postgres_fdw로 마이그레이션 생산성 높이기
배달의민족 커머스 서비스들의 ‘상품’ 도메인 시스템 통합 프로젝트를 하며 postgres_fdw를 이용해 PostgreSQL DB 간의 별도 배치 애플리케이션 없이 마이그레이션을 경험했던 실제 사례 및 결과와 주의사항, 느낀 점들을 공유하고자 합니다.
배달의민족 앱에서 아이폰을 주문해 보신 적 있으신가요? 음식뿐 아니라 장보기・쇼핑, B마트, 전국별미, 배민상회, 대용량특가 등 다양한 커머스 서비스의 상품을 주문해서 배달 또는 배송으로 받아보실 수 있습니다.

커머스 서비스들은 초기에 다양한 요구사항을 신속하게 서비스에 반영하기 위하여 각각 독립된 시스템으로 운영되고 있었습니다. 당시에는 최선의 선택이었지만, 서비스 규모가 점차 커지고 안정화되면서 중복된 역할을 수행하는 시스템이 많아져 운영 비용이 증가하는 문제가 발생했습니다.
이에 저희가 속한 커머스플랫폼실에서는 시스템들을 각 도메인별로 통합하여 운영 비용과 복잡도를 낮추는 프로젝트들을 하게 되었고 이 중 커머스에서 중요한 도메인인 ‘상품’ 시스템을 통합하는 프로젝트를 담당하게 되었습니다.
작년 하반기에 커머스 통합 상품 시스템을 신규 오픈하면서 B마트 상품 시스템을 1차로 통합하는 프로젝트 중에는 Spring Batch로 마이그레이션을 했었는데요. 올해 상반기에는 배민스토어 상품 시스템을 2차로 통합하는 프로젝트를 하던 중 마이그레이션 작업 생산성을 높이기 위해 팀원 한 분이 postgres_fdw를 사용해 배치 애플리케이션 개발 없이 SQL로만 마이그레이션하는 방법을 제안했고, 검토 결과 적합하다고 판단되어 마이그레이션을 postgres_fdw를 사용해 진행하기로 결정하였습니다.
postgres_fdw란?
공식 문서는 PostgreSQL: Documentation: 17: F.36. postgres_fdw — access data stored in external PostgreSQL servers 를 참조해 주세요
FDW(Foreign Data Wrapper)는 PostgreSQL이 외부 데이터 소스와 통신할 수 있는 라이브러리입니다. FDW는 외부 데이터 소스에 연결하고 데이터를 가져오는 세부 과정을 추상화하여, SQL을 사용하여 외부 데이터 소스의 데이터를 조회하고 조작할 수 있도록 해 줍니다. 단, FDW 구현체에 따라 일부 SQL 기능은 지원되지 않을 수 있습니다.
외부 데이터 소스는 PostgreSQL, MySQL, MongoDB와 같은 타 DBMS뿐만 아니라 CSV 파일, REST API 등 다양한 소스가 될 수 있습니다.
postgres_fdw는 PostgreSQL이 다른 PostgreSQL을 외부 데이터 소스로 사용할 수 있게 해주는 PostgreSQL 모듈입니다. postgres_fdw를 사용하면 원격 PostgreSQL의 테이블을 마치 같은 데이터베이스 내 테이블처럼 사용할 수 있으며, 기본적으로 읽기 작업이 가능하고 쓰기 작업은 설정에 따라 제한할 수 있습니다.

기초 사용법
postgres_fdw는 아래의 과정을 거쳐 사용할 수 있습니다.
- 확장 설치 : CREATE EXTENSION 명령어를 사용하여 postgres_fdw 확장을 설치합니다.
- 원격 PostgreSQL 설정 : CREATE SERVER 명령어를 사용하여 연결하려는 다른 PostgreSQL 설정을 추가합니다. 원격 DB의 유저와 패스워드를 제외한 연결 정보를 옵션으로 지정합니다.
