로그 및 SQL 진입점 정보 추가 여정
안녕하세요, B마트서비스개발팀 박지우입니다. 1월 신규 입사 후 맡게 된 가장 컸던 기술 개선 건으로 로그 및 SQL에 진입점 정보를 남기는 작업을 진행했는데요. 이 작업이 왜 필요한지, 그리고 이 과정에서 겪은 시행착오와 해결 방법은 무엇인지를 중심으로 이야기를 나누려고 합니다.
앞으로 해당 작업을 진행하시는 분들이 같은 난관에 직면할 때, 이 글을 통해 조금이나마 도움을 받을 수 있기를 바라며 글 시작하겠습니다!
진입점이 뭐죠?
‘진입점’은 사용자 요청의 시작점을 의미합니다. 애플리케이션 또는 시스템에서 사용자 요청이 최초 진입되는 지점이 바로 진입점 입니다.
그 중에서도 SQL 진입점은 데이터베이스 시스템으로의 쿼리 전송 시, 애플리케이션 또는 시스템에서 쿼리가 전송된 시작점을 의미합니다.

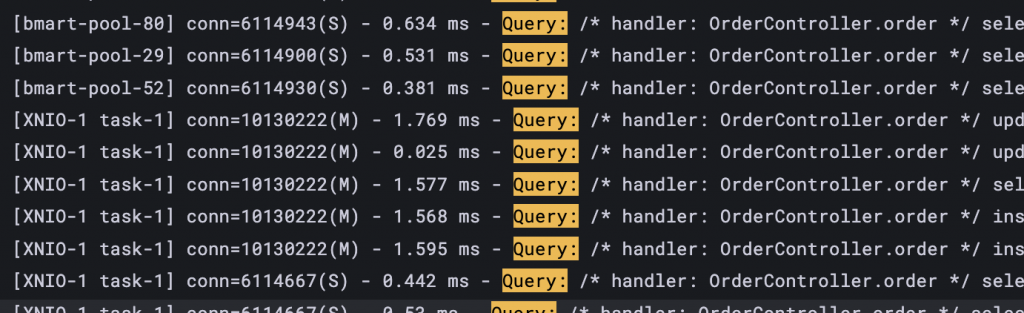
다음은 앱 로그에서 확인되는 쿼리 정보 예시입니다.
/ handler: JiwooController.getShop /
이 부분이 눈에 띄지 않으시나요?
기존에 모든 SQL 요청에 대해 다음 방식으로 진입점 정보를 SQL 로그 주석(/* handler...)으로 남기는 작업을 진행했습니다. 정확히는 컨트롤러+메소드, 이벤트 컨슈머+메소드, 배치 job 이름을 남기게 되었습니다.
초기 세팅부터, 추가적인 고려 사항들까지 포함한 전환 과정을 공유하고자 합니다.
근데 왜 진입점 정보가 남아야 해요?
모든 SQL 요청마다 진입점 정보가 남는다면 다음과 같은 큰 이점을 누릴 수 있습니다.
1) 성능 최적화
특정 진입점에서 발생하는 과도한 데이터베이스 액세스나 비효율적인 쿼리를 식별하는 데 도움이 됩니다.
DBA분들이 제공한 slow query 목록이 있습니다. Grafana 운영 DB의 MySQL Overview에서 slow query 리스트를 확인할 수도 있습니다. 하지만 각 쿼리가 어디서 실행됐는지는 직접 코드에서 확인이 필요합니다. SQL문 마다 진입점 위치를 알 수 있다면 개선 작업이 훨씬 빨라집니다.
2) 추적성
문제가 발생했을 때 어떤 진입점에서 해당 SQL 요청이 발생했는지 쉽게 파악할 수 있습니다. 이로써 디버깅 시간을 줄일 수 있습니다. 예를 들어 데드락 발생 시 최초 컨트롤러 위치를 안다면 더 빠른 해소가 가능할 겁니다.
또한 어떤 컨트롤러나 이벤트 컨슈머 진입점에서 DB 리소스를 가장 많이 사용하는지 분석도 가능하고, 어떤 진입점이 데이터베이스를 얼마나 자주 사용하는지, 어떤 시간대에 가장 활발한지 등의 패턴을 파악하는 데에 도움이 됩니다. 의심스러운 쿼리나 예상치 못한 접근이 있을 때 어느 모듈, 어느 진입점에서 발생했는지 역시 확인할 수 있습니다.
3) 심미성
아름답죠?
MDC를 아시나요?
그렇다면 로그에 왜 진입점 정보가 제대로 남지 않았을까요? 이번 작업을 통해 저 역시 MDC라는 개념을 처음 알게 되었습니다. 이에 대한 사전 지식을 먼저 공유하고자 합니다.
