배달의민족 최전방 시스템! ‘가게노출 시스템’을 소개합니다.

안녕하세요 우아한형제들 프론트검색서비스팀 권용근입니다.
저는 "먼데이 프로젝트" 라는 2019년 대형 프로젝트에서 요란하게 탄생하였고, 탄생한 순간부터 지금까지 배달의민족 최전방에서 활약 중인 2019년 4월 1일생 가게노출 시스템 을 소개하려고 합니다.
가게노출 시스템이란?
가게노출 시스템 은 배달의민족 최전방에서 사용자에게 가게를 노출하는 시스템입니다.
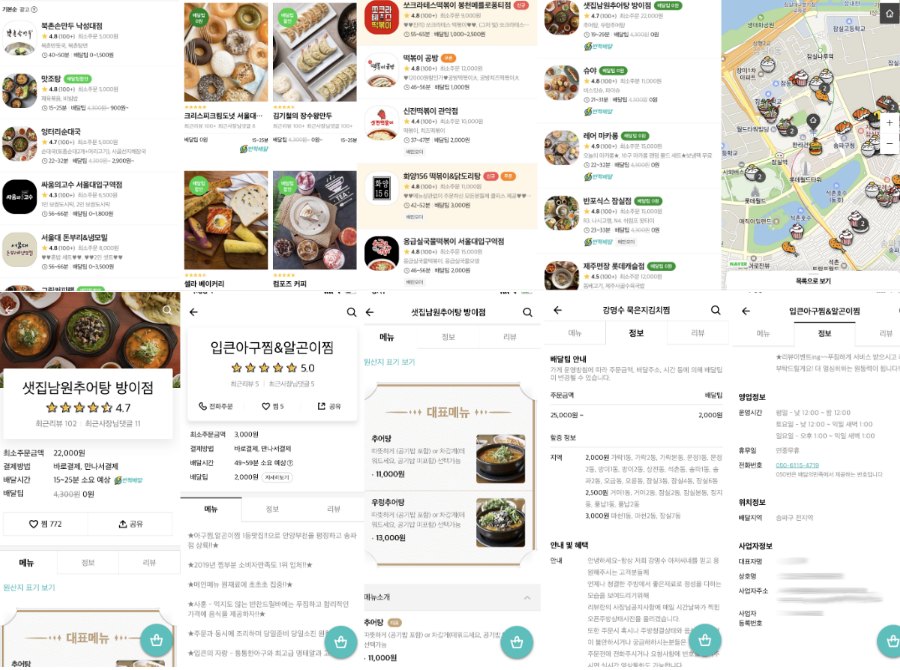
쉽고 단순하다고 생각할 수 있지만, 사실 이 시스템은 매우 복잡하고 어지러운 시스템입니다. 단순히 캐시를 서빙하는 것이 아닌, 십여개의 외부 시스템과 수십개의 실시간 정보를 교환 하고, 십여개의 플랫폼 시스템의 데이터를 조합 하여, 시간, 위치를 기반으로 실시간 계산 된 가게 정보를 제공하고 있습니다.
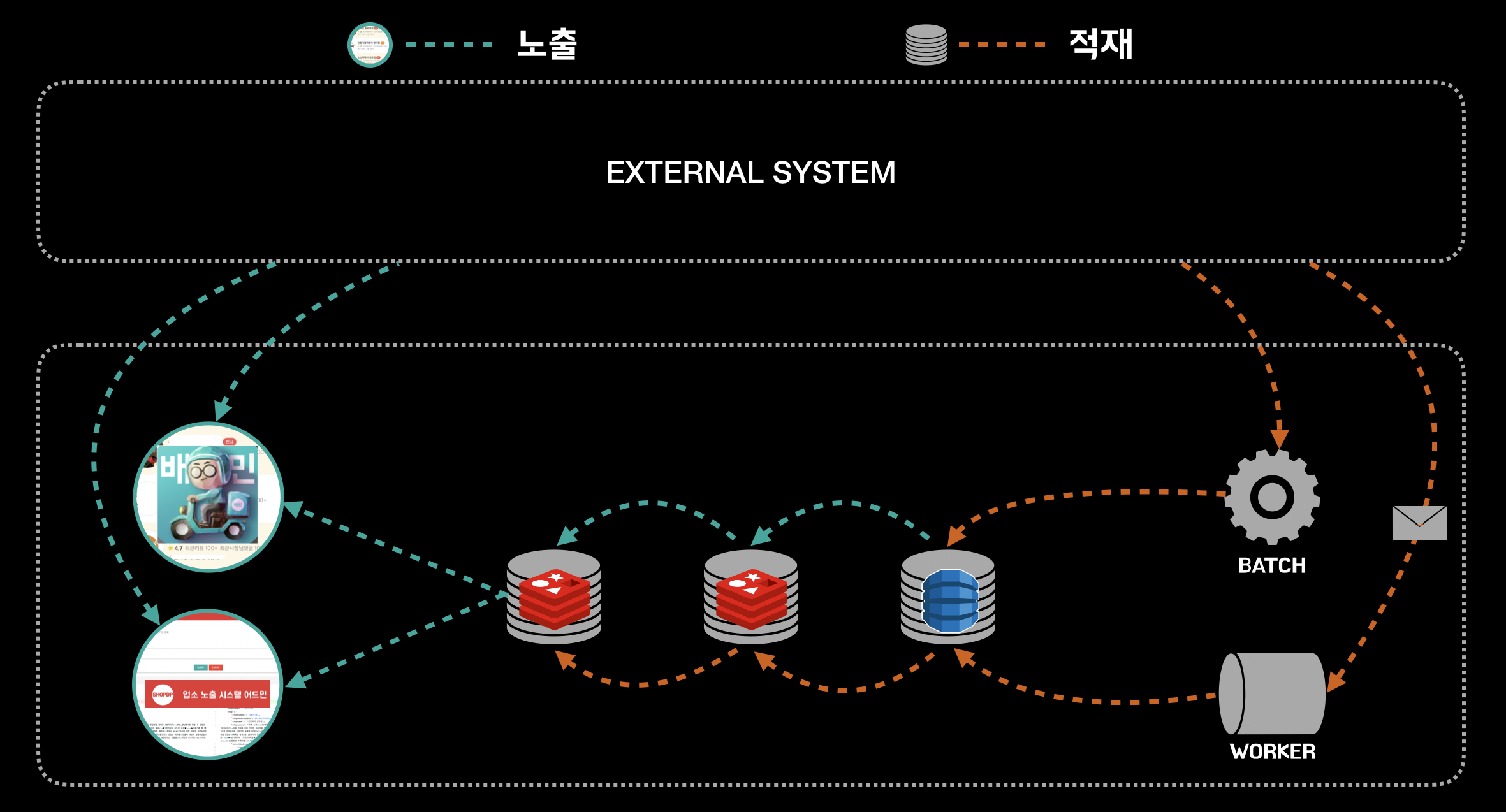
배달의민족 최전방 시스템으로서 최적의 환경을 찾기 위한 지난 1년간의 도전을 정리하여 공유해보고자 합니다.
1. WebFlux
도전의 첫번째 선택은 WebFlux 였습니다. WebFlux 는 리액티브 프로그래밍 을 가능하게 해주는 Spring Framework 의 기술스택 중 하나입니다.
Spring Framework 개발자가 말하는 리액티브 프로그래밍 은 인프라 스트럭처에 대한 도전이라고 합니다. 인프라 스트럭처의 리소스를 효율적으로 운용하기 위한 고민이 시작되었고, WebFlux 는 Event-Driven 과 Asynchronous Non-blocking I/O 을 통해 리소스를 효율적으로 사용할 수 있도록 하였고, 그 도구로 Reactor 를 선택했습니다.
가게노출 시스템은 배달의민족 앱 내에서 가장 많은 트래픽을 소화하는 시스템으로, 다음과 같은 리소스 최적화가 반드시 필요했습니다.
- 하나의 사용자 요청을 처리하기 위해 수십여개의 외부 시스템에 대한 요청이 필요한 시스템에서, 어떻게 가장 빠른 응답을 줄 수 있을까?
- 수많은 요청을 처리해야할 때 어떻게 쓰레드 지옥을 벗어날 수 있을까?
Asynchronous
사용자들에게 정확한 실시간 데이터를 제공하기 위해 가게노출 시스템은 요청당 수십개의 실시간 정보를 획득하여야 합니다. 이 때 유용하게 작용될 수 있는 것이 비동기 동작 입니다.
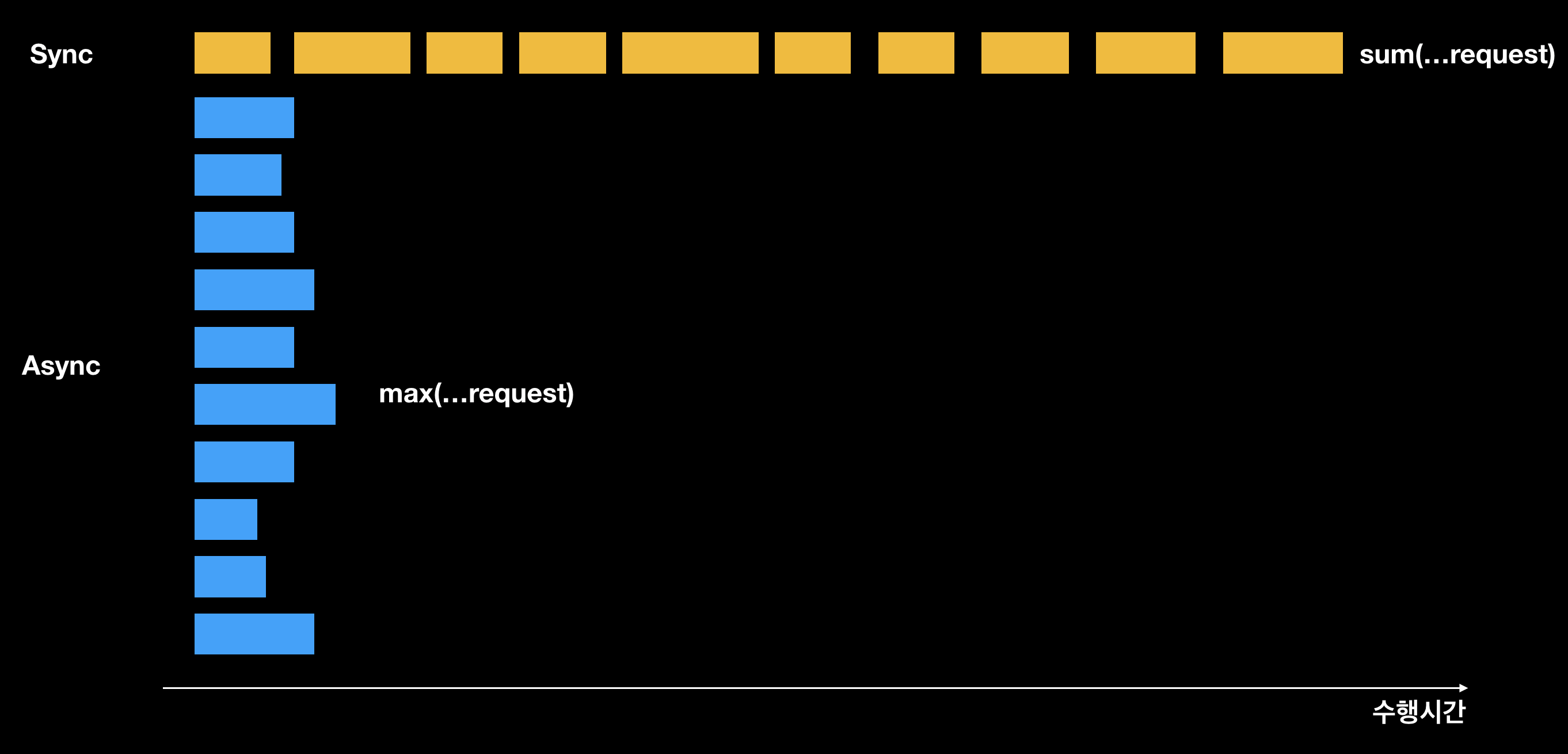
수십개의 동작이 동기 로 이루어질 때 수행시간은 전체 요청 수행시간의 합 이지만, 비동기 로 이루어질 때 수행시간은 전체 요청 수행시간 중 최대 가 됩니다. 동시 요청 수가 적을 때는 큰 장점이 없을 수 있지만, 수십개의 요청이 동시에 필요한 시스템에서는 비동기 동작으로 인해 큰 이득을 얻을 수 있습니다.
