 then 1 else 0 end) as use_yn_1
,sum(case when use_yn = 0 then 1 else 0 end) as use_yn_0
from t_coupon;
+----------+----------+
| use_yn_1 | use_yn_0 |
+----------+----------+
| 1500265 | 48499735 | #yn_1는 전체의 3.1% 분포
+----------+----------+(PostgreSQL)
-- 테이블 생성
psql=> create table t_coupon
(id bigserial primary key
,coupon_id varchar(255)
,use_yn int
,reg_date timestamp
);
-- 인덱스 생성
psql=> create index idx_coupon_yn on t_coupon(reg_date) where use_yn = 1;
-- 테이블 확인
psql=> \d t_coupon;
Table "bm_ord.t_coupon"
Column | Type | Collation | Nullable | Default
-----------+-----------------------------+-----------+----------+--------------------------------------
id | bigint | | not null | nextval('t_coupon_id_seq'::regclass)
coupon_id | character varying(255) | | |
use_yn | integer | | |
reg_date | timestamp without time zone | | |
Indexes:
"t_coupon_pkey" PRIMARY KEY, btree (id)
"idx_coupon_yn" btree (reg_date) WHERE use_yn = 1
데이터 INSERT: 동일한 데이터 세팅을 위해 DMS로 데이터를 이관
데이터 조회
조회 시에는 눈에 띄는 속도차이를 보여 주지는 않았습니다.
(MySQL)
-- 실행계획 확인
mysql> explain select count(*) from t_coupon where use_yn=1 and reg_date >='2014-08-16 10:00:00';
+----+-------------+------------+------------+-------+---------------+------------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+------------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | t_coupon | NULL | range | idx_use_yn | idx_use_yn | 9 | NULL | 318024 | 100.00 | Using where; Using index |
+----+-------------+------------+------------+-------+---------------+------------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select count(*) from t_coupon where use_yn=1;
+----+-------------+------------+------------+------+---------------+------------+---------+-------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------------+---------+-------+---------+----------+-------------+
| 1 | SIMPLE | t_coupon | NULL | ref | idx_use_yn | idx_use_yn | 3 | const | 2814296 | 100.00 | Using index |
+----+-------------+------------+------------+------+---------------+------------+---------+-------+---------+----------+-------------+
1 row in set, 1 warning (0.03 sec)
-- 쿠폰 잔여 확인 (0.06초 / 0.29초)
mysql> select count(*) from t_coupon where use_yn=1 and reg_date >='2014-08-16 10:00:00';
+----------+
| count(*) |
+----------+
| 175220 |
+----------+
1 row in set (0.06 sec)
mysql> select count(*) from t_coupon where use_yn=1;
+----------+
| count(*) |
+----------+
| 1500265 |
+----------+
1 row in set (0.29 sec)
(PostgreSQL)
-- 실행계획 확인
psql=> explain select count(*) from t_coupon where use_yn=1 and reg_date >='2014-08-16 10:00:00';
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=5500.01..5500.02 rows=1 width=8)
-> Gather (cost=5499.80..5500.01 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=4499.80..4499.81 rows=1 width=8)
-> Parallel Index Only Scan using idx_coupon_yn on t_coupon (cost=0.43..4325.01 rows=69914 width=0)
Index Cond: (reg_date >= '2014-08-16 10:00:00'::timestamp without time zone)
(6 rows)
Time: 26.672 ms
psql=> explain select count(*) from t_coupon where use_yn=1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=37219.31..37219.32 rows=1 width=8)
-> Gather (cost=37219.09..37219.30 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=36219.09..36219.10 rows=1 width=8)
-> Parallel Index Only Scan using idx_coupon_yn on t_coupon (cost=0.43..34666.37 rows=621088 width=0)
(5 rows)
-- 쿠폰 잔여 확인 (0.06초 / 0.2초)
psql=> \timing on
psql=> select count(*) from t_coupon where use_yn=1 and reg_date >='2014-08-16 10:00:00';
count
--------
175220
(1 row)
Time: 62.897 ms
psql=> select count(*) from t_coupon where use_yn=1;
count
---------
1500265
(1 row)
Time: 238.436 ms
인덱스 크기 확인
Aurora MySQL (755M) < Aurora PostgreSQL (57M)로 10배 정도 인덱스 크기 차이를 보여 줍니다. 필요한 부분만 인덱스를 생성하기 때문에 저장공간에 대한 이점이 아주 크고 나아가 데이터 삭제, 추가, 갱신에 따른 인덱스 유지관리 비용도 절약된다고 볼 수 있겠습니다.
(MySQL)
-- 인덱스 크기
mysql> select table_name,index_name
,round(stat_value*16384/1024/1024) size_in_mb
from mysql.innodb_index_stats
where table_name='t_coupon' and index_name='idx_use_yn' and stat_name='size';
+------------+------------+------------+
| table_name | index_name | size_in_mb |
+------------+------------+------------+
| t_coupon | idx_use_yn | 764 |
+------------+------------+------------+
1 row in set (0.17 sec)(PostgreSQL)
-- 인덱스 크기
psql=> select pg_size_pretty(pg_relation_size('idx_coupon_yn'));
pg_size_pretty
----------------
41 MB
(1 row)4. Secondary Index 생성
Aurora MySQL 5.7 이 되면서 Online ddl의 기능의 범위가 넓어져 좀 살만해(?) 졌다지만 여전히 대량 테이블의 인덱스 생성 및 컬럼 추가 작업은 저희 dba들에게는 부담스러운 작업입니다. 데이터가 많은 만큼 시간소요 예측도 힘들고 (백업데이터로 테스트를 진행하지만 막상 라이브 환경에서는 시간소요가 더 오래 걸리는 경우도 많음) 만약 작업이 실패하는 경우 rollback 작업에 따른 위험도도 크기 때문입니다.
