
안녕하세요-!
우아한형제들 정산시스템팀 신입 개발자 박우빈입니다.
예전부터 계속 눈팅만 하면서 구경하던 우아한형제들 기술블로그에 제가 지금 localhost:4000을 띄우고 글을 작성하고 있다니
쉽게 믿기지 않네요ㅎㅎ
오늘은 제가 입사한 후 팀 내에서 진행했던 정산 어드민 파일럿 프로젝트에
대해 나눠보려고 합니다.
많은 분들이 이미 잘 아시는 내용이겠지만, 주니어 개발자의 성장기라고 생각하면서 읽어주시면 감사하겠습니다 🙂
입사 전…
팀이 정해지고 나서 제 앞에 놓여진 것은 두 선배님들의 파일럿 프로젝트 블로그 글이었습니다.
나중에 제 돌보미가 되신 갓보미 갓갓보미 세희님의 글과
늘 모두의 편인 멋남 개발자 태현님의 글.

그리고 눈에 들어오는 몇 개의 단어들…

핰… 떨리는 마음을 애써 넣어두고 저는 입사 후 파일럿 프로젝트를 시작하게 되었습니다! 두둥
1-2주 차 : 도메인 설계하기
정산시스템 어드민 구현하기!
파일럿 프로젝트는 정산시스템의 어드민 페이지를 실제보다는 간소화된 기능으로 직접 구현해 보는 것이었는데요!
요구 사항은 간략하게 다음과 같았습니다. (지면 관계 상 간단하게 적어보았습니다.)
- 어드민 회원 기능 – 회원 가입, 로그인, 권한 관리
- 업주 관리 기능 – 한 업주는 여러 주문을 가질 수 있습니다.
- 주문 관리 기능 – 주문은 세부 결제 수단에 대한 주문 상세를 가집니다.
- 보정 금액 기능 – 특정 사유로 인한 이벤트 발생 시 업주님들께 보상 혹은 보정을 해주는 금액입니다.
- 지급 관리 기능 – 주문 상세와 보정 금액 데이터로 업주님들께 지급할 지급금을 생성합니다.
- 기본적으로 생성/수정/삭제는 관리자만 가능하고, 로그인한 모든 사용자는 위의 데이터들을 검색할 수 있습니다.
그리고 필요한 기술 스택은 다음과 같았습니다.
- OOP & Clean Code
- Spring Boot 2.2.x X Gradle X JPA
- Lombok
- HTTP API
- 단위 테스트 & 통합 테스트
- Git & Git Flow 브랜치 전략
- 모던 JS 환경 -> 저는 Vue.js를 선택했습니다!
과제를 받은 후 첫 2주 동안 나름대로 혼자서 여러 가지 시행착오를 거치며 설계부터 개발까지 A to Z로 진행해 보았습니다.
중간에 설 연휴도 있어서 길어 보였던 시간이 금방 지나갔는데요, 어느덧 첫 코드리뷰 발표날이 되었습니다!

노즈라이딩방은 파일럿 발표를 진행했던 회의실 이름입니다.
영갈피티와 함께 준비된 영갈프론트…
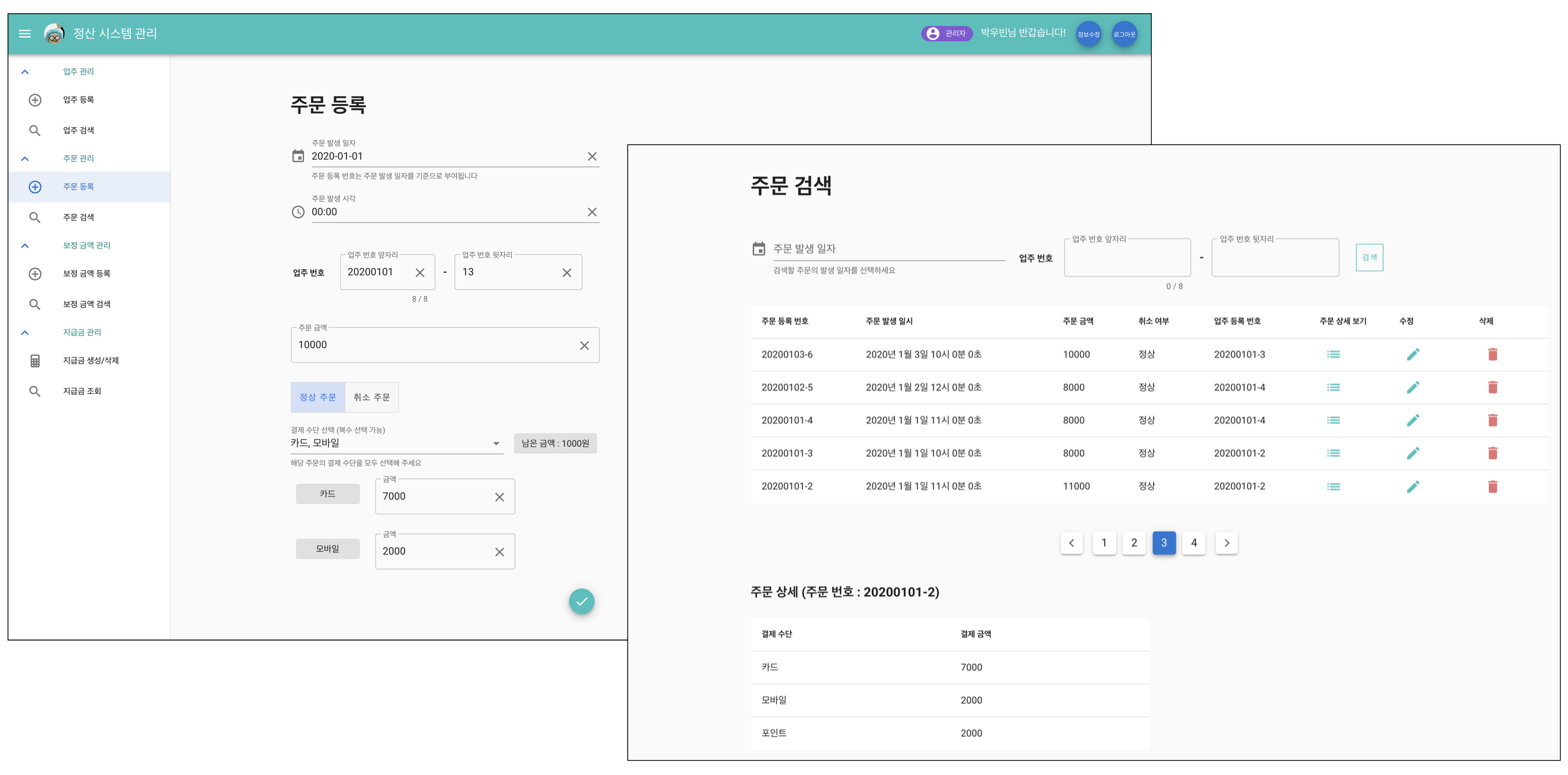
몇 가지 이슈
먼저 첫 코드리뷰 때 팀원분들께 보여드렸던 위 장표를 가지고 1-2주 차에 있었던 몇 가지 개발 이슈를 공유해볼까 합니다!
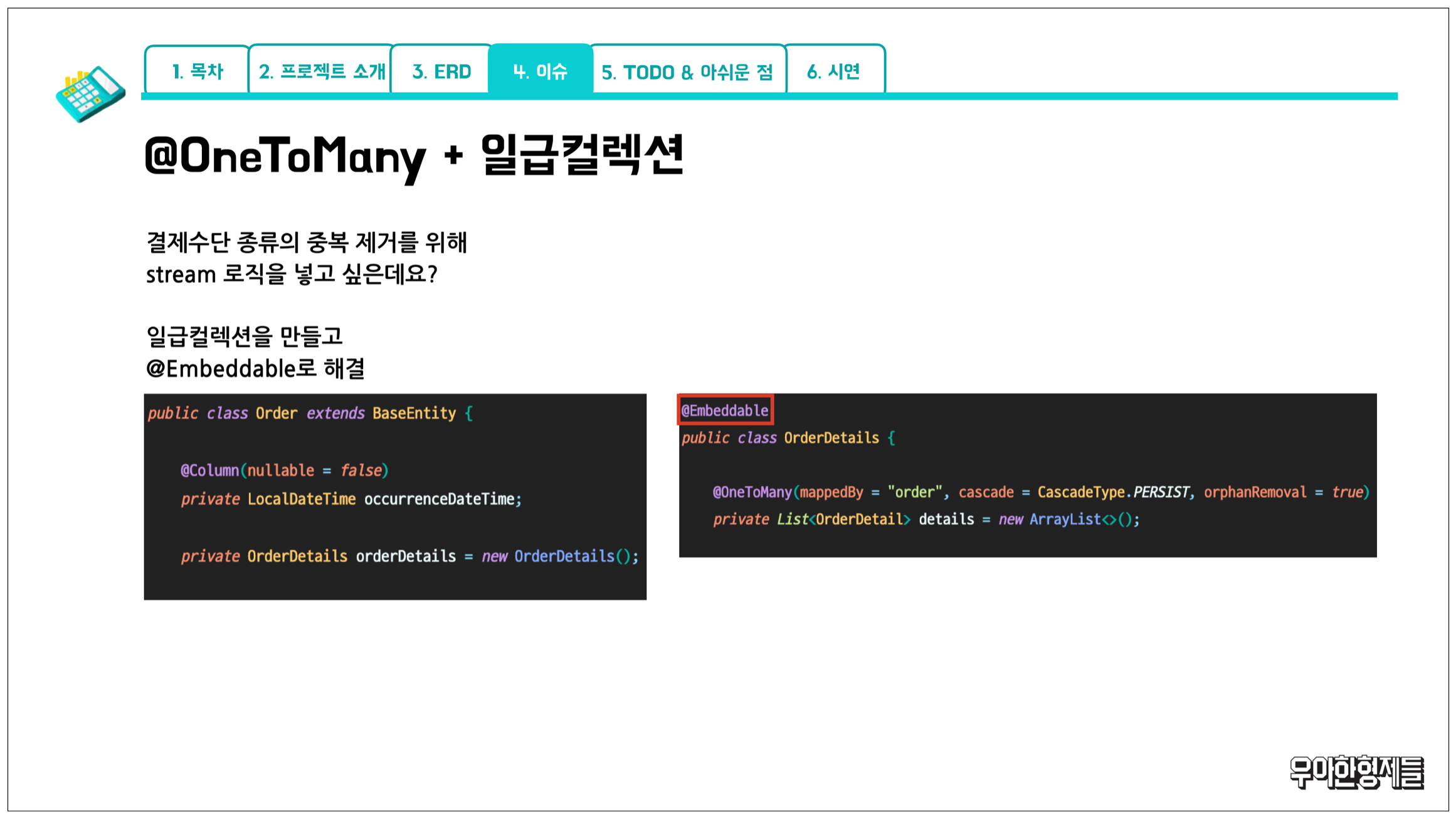
먼저 엔티티와 일급컬렉션에 관한 내용입니다!