Non-blocking, Event-Driven
아무리 비동기 동작이 가능하다고 하더라도, Blocking IO 기반의 동작을 하게 된다면 우리는 쓰레드 지옥에서 벗어날 수 없습니다.
아래 그림은 단일 스레드 상황 에서 blocking I/O 와 non-blocking I/O 를 나타낸 것 입니다.

아래 작업은 작업량과 쓰레드 수 증가에 대한 blocking I/O 와 non-blocking I/O 를 나타낸 것 입니다.
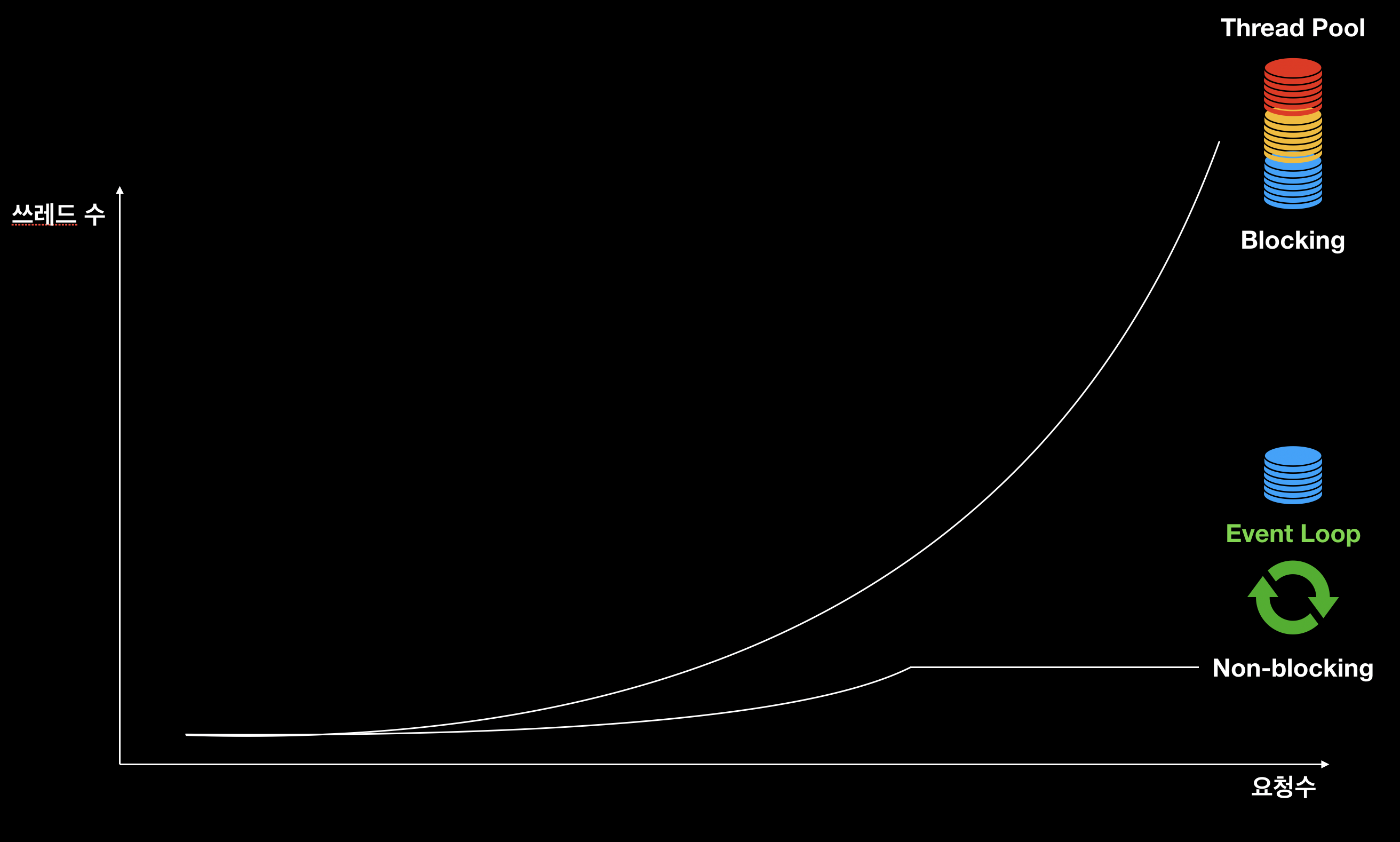
NIO 로 쓰레드가 대기하지 않으며, Event-Driven 방식으로 적은 수량의 쓰레드로도 리소스를 최적화하여 운영할 수 있게 설계되어 있기 때문에 비동기 작업과 맞물려도 최적의 동작을 가능하게 해줍니다.
WebFlux는Event-Driven과Asynchronous Non-blocking I/O을 통해 리소스를 효율적으로 사용할 수 있도록 하였고,가게노출 시스템은 이러한 동작으로 인해 성능적인 많은 이득을 얻을 수 있었습니다.
가게노출 시스템은 2019년 4월 1일, 모든 코드를 WebFlux, Reactor 로 작성하여 배포되었습니다.
2. 데이터 스토어
두번째 도전은 새로운 저장소 아키텍처 입니다. 배달의민족은 MSA 를 추구하고 있고, 현재 거의 모든 시스템이 독립 시스템으로 분리되어 Micro System 을 이루고 있습니다.
최전방에 위치한 가게노출 시스템은 MSA를 기반으로 분리된 십여개 시스템들의 원본 데이터를 적재하고, 가공하여 사용자들에게 제공할 수 있어야 합니다.
- 어떻게 사용자에게 빠른 응답을 줄 수 있을까?
- 어떻게 수백 종류의 이벤트와 데이터를 어떻게 안정적으로 소화해낼 수 있을까?
- 어떻게 장애 상황에서도 사용자에게 데이터를 안정적으로 제공할 수 있을까?
- 어떻게 장애가 발생했을 때 빠르게 복구할 수 있을까?
위와 같은 고민을 통해 Redis 와 DynamoDB 2개의 저장소를 사용했고, 캐시 아키텍처를 만들었으며, Reactor 를 활용한 이벤트 처리기를 구축하였습니다.
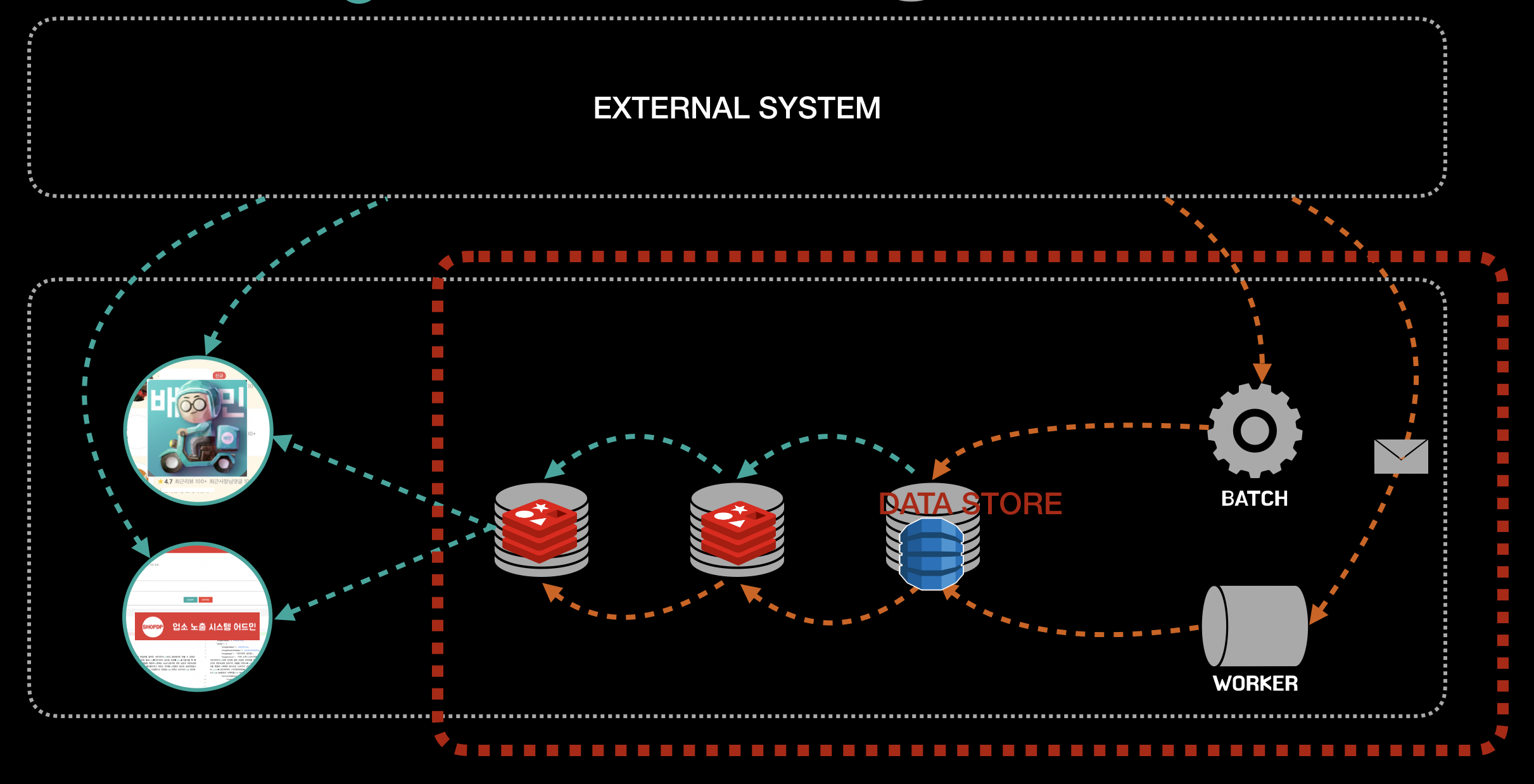
그리고 데이터에 대한 저장, 조회를 책임지는 계층에 데이터 스토어 라는 이름을 붙여주었습니다.
