검색 성능 개선을 위한 Elasticsearch 인덱스 구조와 쿼리 최적화
2023년 12월, 배달의민족 앱 상단 검색 기능에 장보기•쇼핑 탭이 추가되었습니다. 검색 창에 검색어를 입력하고 장보기•쇼핑 탭을 누르면 비마트와 배민스토어 상품만 검색할 수 있는 기능입니다.
커머스검색개발파트에서는 Elasticsearch(이하 ES)를 활용해 커머스 검색과 상품 목록 페이지를 제공하는 리스팅 API를 개발하고 운영하고 있으며, ES를 보다 효율적으로 활용하기 위해 다양한 최적화 작업을 진행하고 있습니다.
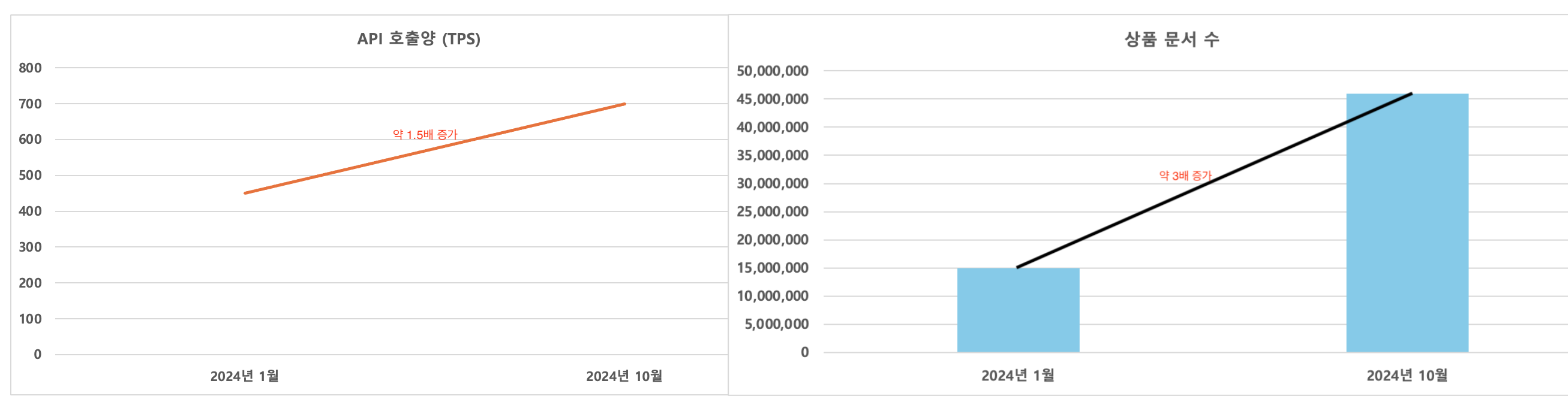
비마트와 배민스토어 상품만 검색할 수 있는 서비스를 오픈한 이후, GS25, GS the Fresh, 이마트에브리데이, CU 등 대형 셀러의 지속적인 추가로 색인 문서의 양이 약 3배 증가했습니다. 또한, 검색 API에 다양한 필터와 검색어 매칭 필드가 추가되었고, 리스팅 API를 새롭게 제공하면서 검색 및 리스팅 API 호출 수는 약 1.5배 증가했습니다. 특히 새로운 영역에서도 리스팅 API 호출이 계속 확대되고 있는 상황입니다.
2024년 1월, 2024년 10월 비교
이처럼 서버가 처리해야 할 기능과 요청량이 급격히 증가하면서 성능 최적화의 중요성이 대두되었습니다. 올해 초부터 커머스 검색 API의 레이턴시 개선을 목표로 다양한 작업을 진행했으며, 특히 ES 인덱스 구조와 쿼리 최적화를 통해 성능을 크게 개선할 수 있었습니다. 이번 글에서는 이러한 성능 개선 과정과 쿼리 최적화에 적용한 주요 방법들을 자세히 공유드리려 합니다.
성능개선을 돕는 도구
개선 과정을 공유드리기 앞서, 성능개선을 돕는 도구들을 먼저 소개드리겠습니다.
API 응답값 비교 스크립트
API 서버는 Nginx가 리버스 프록시 역할을 하여 Spring Boot Web Server로 요청을 전달하고 있습니다.