제가 설계했던 주문 (Order) 엔티티는 주문을 저장할 때 주문상세 (OrderDetail) 도 같이 저장하는 구조였습니다.
주문과 주문상세는 두 엔티티의 밀접한 관계 때문에 다대일 양방향 매핑으로 설계했는데요.
(주문상세는 결제수단과 해당 결제금액을 가지고 있는 또 다른 엔티티입니다.
예를 들어 하나의 10000원 주문이 카드 결제 7000원, 포인트 결제 3000원의 주문 상세 정보를 가진다고 할 수 있습니다.)
그런데 주문 엔티티의 저장 혹은 수정 과정에서 주문상세 엔티티 간의 중복 체크 로직이 필요하다고 느꼈습니다.
하나의 주문에서 세부 결제수단이 중복될 수는 없다고 판단했기 때문입니다.
(ex. 주문 8000원 = 카드 5000원 + 카드 3000원 (?))
서비스 로직에서 위 validation을 진행하기보다는 도메인 레이어를 풍성하게 사용하고 싶었기 때문에 일급컬렉션의 도입을 고려하게 되었습니다.
OOP에서 컬렉션 데이터를 가공해야 하는 경우에 보통 일급컬렉션을 많이 사용하기에 @Embeddable을 사용하여 해당 내용을 적용해 보았습니다!
그동안 공부하면서 설계했던 비교적 간단한 엔티티들과는 달리 엔티티에서 일급컬렉션을 사용하는 게 처음이라 조금 어색하긴 했지만요ㅎㅎ
해당 내용은 필요할 때 잘 활용할 수 있다면 좋을 것 같아 개인 블로그에도 간단하게 정리해 보았습니다 🙂
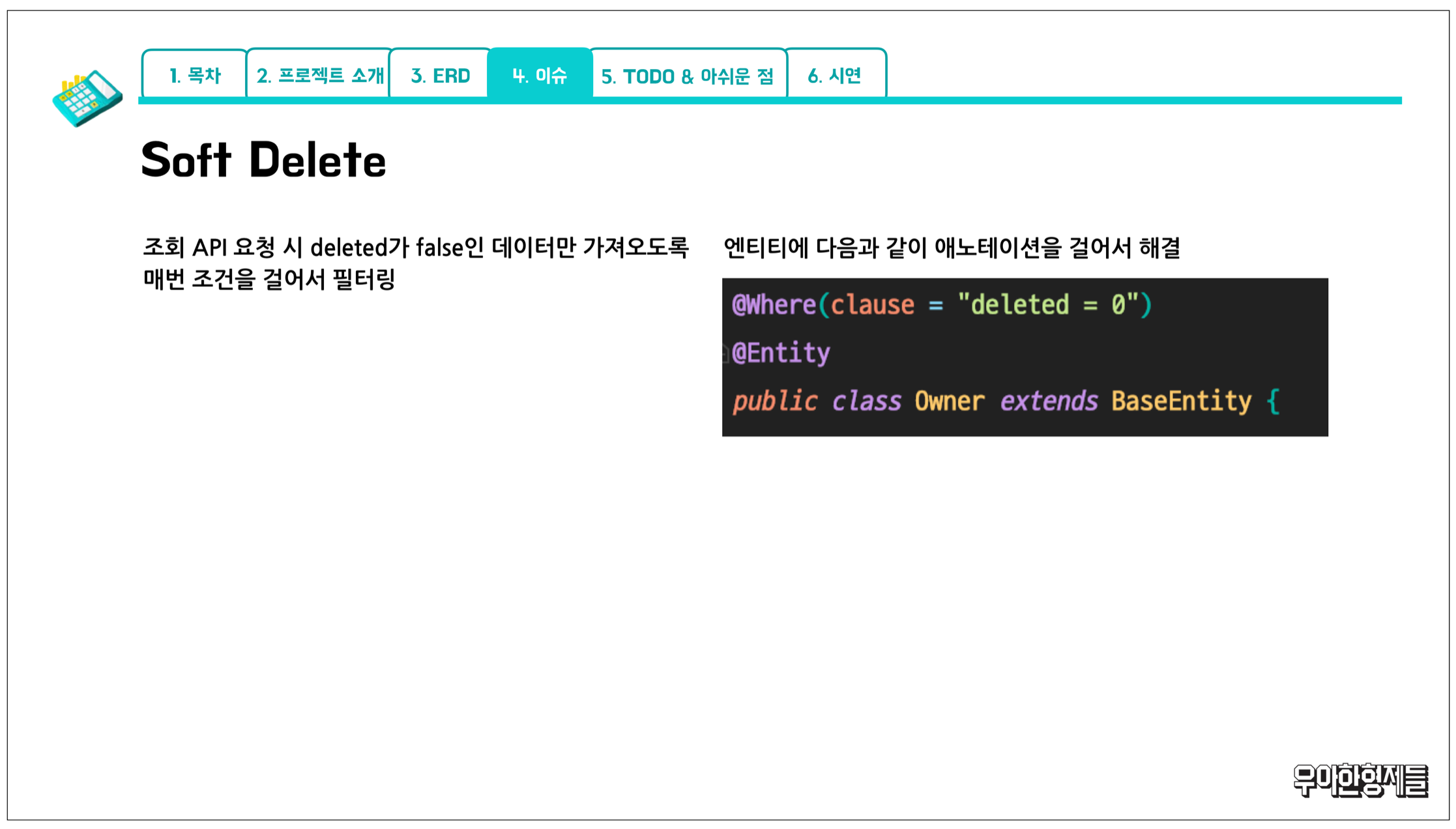
모든 엔티티에는 기본적으로 soft delete를 적용하였습니다!
데이터란 참으로 소중하고 중요한 것이기에… 함부로 삭제하지 말고 오래오래 아껴서 잘 보관해야 합니다. (?)
처음에는 잘 몰라서 매번 수동으로 조회 메소드에서 삭제 필드가 false인 조건을 걸어 가져왔습니다만,
나중에는 @Where(clause = "delete = 0") 이라는 기능을 알게 되어 적용해 보았습니다!
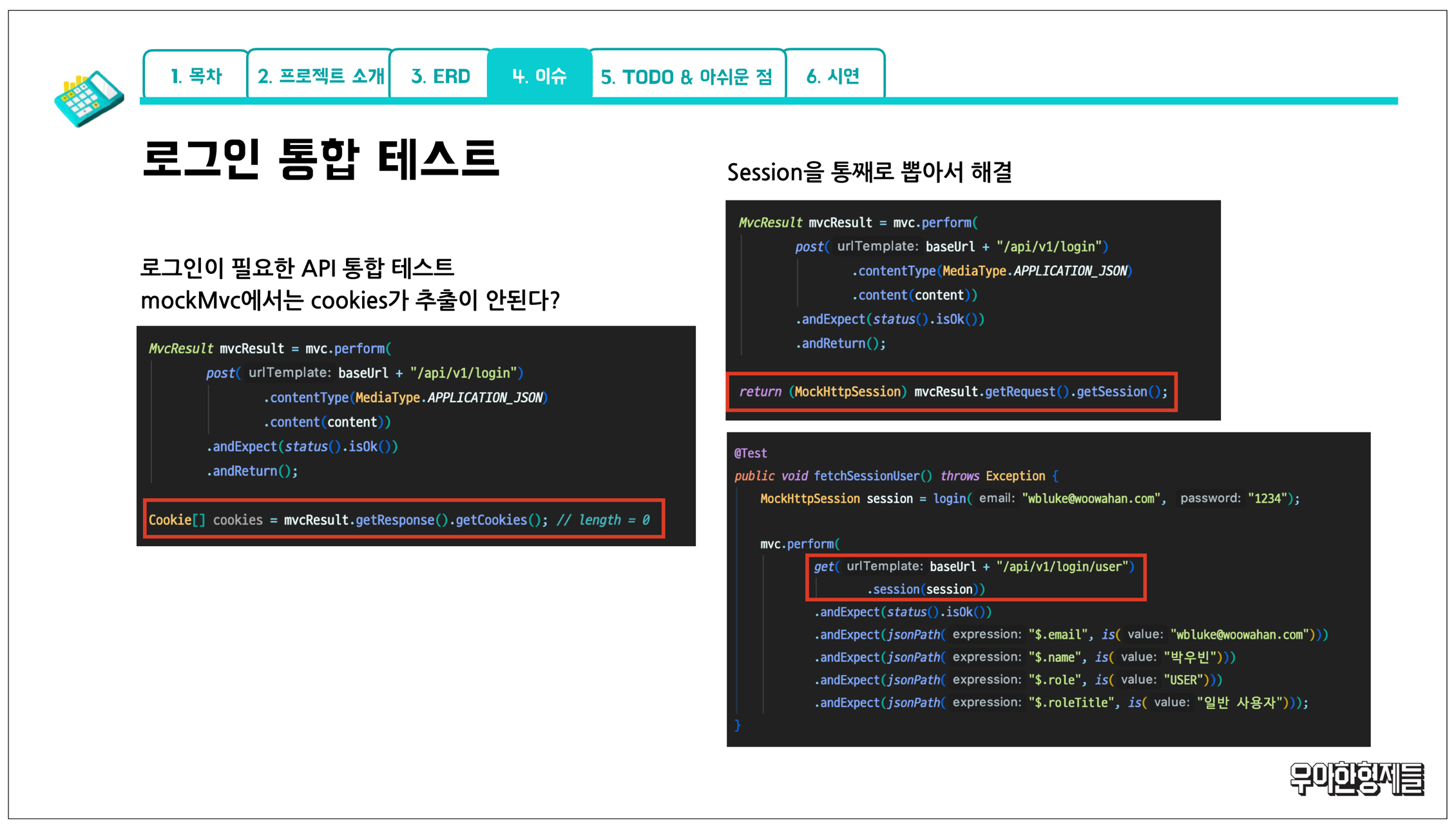
테스트에서도 많은 고민이 있었는데요.