- 원격 DB 유저와의 매핑 생성 : CREATE USER MAPPING 명령어를 사용하여 외부 서버의 유저-내 DB의 유저 간의 매핑을 만듭니다. PUBLIC 옵션 추가 시 내 DB의 특정 유저 대상 매핑이 아닌 공용 매핑을 만들 수 있습니다. 이 단계에서 매핑된 원격 DB의 사용자로 원격 DB에 접속해서 사용하게 됩니다.
- Foreign table 생성 : 액세스 대상 원격 DB 테이블들에 대해 CREATE FOREIGN TABLE 또는 IMPORT FOREIGN SCHEMA 구문으로 Foreign table 을 생성합니다. 이후에는 생성된 Foreign table을 통해 원격 DB의 데이터에 접근할 수 있습니다.
CREATE EXTENSION IF NOT EXISTS postgres_fdw;
-- 원격지 서버 설정
CREATE SERVER migration_source
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'remote_db_host', -- 원격지 postgresql 호스트
port '5432', -- 원격지 postgresql 포트
dbname 'legacy', -- 원격지 DB명
application_name 'migration'
);
-- 원격지 서버에 접속하기 위한 user 설정
CREATE USER MAPPING FOR PUBLIC SERVER migration_source
OPTIONS (
user 'migration_user', -- 원격지 DB의 user
password 'password' -- 해당 user의 password
);
-- 원격 DB의 테이블 "example"은 id(bigint), code(text), name(varchar) 3개의 컬럼을 가지고 있다고 가정
-- Local DB에서는 "legacy_remote" 스키마에 Foreign table을 생성해서 원격 DB로 접근하도록 설정 (반드시 별도의 스키마가 필요한 것은 아니며, foreign table을 구분하려는 용도)
-- legacy_remote 스키마에 원격 테이블 "example"에 연결될 Foreign table "example_ft" 생성
CREATE FOREIGN TABLE legacy_remote.example_ft (
id bigint NOT NULL,
code text NOT NULL,
name varchar(200) NOT NULL
)
SERVER migration_source
OPTIONS (schema_name 'legacy', table_name 'example'); -- 원격 DB의 스키마 및 테이블명 지정
-- example_ft 테이블에 쿼리하면 원격지 DB의 example 테이블의 데이터를 조회 가능
SELECT * FROM legacy_remote.example_ft LIMIT 1;postgres_fdw를 이용한 마이그레이션
계획 및 마이그레이션 규칙 정리
저희가 무리 없이 postgres_fdw를 사용 가능했던 이유 중 하나는 마이그레이션할 때 대상 테이블에 트래픽이 거의 없는 상황에서 작업이 가능했다는 점입니다. 당시 배민스토어 시스템은 이벤트 기반 아키텍처를 도입하여 앱에서 발생하는 조회 트래픽이 상품 DB에 직접 유입되지 않았습니다. 그리고 대부분의 셀러는 새벽에 영업을 하지 않아 앱에서 유입되는 트래픽은 극소수의 조회 트래픽뿐이었습니다.
배민스토어의 이벤트 기반 아키텍처가 궁금하시다면 김민태 님의 배민스토어에 이벤트 기반 아키텍처를 곁들인… 을 추천드립니다 🙂
상품을 등록/수정하는 판매자분들은 새벽시간에 대부분 작업을 하지 않아서, 판매자 어드민의 상품 등록/수정 메뉴만 점검으로 설정 후 작업을 할 수 있었고, 따라서 마이그레이션 중에 데이터의 변경이 없다는 전제를 만들 수 있었습니다.
배민스토어의 상품 테이블 스키마와 커머스 통합 상품 시스템의 테이블 스키마가 달랐기 때문에, 마이그레이션 대상 테이블, 칼럼 매핑 규칙과 데이터 보정 등 추가 작업에 대한 정리가 필요했었고, 이러한 내용들을 구글 스프레드시트에 시트별로 구분해 정리하고, 테스트를 하며 점진적으로 보완해 나갔습니다.