1. MDC(Mapped Diagnostic Context)
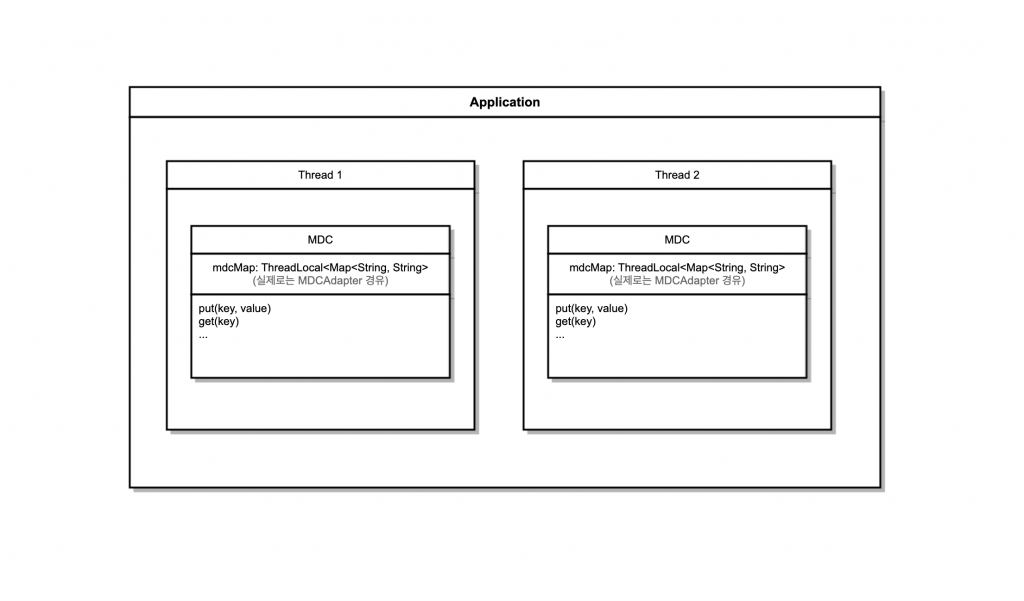
MDC(Mapped Diagnostic Context)는 자바 로깅 프레임워크(slf4j 등)에서 지원하는, 현재 실행중인 쓰레드 단위에 메타 정보를 넣고 관리하는 공간입니다. MDC라는 이름처럼 Map 형태라 (Key, Value) 형태로 값을 저장합니다. 또한 각 스레드는 자체 MDC를 가지기 위해 threadLocal 로 구현되어 있습니다. 동일한 logger를 사용하더라도 로깅한 메시지는 스레드마다 다른 context(MDC) 정보를 가지게 되는 것이죠.
사실 SQL 진입점 정보를 넣는 방법은 다양합니다. 그 중 MDC를 SQL 진입점 정보를 넣기로 결정한 것은, 모든 로그에 이 로그를 남기게된 호출의 진입점 정보를 남기기 위함입니다. MDC로 로그에 진입점 정보를 남기고, SQL에도 MDC 속 값을 꺼내 진입점 정보를 함께 남긴다면 로그부터 SQL까지 모두 진입점 정보를 쉽게 확인할 수 있는 구조로 확장이 가능합니다. 이에 SQL 진입점 정보를 넣는 공간으로 MDC를 선택했습니다.
MDC에 SQL 진입점 정보를 저장하기 위해선 로그와 SQL 진입점에 진입점 정보를 남기기 위한 MDC 설정이 이뤄져야 합니다. 로그에 진입점 정보가 남기 위해서는 다음 두 작업이 필요합니다(간략한 예시).
1) 진입점의 각 메소드 실행 시, 진입점 정보를 추가한다.
MDC.put("handler", controllerInfo);2) 스레드 변경 시 진입점 정보를 복사한다.
Map<String, String> contextMap = MDC.getCopyOfContextMap();
MDC.setContextMap(contextMap);기본 작업
즉 SQL에 진입점 정보를 포함하고 싶다면 다음 3가지 작업이 필요합니다.
- 진입점에 들어올 때 MDC.put으로 진입점 정보를 저장한다.
- 스레드 전환 시 MDC의 정보를 복사한다.
- 각 DB 접근 기술별로 SQL에 진입점 정보를 추가하도록 세팅한다.
1. 진입점 정보 저장
우선 팀 내에 이미 있었던, SQL 진입점 설정을 위한 기본 세팅에 대해 먼저 공유 드리겠습니다. 우선 1의 진입점 정보를 저장하는 방법은 다음과 같습니다.
@Slf4j
public class MdcLoggingInterceptor implements HandlerInterceptor {
public static final String REQUEST_CONTROLLER_MDC_KEY = "handler";
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
if (handler instanceof HandlerMethod) {
HandlerMethod handlerMethod = (HandlerMethod) handler;
String handlerName = handlerMethod.getBeanType().getSimpleName();
String methodName = handlerMethod.getMethod().getName();
String controllerInfo =
handlerName + "." + methodName;
MDC.put(REQUEST_CONTROLLER_MDC_KEY, controllerInfo);
}
return true;
}
/**
* MDC에 저장된 정보를 모두 초기화 한다.
*/
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
MDC.clear();
}
}
/**
* 위의 MDC에 저장된 정보를 모두 초기화하는 MdcLoggingInterceptor() 인터셉터를 WebMvcConfiguration에 추가한다.
*/
@Configuration
public class WebMvcConfiguration implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MdcLoggingInterceptor());
}
}위의 코드에서 HandlerInterceptor 를 통해, MVCController 호출 시마다 MDC에 진입점 정보가 저장됩니다. 인터셉터 안에서는 핸들러 실행 전(preHandle), 핸들러와 핸들러 메소드 이름을 추출해 MDC handler 키의 값으로 저장합니다.
예를 들어 testController 클래스의 search() 메소드가 실행되었다면 MDC 내 진입점 정보는 ("handler", "testController.search")로 저장됩니다.