로그인이 필요한 API를 테스트할 때 mockMvc로 통합 테스트를 진행하면서 cookie를 추출할 수 없는 이슈가 있었습니다.
이 내용을 참고해서
테스트 전 login을 미리 진행하고 session을 가져오는 것으로 해당 이슈를 해결할 수 있었습니다.
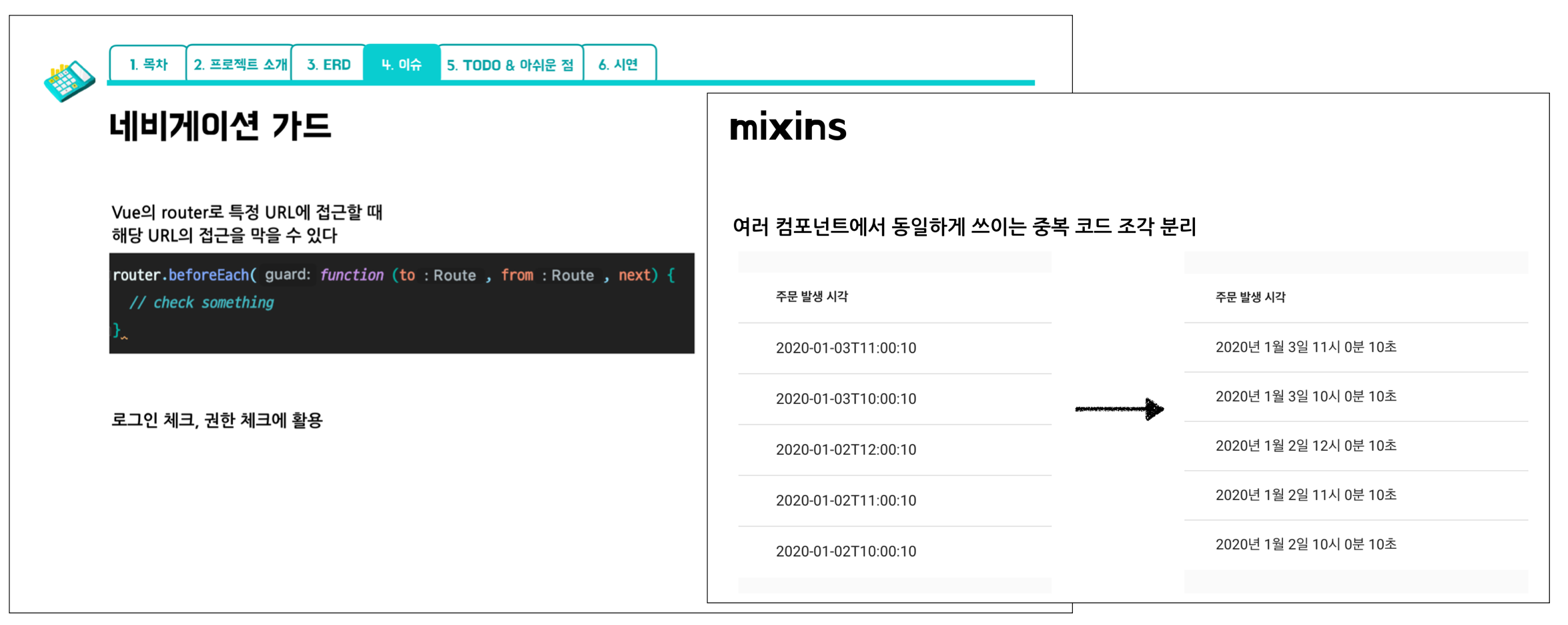
프론트엔드 프레임워크로 Vue.js를 사용하면서도 많은 것들을 새롭게 알게 되었습니다!
그간에는 개인적으로 토이 프로젝트에서만 Vue.js를 써봐서 로그인 체크나 권한 체크를 경험해볼 일이 없었는데요.
Vue의 routing 처리 시 네비게이션 가드를 활용해
사용자가 접근하고자 하는 URL에 대한 관리를 처리할 수 있었습니다.
또한 Mixins를 활용해서 날짜 관련 처리 등의 유틸성 코드 조각들을 분리해내어 코드 중복을 제거할 수 있었습니다!
다음과 같이 말이죠ㅎㅎ
// refineLocalDateTimeMixin.js
export default {
methods: {
// 여러 파일에서 공통적으로 필요한 함수들을 정의
refineLocalDate: function (date) {
// 생략
},
refineLocalTime: function (time) {
// 생략
},
}
}// Orders.vue
import refineLocalDateTimeMixin from "../../mixins/refineLocalDateTimeMixin";
export default {
name: "Orders",
data: () => ({
// 생략
}),
methods: {
// 생략
},
mixins: [refineLocalDateTimeMixin]
}피드백 : 쉽게 경험 못하지!
첫 코드리뷰는 기획자 분들을 포함한 모든 팀원 분들이 참석하셨는데요, 입사 전부터 나름 예상했지만 예상했던 것보다 정말정말 많은 피드백을 받았습니다.
요구 사항으로부터 설계했던 기획 부분의 피드백부터, 코드 레벨에서의 피드백도 빠짐없이 주셨습니다.
또 기획자 분들도 프론트엔드 화면을 보시면서 제가 미처 생각지 못한 기본적인 UI/UX에 대해서 피드백을 같이 주셨습니다.
크… 제 자신이 어느 부분들을 놓치고 있는지 확실하게 마주하게 된, 어디 가서 쉽게 경험 못할 소중한 시간이었습니다.
이제부터 매 주차 별로 받았던 코드 레벨에서의 피드백을 소개할까 합니다!
서비스 로직
먼저 주문(Order) 엔티티에 관련된 서비스 로직을 보겠습니다.
As-Is
@RequiredArgsConstructor
@Service
public class OrderService {
private final OrderRepository orderRepository;
private final OwnerRepository ownerRepository;
// (1)
public long save(final OrderSaveRequest orderSaveRequest) {
Order order = generateOrdersBy(orderSaveRequest);
List<OrderDetailRequest> orderDetailRequests = orderSaveRequest.getOrderDetailRequests();
orderDetailRequests.forEach(orderDetailRequest -> registerOrderDetailInOrders(order, orderDetailRequest));
Order savedOrder = orderRepository.save(order);
return savedOrder.getId();
}
// (2)
private Order generateOrdersBy(final OrderSaveRequest orderSaveRequest) {
Long ownerId = orderSaveRequest.getOwnerId();
Owner owner = EntityServiceUtil.findById(ownerRepository, ownerId);
LocalDateTime occurrenceDateTime = orderSaveRequest.getOccurrenceDateTime();
return Order.builder()
.occurrenceDateTime(occurrenceDateTime)
.owner(owner)
.build();
}
// (2)
private void registerOrderDetailInOrders(final Order order, final OrderDetailRequest orderDetailRequest) {
PaymentMethod paymentMethod = orderDetailRequest.getPaymentMethod();
long amount = orderDetailRequest.getAmount();
OrderDetail orderDetail = generateOrderDetail(order, paymentMethod, amount);
order.addOrderDetail(orderDetail);
}
// (2)
private OrderDetail generateOrderDetail(final Order order, final PaymentMethod paymentMethod, final long amount) {
return OrderDetail.builder()
.paymentMethod(paymentMethod)
.amount(amount)
.order(order)
.build();
}
// ... 생략
}- (1) 가장 먼저 받았던 피드백은 save 로직에 왜
@Transactional이 없나요? 였습니다.
그리고@Transactional의 의미를 알고 있냐고 물어보셨습니다.
저는 일련의 작업을 한 단위로 묶고, 모든 작업은 한 번에 커밋되거나 롤백되어야 한다는 원자성을 부여하기 위함이라고 말씀드렸는데요.
그에 따르면 지금의 save 작업에서는 Order를 저장하면서 다수의 OrderDetail이 같이 저장되는 구조라, insert 쿼리가 여러 방 나가는 구조였기 때문에
필수적으로@Transactional로 묶여야만 했습니다.
그동안 저는 트랜잭션의 본질을 생각하지 못하고 애노테이션을 사용하고 있었습니다.
그저 Service 로직에서 update 메소드의 엔티티 변경 감지(Dirty Checking)나 조회 메소드의 readOnly = true 옵션을 주기 위해서만 사용해 왔었습니다.
특별한 경우가 아니고서야 순서와 작업 단위를 보장해야 하는 Service 레이어의 모든 메소드에서 해당 애노테이션을 붙이는 것이 좋다는 생각이 들었습니다.
(클래스에 붙이는 것은 메소드 별 상세 설정을 할 수 없어서 지양하고 있었습니다.)
- (2) 두 번째로는 하나의 클래스에 private 메소드가 너무 많다는 것이었습니다.
save 하는 과정에서 잘게 쪼개놨지만, 사실 핵심은 Order와 OrderDetail을 저장하는 것이 전부였습니다.
그 외 로직들은 DTO를 엔티티로 변환하거나, 서로의 양방향 관계를 설정하는 등의 부수적인 과정들이었습니다.- DTO의 데이터들을 엔티티로 변환하는 과정은 Service가 아니라 DTO에서 담당해주고, Service에는 명확하게 save라는 목적에 맞는 일만 하는 것이 옳다고 하셨습니다.
- (피드백을 듣고 나서야 예전 프로젝트에서는 Assembler라는 별도 static 클래스에서 DTO와 엔티티 간의 변환을 담당해주도록 구현했던 것이 뒤늦게 기억났습니다ㅠ.ㅠ)
As-Is
// ... 생략
@Transactional(readOnly = true)
public OrderResponse findById(final long id) {
Order order = findOrderById(id);
return new OrderResponse(order);
}
// (3)
private Order findOrderById(final long id) {
return orderRepository.findOrderByIdWithDetails(id)
.orElseThrow(EntityNotFoundException::new);
}
// ... 생략-
(3) public 메소드와 private 메소드는 군집을 이루는 것이 좋다고 하셨습니다.