마이그레이션 쿼리 작성
이제 정리된 규칙대로 마이그레이션 쿼리를 작성할 일만 남았습니다. 앞서 설명드린 것처럼 DB 조회 부하도 감당 가능한 수준이고, 데이터의 변경이 없음을 전제로 할 수 있었습니다. 따라서 저희는 대부분의 마이그레이션을 INSERT ~ SELECT 구문으로 처리 할 수 있었고 레거시 DB에서 저희 스키마에 맞추어 필요한 데이터만 가지고 오는 구문으로 많은 테이블에 대해서 간편하게 마이그레이션 할 수 있었습니다.
앞으로 나올 예시 쿼리에는 3가지 스키마가 등장합니다.
- commerce_product : 마이그레이션된 데이터가 저장될 스키마
- legacy_remote : 원격지 DB에 접근하기 위한 Foreign table을 모아둔 스키마
- legacy : 원격지 DB의 마이그레이션 대상 테이블을 가지고 있는 스키마
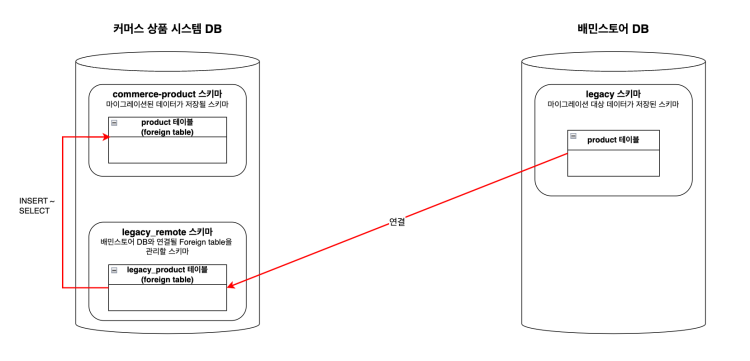
-- 상품 마이그레이션 쿼리 예시
INSERT INTO commerce_product.product (id, name, sale_status, is_package)
SELECT lp.id as id,
lp.name as name,
(CASE ls.sale_status
WHEN 'ON_SALE' THEN 'IN_SALE'
WHEN 'STOP_SALE' THEN 'STOP_SALE'
END) as sale_status, -- 사용하는 enum이 달라져서 변환
false as is_package -- 기존 DB에 없던 값은 상수로 마이그레이션
FROM legacy_remote.legacy_product lp
INNER JOIN legacy_remote.legacy_product_status ls on lp.id = ls.product_id
WHERE lp.register_status = 'COMPLETED'; -- 필요한 데이터만 필터링마이그레이션 대상 데이터 중에는 대량의 가비지 데이터를 가지고 있는 테이블들도 있었는데요. 그중 두 개의 테이블은 각각 약 4억 개의 row가 저장된 테이블에서 700만 개의 row만 유효한 데이터 였습니다.
처음에는 Foreign table에 대해 직접 INSERT ~ SELECT를 시도했었지만 쿼리 실행 시간이 너무 오래 걸려 다른 방법을 고민하게 되었고, 원본 DB 내에서 마이그레이션 대상이 되는 700만 개의 row만 저장된 별도 테이블 생성 후 해당 테이블을 그대로 마이그레이션하는 방법으로 수행하게 되었습니다. 그 결과 40분이 지나도 실행이 완료되지 않던 마이그레이션 쿼리가 10분 내로 마무리되었습니다.