Aurora PostgreSQL에서는 어떻게 작용할지 동일한 환경에서 인덱스 생성 및 컬럼 추가 작업을 진행해 보았습니다. 결과는… 환상적입니다. 약 200G 테이블에 인덱스, 컬럼 추가를 해본 결과 100G만 넘어도 인덱스 생성에 1시간이 넘는 Aurora MySQL과는 다르게 40여 분 만에 인덱스가 생성되었습니다! 컬럼 추가는… 바로 되네요(허허). PostgreSQL의 online ddl 컬럼 추가는 meta data를 저장하는 시스템 카탈로그에 추가된 정보만 반영하기 때문에 아주 빠른 작업이 가능합니다.
(PostgreSQL)
-- 테이블 사이즈 확인
psql=> select pg_total_relation_size('settle_detail');
pg_total_relation_size
------------------------
236,225,634,304 -- 약 220G
(1 row)
-- 인덱스 생성하기
psql=> \timing on
psql=> CREATE INDEX CONCURRENTLY idx_settle_detail_cd_pay_mtd ON settle_detail(modified_date,pay_method);
CREATE INDEX
Time: 2668989.049 ms (44:28.989)
-- 컬럼 추가하기 (바로 됨)
psql=> \timing on
psql=> ALTER TABLE settle_detail add column col1 varchar(10) default'aaa';그 밖의 PostgreSQL의 특징
| 기능 | 특징 |
|---|---|
| SP 생성 | c/c++, Java, JavaScript,.Net, R, Perl, Python, Ruby, Tcl 등 많은 프로그래밍 언어로 SP 생성이 가능하다. |
| PostGIS | geographic object를 지원 가능하다. oracle의 GIS 와 성능이 비견할 정도로 뛰어나다. |
| Vacuum | PostgreSQL은 MVCC를 MGA방식으로 구현한다. 그래서 UPDATE , DELETE시에 물리적으로 공간을 UPDATE하여 사용하지 않고 새로운 영역을 할당하여 사용하게 된다. 즉 이전 공간이 재사용 될 수 없는 dead tuple 상태로 저장공간을 두게 되어서 이러한 현상이 지속될 경우, 공간 부족 및 데이터IO의 비효율을 유발하여 성능저하의 원인이 된다. 때문에 주기적으로 vacuum 기능을 수행하여 재사용 가능하도록 관리해 주어야 한다. |
| Materialized View 지원 | 일반 view와는 다르게 snapshot이라고 불리는 materialized view는 view 생성 시 설정한 조건의 쿼리 결과를 별도의 공간에 저장하고 쿼리가 실행될 때 미리 저장된 결과를 보여주어 성능을 향상시킨다. 실시간 노출 필요성이 적은 통계성 쿼리나, 자주 update 되지 않는 테이블에 생성할 때 성능효과를 볼 수 있다. |
| 상속기능 | 부모테이블을 생성 후 상속기능을 이용해 하위 테이블을 만들 수 있다. – 하위 테이블은 상속받은 부모테이블의 컬럼을 제외한 컬럼만 추가로 생성하면 된다. – 상위 테이블에서 조회 시 기본적으로 하위 테이블의 데이터까지 모두 조회 가능하다. – 데이터 변경 시에도 하위 테이블까지 모두 반영된다. |
| 다양한 사용자 기반 활용 가능 | 연산자, 복합 자료형, 집계함수, 자료형 변환자, 확장 기능 등 다양한 데이터베이스 객체를 사용자가 임의로 만들 수 있는 기능을 제공한다. |
| pg_trgm | trigram매칭을 기반으로 한 모듈로 데이터 간 유사성 파악 및 like %pattern%(3자이상) 인덱스 검색이 가능하다. |
마치며
앞선 내용을 바탕으로 기존에 고민거리였던 복잡한 쿼리의 수행속도 및 대용량 테이블의 관리이슈에 대한 큰 고민을 덜어줄 수 있을 것으로 보고 정산DB를 Aurora PostgreSQL로 이관을 시도해보기로 결정하였습니다. 물론 아직은 테스트 단계이기 때문에 실 서비스 적용 시 예상치 못한 변수가 있을 수 있겠지만 성공 여부를 떠나 의미 있는 시도가 될 것이라 기대합니다. 추후 성공적으로 이관 작업을 마무리 하여 또 좋은 내용으로 기술블로그를 공유드리고 싶네요^^
이상 저의 글을 마치겠습니다. 긴 글 읽어 주셔서 감사합니다.
혹시…
즐기며 일하는 DBA가 로망이신 분 계실까요? 내가 하고 싶은 일을 하며 성장할 수 있는 그런 곳을 찾으시나요? 더 이상 꿈이 아닙니다. 우아한형제들과 함께 하시면 그 꿈 이루실 수 있습니다. 어서 오세요!!! 빨리 오세요!!!