보통은 public 메소드에서 사용되는 private 메소드들이 바로 아래에 오는데,
만약 다수의 public 메소드에서 사용되는 공통의 private 메소드가 있다면 (위의 findOrderById 같은 경우) 순서를 놓기가 꽤 애매해집니다.
그래서 팀 내에서는 public / private 메소드 군집을 만든다고 하셨습니다.- 이렇게 하면 public 메소드들은 이 클래스가 외부에 제공하는 API가 어떤 것인지를 명확히 명시해줄 수 있다는 장점이 있습니다.
- 만약 public 메소드 내의 private 메소드가 어떤 역할을 하는지 명확하지 않아서 계속 맨 아래쪽으로 내려가서
직접 확인을 해야 한다면, 그것은 추상화를 잘못한 경우라고 부연설명 해주셨습니다.
이름만으로 명확한 행위가 설명되지 않는 경우인 것이죠. (이 내용은 당연히 팀 By 팀일 수 있습니다)
As-Is
// ... 생략
@Transactional(readOnly = true)
public List<OrderResponse> searchByOccurrenceDateTimeAndOwnerId(final OrderSearchRequest orderSearchRequest) {
// (4)
PageRequest pageRequest = PageRequest.of(orderSearchRequest.getPage(), orderSearchRequest.getSize());
Page<Order> orders = orderRepository.findByOwnerIdAndOccurrenceDateTimeBetweenOrderByIdDesc(orderSearchRequest.getOwnerId(),
orderSearchRequest.getStartDateTime(), orderSearchRequest.getEndDateTime(), pageRequest);
return transferOrdersToResponses(orders);
}
@Transactional(readOnly = true)
public long countByOccurrenceDateTimeAndOwnerId(final OrderCountRequest orderCountRequest) {
return orderRepository.countByOwnerIdAndOccurrenceDateTimeBetween(orderCountRequest.getOwnerId(),
orderCountRequest.getStartDateTime(), orderCountRequest.getEndDateTime());
}
@Transactional(readOnly = true)
public long countAll() {
return orderRepository.count();
}
// ... 생략
}- (4) 기존에는 pagination을 구현하기 위해 Pageable 인터페이스 형인 PageRequest를 사용하고 있었는데요.
Pageable은 내부적으로 count 쿼리를 같이 사용하기 때문에 편하지만 성능을 개선하기에는 한계가 있다고 하셨습니다.
페이징 결과인 Page를 만들기 위해 매번 조건에 맞는 count 쿼리를 추가로 날려서 데이터를 구성하기 때문입니다.
아래 repository를 함께 보시면!
As-Is
public interface OrderRepository extends JpaRepository<Order, Long> {
@Query("SELECT DISTINCT o FROM Order o JOIN FETCH o.orderDetails.details WHERE o.owner.id = :ownerId" +
" AND o.occurrenceDateTime BETWEEN :startDateTime AND :endDateTime ORDER BY o.id DESC")
List<Order> findByOwnerIdAndOccurrenceDateTimeBetweenOrderByIdDesc(@Param("ownerId") long ownerId,
@Param("startDateTime") LocalDateTime startDateTime, @Param("endDateTime") LocalDateTime endDateTime);
@Query(value = "SELECT DISTINCT o FROM Order o JOIN FETCH o.orderDetails.details WHERE o.owner.id = :ownerId" +
" AND o.occurrenceDateTime BETWEEN :startDateTime AND :endDateTime ORDER BY o.id DESC"
, countQuery = "SELECT COUNT(o) FROM Order o") // (4)
Page<Order> findByOwnerIdAndOccurrenceDateTimeBetweenOrderByIdDesc(@Param("ownerId") long ownerId,
@Param("startDateTime") LocalDateTime startDateTime, @Param("endDateTime") LocalDateTime endDateTime, Pageable pageable);
long countByOwnerIdAndOccurrenceDateTimeBetween(long ownerId, LocalDateTime startDateTime, LocalDateTime endDateTime);
}(…) 보시기에 불편하실 수 있는데요.
Querydsl을 몰랐던 상태에서 JPQL로만 paging 처리를 하려고 해서 그렇습니다.
아래에서 새롭게 단장하니까 잠시만 참아주세요.
쿼리에서 보이다시피, 같은 쿼리인데도 Pageable을 인자로 받아서 처리하면 countQuery를 추가로 요구합니다.
아무튼 그러한 이유로 Pageable 대신 offset, limit의 전통적인(?) Pagination 방식으로 구현해보라고 조언을 주셨습니다.
그리고 마침 동시에 jojoldu 동욱님이 팀 내에 공유해주신 획기적인 pagination 성능 개선 방법이 있었는데요.
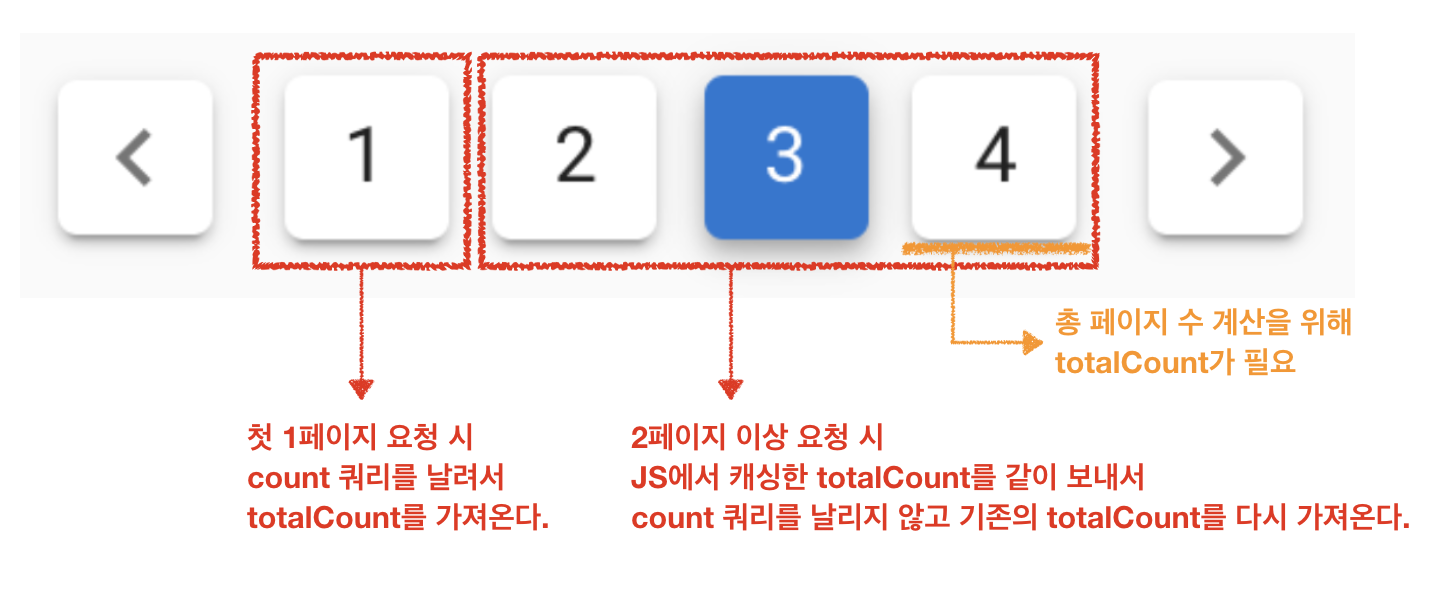
대용량의 데이터를 다뤄야 하는 정산시스템에서는 쿼리의 수나 쿼리 튜닝 여부가 성능에 상당히 큰 영향을 끼칩니다.
위 그림에서와 같이 불필요한 count 쿼리를 최소화하기 위해, 첫 1페이지에서는 totalCount를 구해서 받도록 하고, 이후 페이지에서부터는
JS단에서 가지고 있던 totalCount 값을 페이징 데이터 요청 시에 같이 날립니다.
서버 단에서는 totalCount가 없으면 새로 count 쿼리를 날리고,
totalCount가 있으면 count 쿼리를 날리지 않고 프론트에서 넘겨준 totalCount를 그대로 다시 내려주는 방식으로 처리했습니다. 크 갓동욱님
실시간으로 데이터에 변화가 있는 환경이라면 페이지 개수가 계속 변경되겠지만,
정산 시스템에서는 전날 마감한 데이터를 기준으로 조회하기 때문에
실시간 변동이 많지 않아서 위 방법을 적용할 수 있습니다.
위 피드백을 반영해 수정한 Service 로직은 다음과 같습니다!
To-Be
@RequiredArgsConstructor
@Service
public class OrderService {
private final OrderRepository orderRepository;
private final OwnerRepository ownerRepository;
@Transactional
public long save(OrderSaveRequest orderSaveRequest) {
String ownerKey = orderSaveRequest.getOwnerKey();
Owner owner = ownerRepository.findByOwnerKey(ownerKey)
.orElseThrow(OwnerNotFoundException::new);
Order order = orderSaveRequest.toEntity(owner);
Order savedOrder = orderRepository.save(order);
savedOrder.generateKeyWithId();
return savedOrder.getId();
}
@Transactional(readOnly = true)
public OrderResponse findById(long id) {
Order order = findOrderById(id);
return new OrderResponse(order);
}
@Transactional(readOnly = true)
public OrderSearchResponse search(OrderSearchRequest orderSearchRequest) {
OrderSearchCondition condition = generateSearchConditionFrom(orderSearchRequest);
int offset = orderSearchRequest.getOffset();
int limit = orderSearchRequest.getLimit();
List<Order> orders = orderRepository.findOrdersWithCondition(condition, offset, limit);
Long totalCount = fetchTotalCount(orderSearchRequest.getTotalCount(), condition);
return new OrderSearchResponse(orders, totalCount);
}
Long fetchTotalCount(Long totalCount, OrderSearchCondition condition) {
if (totalCount == null) {
totalCount = orderRepository.countWithCondition(condition);
}
return totalCount;
}
// ... 생략
}totalCount의 존재 유무에 따라 count 쿼리를 날리는 fetchTotalCount 로직은 원래 search 메소드에 같이 묶여 있었는데요.