API 응답값 비교 스크립트는 Nginx의 access log를 기반으로 운영버전 API와 변경버전 API를 호출하여, 응답값의 차이를 검증하는 데 사용됩니다. 이 스크립트는 성능 개선, 대규모 리팩토링, 마이그레이션 작업 등에서 기존 API와 변경된 API의 응답값이 동일한지 확인하기 위해 개발되었습니다.
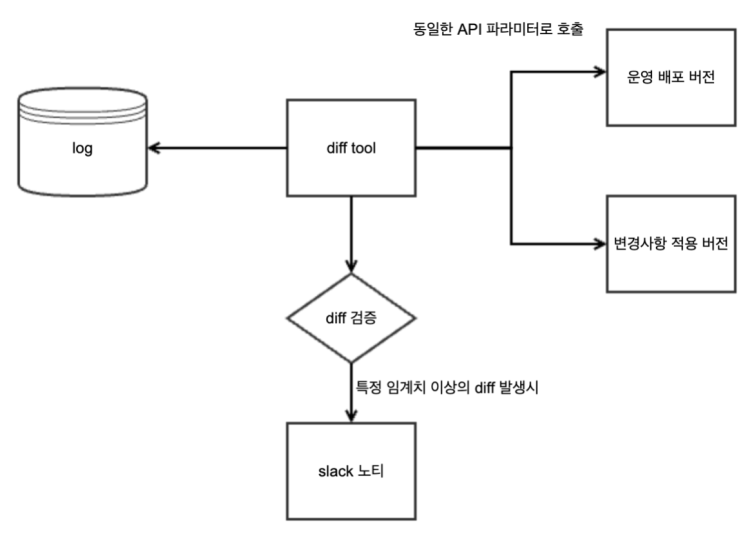
여러 차례의 검색 API의 성능개선 과정에서 이 스크립트를 이용하여 변경 코드가 응답값에 영향을 주는지 검증하도록 하여 서비스 장애가 발생하지 않고 안전하게 성능 개선을 진행했습니다.
참고 자료
슬로우 쿼리 수집기
Nginx의 access.log에는 요청의 응답 시간(request_time)이 기록됩니다. 검색 API에서는 응답 시간이 0.7초 이상 소요되는 요청을 슬로우 쿼리로 간주하며, 이를 모니터링하여 개선점을 도출했습니다.
$request_time
request processing time in seconds with a milliseconds resolution; time elapsed between the first bytes were read from the client and the log write after the last bytes were sent to the client
이제 검색 성능 개선을 위한 5가지 과정들을 공유드리도록 하겠습니다.
- 카테고리 필터 적용 시 레이턴시 지연현상 개선
- 포켓몬 키워드로 인한 레이턴시 지연현상 개선
- Painless 스크립트를 활용한 정렬 제거
- track_scores: true → false 로 변경, 분석되는 term 개수에 따른 쿼리 최적화
- analyzer 라이브러리화
카테고리 필터 적용 시 레이턴시 지연현상
현상
대부분의 커머스 검색에서 제공하는 ‘카테고리 필터링’기능으로, 검색 결과를 특정 카테고리로 좁혀 볼 수 있게 하는 요청에 레이턴시 지연 현상이 발생했습니다.
특정 카테고리를 필터링하는 경우 검색 API의 요청 파라미터로는 categoryId 값이 들어갑니다. (예. categoryId=1000) 검색 API에서는 ES 상품 인덱스에 아래 쿼리를 포함하여 이 카테고리에 대한 상품만을 필터링합니다.
{
"query": {
"bool": {
"filter": [
...
{
"term": {
"categoryId": 1000
}
}
...
]
}
}
}겉으로 보기에는 문제가 없어 보이는 쿼리였지만, 카테고리 필터가 있을 때와 없을 때 검색 API의 응답 속도 차이는 매우 큰 편이었습니다.
카테고리 필터 유무에 따른 API 응답 속도 비교
- 카테고리 필터가 없는 경우 : 115ms
- 카테고리 필터가 있는 경우 : 980ms
문제 원인 분석 및 해결
원인을 파악해 보니 카테고리ID의 필드 타입 설정에 문제가 있었습니다. 카테고리ID 필드는 숫자이기 때문에 integer로 색인을 하였는데요. 카테고리ID 는 범위 검색을 하는 필드가 아니고 정확하게 일치하는 값을 찾아내는 용도로만 쓰고 있기 때문에 keyword로 타입을 변경하고, term필드로 쿼리가 수행될 수 있도록 변경하였습니다.