저장소
저장소 요구사항
-
대용량 트래픽에서 조회, 저장 속도가 빨라야 합니다. (초당 수만개의 가게 정보를 처리)
-
쿼리를 지원해야 합니다. (고객 접점의 이슈, 장애에 빠르게 대응)
-
NIO를 지원해야 합니다. (리소스 사용 최적화) -
AWS에서 관리가 가능해야 합니다. (서비스 개발에 집중할 수 있는 환경)
DynamoDB

선택된 첫번째 저장소는 DynamoDB 입니다. DynamoDB 는 AWS 에서 제공하는 완전관리형 데이터베이스로, 원하는 요구사항을 모두 만족한 듯 보였습니다.
그러나 우리는 이미 DynamoDB 를 경험하며, 가지고 있는 문제점에 대해서도 잘 알고 있었습니다.
첫번째로 문제가 되는 것은 DynamoDB 의 Throughput 입니다.
DynamoDB 는 일관된 응답 속도를 보장하지만, 지정된 Throughput 의 범위를 초과할 경우 요청이 거절됩니다. 그렇기 때문에 요금에 대한 최소화를 하기 위해서는 예정된 스케줄 단위의 프로비저닝을 해주거나, 온디맨드 요금 정책을 사용해야 합니다. 그러나 이 모든 것이 예측이 가능해야 한다는 것이 가장 큰 문제점입니다. 우리는 모든 것을 예측할 수 없다고 확신합니다.
두번째 문제점은 Throughput 단위가 파티션 단위로 책정된다는 것 입니다.
실제로 몇 차례 원인을 알 수 없는 Throttling 이 발생하였었고, AWS 측에 문의해본 결과 특정 파티션에 요청이 몰렸었다는 응답받았었습니다. 배달의민족 시스템의 특성상, 데이터를 고르게 파티션에 분배한다는 것은 불가능하다고 생각을 합니다.
여러가지 문제점을 알고 있었지만, DynamoDB 가 가지고 있는 여러 장점을 포기할 수 없었기에 우리는 DynamoDB 를 주 저장소로 사용하고, DynamoDB 의 단점을 보완해줄 저장소를 찾았습니다.
Redis

선택된 두번째 저장소는 Redis 입니다. Redis 는 이미 너무나도 잘 알려져있는 저장소로, AWS 에서 ElastiCache 라는 이름으로 관리형 서비스 또한 제공되고 있습니다.
여러 데이터 자료형을 제공하지만 거의 대부분 KEY-VALUE 로 사용될 것이기에, DynamoDB 보다 더 빠른 처리가 가능하며, 요금 또한 DynamoDB 보다 훨씬 저렴한 것을 확인했습니다.
그래서 Redis 는 사용자에게 더 빠른 응답을 제공할 수 있는 캐시 저장소로 사용하게 되었습니다.
저장소 레이어링
가게노출 시스템은 크게 3개 레이어의 저장소를 운영하고 있습니다.
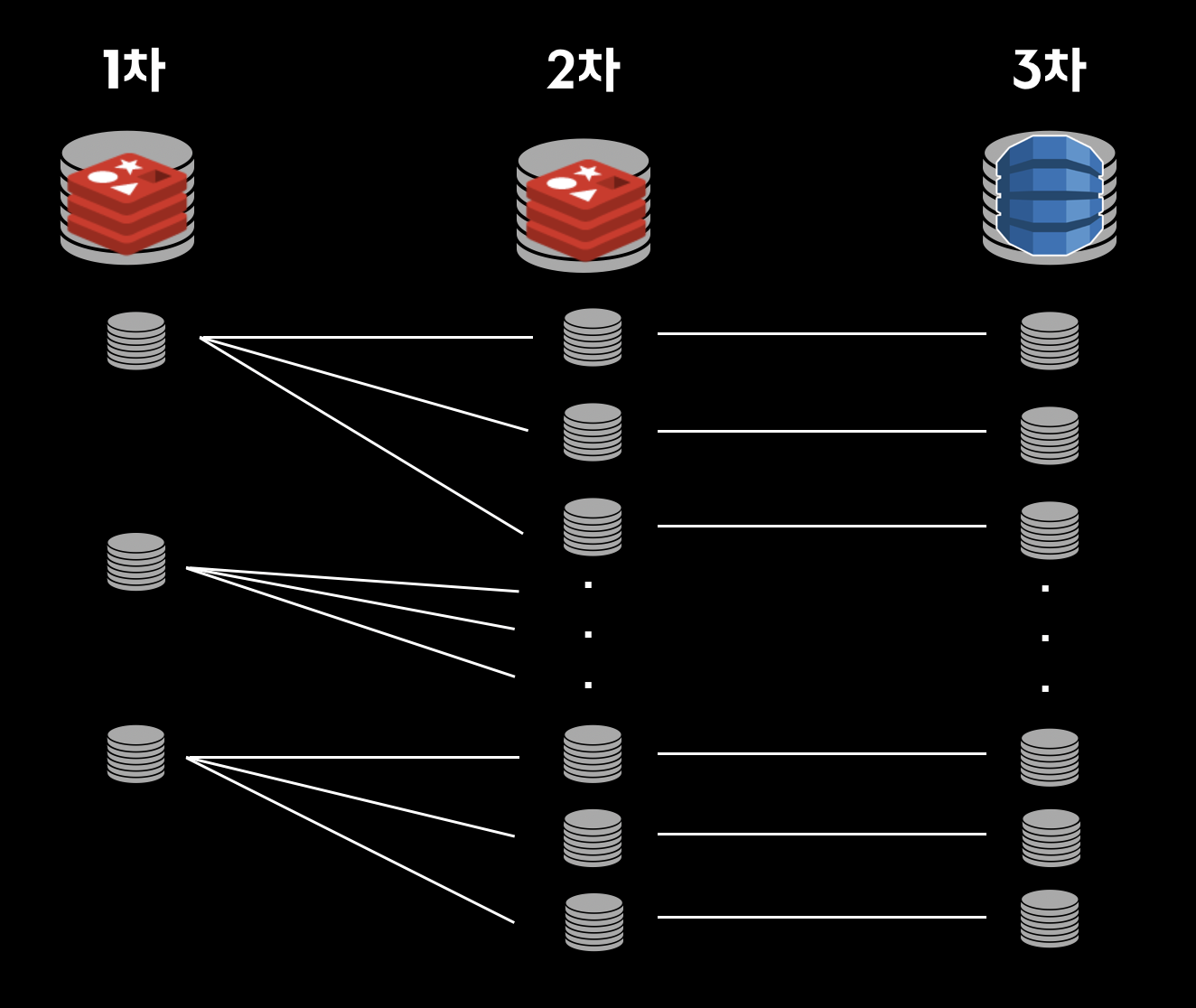
3차 는 DynamoDB 로 원본 형태의 데이터를 저장하는 주 저장소로, 데이터의 조회 및 Fallback 동작의 종단으로 사용되고 있습니다.
2차 는 Redis 로 3차 저장소의 캐시 역할을 하고 있으며, 정밀한 고속 데이터에 대한 처리를 위해 사용되고 있습니다.
2,3차 저장소 는 연동하고 있는 플랫폼 시스템과 1:1 로 대응되는 저장소 로, 각 플랫폼 시스템 데이터의 생명주기를 고려하여 작성된 원자적 단위입니다.
1차는 Redis 로 가게노출 서비스를 위한 저장소입니다. 1차 저장소의 데이터는 각 플랫폼 시스템의 데이터를 서비스향의 응집성과 생명주기를 고려한 단위로 재구성된 데이터 저장소 입니다. 간단한 예로 가게, 업주 의 플랫폼 데이터는 분리되어 있지만, 서비스에서는 하나의 데이터로 사용되기 때문에 데이터를 뭉쳐 재구성한 서비스향의 가게 데이터가 있을 수 있습니다.
가게노출 시스템은 이렇게 3개의 레이어로 저장소를 분리했으며, 분리된 저장소는 각종 장애 대응에서도 유용하게 동작하고 있습니다.
3개 레이어로 분리된 저장소에서 초당 수십만의 조회가 발생하고 있습니다.
캐시 정책
데이터 갱신, 조회에 대한 정책입니다.