-- legacy DB에서 실행
CREATE TABLE legacy.some_big_table_mig AS
SELECT bt.id,
bt.product_id as product_id,
bt.data as new_column_name
FROM legacy.some_big_table bt
WHERE bt.deleted = false
AND ...;
-- 마이그레이션 될 DB에서 실행
CREATE FOREIGN TABLE legacy_remote.some_big_table_mig
(
id bigint not null,
product_id bigint not null,
new_column_name varchar(100) not null
)
SERVER migration_source
OPTIONS (schema_name 'legacy', table_name 'some_big_table_mig');
INSERT INTO commerce_product.filtered_data (id, product_id, data)
SELECT id, product_id, data
FROM legacy_remote.some_big_table_mig;복잡한 데이터의 마이그레이션 처리
원격 DB → 목적지 DB로 마이그레이션시 아래와 같은 상황이 발생할 수 있는데요
- 동일한 속성(데이터)라도 설계가 달라서 1:1로 매핑되지 않음
- 동일한 속성(데이터)에 대한 정책이 변경되어 속성값 자체에 변경이 필요
특히 상품의 상품정보제공고시가 위에 해당하였습니다.
상품정보제공고시는 각 상품에 대한 세부 정보를 담고 있는 데이터로, 상품마다 항목이 다를 수 있으며, 고유한 포맷과 다층 구조로 이루어져 있어 일관된 스키마로 처리하기 어려운 특징이 있었는데요. 이 경우에는 한 번의 쿼리로 마이그레이션이 하기 어려워 단계별로 나누어서 마이그레이션을 수행하였습니다.
원격지 DB의 상품정보제공고시 데이터는 JSON 형식으로 되어 있으며, 데이터 규모가 커서 구조적으로 다루기 쉽지 않았고, 이로 인해 단일 쿼리로 마이그레이션을 수행하는 데 어려움이 있었습니다. 복잡한 데이터 구조를 목적지 DB에 그대로 적재하기 위해서는 1. 매핑테이블 생성, 2. 전처리 데이터 생성, 3. 마이그레이션 쿼리 실행 단계를 거쳐야 했습니다.
Step 1. 매핑 테이블 생성
원격지 DB의 복잡한 구조의 데이터를 목적지 DB에서 전처리 데이터 생성이 가능하려면 매핑 규칙이 필요한데요. 이를 위해 사전에 정리해둔 마이그레이션 규칙 문서를 기반으로 원격지 DB의 필드와 목적지 DB의 필드를 연결하는 매핑 테이블을 생성하였고 고유 키와 각 항목에 대응하는 컬럼을 일대일 매핑할 수 있도록 준비했습니다.
(쿼리는 예시로 간략하게 작성하도록 하겠습니다)
CREATE TABLE commerce_product.product_information_notice_mapping_rule (
id bigint not null,
code varchar(126) not null,
name varchar(126) not null,
legacy_id bigint not null,
legacy_code varchar(126) not null
);
INSERT INTO commerce_product.information_notice_mapping_rule ...
... (생략) ...Step 2. 전처리 데이터 생성
복잡한 다층 구조의 데이터는 한 번에 처리하기 어려우며, DB 작업은 가능한 짧은 트랜잭션으로 수행하는 것이 좋습니다. 또한 최종 마이그레이션 쿼리를 실행할 때 Foreign table과의 조인(join)을 피하려면, 사전에 전처리 데이터를 생성하는 건 중요하기에 각 항목을 목적지 DB에 필요한 스키마에 맞는 데이터로 미리 생성해놓습니다.
CREATE TABLE commerce_product.product_information_notice_raw_data as (
SELECT ...(생략)...
FROM commerce_product.product p
-- 미리 기 생성된 Foreign table 과 join 수행
JOIN legacy_remote.legacy_product.information_notice lpin
ON lpin.product_id = p.id
...(생략)...
);Step 3. 마이그레이션 쿼리 실행
준비된 매핑 테이블과 전처리 데이터를 활용하여 목적지 DB의 실제 테이블로 마이그레이션하는 쿼리를 실행합니다. 미리 생성된 데이터들로 인해 필요한 테이블만 조인(join) 후 데이터를 그대로 INSERT 하면 되므로 무리 없이 마이그레이션 쿼리 수행이 가능했습니다.