추후 추가적인 피드백으로 해당 로직을 분리해서 mocking 테스트를 해보면 어떻겠냐는 피드백을 받았습니다.
다음과 같이 말이죠.
To-Be
@Test
public void totalCount가_있는_경우_count_쿼리를_날리지_않는다() {
OrderSearchCondition condition = OrderSearchCondition.builder().build();
when(mockOrderRepository.countWithCondition(condition)).thenReturn(1L);
Long totalCount = mockOrderService.fetchTotalCount(10L, condition);
verify(mockOrderRepository, times(0)).countWithCondition(condition);
assertThat(totalCount).isEqualTo(10L);
}
@Test
public void totalCount가_없는_경우_count_쿼리를_날린다() {
OrderSearchCondition condition = OrderSearchCondition.builder().build();
when(mockOrderRepository.countWithCondition(condition)).thenReturn(1L);
Long totalCount = mockOrderService.fetchTotalCount(null, condition);
verify(mockOrderRepository, times(1)).countWithCondition(condition);
assertThat(totalCount).isEqualTo(1L);
}WebConfig에서의 권한 관리
권한 관리도 큰 테마 중 하나였습니다.
앞선 요구사항에 따르면, 기본적으로 로그인한 사용자만 페이지에 접근 가능해야 하고,
검색은 모든 사용자가 가능, 생성/수정/삭제는 관리자만 가능하도록 사용자 별 권한을 관리해야 했습니다.
따라서 로그인 유무를 체크하는 LoginInterceptor와 ADMIN 권한을 가지고 있는지 체크하는 AdminRoleInterceptor를 두어 흐름을 제어했는데요.
As-Is
@Configuration
public class WebConfig implements WebMvcConfigurer {
private static final List<String> LOGIN_EXCLUDE_PATH_PATTERNS = Arrays.asList("/api/v1/login/**", "/api/v1/sign-up/**",
"/api/v1/logout");
// (1)
private static final List<String> ADMIN_ROLE_EXCLUDE_PATH_PATTERNS = Arrays.asList("/api/v1/owners/search/**",
"/api/v1/owners/count/**", "/api/v1/orders/search/**", "/api/v1/orders/count/**",
"/api/v1/correction-amounts/search/**", "/api/v1/correction-amounts/count/**", "/api/v1/payouts");
@Value("$")
private List<String> basicExcludePathPatterns;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoginInterceptor())
.addPathPatterns("/**")
.excludePathPatterns(basicExcludePathPatterns)
.excludePathPatterns(LOGIN_EXCLUDE_PATH_PATTERNS);
registry.addInterceptor(new AdminRoleInterceptor())
.addPathPatterns("/**")
.excludePathPatterns(basicExcludePathPatterns)
.excludePathPatterns(LOGIN_EXCLUDE_PATH_PATTERNS)
.excludePathPatterns(ADMIN_ROLE_EXCLUDE_PATH_PATTERNS);
}
// ... 생략
}다음과 같은 피드백이 있었습니다.
-
(1) 현재 ADMIN ROLE을 체크하기 위해서 많은 URL들을 배제하는 형식으로 적용하고 있는데, 나중에 또 다른 권한이 생기거나
추가해야 할 interceptor가 생긴다면 EXCLUDE_PATH_PATTERNS를 꼬리물기로 추가해야 할 수도 있다고 하셨습니다.
오히려 배제하는 방식 대신 역산으로 필요한 URL에만 적용하는 방법이 좋겠다고 말씀해 주셨습니다. -
(2) 추가로 interceptor 내에서 HTTP Method에 대한 체크는 이루어지지 않고 있었는데, 권한 관리는 기본적으로 URL + HTTP Method 의 조합으로
관리하는 것이 좋다고 피드백을 주셨습니다.
리팩토링한 코드는 다음과 같습니다!
To-Be
@Configuration
public class WebConfig implements WebMvcConfigurer {
private static final List<String> LOGIN_EXCLUDE_PATH_PATTERNS = Arrays.asList("/api/v1/login/**", "/api/v1/sign-up/**",
"/api/v1/logout");
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoginInterceptor())
.addPathPatterns("/**")
.excludePathPatterns("/", "/index.html", "/css/**", "/fonts/**", "/wp-content/uploads/img/**", "/js/**")
.excludePathPatterns(LOGIN_EXCLUDE_PATH_PATTERNS);
registry.addInterceptor(new AdminRoleInterceptor())
.addPathPatterns("/api/v1/owners/**", "/api/v1/orders/**", "/api/v1/correction-amounts/**", "/api/v1/payouts/**",
"/api/v1/search/**");
}
// ... 생략
}public class AdminRoleInterceptor extends HandlerInterceptorAdapter {
public static final String ALLOWED_HTTP_METHOD = "GET";
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
HttpSession session = request.getSession();
SessionUser sessionUser = (SessionUser) session.getAttribute(SESSION_USER);
if (sessionUser == null) {
return false;
}
if (Role.ADMIN.equals(sessionUser.getRole())) {
return true;
}
String httpMethod = request.getMethod();
return isAllowedHttpMethod(httpMethod);
}
private boolean isAllowedHttpMethod(String httpMethod) {
return ALLOWED_HTTP_METHOD.equals(httpMethod);
}
}좀 슬림해졌나요?ㅎㅎ
3주 차 : 리팩토링 + 인덱스 적용하기
엔티티
3주 차에는 1-2주 차에 받았던 피드백들을 적용하고, 인덱스에 대해서도 고민해보는 시간을 가졌습니다.
도메인에서도 많은 피드백을 받았는데요!
As-Is
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Where(clause = "deleted = 0")
@Entity
@Table(name = "order_table", indexes = { // (1)
@Index(name = "idx_owner_occurrenceDate", columnList = "owner_id, occurrenceDate")
})
public class Order extends BaseEntity {
@Embedded
private OrderKey orderKey;
@Column(nullable = false)
private LocalDate occurrenceDate; // (2)
@Column(nullable = false)
private LocalTime occurrenceTime; // (2)
// List<OrderDetail>을 가지고 있는 @Embeddable 일급컬렉션
private OrderDetails orderDetails = new OrderDetails();
@ManyToOne(fetch = FetchType.LAZY)
private Owner owner;
@Column(nullable = false)
private boolean canceled = false;
@Column(nullable = false)
private long amount;
// ... 생략-
(1) 기존에는 인덱스를
columnList = "owner_id, occurrenceDate"로 한꺼번에 걸고 있었는데요.
업주 id와 date 타입에 한 번에 인덱스를 걸면 나중에 동적 쿼리가 적용되어 주문 발생 일자 (occurrenceDate) 로만 검색할 경우 해당 인덱스를 사용할 수 없다고 하셨습니다.
이런 경우엔 각각 따로 인덱스를 생성하는 것이 더 좋다고 피드백을 주셨습니다! -
(2) 1-2주 차 때는 주문이나 보정금액의 발생 일자를 LocalDateTime으로 관리하고 있었습니다.
하지만 비즈니스 로직 상 LocalDate를 사용하는 일이 더 많아서, (일자 조회 등)
3주 차 때 LocalDate와 LocalTime으로 오랜 시간을 들여 다 분리했습니다.
그랬더니 바로 날아온 피드백…ㅎㅎ- Date와 Time을 따로 관리하게 되면, 기간 검색을 하기에 비효율적이라는 단점이 생깁니다.
- 예를 들어 2020년 1월 1일 07시부터 2020년 1월 3일 07시까지를 조회하려고 하면,
LocalDateTime인 경우는 한 방에 조회가 되지만,
LocalDate와 LocalTime이 따로 저장되어 있는 경우에는 쿼리가 날짜별로 끊겨서 최소 3방이 나가야 합니다.
결국 다음 코드리뷰 전까지 다시 열심히 일자와 시간을 합쳤습니다…롬곡옾높
(나중에는 편의를 위해 LocalDateTime과 LocalDate를 둘 다 가지고 있게 했습니다.)
LocalDateTime을 다루기 불편해서 LocalDate와 LocalTime으로 분리하자는 생각은,
마주한 문제를 깊은 고민 없이 단순히 설계의 방향을 바꿈으로써 해결하고자 했던 생각이었습니다.
그리고 이어서 주신 말씀은 제게 많은 도전이 되었습니다.
개발을 편하게 하기 위해서 기획의 내용을 바꾸는 것은 크게 다시 생각해 보아야 한다.
혼자 공부할 때나, 토이 프로젝트를 할 때는 사실 개발이 조금이라도 막히면 기획이나 UI/UX 적인 측면으로 돌아서 회피하기가 쉽다.
하지만 실무에서는 기획의 내용이 확실하게 정해져 있고, 그 요구사항을 충족시키기 위해 어떻게 접근하는지가 개발자의 역량이 드러나는 지점이다.

띠용… 머리에 망치를 맞았습니다. 그렇지만 곱씹을 틈 없이 피드백은 계속 이어집니다. (집에 가서 많이 되새겼습니다)
As-Is
@Builder // (3)
public Order(final LocalDate occurrenceDate, final LocalTime occurrenceTime, final Owner owner, final boolean canceled, final long amount) {
this.occurrenceDate = occurrenceDate;
this.occurrenceTime = occurrenceTime;
this.owner = owner;
this.canceled = canceled;
this.amount = amount;
}
// (4)
public void generateKeyWith(final long orderSequence) {
this.orderKey = OrderKey.of(occurrenceDate, orderSequence); // (5)
}
@Override
public void softDelete() {
super.softDelete();
orderDetails.softDelete();
}
// ... 생략
}-
(3) 저는 메소드 파라미터에 final 키워드를 자동으로 붙여주는 인텔리제이 설정을 사용하고 있었는데요.
뭔가 파라미터의 값을 확실하게 보증해주는 듯 보이기도 하고, 음…있어 보여서
하지만 사실 요즘은 메소드를 잘게 쪼개고, 한 가지 일만 하도록 짧게짧게 작성하기 때문에 사실 상 효과가 미미한 장치입니다.