2. 스레드 전환 시 진입점 정보 복제
다음으로 ‘2. 스레드 전환 시 MDC의 정보 복제’가 필요합니다. 스레드가 전환될 때 기본적으로 MDC 정보가 자동으로 복제되지 않기 때문입니다.
이때 스레드풀 내에서는 taskDecorator를 사용할 수 있습니다.
해당 taskDecorator는 Spring의 ThreadPoolTaskExecutor 에서 제공해주는 기능으로, 스레드 풀에서 실행되는 각 태스크를 래핑하는 데 사용됩니다. 이를 사용하여 실행되는 태스크에 대해 threadLocal 내 정보를 복제하는 등의 커스텀 로직을 적용할 수 있습니다.
@Bean
public ThreadPoolTaskExecutor asyncThreadPoolTaskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.set...
taskExecutor.setTaskDecorator(new MDCCopyTaskDecorator());// 이곳에서 복제가 이뤄집니다.
return taskExecutor;
}위의 코드에서 컨텍스트 복제가 이뤄지는 부분은 MDCCopyTaskDecorator 입니다.
해당 클래스는 다음과 같이 짜여 있습니다.
public class MDCCopyTaskDecorator implements TaskDecorator {
@Override
public Runnable decorate(Runnable runnable) {
Map<String, String> contextMap = MDC.getCopyOfContextMap();
return () -> {
try {
if (contextMap != null) {
MDC.setContextMap(contextMap);
}
runnable.run();
} finally {
MDC.clear();
}
};
}
}
decorate 메소드는 말 그대로 데코레이터 패턴이 사용되었습니다. MDC.getCopyOfContextMap()으로 이전 스레드의 MDC Map 정보를 가져오고, 전환된 스레드에 해당 Map 정보를 그대로 세팅해주는 방식입니다.
해당 taskDecorator는 Spring의 ThreadPoolTaskExecutor 내에서 다음과 같이, execute 실행 시점에 decorate로 적용하도록 구현되어 있습니다.
public class ThreadPoolTaskExecutor {
...
@Override
protected ExecutorService initializeExecutor(
ThreadFactory threadFactory, RejectedExecutionHandler rejectedExecutionHandler) {
BlockingQueue<Runnable> queue = createQueue(this.queueCapacity);
if (this.taskDecorator != null) {
executor = new ThreadPoolExecutor(
this.corePoolSize, this.maxPoolSize, this.keepAliveSeconds, TimeUnit.SECONDS,
queue, threadFactory, rejectedExecutionHandler) {
@Override
public void execute(Runnable command) {
Runnable decorated = taskDecorator.decorate(command);
if (decorated != command) {
decoratedTaskMap.put(decorated, command);
}
super.execute(decorated);
}
};
}
...
}
}
3. DB 접근 시 SQL에 진입점 정보 추가 세팅
또한 DB 접근 시점에, SQL문에 진입점 정보를 추가하도록 세팅이 필요합니다. Spring Data JPA를 사용하고 있기 때문에, 하이버네이트에 세팅하는 인터셉터인 EmptyInterceptor 인터페이스를 상속받아 진입점 정보를 추가하는 인터셉터를 만들었습니다. 여기서 EmptyInterceptor는 인터셉트를 원하는 메소드만을 오버라이드할 수 있습니다. 여기서 onPrepareStatement의 SQL 문자열을 가져와 진입점을 추가했습니다.
public class MDCRequestHandlerCommentInterceptor extends EmptyInterceptor {
private final transient MDCHandlerCommentAppender mdcRequestHandlerCommentAppender;
public MDCRequestHandlerCommentInterceptor() {
this(Set.of("handler", "consumer", "batch"));
}
public MDCRequestHandlerCommentInterceptor(Set<String> handlerKeys) {
Preconditions.checkArgument(!CollectionUtils.isEmpty(handlerKeys), "handlerKeys는 null 혹은 empty 이면 안됩니다.");
this.mdcRequestHandlerCommentAppender = new MDCHandlerCommentAppender(handlerKeys);
}
@Override
public String onPrepareStatement(String sql) {
return mdcRequestHandlerCommentAppender.appendHandlerName(sql);
}
}그리고 SQL문 문자열에 직접 진입점 정보를 추가해준 MDCHandlerCommentAppender 클래스는 아래와 같이 구현되어 있습니다.
public class MDCHandlerCommentAppender {
public static final Set<String> HANDLER_MDC_KEYS = Set.of("handler", "consumer", "batch");
private final Set<String> handlerKeys; //Controller 혹은 Consumer 를 나타내는 handler 값을 저장할 MDC key 들. 이 중에서 값이 존재하는 하나만 사용하게 됩니다.
public MDCHandlerCommentAppender() {
this(HANDLER_MDC_KEYS);
}
public MDCHandlerCommentAppender(Set<String> handlerKeys) {
Preconditions.checkArgument(!CollectionUtils.isEmpty(handlerKeys), "handlerKeys는 null 혹은 empty 이면 안됩니다.");
this.handlerKeys = handlerKeys;
}
public String appendHandlerName(String sql) {
final Optional<String> handlerMdcValue = readHandlerMdcValue();
if (handlerMdcValue.isEmpty()) {
return sql;
}
if (StringUtils.isBlank(handlerMdcValue.get())) {
return sql;
}
return buildSqlWithHandlerInfo(sql, refinedHandlerMdcValue);
}
private Optional<String> readHandlerMdcValue() {
return handlerKeys.stream()
.map(MDC::get)
.filter(Objects::nonNull)
.filter(not(String::isBlank))
.findFirst();
}
private String buildSqlWithHandlerInfo(String sql, String refinedHandlerMdcValue) {
return "/* handler: " + refinedHandlerMdcValue + " */ " + sql;
}
}코드를 보면 알 수 있듯, handler 키의 값이 존재하는지, 그리고 그 값이 빈 값이 아닌지를 체크한 후, SQL문에 진입점 정보를 추가해주는 방식입니다.