-- 전처리 데이터가 적재된 테이블과 매핑 테이블을 join 후 insert 가능한 데이터로 가공합니다.
WITH base (SELECT
(...생략...)
FROM commerce_product.product_information_notice_raw_data raw_data
JOIN commerce_product.product_information_notice_mapping_rule mapping_rule
ON raw_data.code = mapping_rule.code
)
INSERT INTO commerce_product.product_information_notice (
...(생략)...
)
SELECT ...(생략)...
FROM base;DB 전문가와 함께 마이그레이션 전략 최적화
우아한형제들에는 DB 관련 작업 시마다 든든한 지원군이 되어 주는 스토리지 서비스팀의 뛰어난 DBA분들이 있습니다. 이번 마이그레이션시에는 DB에 특화된 기능을 이용하기 때문에 스토리지 서비스팀에도 자문을 받았는데요. 저희가 작성한 작업 계획을 꼼꼼히 검토해 주셨고, 아래와 같은 개선사항을 제안해 주었습니다.
편의상 마이그레이션 목적지(커머스 상품 시스템) DB의 테이블을 Local table이라고 부르겠습니다.
1. Foreign table과 Local table 간의 조인(join)은 피할 것
- 작성한 마이그레이션 쿼리 중에는 편의를 위해 마이그레이션이 완료된 다른 Local table과 Foreign table을 조인(join)하는 쿼리가 있었습니다. Foreign table과 Local table의 조인(join)은 성능이 매우 떨어질 수 있어 가능한 모든 조인(join)을 Foreign table 간에만 수행하도록 권장하였습니다.
추가로 소소한 팁을 공유드리면 mysql이나 sql server에서도 비슷한 기능이 제공되고 있는데요
- MySQL : The FEDERATED Storage Engine
- SQLServer : Linked Servers (Database Engine)
Remote Server와 Local Server 간의 조인(join)은 이 두 개 DB도 동일하게 FullScan으로 동작하니 이러한 기술들을 사용할 때 가장 주의해야 하는 부분입니다.
2. 사이즈가 크지 않은 원본 테이블을 마이그레이션 목적지 DB에 그대로 옮기고, 가능하다면 목적지 DB 내에서 마이그레이션
- 마이그레이션 쿼리 내에서 반복적으로 사용되는 Foreign table들이 있었고, 이 테이블들을 Local table로 옮겨두면 마이그레이션 속도 향상을 기대할 수 있었습니다.
-
Foreign table과 Local table 간의 조인(join)은 피했지만, 일부 상황에서는 반드시 두 테이블 간의 조인(join)이 필요한 경우도 있었습니다. 이런 경우에도 마이그레이션 대상이 되는 데이터를 미리 Local table로 옮겨두면 Foreign table과의 조인(join) 성능 우려 없이 마이그레이션이 가능했습니다.
-- 원래의 마이그레이션 쿼리 INSERT ~ INTO commerce_product.product SELECT ~ FROM legacy_remote.legacy_product WHERE ...; INSERT ~ INTO commerce_product.product_image SELECT ~ FROM legacy_remote.legacy_product_image i INNER JOIN legacy_remote.legacy_product p ON i.product_id = p.id INNER JOIN local.something_new n ON n.product_id = p.id WHERE ... -- 아래의 2단계로 분리 -- Foreign table의 데이터를 목적지 DB로 전부 가져온다 CREATE TABLE commerce_product.legacy_product_local AS SELECT * FROM legacy_remote.legacy_product; CREATE TABLE commerce_product.legacy_product_image_local AS SELECT * FROM legacy_remote.legacy_product_image; -- 원격지 DB (Foreign table)를 통하지 않고 목적지 DB(마이그레이션 될 DB) 내에서 모두 처리 INSERT ~ INTO commerce_product.product SELECT ~ FROM commerce_product.legacy_product_local WHERE ... INSERT ~ INTO commerce_product.product_image SELECT ~ FROM commerce_product.legacy_product_image_local i INNER JOIN commerce_product.legacy_product_local p ON i.product_id = p.id INNER JOIN commerce_product.something_new n ON n.product_id = p.id WHERE ...