오히려 메소드 선언부의 길이가 너무 길어져서 보기에 더 불편하다는 단점이 있었습니다. -
(4) 3주 차에 새롭게 시도한 것은 DB에서 부여해주는 id 외에 비즈니스적으로 사용되는 Key 필드를 사용한 것이었습니다.
일련번호를 부여하기 위해, 현재 DB에 있는 데이터의 수를 count로 조회해와서 [날짜 – sequence] (ex. 20200101-3) 값을 만들어 Key로 사용했습니다.
하지만 여기에는 치명적인 문제가 있었습니다.- unique한 비즈니스 Key 값을 만드는데 실시간으로 동일 데이터인지 보장할 수 없는 DB 데이터의 수를 가져와서 사용하는 것은
심각한 문제를 유발할 수 있었습니다. - 현재 데이터가 30개 있는데 너도나도 30이라는 개수를 동시에 가져가서 [20200101-31]이라는 키를 만들 수 있으니까요.
아마 저장할 때 한 명의 관리자만 엔티티 저장에 성공하고 나머지 관리자는 계속 실패를 맛봤을 겁니다. - 그래서 보통은 ID 값을 사용하거나, UUID를 사용해서 비즈니스 키를 만든다고 합니다! (저는 ID를 사용했습니다.)
- unique한 비즈니스 Key 값을 만드는데 실시간으로 동일 데이터인지 보장할 수 없는 DB 데이터의 수를 가져와서 사용하는 것은
-
(5) 저는 객체 생성 시에 별다른 이유 없이 static factory method를 통해 객체를 생성하고 있었는데요.
있어 보여서
파라미터가 1개일 때는from, 파라미터가 2개 이상일 때는of라는 이름을 쓰고 있었습니다.- 하지만 static factory method는 객체의 생성 방법이 여러 가지일 때 (예를 들어 파라미터에 String 타입이 여러 개라던가) 사용하지
팀에서는 즐겨 사용하지 않는다고 말씀해 주셨습니다. - 위와 같은 이름 규칙도 정해진 팀 컨벤션이 없는 상황에서는 팀에 새로운 분이 올 때마다 공유하는 불필요한 전달사항이 될 수 있다고 하셨습니다.
(이 내용도 팀 By 팀일 수 있겠네요!)
- 하지만 static factory method는 객체의 생성 방법이 여러 가지일 때 (예를 들어 파라미터에 String 타입이 여러 개라던가) 사용하지
수정한 Order 엔티티는 다음과 같습니다!
To-Be
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Where(clause = "deleted = 0")
@Entity
@Table(name = "order_table", indexes = {
@Index(name = "idx_owner", columnList = "owner_id"),
@Index(name = "idx_occurrenceDate", columnList = "occurrenceDate")
})
public class Order extends BaseEntity {
@Embedded
private OrderKey orderKey;
@Column(nullable = false)
private LocalDateTime occurrenceDateTime;
@Column(nullable = false)
private LocalDate occurrenceDate;
private OrderDetails orderDetails = new OrderDetails();
@ManyToOne(fetch = FetchType.LAZY)
private Owner owner;
@Column(nullable = false)
private boolean canceled = false;
@Column(nullable = false)
private long amount;
@Builder
public Order(LocalDateTime occurrenceDateTime, Owner owner, boolean canceled, long amount) {
this.occurrenceDateTime = occurrenceDateTime;
this.occurrenceDate = occurrenceDateTime.toLocalDate();
this.owner = owner;
this.canceled = canceled;
this.amount = amount;
}
public void generateKeyWithId() {
this.orderKey = new OrderKey(this.occurrenceDate, this.getId());
}
@Override
public void softDelete() {
super.softDelete();
orderDetails.softDelete();
}
// ... 생략
}4주 차 : querydsl + 멀티모듈
4주 차는 querydsl과 멀티모듈 적용하기 였는데요!
둘 다 처음 해봐서 걱정이 이만저만 아니었지만ㅎㅎ 우여곡절 끝에 적용해 보았습니다.
먼저 앞서 보여드렸던 repository는 querydsl을 통해 다음과 같이 새 단장을 하였습니다! (영한님께 감사를 드립니다…ㅎㅎ)
To-Be
@RequiredArgsConstructor
public class OrderRepositoryImpl implements OrderRepositoryCustom {
private final JPAQueryFactory queryFactory;
@Override
public List<Order> findUncanceledOrdersWith(LocalDateTime startDateTime, LocalDateTime endDateTime, Owner foundOwner) {
if (isEmptyOneOf(startDateTime, endDateTime, foundOwner)) {
throw new LackQueryConditionException();
}
return queryFactory
.selectDistinct(order)
.from(order)
.join(order.orderDetails.details, orderDetail).fetchJoin()
.join(order.owner, owner).fetchJoin()
.where(occurrenceDateTimeBetween(startDateTime, endDateTime),
owner.eq(foundOwner),
order.canceled.isFalse())
.orderBy(order.id.desc())
.fetch();
}
@Override
public List<Order> findOrdersWithCondition(OrderSearchCondition condition, int offset, int limit) {
return queryFactory
.selectDistinct(order)
.from(order)
.join(order.orderDetails.details, orderDetail).fetchJoin()
.join(order.owner, owner).fetchJoin()
.where(occurrenceDateTimeBetween(condition.getStartDateTime(), condition.getEndDateTime()),
ownerKeyEq(condition.getOwnerKey()))
.offset(offset)
.limit(limit)
.orderBy(order.id.desc())
.fetch();
}
@Override
public Long countWithCondition(OrderSearchCondition condition) {
return queryFactory
.selectFrom(order)
.where(occurrenceDateTimeBetween(condition.getStartDateTime(), condition.getEndDateTime()),
ownerKeyEq(condition.getOwnerKey()))
.fetchCount();
}
private boolean isEmptyOneOf(LocalDateTime startDateTime, LocalDateTime endDateTime, Owner owner) {
return isEmpty(startDateTime) || isEmpty(endDateTime) || isEmpty(owner);
}
private BooleanExpression occurrenceDateTimeBetween(LocalDateTime startDateTime, LocalDateTime endDateTime) {
return (startDateTime != null && endDateTime != null)
? order.occurrenceDateTime.between(startDateTime, endDateTime)
: null;
}
private BooleanExpression ownerKeyEq(String ownerKey) {
return hasText(ownerKey) ? order.owner.ownerKey.value.eq(ownerKey) : null;
}
}조건에 따라 분기문을 작성해야 했던 Service 로직을 다 걷어내고, 동적으로 조건을 바꿔가면서 적용할 수 있었습니다!
동적 쿼리를 적용하기 위해 복잡하게 얽어 놓은 분기 로직들을 한 번에 걷어내는 경험은 정말 짜릿했습니다!ㅋㅋ

그리고 멀티모듈은 module-common과 module-web으로 분류했는데요. 다음과 같은 피드백을 받았습니다.
-
모듈 간 의존성의 내용을 프로젝트 root의 build.gradle에서 알 필요는 없습니다. root에는 정말 공통적인 설정들만 있으면 충분합니다.
- ex) web 모듈이 common 모듈의 라이브러리를 쓴다는 것을 root에 명시할 필요는 없습니다.
- 이 내용도 팀 By 팀 입니다! root에 모든 설정을 넣어 한 눈에 보기를 선호하는 팀도 있습니다.
-
common이라는 이름은 위험합니다. common이라는 모듈 혹은 패키지가 있을 때, A, B, C, D 의 모듈이 있다고 가정하면
A, B에서 사용하는 공통 로직도 common에 들어가고, B, C, D에서 사용하는 공통 로직도 common에 들어갈 확률이 높습니다.- 정말 모두가 사용할 수 있는 유틸성 클래스들만 common에 들어가고, 최대한 common이라는 이름은 지양하는 것이 좋습니다.
- 나중에는 common을 core로, web을 api라는 이름으로 변경하였습니다ㅎㅎ
-
querydsl을 구현하기 위해 CustomRepository를 Impl하는 방법은 한 번 밖에 못쓰기 때문에 core 모듈이 아니라 외부에서 구현해야 합니다.
querydsl을 쓰는 이유는 결국 동적쿼리, 복잡한 쿼리를 사용하기 위함인데 core에서 갖고 있을 필요도 없고,
querydsl을 사용해야 하는 다른 모듈에서 상속받아 구현하는 것이 자연스럽습니다.
여담이지만 마지막 주에는 배치 로직을 적용하다가, 모듈의 패키지와 gradle 파일이 모두 꼬여버리는 불상사가 생기기도 했습니다.
(동욱님이 물에 빠진 프로젝트를 구해주셨습니다… ㅠ.ㅠ)
이유인즉슨 멀티모듈에서는 모듈이 나눠진 것처럼 보이지만 사실은 패키지가 전부 하나로 합쳐져서 인식되기 때문이었습니다.
그래서 @ComponentScan이나 @SpringBootApplication을 통해 다른 모듈의 Bean을 스캔해서 사용하고자 할 때도, 해당 애노테이션을 갖고 있는
클래스는 모든 모듈의 패키지보다 상위에 있어야 했습니다.
그러면서 해주신 또 하나의 멋진 조언은 다음과 같았습니다.
gradle 멀티 모듈, Spring Boot, JPA, querydsl 등등은 지금 내가 맡고 있는 사내 프로젝트가 아니더라도
항상 최신 버전에 대한 연습이 필요하다.
개발자가 자바 디버깅을 아무리 잘해도 gradle 앞에서 주눅 든다면, 항상 다른 개발자들에게 의존할 수 밖에 없다.
- 실제로 블로그에 글을 작성하실 때에도 매번 새 프로젝트를 생성해서 글을 작성해 보신다고 합니다!
테스트 구조 개편
이번 주차에는 테스트 방식도 전면 개편했는데요!
기존 프로젝트의 테스트 방식은 다음과 같았습니다.