해당 인터셉터는 DB 설정의 yml 파일 내에서 다음과 같이 직접 지정해야 합니다.
spring.jpa.properties.session_factory.interceptor: fqcn(전체 패키지).MDCRequestHandlerCommentInterceptor이를 통해 JPA를 경유하는 SQL문의 경우 진입점 정보를 추가할 수 있습니다!
추가 작업
위의 세 단계를 통해, 진입점에서 하이버네이트로 들어오는 SQL에 진입점 정보를 포함해 로그로 남길 수 있습니다.
하지만 위의 작업에는 추가적인 고려가 필요한 작업들이 빠져있습니다. 기본 설정 이후에도 모든 SQL 로그에 진입점 정보가 남도록 추가 설정하는 법을 소개해드리겠습니다.
1. 진입점 정보가 저장되도록 추가 설정
우리는 위에서 진입점에 들어올 때 MDC.put으로 진입점 정보를 저장하도록 세팅했습니다.
다만 전수 조사한 결과 해당 설정이 적용되지 않는 케이스가 몇 군데 있었습니다.
아래는 그러한 케이스들입니다.
– Spring Web MVC 모듈의 Interceptor 설정 추가
팀의 프로젝트는 멀티 모듈 구조로 되어 있으며, 총 10개의 모듈로 구성되어 있습니다. 그 중 일부 모듈에서는 MVCController를 사용하고 있지만, Interceptor 등록이 누락된 경우가 발견되었습니다.
@Configuration
public class WebMvcConfiguration implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MdcLoggingInterceptor());
}
}WebMvcConfiguration 이 모듈 별로 있다 보니 빼먹은 부분이 있었던 거죠. 다음 코드와 같이 설정을 추가하니 진입점 정보가 남는 것이 확인되었습니다.
또한 아예 WebMvcConfiguration 세팅 자체가 안 되어있는 부분도 있어 해당 모듈에선 새 WebMvcConfiguration을 등록했습니다. 작업 시 모듈별 인터셉터 설정이 모두 되었는지 유의하시기 바랍니다.
– Event Consumer, Batch 모듈에 Logging Aspect 설정 추가
이외에도 진입점 정보가 저장되지 않는 케이스로는 이벤트 컨슈머, 배치 쪽이 있습니다. 지금까지의 작업은 MVCController, 즉 Spring Web MVC의 컨텍스트에서만 작동하기 때문입니다!
즉, 해당 작업으론 Event Consumer(SQS, Kafka 등), 스케쥴러나 Batch 등 Spring Web MVC의 범위 밖에서 기대한대로 동작하지 않습니다. 둘의 프로세스에서의 실행 흐름과 생명주기는 MVCController와는 다르기 때문에 추가 설정이 필요한 것이죠. 이에 AOP를 적용해 설정을 추가해줬습니다.
1) Event Consumer 모듈
@Aspect
@Component
@Slf4j
public class ConsumerLoggingAspect {
// MDC 키 값으로 "consumer"를 사용
public static final String CONSUMER_MDC_KEY = "consumer";
// @SqsListener 어노테이션이 붙은 메소드 실행 시 아래의 코드가 수행됩니다.
@Before("(@annotation(org.springframework.cloud.aws.messaging.listener.annotation.SqsListener))") //Spring Cloud AWS 2.2.x 이하
@Before("(@annotation(io.awspring.cloud.messaging.listener.annotation.SqsListener))") //Spring Cloud AWS 2.3.0 이후
public void beforeConsumeSqs(JoinPoint joinPoint) {
putMDC(joinPoint);
}
// @KafkaListener 어노테이션이 붙은 메소드 실행 시 아래의 코드가 수행됩니다.
@Before("(@annotation(org.springframework.kafka.annotation.KafkaListener))")
public void beforeConsumeKafka(JoinPoint joinPoint) {
putMDC(joinPoint);
}
// @Scheduled 어노테이션이 붙은 메소드 실행 시 아래의 코드가 수행됩니다.
@Before("(@annotation(org.springframework.scheduling.annotation.Scheduled))")
public void beforeSchedule(JoinPoint joinPoint) {
putMDC(joinPoint);
}
private void putMDC(JoinPoint joinPoint) {
Method method = ((MethodSignature) joinPoint.getSignature()).getMethod();
String consumerInfo =
joinPoint.getTarget().getClass().getSimpleName() + "." + method.getName();
MDC.put(CONSUMER_MDC_KEY, consumerInfo);
}
// @SqsListener 어노테이션이 붙은 메소드 실행 후 아래의 코드가 수행됩니다.
@After("@annotation(org.springframework.cloud.aws.messaging.listener.annotation.SqsListener))") //Spring Cloud AWS 2.2.x 이하
@After("@annotation(io.awspring.cloud.messaging.listener.annotation.SqsListener))") //Spring Cloud AWS 2.3.0 이후
public void afterConsumeSqs(JoinPoint joinPoint) {
clearMDC();
}
// MDC 내 이벤트 컨슈머 진입점 정보가 초기화됩니다.
private void clearMDC() {
MDC.clear();
}
// @KafkaListener 어노테이션이 붙은 메소드 실행 후 아래의 코드가 수행됩니다.