데이터 갱신
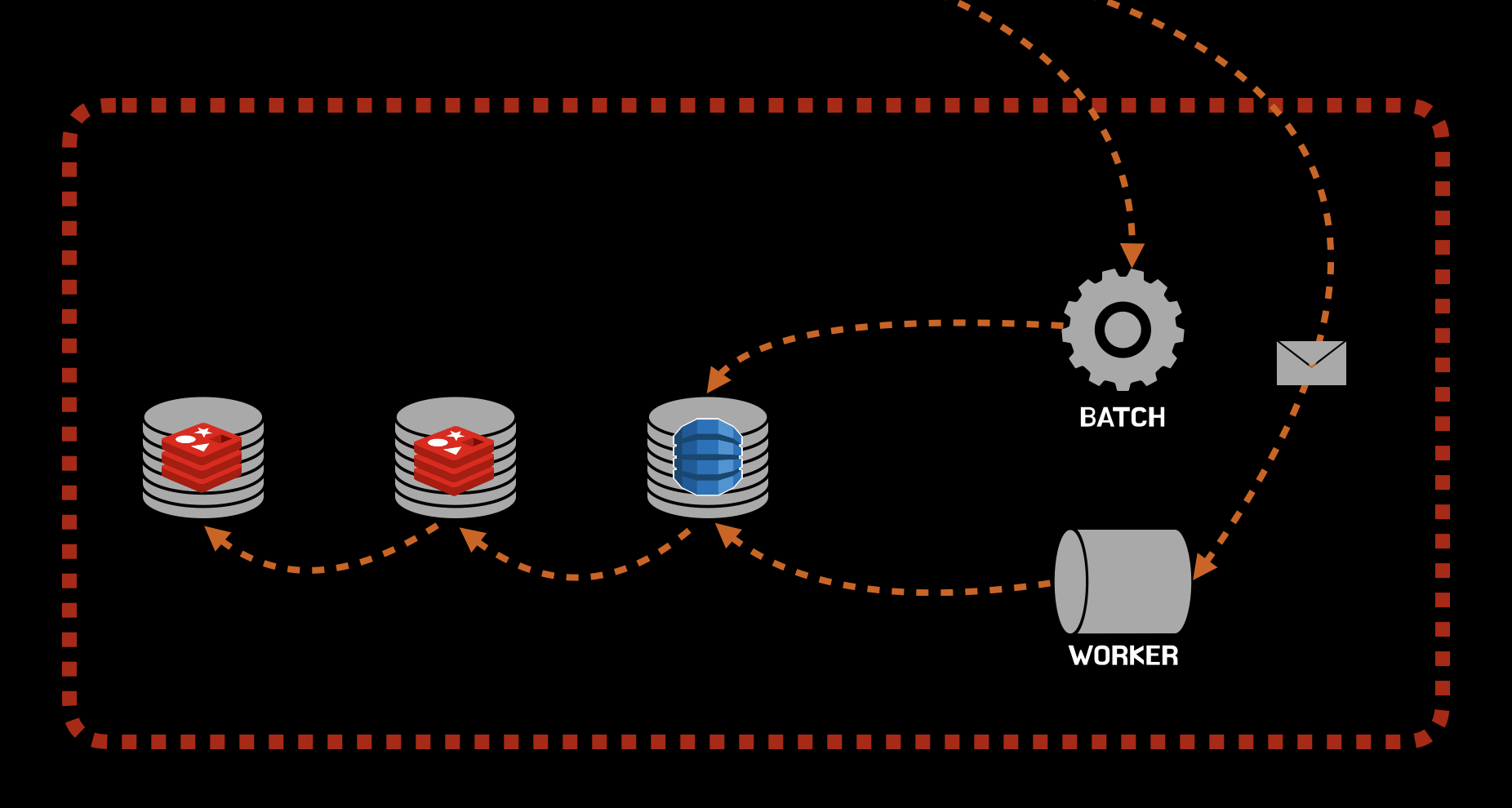
데이터 갱신은 Event 를 처리하는 Worker 혹은 Batch 로부터 시작되어 원본 데이터를 가공하여 저장하게 됩니다. 데이터의 저장은 주 저장소인 DynamoDB 에서부터 캐시 저장소인 Redis 로 순차적으로 진행됩니다.
DynamoDB데이터 갱신2차 Redis데이터 갱신1차 Redis갱신 이벤트 발행- 이벤트 수신 후
1차 Redis데이터 갱신
데이터를 갱신할 때 캐시 저장소를 지우고 추후 읽기 동작에 의해 갱신되는 정책을 사용할 수도 있지만, Cache 가 만료된 사이에 요청이 몰릴 경우 사용자에게 느린 응답이 제공될 수 있기 때문에 기본적인 캐시 갱신 정책은 주 저장소부터 순차적으로 갱신하는 전략을 선택했습니다.
데이터 조회
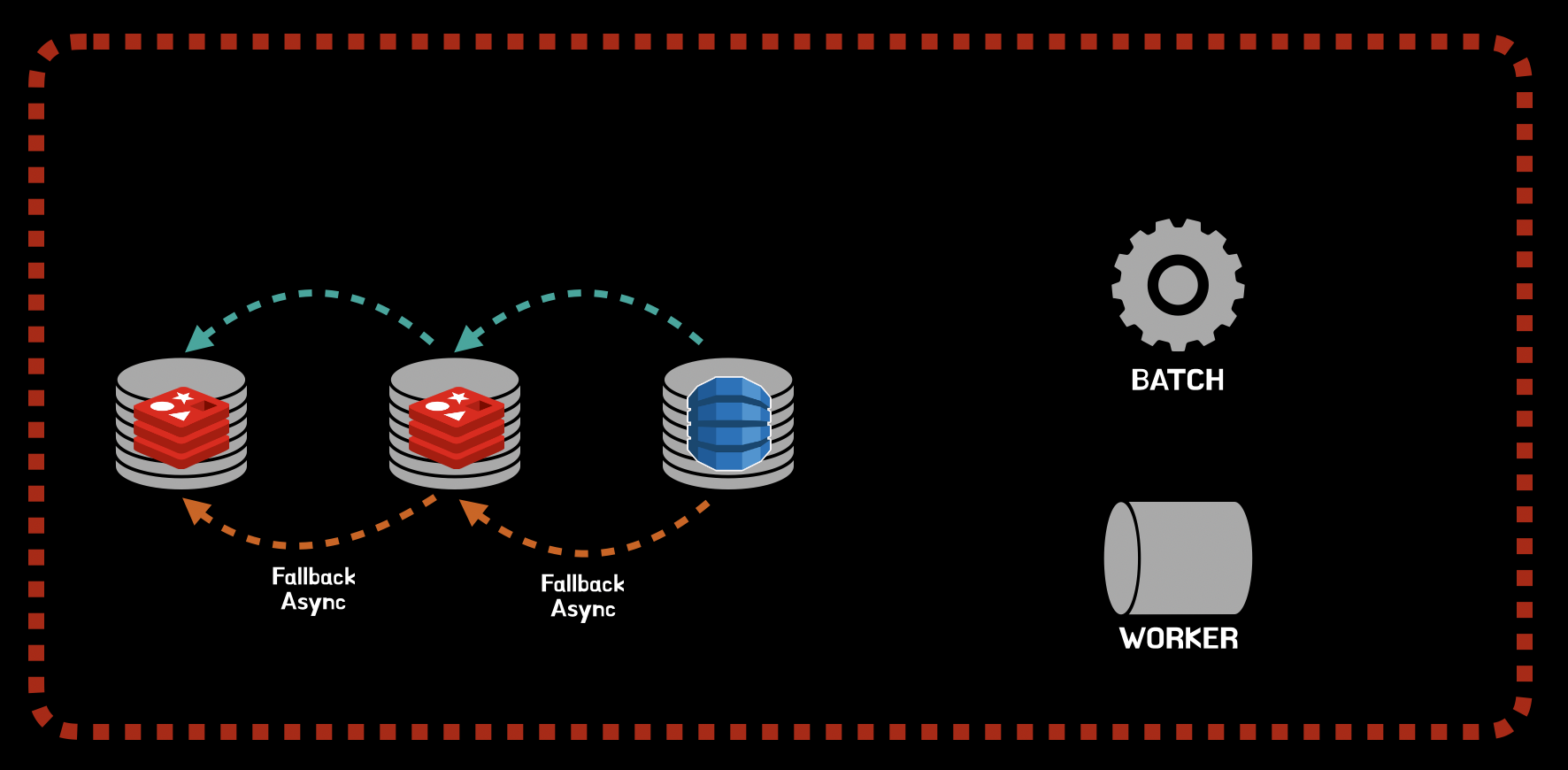
조회는 우리가 흔히 알고 있는 Cache 정책인 캐시에 데이터가 있으면 캐시에서 반환하고, 캐시에 데이터가 없으면 fallback 동작으로 데이터를 반환한 후 캐시를 갱신하는 전략을 사용하고 있습니다. 이 때 Fallback 동작 후 캐시에 저장하는 동작은 비동기 처리되도록 구성하고 있습니다.
Reactor 를 사용하면 Spring Framework 에서 기본으로 제공하는 기능을 사용하기 어렵기도 하며, 어노테이션으로 동작하는 메타 프로그래밍을 더 이상 지향하지 않기 때문에 직접 구현을 하였습니다.
Interface
Mono<CacheData<T>> get(ID id);
Mono<T> put(ID id, T data);
Mono<Boolean> evict(ID id);Implementation
public Mono<CacheData<T>> cacheable(ID id, Function<ID, Mono<T>> fallback) {
return get(id)
.onErrorResume(throwable ->
Mono.defer(() -> fallback(id, fallback, false))
)
.switchIfEmpty(
Mono.defer(() -> fallback(id, fallback, true))
);
}
private Mono<CacheData<T>> fallback(ID id, Function<ID, Mono<T>> fallback, boolean writeBack) {
return fallback.apply(id)
.doOnNext(data -> {
if(writeBack) {
put(id, data)
.onErrorResume(throwable -> Mono.empty())
.subscribe();
}
})
.map(CacheData::of);
}Test
StepVerifier.create(
cacheService.cacheable(1L, id -> Mono.just(new Person(1L, "bbode", "king")))
.map(CacheData::getData)
)
.consumeNextWith(person -> assertThat(person.getFirstname()).isEqualTo("bbode"))
.verifyComplete();Event Worker Application
가게노출의 이벤트를 처리하는 시스템인 Event Worker 는 AWS SQS 로 수신된 이벤트를 처리하는 시스템입니다.
이전 Thread Model 을 사용하던 시스템에서는 ThreadPool 기반으로 이벤트 소비를 컨트롤하였지만, Reactor 를 사용하는 시스템에서는 더 효율적인 처리를 해보았습니다.
FluxSink
FluxSink 는 반응형 스트림 으로 소비자에게 여러 요소에 대한 전송을 지원합니다.