3. 원본 DB의 스냅샷을 생성한 새로운 DB를 활용해 마이그레이션
- 마이그레이션 대상 DB는 서비스 전반 사용되고 있어 트래픽이 적은 시간대에 작업하더라도 서비스에 영향을 미칠 가능성이 있었고, 작업 시작 시점의 DB 스냅샷을 생성하고 해당 스냅샷을 기반으로 마이그레이션을 해서 서비스에 영향을 주지 않고 안전하게 마이그레이션을 완료할 수 있었습니다.
운영 마이그레이션 및 데이터 검증
운영 환경에서의 마이그레이션은 아래와 같은 순서로 진행되었습니다.
- 레거시 시스템에서 INSERT / UPDATE / DELETE 작업이 발생하는 모든 기능 차단
- 레거시 DB의 RDS 스냅샷 생성 후, 해당 스냅샷을 기반으로 새로운 마이그레이션용 DB 생성
- 마이그레이션용 DB에 대해 postgres_fdw 설정
- 마이그레이션 구문 실행
위에서 설명드린 개선사항들을 적용한 결과, 신규 DB 생성 시간을 제외하면 천만 건 단위의 데이터를 45분 내에 마이그레이션할 수 있었습니다. 이 중 대부분의 시간은 수억 건의 데이터를 보유한 레거시 테이블에서 필요한 데이터를 필터링하는 데 소요되었으며, 각 테이블의 데이터 이관 자체는 비교적 짧은 시간 내에 완료되었습니다.
postgres_fdw 사용 시 주의사항
1. Local Table과 Foreign Table 간의 조인(Join)은 성능 저하를 유발할 수 있음
이미 여러 번 언급된 내용이지만, Local table과 Foreign table 간 조인(join)을 사용하면 높은 부하를 발생시키고 결과 반환 속도가 느려질 수 있습니다. postgres_fdw는 foreign table 조회 시 기본적으로 remote DB에 쿼리를 전송하고, 커서를 받아 fetch_size 설정값(기본값 100)만큼의 row를 반복적으로 fetch하여 결과를 반환합니다.
동일한 remote DB에 있는 foreign table 간의 조인(join)은 remote DB에서 처리된 결과를 한 번에 fetch할 수 있지만, Local table과 Foreign table 간의 조인(join)은 방식이 다릅니다. 이 경우, remote DB에서 데이터를 가져와 local table과 조인(join) 작업을 수행해야 하므로, 쿼리가 복잡해질 경우 local DB가 foreign table의 모든 row를 가져온 뒤(SELECT * FROM foreign_table) 쿼리를 처리하게 되는 상황이 발생할 수 있습니다.
이로 인해 비효율적인 데이터 조회가 이루어질 수 있으며, 결과적으로 성능 저하가 발생합니다.

(출처: Performance Tips for Postgres FDW)
이를 피하기 위해서는 다음과 같은 방법들을 사용할 수 있습니다.
- 원격 DB 데이터를 Local DB로 미리 옮기기
- 필요한 데이터를 Local DB로 옮겨두면 조인(join) 시 불필요한 remote fetch 작업을 줄일 수 있습니다. 이 과정에서 Materialized View를 활용하는 것도 좋은 방법입니다.
- Common Table Expression (CTE)를 사용해 조회 대상 줄이기
- CTE를 활용하면 remote table에서 필요한 row만 조회하도록 제한하여 효율성을 높일 수 있습니다.