개선 결과
- 카테고리 필터로 인한 슬로우 쿼리는 더 이상 발생하지 않게 되었습니다. 아래는 개선 전후 달라진 내용입니다.
| 구분 | 개선 전 | 개선 후 |
|---|---|---|
| categoryId 필드 타입 |
|
|
| 쿼리 예시 |
|
|
| API 응답시간 | 980ms | 104ms |
- 이 문제를 해결하고 나니 특정 키워드에 대한 슬로우 쿼리를 확인할 수 있었습니다.
numeric, keyword 타입 색인/쿼리 비교
numeric, keyword 타입이 내부적으로 어떻게 색인이 되고 term쿼리를 수행했을 때 어떻게 데이터를 찾아오게 되는지 조금 더 조사해보았습니다.
색인
- numeric (숫자) 타입 : Lucene 내부적으로는 PointValues로 색인하게 되는데 이는 KD-Tree 자료구조를 사용하여 저장이 되어있다고 합니다.
Points represent numeric values and are indexed differently than ordinary text. Instead of an inverted index, points are indexed with data structures such as KD-trees. These structures are optimized for operations such as range, distance, nearest-neighbor, and point-in-polygon queries.
- keyword 타입 : 역인덱스타입으로 저장되어 있습니다. 정확하게 일치하는 값으로만 쿼리가 가능합니다.
쿼리
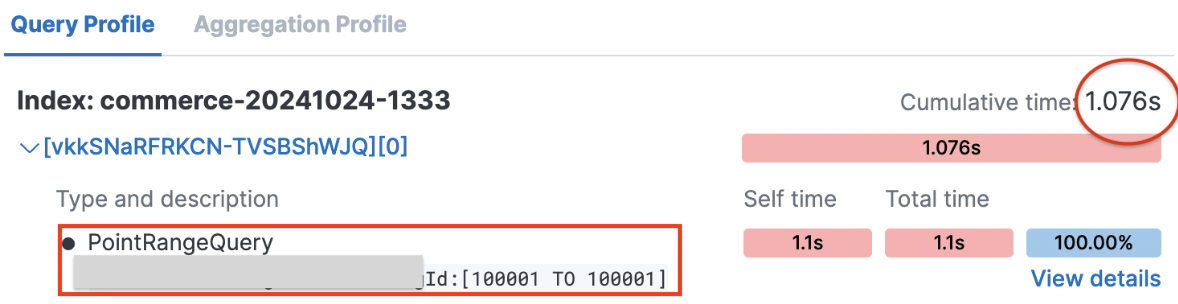
kibana로 아래 쿼리를 프로파일링해 보면, 내부적으로 수행되는 Lucene 쿼리가 다른 것을 확인할 수 있었습니다.
쿼리를 수행한 인덱스의 문서 수는 4천만 건입니다.
{
"query": {
"term": {
"$content.catalogPath0.catalogId": {
"value": 100001
}
}
}
}- integer 타입을 term 쿼리했을 때: PointRangeQuery가 수행됨.
- 숫자,날짜 등의 범위 검색에 적합한 쿼리라고 할 수 있습니다.
- KD-trees를 기반으로 범위 검색을 수행합니다.
- 숫자,날짜 등의 범위 검색에 적합한 쿼리라고 할 수 있습니다.
- keyword 타입을 term 쿼리했을 때: TermQuery가 수행됨.
- 말그대로 매칭된 term 이 있는지를 찾는 쿼리입니다. keyword 타입은 역색인으로 저장되어 있기에 바로 접근하여 가져옵니다.
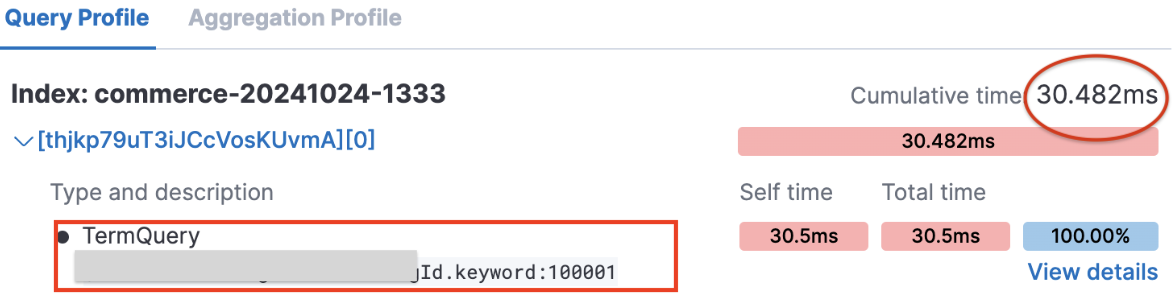
- 단일 값에 대한 검색은 빠르지만 범위 검색은 불가능합니다.