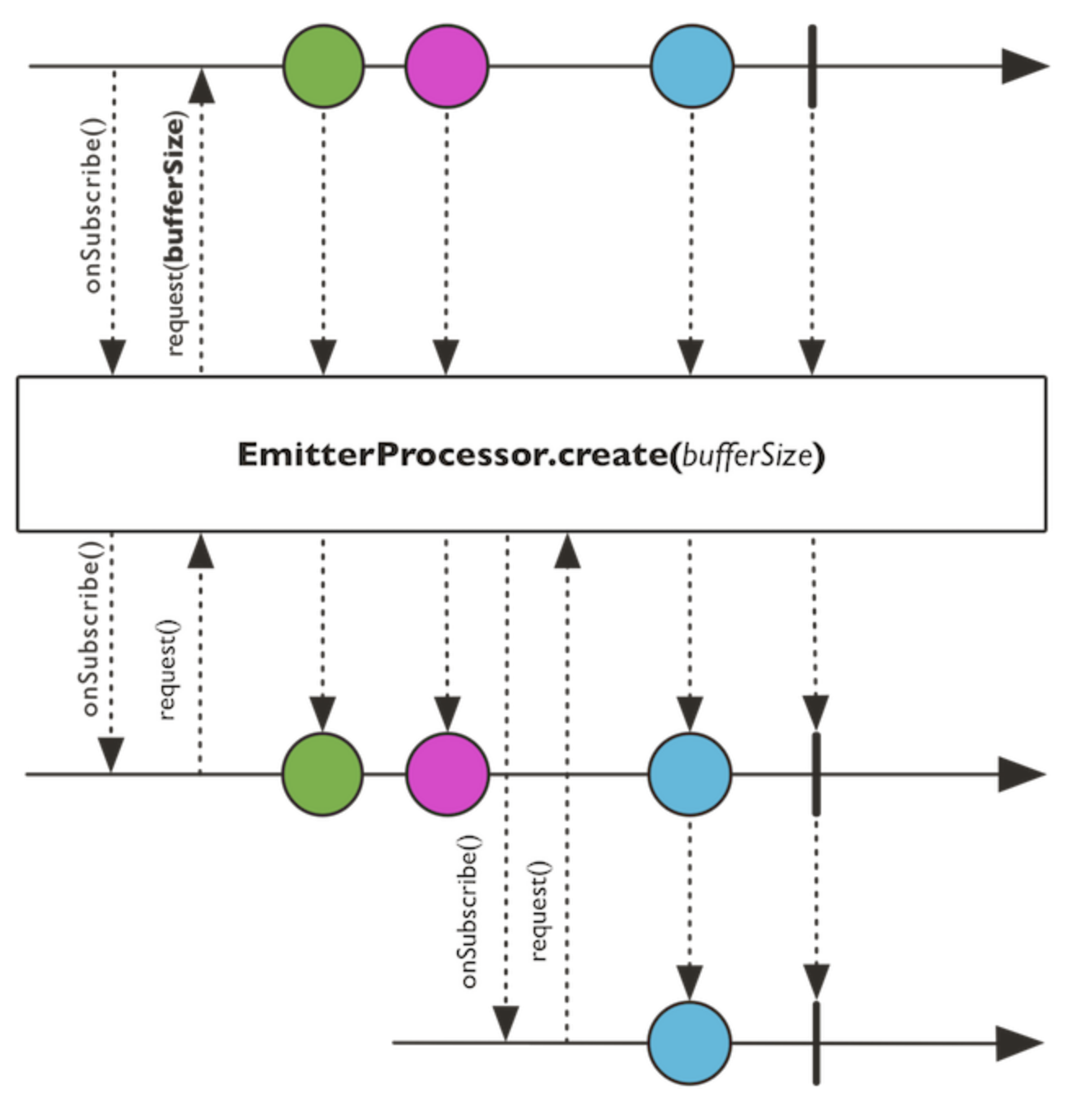
FluxSink 이벤트 처리를 위한 다양한 구현체가 존재하며, 각 시스템 특성에 맞는 구현체를 선택 가능합니다. 가게노출 시스템은 기본 구현체 중 하나인 EmitterProcessor 를 사용하고 있습니다.
@SqsListener(value = "$", deletionPolicy = SqsMessageDeletionPolicy.NEVER)
public void listen(@Payload AdOngoingListingPayload event, Acknowledgment ack) {
consumeProcessor.sink(SinkData.of(event, ack));
}listen 메서드는 sink 라는 비동기 메서드를 호출한 직후 즉시 종료됩니다. 그 후 이벤트에 대한 처리는 모두 FluxSink 구현체에게 위임하고 있습니다.
sink 진입 이후에는 Asynchronous Non-blocking I/O 로 동작하기 때문에 리소스에 최적화된 이벤트를 처리할 수 있습니다. 구현체에서는 SQS 이벤트 acknowledge 처리 및 로그 적재, 배압 조절, 실패 처리를 담당합니다.
Back Pressure
Reactive Programming 의 가장 큰 장점 중 하나는 바로 배압 조절이 가능하다는 것입니다.
가게노출 시스템의 Event Worker 에서 몇 번의 장애 가 있었습니다. 장애시마다 생겼던 문제점은 Event Worker 가 이벤트를 소비하지 못하는 동안 누적되어 쌓여버린 대량의 이벤트들입니다.
이벤트를 수신하는 Thread 는 FluxSink 로 이벤트를 던지는 역할만 하게 되어있기 때문에 장애 후 재기동시 쌓여있던 이벤트들이 엄청난 속도로 FluxSink 로 들어오게 됩니다. 이런 경우 FluxSink 의 core 쓰레드가 사망하게 되어 더 이상 이벤트 처리가 불가능합니다.
이 때 유용하게 사용할 수 있던 것이 Back Pressure 설치입니다. 스트림 처리에 대한 요청량과 속도를 적절히 조절하여 시스템에 안정적인 흐름만 흐르도록 작성할 수 있었습니다.
사용한 것은 delaySequence, limitRate 의 조합으로, 시간당 최대 처리량을 조절하였습니다.
100ms 당 최대 2개 의 이벤트만 처리할 수 있도록 아래와 같이 구성하였을 때
Flux.range(0, 10)
.delaySequence(Duration.ofMillis(100))
.limitRate(2)
.doOnNext(integer -> log.info("i = ", integer))
.collectList()
.block();의도대로 잘 처리되는 것을 확인할 수 있습니다.
19:39:23.035 [parallel-1] INFO Test - i = 0
19:39:23.038 [parallel-1] INFO Test - i = 1
19:39:23.142 [parallel-1] INFO Test - i = 2
19:39:23.143 [parallel-1] INFO Test - i = 3
19:39:23.243 [parallel-1] INFO Test - i = 4
19:39:23.243 [parallel-1] INFO Test - i = 5
19:39:23.348 [parallel-1] INFO Test - i = 6
19:39:23.348 [parallel-1] INFO Test - i = 7
19:39:23.452 [parallel-1] INFO Test - i = 8
19:39:23.452 [parallel-1] INFO Test - i = 9실제 위와 같은 동작을 직접 구현하려면 복잡한 이해가 필요하겠지만, Reactor Project 에서 여러 편의성 기능을 잘 만들어놓아 비교적 쉽게 설치할 수 있었습니다.
가게노출 시스템에서는 초당 약 100여개의 이벤트로 인한 갱신이 이루어지고 있습니다.
Batch Application
배치는 아래와 같은 목적으로 작성되었습니다.
- 언제든 처음부터 모든 데이터를 적재할 수 있어야한다.
- 언제든 특정 시점으로부터 데이터를 재갱신할 수 있어야 한다.
- 언제든 특정 데이터를 갱신할 수 있어야 한다.
가게노출 시스템은 연계된 모든 플랫폼 시스템들에게 위와 같은 조건의 스팩을 약속하고 있습니다.
언제든 처음부터 모든 데이터를 적재할 수 있어야 한다
저장소를 이전하거나, 새로운 형태로 재개편, 재구성을 해야할 때 유용하게 사용될 수 있었습니다. 또한 데이터 정합성의 보정을 위해, 매일 새벽 모든 데이터를 재갱신하고 할 때도 사용되고 있습니다.
언제든 특정 시점으로부터 데이터를 재갱신할 수 있어야 한다
Event Worker 시스템의 장애가 발생하여, 약 2시간동안 데이터를 갱신할 수 없었던 적이 있습니다. 이 때 특정 시점 기반의 배치 프로그램을 1분 주기로 장애 복구시까지 사용하여, 사용자 영향없이 장애를 해소할 수 있었습니다.
언제든 특정 데이터를 갱신할 수 있어야 한다
특정 데이터의 빠른 복구 혹은 갱신을 위해, 플랫폼 시스템으로부터의 요청 혹은 고객의 요청으로 데이터를 갱신할 때 유용하게 사용되고 있습니다.
배치 프로그램을 상시로 사용하고 있지는 않지만, 모든 예외적인 상황을 회피할 수 있도록 개발하여 사용되고 있습니다.
Reactor 에서 배치 개발?
Spring Framework 5 가 등장하고 WebFlux 가 공식적인 기술스택에 올랐지만, Spring Batch 가 이를 지원하고 있지는 않습니다. 가게노출 시스템은 모든 코드가 Reactor 베이스로 작성되어 있지만 Spring Batch 를 여전히 사용하고 있습니다.
Spring Batch 에서 사용되는 Reactor 코드들은 모두 block 이라는, 동기를 지원하는 코드를 사용하고 있습니다.
@Bean(STEP_NAME + "Writer")
@StepScope
public ItemWriter<CompositeProcessorResult<HistoryMeta<ShopResponse>, Shop>> dataItemWriter() {
return results -> {
List<Shop> items = results.stream()
.map(CompositeProcessorResult::getResult)
.collect(Collectors.toList());
try {
shopDataCommandService.batchUpdate(items)
.doOnError(throwable -> log.error("Shop Update 실패", throwable))
.block(); //here
} catch (Exception e) {
throw new IllegalStateException(e);
}
};
}Spring Batch 는 그 자체로 최적화된 데이터 조회, 가공, 저장의 흐름을 이미 제공하고 있습니다. Reactor 를 사용하지만, Spring Batch 에서는 Spring Batch 의 흐름을 더 우선시 하여 개발하고 있습니다.
(각종 알람에는 제가 좋아하는 분들의 얼굴들을 사용하고 있습니다..)
가게노출 시스템에는 약 70개의 배치 JOB 이 존재하고, 모든 배치 JOB이 1회 이상 수행되었으며, 1년 간 약 4000회 실행되었습니다.
3. 서비스 어플리케이션
마지막 세번째 도전은 위의 두 도전에서 선택한 WebFlux, 데이터 스토어 를 사용하여, 사용자에게 최적화된 서비스를 안정적으로 제공하는 일이었습니다. 배달의민족 앱으로부터 가장 많은 트래픽을 소화해야하는 시스템을 만드는 일이기도 합니다.
테스트
구체적으로 언급할 수는 없지만, 가게노출 시스템에는 책임져야 할 수많은 비지니스 정책들이 있습니다.
간단한 예로 배달팁, 예상시간, 운영여부 관련 정책, 그리고 노출 시스템의 피할 수 없는 숙명인 노출 형태에 대한 수많은 비지니스정책 등이 있습니다.
모든 것을 아름답게 테스트하고 있지는 않지만, 비지니스를 보호하고 안정적으로 개발을 하기 위해 테스트 코드 작성을 필수 조건으로 규칙을 정하여 꾸준히 테스트 갯수를 늘려가고 있으며, 현시간 기준 어느덧 1300여개의 테스트가 시스템을 보호하고 있습니다.
(각종 알람에는 제가 좋아하는 분들의 얼굴들을 사용하고 있습니다..)
장애 전파 방지
안정적인 서비스를 위한 중요한 요소를 장애 전파 로 생각합니다. 계속 언급한 것처럼 가게노출 시스템에서는 수십개의 실시간 정보를 교환 하고, 십여개의 플랫폼 시스템의 데이터를 조합 하고 있습니다. 어느 한 시스템에서든 장애가 발생했을 때에도 사용자에게 최소한의 영향을 줄 수 있는 시스템을 만들기 위해 노력했습니다.