@After("(@annotation(org.springframework.kafka.annotation.KafkaListener))")
public void afterConsumeKafka(JoinPoint joinPoint) {
clearMDC();
}
// @Scheduled 어노테이션이 붙은 메소드 실행 후 아래의 코드가 수행됩니다.
@After("(@annotation(org.springframework.scheduling.annotation.Scheduled))")
public void afterSchedule(JoinPoint joinPoint) {
clearMDC();
}
}
팀 내에서는 Consumer 모듈에서 Amazon SQS, Kafka, Spring Scheduler 기술을 사용하고 있습니다. 이에 따라 SQL 진입점 종류는 총 세 가지로, @SqsListener, @KafkaListener, 그리고 @Scheduled 어노테이션을 통해 구분됩니다. 위의 코드와 같이, 세 어노테이션을 포함한 지점들을 진입점으로 판단해, 해당 부분에 AOP 설정을 적용했습니다.
2) Batch 모듈
Spring Batch의 경우 역시, 각각의 Job에 따라 SQL 진입점이 달라집니다. 이를 관리하기 위해 Batch 모듈에도 AOP를 통해 MDC에 진입점 정보를 추가했습니다.
@Aspect
@Component
public class BatchLoggingAspect {
// MDC 키 값으로 "batch"를 사용
public static final String BATCH_MDC_KEY = "batch";
// 스프링 배치의 JobLauncher.run(..) 메소드 실행 시 아래의 코드가 수행됩니다.
@Around("execution(* org.springframework.batch.core.launch.JobLauncher.run(..))")
public Object putMDC(ProceedingJoinPoint joinPoint) throws Throwable {
final Object[] args = joinPoint.getArgs();
final Job job = (Job) args[0]; // 메소드의 첫 번째 인자는 Job의 인스턴스입니다.
MDC.put(BATCH_MDC_KEY, job.getName());
return joinPoint.proceed();
}
}위 코드는 스프링 배치에서 실행되는 각 Job마다 해당 Job의 이름을 로깅하는 설정입니다. BatchLoggingAspect라는 Aspect 클래스를 만들었습니다. 또한 포인트컷 표현식을 통해, 스프링 배치의 JobLauncher.run(..) 메소드 실행 전후를 타겟으로 설정했는데요. 모든 Job의 시작 지점이 해당 메소드이기 때문입니다.
팀 내 배치는 배치 마다 새로운 프로세스로 실행하기 때문에, 이벤트 컨슈머와는 다르게 별도로 MDC.clear() 작업을 추가하지 않았습니다. 만약 하나의 프로세스에서 스레드를 공유하면서 사용하는 구조라면 MDC 초기화 작업이 필요합니다.
– Batch에 @JobScope, @StepScope 설정 추가
Batch 작업 로깅 설정이 완료된 후, 결과 로그를 Grafana에서 확인하였습니다. 예상과 달리 절반 이상의 사용자 요청에 대한 진입점이 SQL에 기록되지 않는 현상을 발견했습니다. 여기엔 여러 이유가 있었는데요. 주요 원인 중 하나는 빈 스코프 설정의 누락 과 관련되어 있었습니다.
Spring Batch 에서는 Job과 Step의 실행 동안 생성되는 빈의 수명주기를 관리하기 위한 @JobScope와 @StepScope 어노테이션이 제공됩니다. @JobScope는 Job이 시작될 때 빈이 생성되고, Job이 끝날 때 빈이 소멸됩니다. @StepScope는 마찬가지로 step의 생명주기를 따릅니다.
@Bean
public ItemReader<A> AReader() {
Iterator<A> iterator = ARepository.getA().iterator(); // 생성 시점에 sql문 호출
return () -> {
if (iterator.hasNext()) {
return iterator.next();
}
return null;
};
}그런데 팀 내 배치 중 Reader의 빈 생성 시점에 sql문이 만들어지고 있으며 빈 스코프 지정이 안 된 경우가 있었습니다. 이때 Reader 빈은 특별한 스코프 어노테이션이 없기 때문에, ApplicationContext가 시작될 때 생성됩니다. 따라서 Job이 시작되기 전에 DB 접근이 이뤄집니다.
JobLauncher.run() 실행 이전에 빈이 만들어지고, 위 코드에서는 빈이 만들어질 때 DB에 SQL문이 날아갈테니 당연히 MDC에 Batch job 이름이 들어갈 리 없습니다.
따라서 현재 상황에서 JobLauncher.run() 시점에 추가한 Job 이름 정보가 SQL에 추가되려면 DB에 접근하는 모든 시점의 빈 스코프가 최소 @JobScope 이상이어야 합니다. 그렇지 않으면, MDC 설정이 완료되기 전에 Bean이 생성되면서 SQL 쿼리가 실행될 수 있습니다.
다만, reader, writer, processor bean 초기화 시 bean 생성 시점의 쿼리는 MDC 로그가 남지 않지만, 구현체 안에서 실행되는 실제 객체(…service)는 MDC 로그가 잘 남습니다. 이는 구현체 내부의 로직이 MDC 설정 후, 즉 JobLauncher.run() 후 실행되기 때문입니다. 따라서 구현체 내에서의 로직은 MDC 설정이 완료된 상태에서 SQL 쿼리가 실행되기 때문에, 해당 로그에는 MDC 정보가 정상적으로 남게 됩니다.