- 말그대로 매칭된 term 이 있는지를 찾는 쿼리입니다. keyword 타입은 역색인으로 저장되어 있기에 바로 접근하여 가져옵니다.
포켓몬 키워드로 인한 레이턴시 지연현상
현상
카테고리 필터 문제를 해결하고 나니 대부분의 슬로우쿼리를 유발하는 키워드는 "포켓몬" 키워드로 검색하는 경우인 것을 확인할 수 있었습니다.
문제 원인 분석 및 해결
ES 쿼리의 성능 문제를 분석한 결과, 특정 카테고리에 속한 키워드 점수를 부스팅하기 위해 사용한 function_score 쿼리에서 원인을 발견했습니다.
당시 쿼리는 다음과 같은 구조로 작성되어 있었습니다.
{
"from": 0,
"size": N,
"query": {
"bool": {
"filter": [
1️⃣ 상품상태와 관련된 매칭 조건, 키워드 매칭 조건 필터링
]
"must": [
{
"bool": {
"must": [
{
"function_score": {
"query": {
"match_all": { } 2️⃣
},
"functions": [
부스팅 조건을 만족할때의 점수부여하는 쿼리들
],
"score_mode": "",
"boost_mode": ""
}
}
],
"should": [
필드별 매칭 조건에 따른 점수부여
]
}
}
]
}
},
"aggregation": {
각종 aggregation 쿼리
}
}문제점
- 1️⃣에서 필터링된 결과에 function_score 쿼리가 적용될 것으로 예상했으나, 실제로는 2️⃣ (
"query": { "match_all": {} })에 의해 모든 문서에 대해 부스팅 조건을 실행하고 있었습니다. - 이로 인해 특정 키워드(예: "포켓몬")가 최상위 카테고리에 속하고 대부분의 문서에 색인된 상황에서, 불필요하게 functions 내의 부스팅 연산을 수행하고 있었습니다.
해결 방안
function_score 쿼리의 "filter" 조건에 1️⃣ (기존 bool – filter의 쿼리)를 포함하도록 수정했습니다. 이를 통해 부스팅 조건이 사전에 필터링된 결과에만 적용되도록 변경했으며, 그 결과 쿼리 속도가 크게 개선된 것을 확인했습니다.
개선 후 쿼리
{
"from": 0,
"size": N,
"query": {
"bool": {
"filter": [
1️⃣ 상품상태와 관련된 매칭 조건, 키워드 매칭 조건 필터링
],
"must": [
{
"bool": {
"must": [
{
"function_score": {
"query": {
"bool": {
"filter": [
1️⃣ 상품상태와 관련된 매칭 조건, 키워드 매칭 조건 필터링
]
}
},
"functions": [
부스팅 조건을 만족할때의 점수 부여하는 쿼리들
],
"score_mode": "",
"boost_mode": ""
}
}
],
"should": [
필드별 매칭 조건에 따른 점수부여
],
}
}
]
},
"aggregation": {
각종 aggregation 쿼리
}
}개선 결과
포켓몬 키워드로 인해 발생한 슬로우쿼리가 모두 사라지게 되었습니다.
이 작업 이후, function_score 쿼리에서 1️⃣ 블록이 두 군데에 중복으로 filter가 있게 되었는데, 중복 쿼리 및 의미없는 depth가 생긴 쿼리들을 최적화하는 작업을 진행해 쿼리 가독성을 높이도록 했습니다. 이러한 개선 작업으로 쿼리 구조가 더 명확해지고, 쿼리 분석 및 변경 작업이 더욱 효율적으로 이루어질 수 있게 되었습니다.
Painless 스크립트를 활용한 정렬 제거하기
현상
배민의 커머스 상품은 대형 셀러(GS25, GS the Fresh, 이마트에브리데이, CU 등)의 입점으로 셀러 * 지점수에 비례하여 상품 수가 증가합니다. 서비스 초기에는 약 1천만 건이었던 상품 수가 현재는 5천만 건을 넘어섰으며, 앞으로도 대형 셀러의 지속적인 입점으로 상품 수는 계속 증가할 전망입니다. 또한, 커머스검색개발파트에서 지원하는 API는 키워드 검색뿐만 아니라 상품 리스팅을 위한 API, 상품 목록 화면의 카테고리별 상품 수를 반환하는 aggregation API 등 다양한 기능을 제공하며, 이에 따라 성능 개선 작업도 꾸준히 진행되고 있습니다.