Circuit Breaker (Resilience4j)
Circuit Breaker 는 동작에 대한 오류가 발생시에 회로를 차단하여 계단식으로 퍼지는 장애 전파 를 방지하는 역할을 합니다. 사용자에게는 빠른 피드백을 줄 수 있고, 오류 발생부에게는 회복 시간을 벌어줄 수 있는 유용한 장치입니다.
수십개의 실시간 정보를 교환 하는 WebClient 의 서비스 구현체에게 Circuit Breaker 를 적용하고 있습니다.
Spring Framework 진영에서 가장 잘 알려진 회로 차단기는 Hystrix 일 것 입니다. 그러나 Resilience4j 를 선택한 이유는 아래와 같습니다.
- Spring Boot 공식 회로차단기가
Hystrix에서Resilience4j로 변경 Netflix 라이브러리가 2018년 12월 18일부터 Maintenance 모드에 돌입Resilience4j는Functional Programming의 원칙을 기반
대부분 Hystrix 에 익숙하였기에, Resilience4j를 꼼꼼하게 검증하였습니다.

어노테이션을 덕지덕지 칠해야 했던 Hystrix 에 비해 (어노테이션 아니어도 사용할 수 있기는 하지만), 데코레이터를 쌓을 수 있도록 함수 구성에 의존한 방식이 상당히 마음에 들었습니다.
client.requestA(request)
.transform(CircuitBreakerOperator.of(circuitBreaker))Circuit Breaker 는 아래에서 언급할 Micrometer 와도 쉽게 연동되어 유용하게 모니터링을 하고 있습니다.
Fallback
십여개의 플랫폼 시스템의 데이터를 저장하고 있는 데이터 저장소 의 데이터 조회에 fallback 을 언급하였습니다.
Fallback 동작은 저장소 장애에 대응하기 위한 목적도 가지고 있습니다. 첫번째 캐시 레이어인 Redis 에서 장애가 발생하여도, 2차 캐시 레이어에서 사용자에게 데이터를 제공할 수 있도록 만들었습니다. (2차에서도 안되면 3차로..)
public Mono<ShopDetail> get(Long shopNumber) {
return shopDetailRedisCacheService.cacheable(shopNumber, shopDetailSecondCacheService::get)
.map(CacheData::getData);
}가게노출 시스템에는 1,2,3차 캐시가 존재하며, 서로 다른 인프라를 가지고 동일한 데이터를 제공할 수 있도록 만들었습니다.
이 때, 거듭된 fallback 끝에 3차 캐시에 도달해서까지 실패하더라도 플랫폼 시스템에 의존하지는 않도록 작성하였습니다. 속도 보다는 데이터의 정합성을 중요시하여 설계된 플랫폼 시스템에 사용자 트래픽을 넘기면 서비스의 장애가 플랫폼의 장애로까지 전파될 것 입니다. 가게노출 시스템에서는 어떠한 경우에도 플랫폼 시스템에 사용자 트래픽을 넘기지 않고 이벤트 기반으로만 대화하도록 설계 되었습니다.
플랫폼 시스템과 이벤트로만 대화하고 있으므로 반대의 경우인 플랫폼 시스템의 장애시에도 가게노출 시스템은 사용자에게 장애를 전파하지 않고 원활한 서비스를 제공할 수 있습니다.
대용량 트래픽에서 데이터를 빠르고 정확하게 제공해야 하는
Query성격의 시스템들이 있고, 데이터의 정합성과 안정성이 중요한Command성격의 시스템이 있습니다. 가게노출 시스템은 이러한Query성격의 시스템으로서,Command시스템인 플랫폼 시스템들과는이벤트를 통해서만 대화하도록 설계하였습니다.
모니터링
안정적인 서비스를 위한 중요한 두번째 요소는 모니터링 입니다. 모니터링 도구의 대부분이 Thread 모델을 기반으로 작성되어, 아직 Reactor 를 사용하는 시스템을 효과적으로 지원하는 도구가 별로 없습니다. 그렇지만 모니터링을 하지 못하는 것은 아닙니다.
가게노출 시스템을 모니터링하며 유용했던 두 가지를 소개합니다.
Reactor With MDC
MDC 는 로깅 프레임워크에서 특별한 메시지를 남기기 위한 도구입니다. MDC 를 가장 많이 활용하는 것은 바로 요청에 대한 식별자일 것 입니다. Transacion ID 를 남기어, 요청에 대한 로그를 쉽게 추출할 수 있습니다.
그러나 대부분의 MDC 동작은 Thread 를 중심으로 작성됩니다. 전통적인 Thread Model 에서는 요청부터 응답이 같은 Thread 로 수행되기 때문에 MDC를 사용하기 쉬웠지만, Asynchronous NIO 기반의 Reactor 에서는 하나의 요청에서도 수십번 Thread 탈바꿈이 일어나게 됩니다.
이를 Reactor 에서 동작하도록하여 사용 중 입니다. 코틀린으로 작성된 코드를 자바 기반으로 옮겼으며, 이미 온라인에 공개된 내용이니 코드도 공개합니다.
/**
* @link https://www.novatec-gmbh.de/en/blog/how-can-the-mdc-context-be-used-in-the-reactive-spring-applications/
*/
@Configuration
public class MdcContextLifterConfiguration {
public static final String MDC_CONTEXT_REACTOR_KEY = MdcContextLifterConfiguration.class.getName();
@PostConstruct
@SuppressWarnings("unchecked")
public void contextOperatorHook() {
Hooks.onEachOperator(MDC_CONTEXT_REACTOR_KEY, Operators.lift((scannable, subscriber) -> new MdcContextLifter(subscriber)));
}
@Bean
public MdcLoggingFilter mdcLoggingFilter() {
return new MdcLoggingFilter();
}
@PreDestroy
public void cleanupHook() {
Hooks.resetOnEachOperator(MDC_CONTEXT_REACTOR_KEY);
}
/**
* Helper that copies the state of Reactor [Context] to MDC on the #onNext function.
*/
@RequiredArgsConstructor
public static class MdcContextLifter<T> implements CoreSubscriber<T> {
private final CoreSubscriber<T> coreSubscriber;
@Override
public void onSubscribe(Subscription subscription) {
coreSubscriber.onSubscribe(subscription);
}
@Override
public void onNext(T t) {
copyToMdc(coreSubscriber.currentContext());
coreSubscriber.onNext(t);
}
@Override
public void onError(Throwable throwable) {
coreSubscriber.onError(throwable);
}
@Override
public void onComplete() {
coreSubscriber.onComplete();
}
@Override
public Context currentContext() {
return coreSubscriber.currentContext();
}
/**
* Extension function for the Reactor [Context]. Copies the current context to the MDC, if context is empty clears the MDC.
* State of the MDC after calling this method should be same as Reactor [Context] state.
* One thread-local access only.
*/
void copyToMdc(Context context) {
if (context != null && !context.isEmpty()) {
Map<String, String> map = context.stream()
.collect(Collectors.toMap(e -> e.getKey().toString(), e -> e.getValue().toString()));
MDC.setContextMap(map);
} else {
MDC.clear();
}
}
}
}컨텍스트 스위칭이 일어날 때마다 MDC 를 복사하게끔 하는 코드이며, WebFilter 를 사용하여 모든 요청에서 적용되도록 일괄 적용 합니다.
public class MdcLoggingFilter implements WebFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
return chain.filter(exchange).subscriberContext(ReactiveMdcUtils::injectUuid);
}
}서로 다른 Thread 에서 동작하지만, 같은 Transaction ID 로 로그가 남는 것을 확인할 수 있습니다.
2020-02-17 02:07:12 INFO --- [0fcf6f919b11445][elastic-2] c.b.shop.display.MdcTestController : hello
2020-02-17 02:07:12 INFO --- [0fcf6f919b11445][elastic-3] c.b.shop.display.MdcTestController : hello worldSpring Boot Micrometer
현존하는 대부분의 APM 들을 검증했지만 WebFlux 를 잘 지원하고 있는 APM 을 아직 찾지는 못했습니다. 절망하던 가운데, 희망을 주었던 것은 Spring Boot Micrometer 입니다. 가게노출 시스템에서는 Micrometer 메트릭을 1년째 유용하게 사용하고 있습니다.
Spring Boot 2 가 등장하며 함께 등장한 Micrometer 은 아래와 같은 매트릭을 제공해줍니다.

출처: https://spring.io/blog/2018/03/16/micrometer-spring-boot-2-s-new-application-metrics-collector
거의 대부분의 유용한 메트릭을 지원하고 있습니다.
-
Netflix Atlas
-
CloudWatch
-
Datadog
-
Ganglia
-
Graphite
-
InfluxDB
-
JMX
-
New Relic
-
Prometheus
-
SignalFx
-
StatsD (Etsy, dogstatsd, Telegraf, and proprietary formats)
-
Wavefront
거의 대부분의 모니터링 시스템과의 연계 또한 지원하고 있습니다. Prometheus 와 가장 최적화되어있지만, 당시 Prometheus 를 사용하기에는 버거운 환경이였기에 가게노출 시스템은 InfluxDB 와 연동하고, Grafana 를 통해 모니터링 및 알람을 구축하였습니다.
연동은 매우 쉽습니다. application.yml 에 아래 설정을 해주는 것만으로도 매우 많은 매트릭을 제공해줍니다.
management:
metrics:
export:
influx:
step: 10s
db
enabled: true위 설정은 influx 와 연동하며, 10초 간격으로 매트릭을 전송하도록 구성하였습니다. 각 연동 모니터링 시스템에 따라 매트릭을 전송하는 방식은 다릅니다. (Prometheus 는 polling 방식으로 동작합니다.)