요약하자면, 아래 @Bean, @Component 등을 통한 빈 생성시 bean 객체 생성 시점에 남기는 SQL 로그를 보고 싶다면 bean 스코프 지정이 필요합니다. 이에 Job 설정 안에서 DB 호출 지점이지만 bean 스코프가 정의되지 않은 경우 다음과 같이 스코프를 추가 정의했습니다.
- @JobScope : step
- @StepScope : reader, writer, processor, tasklet
2. MDC 정보의 복제를 위한 추가 설정
사실 위에서 설정해줬던 taskDecorator 는 스레드풀 그중, Spring의 threadPoolTaskExecutor 에서만 적용 가능합니다. 따라서 이외의 스레드 전환 상황에 대해서도 설정이 필요합니다.
그렇다면 어떤 상황에서 스레드가 전환될까요? 다음과 같은 케이스를 생각해볼 수 있습니다!
- 스레드풀 : java ExecutorService 등
- 비동기 작업 : Executor, ForkJoinPool 등
- Java의 Future와 CompletableFuture
- 스케쥴러 작업
- Reactive 프로그래밍 : Reactor 등
- 요청마다 새로운 스레드나 재사용되는 스레드를 사용하는 서버
- 캐시 : Caffeine 등
그리고 전수 조사한 결과 해당 설정이 적용될 수 없는 다양한 케이스를 마주하게 되었습니다.
– taskDecorator 미설정된 부분 추가 설정
우선 threadPoolTaskExecutor 사용처 중 taskDecorator이 설정되지 않은 경우가 있었습니다. threadPoolTaskExecutor를 검색해 추가 설정만 하는 간단한 작업이었습니다. 이외에도 taskExecutor 중 threadPoolTaskExecutor로 변환이 쉽게 가능한 케이스는 전부 변경했습니다.
taskExecutor.setTaskDecorator(new MDCCopyTaskDecorator());문제는 ExecuteService 였습니다.
– ExecuteService 에서 TaskExecutor로

다음은 Executor 구조 UML입니다. (주요 메소드만 표시한 약식 UML이니 가볍게 봐주세요!)
방금 본 세팅은 말씀드렸듯 ThreadPoolTaskExecutor에서만 적용 가능합니다. 스레드풀은 대체로 Executor 인터페이스를 기반으로 합니다. 그리고 일반적으로 java.util의 ExecutorService나 Spring core의 TaskExecutor 중 하나를 기본 스레드풀로 선택하여 사용하는 경우가 많습니다.
그리고 ThreadPoolTaskExecutor은 TaskExecutor를 상속받은 구현체입니다.
따라서, ExecuteService를 사용하는 경우, MDC 정보를 복제하는 것이 기본적으로 불가능하다는 점을 알아두셔야 합니다~!
물론 방법은 있습니다. 데코레이터 패턴을 이용해 우리만의 CustomExecutorService를 만드는 겁니다.
public class CustomExecutorService implements ExecutorService {
@Override
public void execute(@NonNull Runnable command) {
Runnable decorate = taskDecorator.decorate(command);
executorService.execute(decorate);
}
//...이외 모든 ExecutorService 메소드들에 적용하면 됩니다.
}위의 CustomExecutorService는 ExecutorService의 모든 메소드를 오버라이드하여 TaskDecorator를 적용하게 됩니다. 처음에는 이러한 방식으로 구현했습니다.
하지만 팀 내 스레드풀 설정이 ExecutorService와 ThreadPoolTaskExecutor로 혼용되어 있는 것보단 기존의 ExecutorService를 ThreadPoolTaskExecutor로 대체하는 편이 좋지 않겠냐는 코드 리뷰를 받게 되었습니다. CustomExecutorService를 쓸 시 앞으로 코드 관리 포인트가 증가할 것도 이유였습니다.
이에 기존의 ExecutorService를 모두 ThreadPoolTaskExecutor로 전환하는 작업을 진행하게 되었습니다. 이쯤 되니 SQL 진입점이 문제가 아니고, 스레드풀 전체를 건드려야 하는 일이 되었습니다🤔
팀에선 다음과 같은 ExecutorService가 bean으로 등록되어 있었습니다.
ExecutorService executorService = Executors.newFixedThreadPool(corePoolSize);
ExecutorService executorService = new DelegatingSecurityContextExecutorService(Executors.newFixedThreadPool(corePoolSize));
ExecutorService executorService = Executors.newScheduledThreadPool(taskPoolSize);이 부분은 Executors에서 제공하는 각 스레드풀 픽스쳐 설정을 비교해 동일하게 세팅했습니다. 해당 세팅 시 적정 corePoolSize, QueueCapacity, MaxPoolSize 등을 함께 고민하고, 스레드 덤프 분석을 통해 재세팅 진행했습니다.
@Bean(name = "bmartTaskExecutor") //= newFixedThreadPool()
public ThreadPoolTaskExecutor bmartTaskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(corePoolSize);
//...스레드풀 세팅
taskExecutor.setTaskDecorator(new MDCCopyTaskDecorator());
return taskExecutor;
}
/**
* DelegatingSecurityContextAsyncTaskExecutor는 Spring에서 지원하는 클래스입니다.