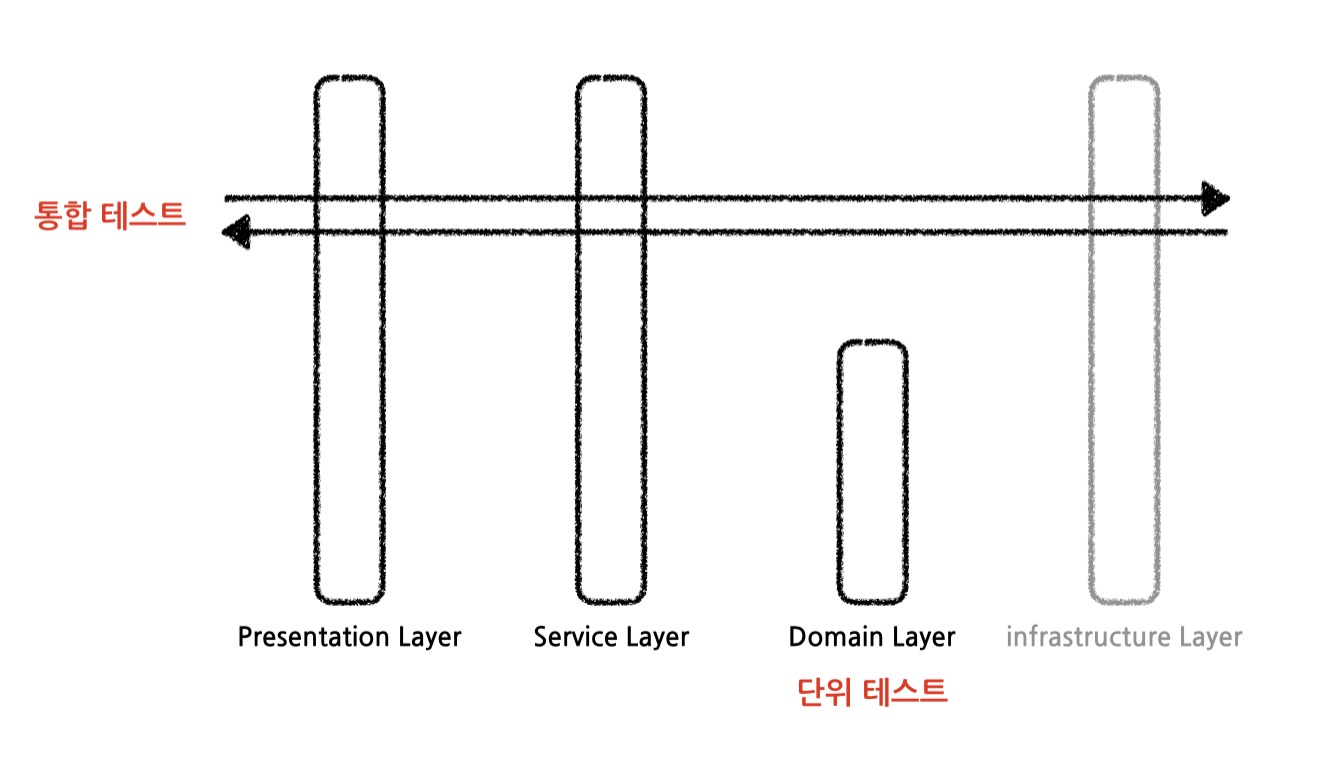
도메인 레이어는 단위 테스트하고, 나머지 모든 레이어를 묶어서 통합 테스트를 진행했는데요.
이렇게 하니 사실 상 서비스 레이어나 custom한 repository 레이어의 테스트가 없어 매번 수동 확인 작업을 거쳐야 했습니다.
그래서 다음과 같이 테스트 방식을 바꾸고 빠진 테스트를 모두 추가했습니다.
- Presentation Layer : Service Layer를 mocking한 API 확인 테스트
- Service Layer : 사실 상 이 친구가 통합 테스트
- Repository : (querydsl같은) custom한 repository에 대한 쿼리 테스트
- 그 외 도메인, 유틸 클래스 등 단위 테스트
테스트 자체에서도 피드백을 받은 내용이 있었습니다!
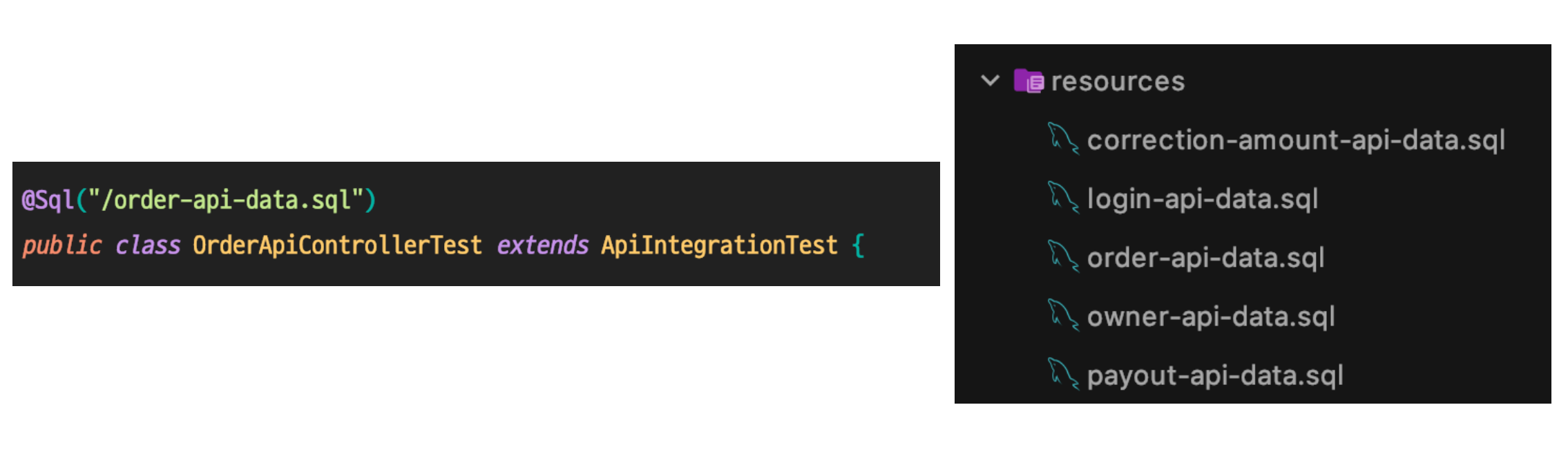
저는 테스트용 데이터 준비를 편리하게 하기 위해 data.sql을 사용하여 미리 데이터를 넣어놓는 방식으로 테스트를 작성하였는데요.
이럴 경우 각 테스트 별로 지금 어떤 데이터가 준비되어 있고, 어떤 상황이 주어졌는지를
해당 data.sql 파일을 찾아가서 열어봐야만 알 수가 있다는 명백한 단점이 존재합니다.
관리 포인트를 줄인다고 도메인 API 별로 파일을 쪼개놓기는 했지만, 결국 테스트의 given절이 불분명해지고 테스트의 내용을 쉽게 파악할 수 없게 되는 것이죠.
테스트는 테스트 자체로써 의미가 있을 뿐더러, API 문서 역할을 하기 때문에
각 테스트 메소드는 given-when-then의 형식을 지켜 무엇을 테스트하고자 하는지 명확히 보여줄 수 있어야 합니다.
그래서 기존의 data.sql들을 삭제하고 조금 귀찮아도 테스트할 데이터들을 given절에서 생성 및 저장하고 테스트를 진행하였습니다.
(현재 테스트할 내용과 크게 관련이 없지만 연관관계 설정 등의 이유로 필요했던 부수적인 데이터들은 @Before 절에서 미리 생성하여 사용하였습니다!)
@Ignore
@RunWith(SpringRunner.class)
@Transactional
@SpringBootTest
public class EntityServiceTest {
// ... 생략
}@Ignore
@RunWith(SpringRunner.class)
@Import(QuerydslConfig.class)
@DataJpaTest
public class EntityRepositoryTest {
// ... 생략
}또 위와 같이 Service나 Repository를 테스트할 때 더미 데이터를 롤백하기 위해 @SpringBootTest + @Transactional 조합을 쓰거나
@DataJpaTest를 사용했는데요.
(@DataJpaTest 안에도 @Transactional이 있습니다)
팀에서는 테스트 코드를 작성할 때 @Transactional을 사용하지 않는다고 조언해 주셨습니다!
롤백되는 기능은 편리하지만, 만약 트랜잭션이 보장되지 않았을 경우 실패하는 테스트를 작성했을 때 오히려 성공하는 경우가 많아서 사용하지 않는다고 하셨습니다.
그래서 다음과 같이 @SpringBootTest와 함께 @After절에서 모든 데이터를 직접 삭제하는 방식으로 테스트를 작성한다고 가이드해 주셨습니다.
public class OrderServiceTest extends EntityServiceTest { // @Transactional 제거한 EntityServiceTest
@Autowired
private OrderService orderService;
@Autowired
private OrderRepository orderRepository;
@Autowired
private OrderDetailRepository orderDetailRepository;
@Autowired
private OwnerRepository ownerRepository;
@Before
public void setUp() {
// 생략
}
@After
public void tearDown() {
orderDetailRepository.deleteAllInBatch();
orderRepository.deleteAllInBatch();
ownerRepository.deleteAllInBatch();
}
// ... 생략이 내용도 팀 By 팀 입니다!
@DataJpaTest는 테스트 시 필요한 Bean들만 띄워서 빠르게 테스트할 수 있다는 장점도 있어서 많은 분들이 사용합니다.
프로젝트가 끝날 무렵에는 기능 대비 아주 많은 테스트 수에 칭찬을 받기도 했습니다. 호홓
5-6주 차 : Spring Batch와 Jenkins X BeanStalk
마지막 5주 차와 6주 차 과제는 정산 어드민의 핵심인 Spring Batch 적용과 Jenkins, BeanStalk으로 배포 사이클 경험해보기였습니다.
젠킨스와 빈스톡은 경험이 많이 없었지만, 동욱님의 블로그 시리즈를 따라 하면서 나름 수월하게 경험해 보았습니다.
이 글에서는 배치 로직을 중점적으로 소개해 보려고 합니다!