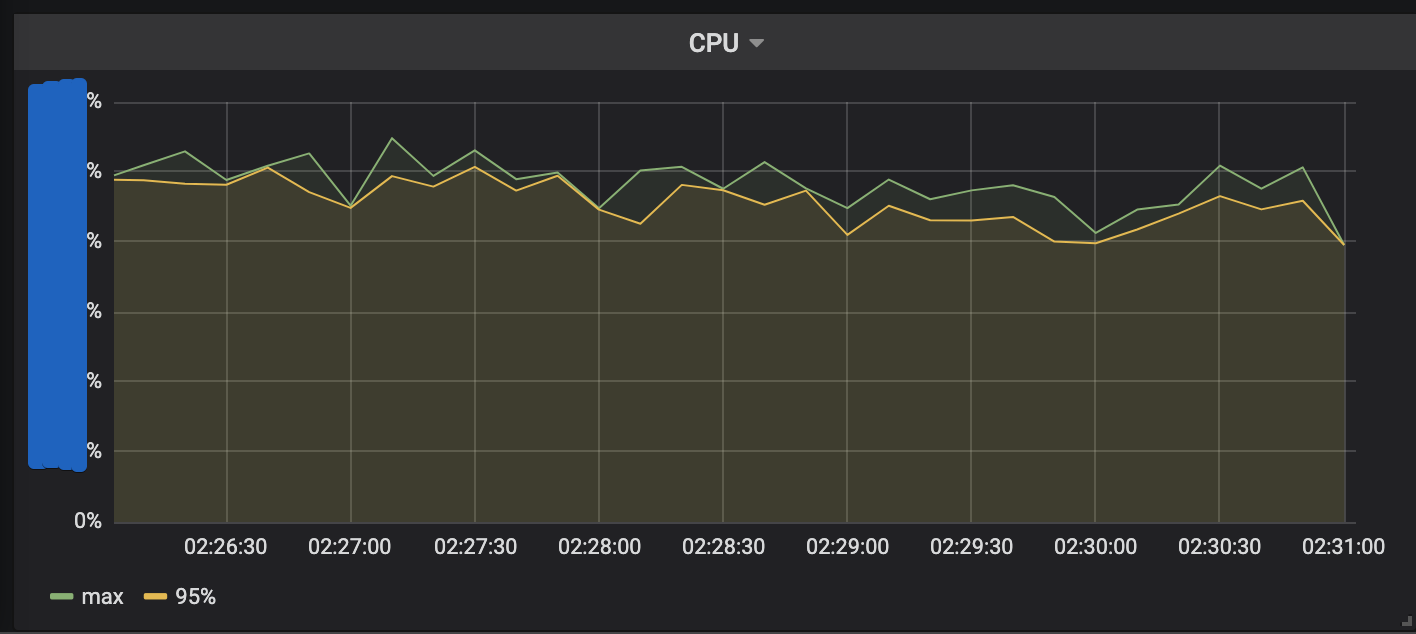
CPU
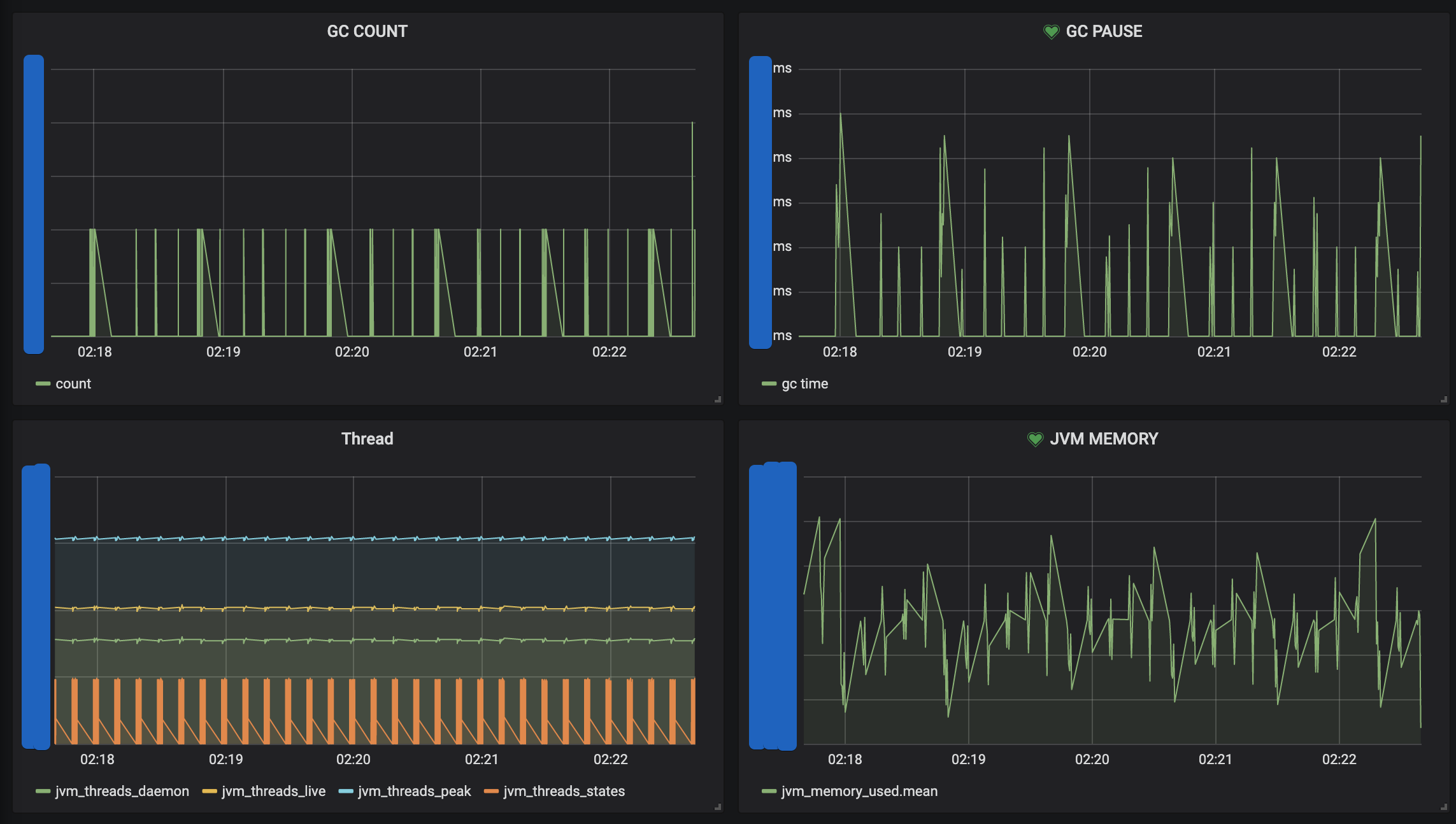
JVM
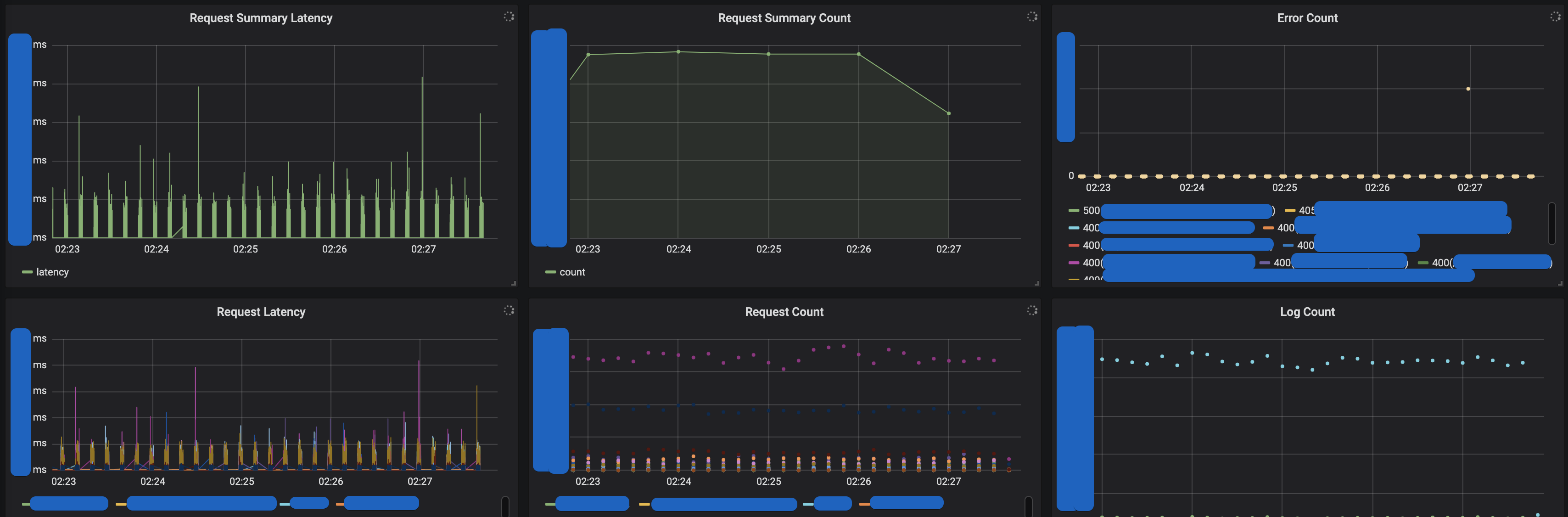
Request Server
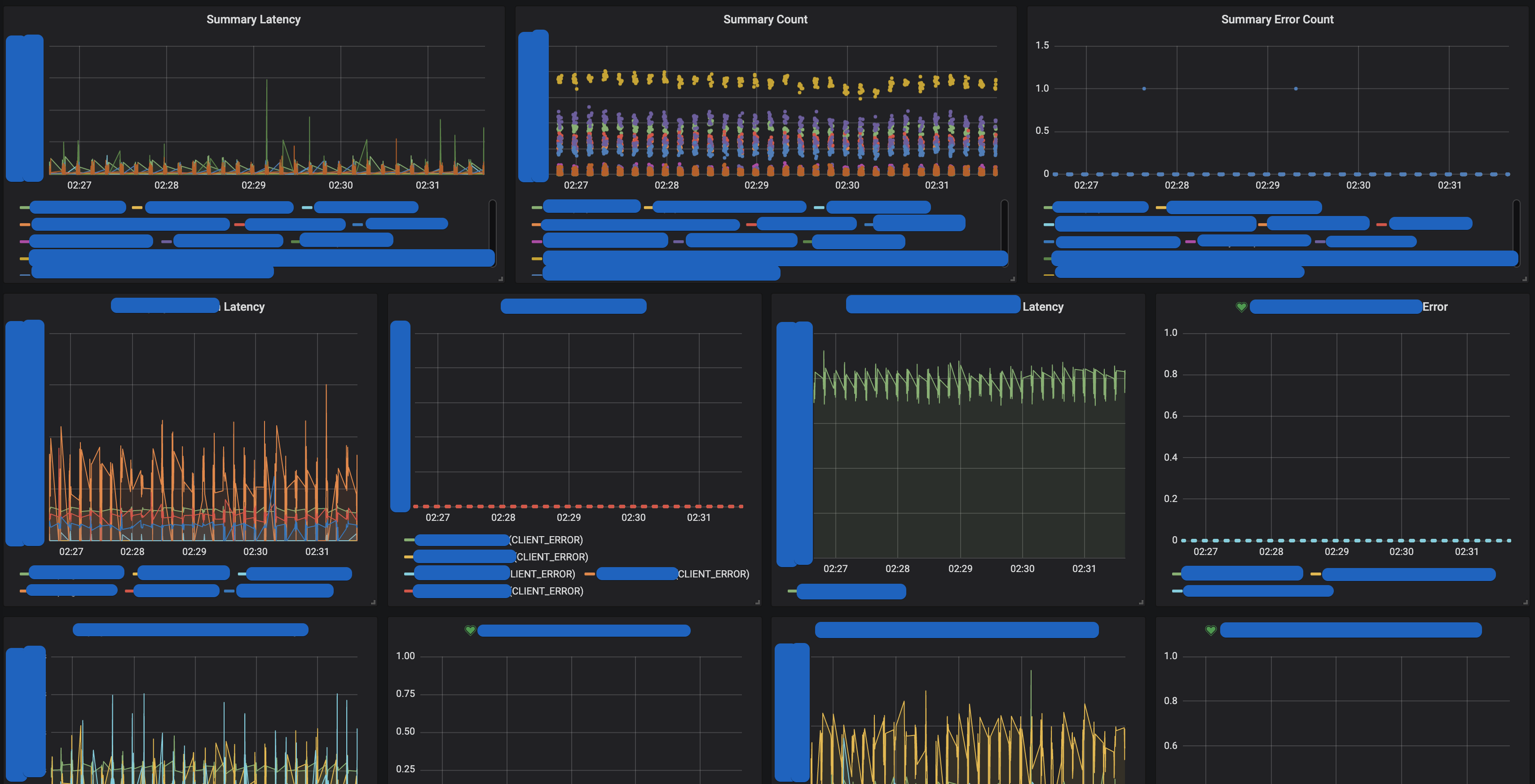
Request Client
Circuit Breaker
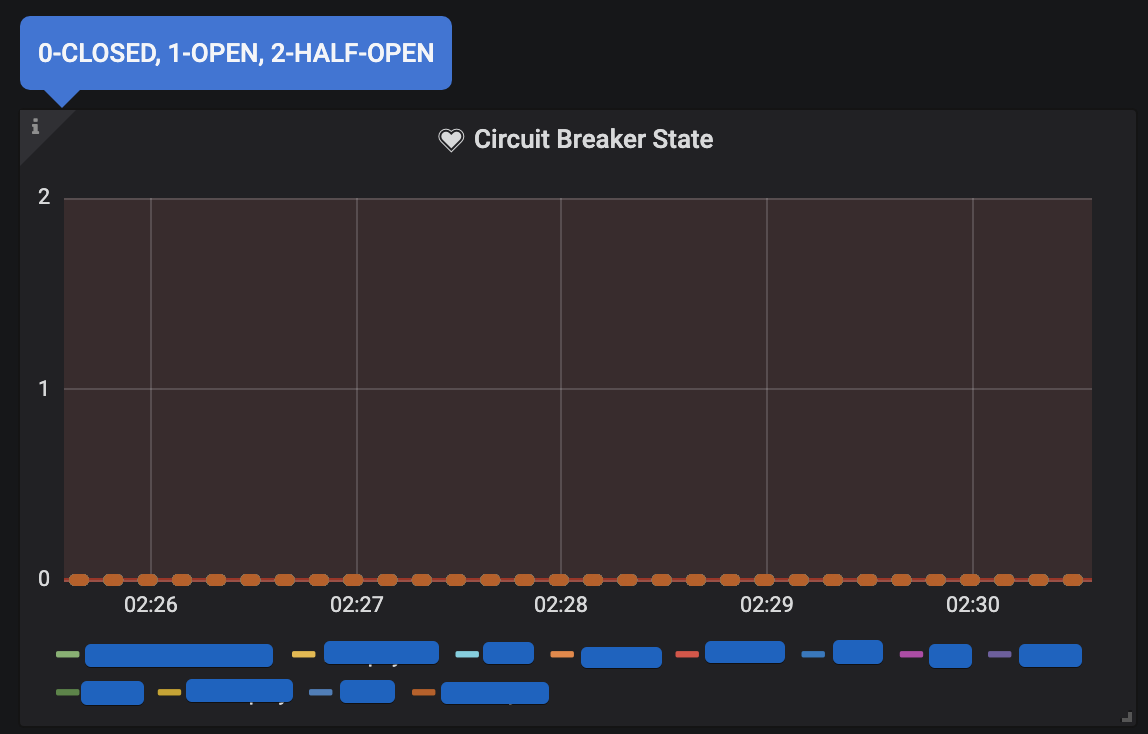
기본으로 제공되는 모니터링 매트릭이 이 정도이며, 매트릭 요소 추가 역시 쉽게 할 수 있습니다.
Event Process
가게노출 시스템에서는 이벤트로 처리되는 매트릭을 추가 구성하여 모니터링을 하고 있습니다.
public ConsumeProcessor(String key, MeterRegistry meterRegistry) {
this.successCounter = meterRegistry.counter(key + ".consume.success");
this.failedCounter = meterRegistry.counter(key + ".consume.fail");
this.skipCounter = meterRegistry.counter(key + ".consume.skip");
}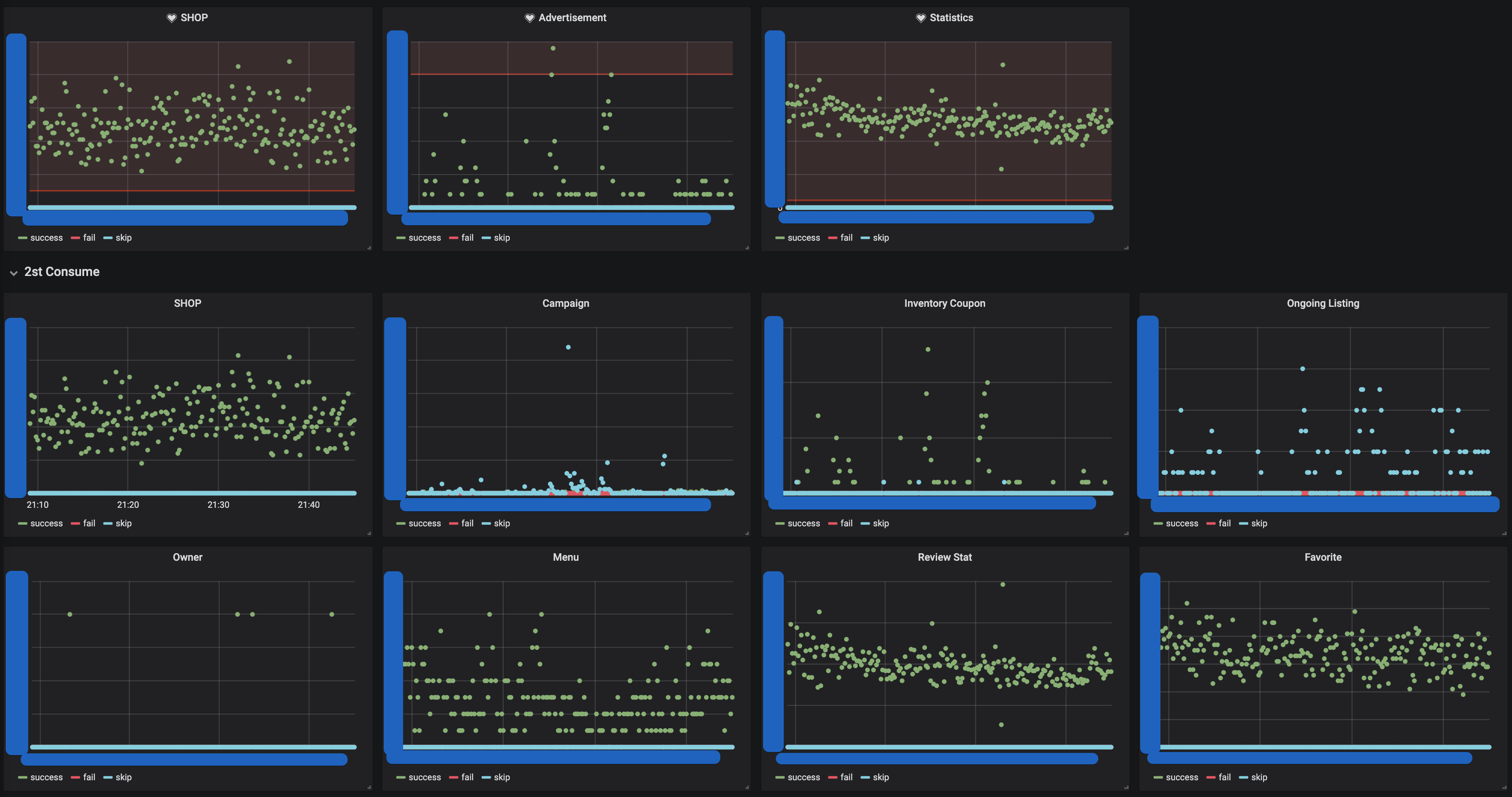
가게노출 시스템은 이외에도 다양한 지표를 모니터링 하고 있습니다.
4. 앞으로 가게노출 시스템은?
지금까지 가게노출 시스템의 1년을 공유해보았습니다. 가게노출 시스템은 최전방 시스템으로서, 그리고 어쩌면 종합정보 시스템으로서의 역할을 다하기 위하여 많은 도전과 시도를 하고 있습니다.