* 멀티 스레드 환경에서 Spring Security를 사용할 수 있는 저수준 추상화를 제공하는 클래스입니다.
* 스레드풀 세팅은 bmartTaskExecutor와 동일합니다.
*/
@Bean//= DelegatingSecurityContextExecutorService()
public DelegatingSecurityContextAsyncTaskExecutor securityContextAsyncTaskExecutor(ThreadPoolTaskExecutor bmartTaskExecutor) {
return new DelegatingSecurityContextAsyncTaskExecutor(bmartTaskExecutor);
}
@Bean(name = "scheduled")
public TaskScheduler scheduled() {
ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();
//...스레드풀 세팅
return new DelegatingMDCTaskScheduler(scheduler);
}여기서 DelegatingSecurityContextAsyncTaskExecutor는 Spring에서 지원하는 클래스로, 기존의 DelegatingSecurityContextExecutorService와 동일하게 구동됩니다.
반면 TaskScheduler는 taskDecorator 적용이 불가능합니다! 위의 ExecutorService와 동일한 이유입니다.
이에 DelegatingMDCTaskScheduler을 데코레이터 패턴으로 직접 구현했습니다. 이때 기존 taskDecorator 구현 방식과 달리 AbstractDelegatingMDCSupport를 추가했습니다.
구조는 다음과 같습니다.

또한 코드는 다음과 같습니다.
public class DelegatingMDCTaskScheduler extends AbstractDelegatingMDCSupport implements TaskScheduler {
private final TaskScheduler delegate;
public DelegatingMDCTaskScheduler(TaskScheduler delegate) {
this.delegate = delegate;
}
@Override
public ScheduledFuture<?> schedule(Runnable task, Trigger trigger) {
return delegate.schedule(wrap(task), trigger);
}
}
public abstract class AbstractDelegatingMDCSupport {
protected final Runnable wrap(Runnable delegate) {
Map<String, String> contextMap = MDC.getCopyOfContextMap();
return () -> {
try {
if (contextMap != null) {
MDC.setContextMap(contextMap);
}
delegate.run();
} finally {
MDC.clear();
}
};
}
protected final <T> Callable<T> wrap(Callable<T> delegate) {
Map<String, String> contextMap = MDC.getCopyOfContextMap();
return () -> {
try {
if (contextMap != null) {
MDC.setContextMap(contextMap);
}
return delegate.call();
} finally {
MDC.clear();
}
};
}
}
여기서 AbstractDelegatingMDCSupport 클래스가 추가되었는데요.
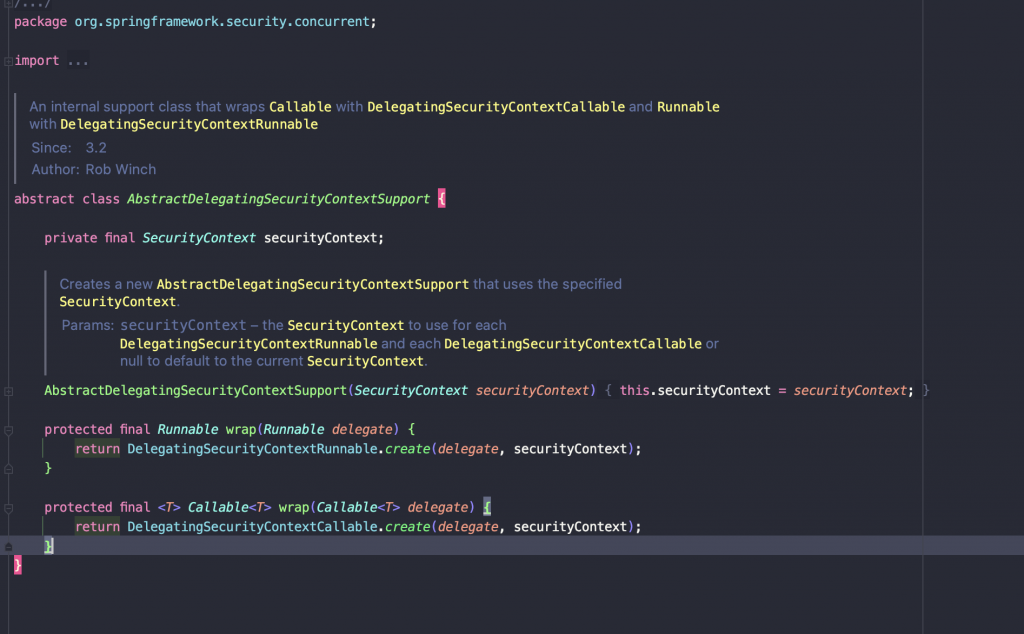
중간에 AbstractDelegatingMDCSupport를 둔 구현 방향은 Spring Security의 AbstractDelegatingSecurityContextSupport의 방식을 참고했습니다.
– Caffeine 캐시 사용처 추가 설정
이외에도 Caffeine 캐시 사용처 중 스레드풀 설정이 추가적으로 필요한 경우가 있었습니다.
public class CacheConfiguration {
@Bean
@Qualifier("memory")
public CacheManager inMemoryCacheManager() {
CaffeineCacheManager caffeineCacheManager = new CaffeineCacheManager();
Caffeine<Object, Object> caffeine = Caffeine.newBuilder()
.executor(cached);//해당 설정이 빠진 캐시 설정마다 executor를 추가했습니다.
caffeineCacheManager.setCaffeine(caffeine);
return caffeineCacheManager;
}
}Caffeine 캐시 사용처에 taskExecutor 세팅이 이뤄지지 않은 경우, taskDecorator 설정된 taskExecutor를 추가 설정했습니다.