배치에서는 야심 차게 동욱님이 최근 기술블로그 글에서 소개해 주신 QuerydslPagingItemReader를 사용해 보았습니다!ㅎㅎ
As-Is
@Slf4j
@RequiredArgsConstructor
@Configuration
public class PayoutCreationJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private final PayoutCollector payoutCollector;
private final PayoutCoreRepository payoutCoreRepository;
// (1)
private int chunkSize = 10;
@Bean
public Job payoutCreationJob() {
return jobBuilderFactory.get("payoutCreationJob")
.start(validateParameters(null, null))
.next(registerOrderDetailAmountsStep(null, null))
.next(registerCorrectionAmountAmountsStep(null, null))
.next(saveAllPayoutsStep())
.next(clearPayoutCollector())
.build();
}
// validateParameters 로직 생략
/**
* OrderDetail을 기준으로 각 Owner의 (지급금용) 주문 합계 금액을 가져온다.
* PayoutCollector Bean에 등록한다.
*/
@Bean
@JobScope
public Step registerOrderDetailAmountsStep(@Value("#") String startPayoutDate,
@Value("#") String endPayoutDate) {
return stepBuilderFactory.get("registerOrderDetailAmountsStep")
.<PayoutSubTotal, PayoutSubTotal>chunk(chunkSize)
.reader(payoutByOrdersReader(startPayoutDate, endPayoutDate))
.processor(payoutRegistrationOnCollectorProcessor())
.writer(customNoOperationItemWriter())
.build();
}
@Bean
@StepScope
public QuerydslPagingItemReader<PayoutSubTotal> payoutByOrdersReader(@Value("#") String startPayoutDate,
@Value("#") String endPayoutDate) {
LocalDate startDate = LocalDateFormatter.toLocalDate(startPayoutDate);
LocalDate endDate = LocalDateFormatter.toLocalDate(endPayoutDate);
log.info("startDate = ", startDate);
log.info("endDate = ", endDate);
List<PaymentMethod> paymentMethods = PaymentMethod.getPaymentMethodsIncludedInPayout();
return new QuerydslPagingItemReader<>(entityManagerFactory, chunkSize, queryFactory -> queryFactory
.select(Projections.fields(PayoutSubTotal.class,
order.occurrenceDate.as("payoutDate"),
owner.as("owner"),
orderDetail.amount.sum().as("totalAmount")
))
.from(orderDetail)
.join(orderDetail.order, order)
.join(order.owner, owner)
.where(order.occurrenceDate.between(startDate, endDate),
orderDetail.paymentMethod.in(paymentMethods),
order.canceled.isFalse())
.groupBy(owner, order.occurrenceDate)
.orderBy(owner.id.asc())
);
}
// (2)
@Bean
@StepScope
public ItemProcessor<PayoutSubTotal, PayoutSubTotal> payoutRegistrationOnCollectorProcessor() {
return payoutSubTotal -> {
log.info("payoutSubTotal ", payoutSubTotal);
payoutCollector.register(payoutSubTotal);
return payoutSubTotal;
};
}
// (2)
@Bean
@StepScope
public ItemWriter<PayoutSubTotal> customNoOperationItemWriter() {
return items -> {
};
}
/**
* CorrectionAmount를 기준으로 각 Owner의 (지급금용) 주문 합계 금액을 가져온다.
* PayoutCollector Bean에 등록한다.
*/
// registerCorrectionAmountAmountsStep 생략
/**
* PayoutCollector에서 모든 지급금을 만들어와서 repository에 저장한다.
*/
// saveAllPayoutsStep 생략
// ... 생략-
(1) chunkSize는 배치 로직에서 매우 중요한 값인데요.
해당 값은 @Value 애노테이션으로 외부에서 지정할 수 있도록 해야 한다는 피드백을 들었습니다!
내가 처한 상황에 따라 chunkSize를 유동적으로 가져가야 할 수 있어야 하기 때문입니다. -
(2) 현재 reader와 writer는 필수고, processor는 옵션이라서 processor에서 로직이 끝나고 writer는 비어있는 이상한 그림이 나왔는데요.
processor를 없애고 해당 로직을 writer에서 일괄처리하도록 구현해보라고 하셨습니다.
// (3)
@Bean
@JobScope
public Step clearPayoutCollector() {
return stepBuilderFactory.get("clearPayoutCollector")
.tasklet((contribution, chunkContext) -> {
payoutCollector.clear();
return RepeatStatus.FINISHED;
})
.build();
}
@Component // (3)
public static class PayoutCollector {
// 주문 상세 정보와 보정 금액 정보를 계산하여 지급금을 생성하는
// 임시 Batch 전용 Bean
}
}- (3) 저는 지급금을 생성하기 위해 PayoutCollector라는 배치 전용 Bean을 만들어서 사용하고 있었습니다.
아무 생각 없이 Bean이라는 생각에@Component라고 선언한 후 사용하니 관련 테스트 여러 개가 다 깨지는 상황이 벌어졌습니다.
이유는 배치에 사용되는 Bean들의 스코프와 일반적인 싱글톤 스코프의 차이 때문이었습니다.- 싱글톤으로 띄운 Bean은 테스트에 있는 모든 배치 로직들이 공유하는 단 하나의 Bean입니다.
그래서 데이터가 지속해서 쌓이기 때문에 문제가 생겼던 것이었습니다. - 급하게 해결한 것이 위의 clearPayoutCollector라는 Step을 하나 더 두어 매번 해당 Bean을 clear 하는 방법이었습니다.
- 하지만 해당 Bean을 @JobScope에서 생성하여 Bean으로 만들면, Bean의 생명 주기가 Job에 의존하게 됩니다.
따라서 해당 스코프에서 생성된 Bean은 Job이 시작될 때 생성되고, Job이 종료될 때는 Bean이 소멸하게 되어 기존에 문제였던 부분이 말끔하게 해결됩니다!
- 싱글톤으로 띄운 Bean은 테스트에 있는 모든 배치 로직들이 공유하는 단 하나의 Bean입니다.
수정한 로직은 다음과 같습니다!
To-Be
@Slf4j
@RequiredArgsConstructor
@Configuration
public class PayoutCreationJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private final PayoutCollector payoutCollector;
private final PayoutCoreRepository payoutCoreRepository;
@Value("$")
private int chunkSize;
@Bean
public Job payoutCreationJob() {
return jobBuilderFactory.get("payoutCreationJob")
.start(validateParameters(null, null))
.next(registerOrderDetailAmountsStep(null, null))
.next(registerCorrectionAmountAmountsStep(null, null))
.next(saveAllPayoutsStep())
.build();
}
// validateParameters 로직 생략
/**
* OrderDetail을 기준으로 각 Owner의 (지급금용) 주문 합계 금액을 가져온다.
* PayoutCollector Bean에 등록한다.
*/
@Bean
@JobScope
public Step registerOrderDetailAmountsStep(@Value("#") String startPayoutDate,
@Value("#") String endPayoutDate) {
return stepBuilderFactory.get("registerOrderDetailAmountsStep")
.<PayoutSubTotal, PayoutSubTotal>chunk(chunkSize)
.reader(payoutByOrdersReader(startPayoutDate, endPayoutDate))
.writer(customNoOperationItemWriter())
.build();
}
@Bean
@StepScope
public QuerydslPagingItemReader<PayoutSubTotal> payoutByOrdersReader(@Value("#") String startPayoutDate,
@Value("#") String endPayoutDate) {
LocalDate startDate = LocalDateFormatter.toLocalDate(startPayoutDate);
LocalDate endDate = LocalDateFormatter.toLocalDate(endPayoutDate);
log.info("startDate = ", startDate);
log.info("endDate = ", endDate);
List<PaymentMethod> paymentMethods = PaymentMethod.getPaymentMethodsIncludedInPayout();
return new QuerydslPagingItemReader<>(entityManagerFactory, chunkSize, queryFactory -> queryFactory
.select(Projections.fields(PayoutSubTotal.class,
order.occurrenceDate.as("payoutDate"),
owner.as("owner"),
orderDetail.amount.sum().as("totalAmount")
))
.from(orderDetail)
.join(orderDetail.order, order)
.join(order.owner, owner)
.where(order.occurrenceDate.between(startDate, endDate),
orderDetail.paymentMethod.in(paymentMethods),
order.canceled.isFalse())
.groupBy(owner, order.occurrenceDate)
.orderBy(owner.id.asc())
);
}
@Bean
@StepScope
public ItemWriter<PayoutSubTotal> customNoOperationItemWriter() {
return items -> {
for (PayoutSubTotal item : items) {
log.info("payoutSubTotal ", item);
payoutCollector.register(item);
}
};
}
/**
* CorrectionAmount를 기준으로 각 Owner의 (지급금용) 주문 합계 금액을 가져온다.
* PayoutCollector Bean에 등록한다.
*/
// registerCorrectionAmountAmountsStep 생략
/**
* PayoutCollector에서 모든 지급금을 만들어와서 repository에 저장한다.
*/
// saveAllPayoutsStep 생략
@Bean
@JobScope
public PayoutCollector payoutCollector() {
return new PayoutCollector();
}
}나오며
두 달여 간의 길고 긴 파일럿 프로젝트도 드디어 끝이 났습니다.
처음부터 끝까지 모든 영역에 대해 팀이 아닌 혼자서 설계하고 구현해 보았는데요.
정말 느낀 바가 많았습니다.
팀으로 함께 할 때는 모두가 각자 잘하는 영역을 맡음으로써 서로의 부족한 점을 채워주는 장점이 있었습니다.
아! 이게 ‘스타보다 팀웤’이라는 말의 의미인가보다!
하지만 혼자서 해보니 내가 무의식적으로 회피하면서 다른 사람에게만 의지하고 있었던 영역들이 겉으로 드러나고,
앞으로 내가 공부하면서 채워나가야 할 방향성이 명확하게 보이기 시작했습니다.
‘스타보다 팀웤’이라는 말에는 팀에서 비록 (상대적으로) 스타 역할을 하는 팀원이 빠지더라도,
팀이 온전하게 팀으로 역할을 할 수 있어야 한다는 의미도 포함되지 않을까 싶었습니다.
팀이 온전하게 팀으로 활약할 수 있도록, 제 개인적으로도 성장의 끈을 놓지 말아야겠다는 굳은 다짐을 하게 되었습니다ㅎㅎ
긴 글 읽어주셔서 감사드리며, 저는 앞으로 멋진 정산지기로 성장해 보겠습니다! 지켜봐 주세요! 🙂