- fetch_size 옵션 값 조정
- fetch_size 를 늘리면 대량의 데이터를 처리할 때 성능 향상을 기대할 수 있습니다. 다만, 이는 근본적인 해결책이 아니므로 가능하면 Local table과 Foreign table 간의 조인(join) 자체를 피하는 것이 바람직합니다.
2. 원격 DB에 INSERT / UPDATE / DELETE / TRUNCATE 도 가능
postgres_fdw를 사용하면 원격 DB에 대해 CUD 작업(INSERT, UPDATE, DELETE)뿐 아니라 TRUNCATE TABLE 도 수행할 수 있습니다. 그러나 운영 환경에서 실수로 잘못된 작업이 실행되면 매우 치명적일 수 있으므로, 이를 방지하기 위한 안전장치를 마련하는 것이 중요합니다.
- FDW 전용 User 생성 및 최소 권한 부여
- 원격 DB에는 FDW 전용 User를 별도로 생성하고, 필요한 최소한의 권한만 부여하는 것을 권장합니다.
- 업데이트 및 삭제 작업 제한
- SERVER 또는 FOREIGN TABLE 생성 시, updatable=false, truncatable=false 옵션을 설정하여 CUD 및 TRUNCATE 작업을 방지하는 방법도 효과적입니다.
3. 트랜잭션 처리
사용 패턴상 트랜잭션을 깊이 다룰 필요는 없었지만, postgres_fdw를 사용하는 분들께 도움이 될 수 있을 만한 정보를 간략히 정리해 보겠습니다.
- 원격 DB의 트랜잭션 처리
- 원격 DB에도 트랜잭션을 적용할 수 있으며, 로컬 트랜잭션이 commit 또는 abort 될 때 원격 트랜잭션도 순차적으로 동일하게 처리됩니다.
- 제한사항
- 트랜잭션은 순차적으로 commit 또는 abort 될 뿐이며, two-phase commit 과 같은 분산 트랜잭션 관리는 지원되지 않습니다.
- Isolation Level
- 로컬 트랜잭션의 Isolation Level이 SERIALIZABLE 일 경우, 원격 트랜잭션도 동일하게 SERIALIZABLE 로 설정됩니다.
- 이외의 경우에는 원격 트랜잭션의 Isolation Level 이 REPEATABLE READ 로 자동 설정됩니다.
4. 작업 완료 후 Foreign Table과 postgres_fdw 설정 제거
Foreign Table과 postgres_fdw 설정 제거는 아래의 이유들로 필수적인 마무리 작업입니다.
- 시스템 자원 관리
- Foreign Table과 FDW 설정은 연결된 원격 데이터베이스와의 통신을 위해 PostgreSQL 서버의 리소스를 소모합니다. 마이그레이션이 완료된 후에도 이를 유지하면 불필요한 자원 소모로 이어질 수 있습니다.
- 보안 강화
- 마이그레이션 과정에서 설정된 FDW는 원격 데이터베이스로의 접근 권한을 유지합니다. 마이그레이션 완료 후 이를 방치하면 의도치 않은 접근 또는 데이터 누출 위험이 발생할 수 있습니다.
- 시스템 복잡성 감소
- Foreign Table과 FDW는 유지보수 시 혼란을 초래할 수 있습니다. 특히, 불필요한 설정이 남아 있으면 시스템 구조가 복잡해지고, 의도치 않은 쿼리가 원격 데이터베이스를 참조하는 등의 문제가 발생할 수 있습니다.
- 추적 가능성 개선
- 마이그레이션 후에 Foreign Table과 FDW를 삭제하면, 이후의 데이터 참조가 로컬 데이터베이스로 제한되어 문제가 발생했을 때 원인을 추적하기 쉽습니다.