– Mono/Flux elastic 전환
Reactor의 Mono/Flux에서 사용되는 Scheduler는 각각 elastic(), parallel()이었고, 당연히도 taskDecorator 세팅이 적용되지 않아 있었습니다.
Mono.fromCallable(() -> getA(AId))
.publishOn(Schedulers.elastic())
Flux.fromIterable(rules)
.publishOn(Schedulers.elastic())
.parallel()
.runOn(Schedulers.parallel())이에 elastic()의 경우 사용처마다 Schedulers.fromExecutor(bmartTaskExecutor);를 받도록 전환했습니다.
Flux에서 사용된 parallel()은 CompletableFuture로 전환하거나 동기로 변환될 예정입니다.
3. DB 접근 기술 별 추가 세팅
지금까지의 작업은 DB 접근이 하이버네이트를 통해 이뤄진다는 가정 하에 이뤄졌습니다. 사실 위에서 얘기하지 않은 부분이 있습니다. 바로, 실제로 SQL에 진입점 정보를 추가해 쿼리를 날리는 부분입니다.
그리고 팀 코드에서는 여러 이유로 JPA와 JdbcTemplate를 함께 사용하고 있었습니다…
– 커스텀 JdbcTemplate 작업
이에 JdbcTemplate, namedJdbcTemplate을 통한 쿼리에도 동일하게 진입점 정보를 넘기기 위한 CustomJdbcTemplate을 구현하는 작업을 진행했습니다.
더불어 bean 등록되지 않고 클래스 내에서 new로 선언된 JdbcTemplate을 bean 등록된 CustomJdbcTemplate로 교체했습니다.
public class CustomJdbcTemplate {
private final NamedParameterJdbcTemplate namedParameterJdbcTemplate;
private final JdbcTemplate jdbcTemplate;
private final MDCHandlerCommentAppender mdcHandlerCommentAppender;
public CustomJdbcTemplate(NamedParameterJdbcTemplate namedParameterJdbcTemplate) {
this.namedParameterJdbcTemplate = namedParameterJdbcTemplate;
this.jdbcTemplate = namedParameterJdbcTemplate.getJdbcTemplate();
this.mdcHandlerCommentAppender = new MDCHandlerCommentAppender();
}
//--------------------------------------- NamedParameterJdbcTemplate -------------------------------------------------//
public int update(String sql, Map<String, ?> paramMap) {
final String refinedSql = appendHandlerName(sql);
return namedParameterJdbcTemplate.update(refinedSql, paramMap);
}
//--------------------------------------- jdbcTemplate -------------------------------------------------//
public <T> List<T> query(String sql, Object[] args, RowMapper<T> rowMapper) {
final String refinedSql = appendHandlerName(sql);
return jdbcTemplate.query(refinedSql, args, rowMapper);
}
private String appendHandlerName(String sql) {
final String refinedSql = removeLastSemicolon(sql);
return mdcHandlerCommentAppender.appendHandlerName(refinedSql);
}
private String removeLastSemicolon(String sql) {
if (!sql.endsWith(";")) {
return sql;
}
return sql.substring(0, sql.length() - 1);
}
}
– Batch 내 CustomPagingQueryProvider 작업
Batch 내 job 중 여러 이유로 MDC 진입점 정보 추가가 이뤄지지 않는 경우에도 처리가 필요합니다. JdbcPagingItemReaderBuilder, JdbcBatchItemWriterBuilder를 사용하는 경우 등 입니다.
MySqlPagingQueryProvider mySqlPagingQueryProvider = new MySqlPagingQueryProvider();
mySqlPagingQueryProvider.set...
PagingQueryProvider customPagingQueryProvider = new CustomPagingQueryProvider(mySqlPagingQueryProvider);
public class CustomPagingQueryProvider implements PagingQueryProvider {
private final PagingQueryProvider pagingQueryProvider;
private final MDCHandlerCommentAppender mdcHandlerCommentAppender = new MDCHandlerCommentAppender();
public CustomPagingQueryProvider(PagingQueryProvider pagingQueryProvider) {
this.pagingQueryProvider = pagingQueryProvider;
}
@Override
public void init(DataSource dataSource) throws Exception {
pagingQueryProvider.init(dataSource);
}
@Override
public String generateFirstPageQuery(int pageSize) {
String firstPageQuery = pagingQueryProvider.generateFirstPageQuery(pageSize);
return mdcHandlerCommentAppender.appendHandlerName(firstPageQuery);
}
}
JdbcPagingItemReaderBuilder 케이스의 경우, 데코레이터 패턴의 CustomPagingQueryProvider를 구현한 후 queryProvider에 진입점 값을 추가하는 형태로 구현했습니다.
마무리
지금까지 로그 및 SQL에 진입점 정보를 추가하는 여정이었습니다. 단순히 쿼리 앞단에 진입점 정보를 추가하면 되는 간단한 작업이지만, 과정에서 여러 시행착오를 겪었습니다.
여기까지 작업하며 팀원들의 끊임없는 지원과 피드백을 받았는데요. 특히, 페어 작업하면서 많이 가르쳐주신 순규 님에게도 감사드립니다. 🙇️