WebFlux의 도입, 데이터 스토어 설계, 장애 전파 방지, 모니터링 등 다양한 도전을 이야기했지만, 정말 중요한 것을 이 글에 싣지 못하였습니다. 가게노출 시스템이 최전방 시스템으로서 앱과 어떻게 통신하고, 어떻게 데이터를 가공하고, 어떠한 문제를 해결하고 있는지 입니다. 그동안의 도전이 성능과 안정화를 위한 도전들이였다면, 앞으로는 더 잘 운영하기 위한 도전들을 시작하고 있습니다.
- 다양한 주체의 플랫폼 시스템들의 데이터를 어떻게 우리의 것으로 가공하여, 더 효율적인 시스템을 만들 것인가
- 노출과 플랫폼 사이에 존재하는 수많은 정책들을 어떻게 코드로 작성할 것이며, 어떤 도메인 응집군으로 관리할 것이며, 어떻게 검증할 것인가
- 어떻게 빠르게 이슈를 트래킹할 것인가
- 어떻게 하위 버전의 앱들을 안정적으로 지원하며, 새로운 기능들을 계속해서 빠르게 확장해나갈 것인가
- 어떻게 어떠한 변화에도 유연한 시스템을 만들어낼 것인가
과제를 달성하기 위해 기술을 다루고, 시스템을 운영하며 계속하여 변경에 유연한 코드와 시스템을 만들어내기 위하여 가게노출 시스템은 계속하여 도전 중 입니다!

가게노출 시스템을 더 알고 싶거나, 직접 운영해보고 싶은 분들은 서둘러 지원을.. 부탁드립니다.
이상 가게노출 시스템에 대한 소개였습니다. 다음에 기회가 된다면 더 잘 운영하기 위한 도전의 결과를 다시 공유드리겠습니다.
긴 글 읽어주셔서 감사합니다!
Behind 실패 알람

각종 실패 알림에도 좋아하는 분들의 얼굴을 사용하고 있습니다.