배치로 마이그레이션하는 방법과 비교 시 장단점
장점
1. 빠른 피드백과 수정 가능
쿼리를 작성한 후 실행만 하면 바로 결과를 확인할 수 있어, 피드백과 수정이 배치 방식보다 훨씬 빠릅니다. 특히 마이그레이션 대상 테이블에 데이터를 실제로 INSERT하지 않아도 결과를 미리 확인할 수 있어 작업 과정이 간소화됩니다. 반면 배치 방식은 코드를 작성한 후 빌드 및 실행, 데이터베이스에 반영된 결과를 확인하는 번거로운 과정이 필요합니다. 쿼리를 사용하는 방법은 DB 접근 툴만 열어두고 모든 작업을 할 수 있어 편리했습니다.
2. 결과 확인과 수정의 용이성
배치 프로그램을 사용할 경우, 잘못된 데이터가 INSERT되었을 때 이를 제거하거나 롤백하는 작업이 필요합니다. 하지만 쿼리 방식에서는 실행 결과를 사전에 확인하고 수정할 수 있어, 잘못된 데이터가 DB에 기록되는 위험을 사전에 방지할 수 있습니다. 이러한 점에서 마이그레이션 쿼리를 빠르게 작성하고 수정하는 데 유리했습니다.
3. 코드 관리의 간소화
배치 프로그램을 작성할 경우, 일회성 마이그레이션 코드를 작성하고 이를 기존 서비스의 코드베이스와 분리 관리해야 합니다. 예를 들어, 별도의 브랜치에 마이그레이션용 DataSource 설정 및 배치 로직을 추가해야 하며, 개발 중 스키마나 공용 코드가 변경될 경우 배치 코드가 영향을 받지 않도록 지속적으로 브랜치를 유지해야 합니다. 하지만 쿼리 방식은 이러한 코드 관리 부담이 없어, 마이그레이션 작업 자체에만 집중할 수 있었습니다.
단점
1. 복잡한 마이그레이션 룰 작성의 어려움
마이그레이션 룰이 복잡한 경우, 이를 SQL 쿼리로 작성하는 것이 어려울 수 있습니다. 반면, 코드로 작성하면 복잡한 비즈니스 로직을 메서드나 함수로 분리해 가독성을 높이고, 관리하기도 훨씬 용이합니다.
2. 디버깅 및 테스트의 제한
배치 프로그램 방식에서는 테스트 코드를 작성하여 복잡한 케이스에 대해 마이그레이션이 올바르게 수행되는지 사전에 확인할 수 있습니다. 반면, 쿼리 방식에서는 이러한 자동화된 디버깅이나 테스트 과정을 제공하기 어려워, 직접 데이터를 대조하며 결과를 검증해야 하는 수고가 필요합니다. 이러한 점에서 쿼리 방식은 대규모 데이터나 예외 처리 로직이 많을 경우 작업 난이도가 높아질 수 있습니다.
마무리
Postgres_fdw를 활용한 데이터 마이그레이션은 다른 데이터베이스의 데이터를 직접 조회 및 활용할 수 있다는 점에서 많은 이점을 제공했습니다. 코드 작성 대신 쿼리를 활용하여 생산성을 극대화할 수 있었고, 그 결과 짧은 기간 안에 마이그레이션 작업을 성공적으로 완료할 수 있었습니다.
물론, 앞서 언급한 장점과 단점에서 보았듯이 모든 상황에 해결 가능한 은총알은 없습니다. 상황에 맞는 마이그레이션 방식을 선택하는 게 중요할 것입니다. 저희는 postgres_fdw를 활용하며 복잡한 데이터 구조를 효율적으로 다루는 데 쿼리 기반 접근법이 적합하다고 판단했고, 이러한 경험을 통해 많은 것을 배울 수 있었습니다.
이 글이 비슷한 사례를 고민하고 계신 분들께 참고가 되고, 적합한 마이그레이션 방식을 선택하는 데 조금이나마 도움이 되길 바랍니다.
참고문서
- PostgreSQL: Documentation: 17: F.36. postgres_fdw — access data stored in external PostgreSQL servers
- Performance Tips for Postgres FDW
- 4.2. How the Postgres_fdw Extension Performs