키워드 검색 API에서는 여전히 무거운 쿼리로 인해 레이턴시 지연 현상이 발생하고 있었습니다. 위에서 특정 사례를 중심으로 쿼리를 개선하는 작업을 진행했으나, 근본적인 원인을 파악하고 이를 해결하기 위한 추가적인 개선이 필요했습니다.
문제 원인 분석 및 해결
원인을 분석한 결과, 검색에서 셀러별로 aggregation을 수행하고, 이를 그룹화된 형태로 정렬을 하기 위해 top_hits aggregation을 사용하는 과정에서 성능 차이가 발생하는 것을 확인했습니다. 특히, 정렬 과정에서 사용된 Painless script가 근본적인 부하의 원인임을 알게 되었습니다. 이 스크립트는 ES 쿼리로 반환된 _score 값을 기반으로 점수를 역산하여 스케일링하고, 입력된 키워드와 매칭되는 점수를 계산하는 작업을 수행했습니다.
추가로, 스크립트 내에서 계산하던 keywordMatchingScore, ctrScore, recommendScore와 같은 로직을 제거하고, 이를 쿼리 단계에서 처리할 수 있도록 수정하여 성능 개선을 이루었습니다.
{
"_script": {
"script": {
"source": """
_score 역산하여 추출 후 점수 보정 연산한 키워드 매칭 점수
def keywordMatchingScore = ...
검색 키워드에 대한 ctrFeature가 반영된 점수
def ctrScore = ...
상품의 점수 필드를 위해 여러 값들의 수식을 적용하여 합산한 점수
def recommendScore = ...
return keywordMatchingScore + ctrScore + recommendScore;
""",
"lang": "painless",
"params": {
"keyword": "우유"
}
},
"type": "number",
"order": "desc"
}
},keywordMatchingScore
검색한 키워드에 문서 필드가 매칭되었을때 가중치를 부여하는 부분입니다. 이 점수를 전체 점수를 보정하기 위해서 _score 내에서 keywordMatchingScore를 추출해서 값을 역산하게 되었는데요. 아주 간단한 원리를 이용해서 분리했습니다.
필드 productName, sellerName, shopName에 매칭될 점수가 productName = 10 , sellerName = 20, shopName = 30이라면 점수보정연산을 미리 적용한 뒤 쿼리에 적용하여 해결했습니다.
- 개선 전: (10 + 20 + 30) * 점수보정연산
- 개선 후: 10 * 점수보정연산 + 20 * 점수보정연산 + 30 * 점수보정연산
{
"bool": {
"should": [
{
"constant_score": {
"filter": {
필드 productName에 대한 조건 쿼리
}
},
"boost": 10 * 점수보정연산
},
{
"constant_score": {
"filter": {
필드 sellerName에 대한 조건 쿼리
}
},
"boost": 20 * 점수보정연산
},
{
"constant_score": {
"filter": {
필드 shopName에 대한 조건 쿼리
}
},
"boost": 30 * 점수보정연산
}
]
}
}CTR Score
검색한 키워드가 특정 키워드에 매칭되었을때 가산점을 부여하는 부분입니다. Painless 스크립트를 사용해 반복문으로 질의 키워드와 일치하는 키워드를 찾고 점수를 부여하는 방식으로 구현되었습니다. 의도한 대로 동작하긴 했지만, 반복문 처리로 조회 속도에 부정적인 영향을 미치는 문제가 있었습니다.
샘플 데이터
{
"ctrFeatures":[
{
"ctrKeyword":"배추",
"ctrScore":0.0127
},
{
"ctrKeyword":"종가집",
"ctrScore":0.7036
},
{
"ctrKeyword":"김치",
"ctrScore":0.4284
}
]
}
검색한 키워드와 일치하는 키워드에 ctrScore 를 반환하는 함수
def getCtrScore(def ctrFeatures, def keyword) {
if (ctrFeatures == null) {
return 0.0;
}
return ctrFeatures.stream()
.filter(feature -> feature.ctrKeyword.equals(keyword))
.map(feature -> feature.ctrScore)
.mapToDouble(Double::doubleValue)
.max()
.orElse(0.0);
}위 문제를 해결하기 위해 Lucene에서 제공하는 Payload 값을 활용하는 방식을 도입했습니다. Payload는 특정 term에 추가로 저장할 수 있는 메타데이터를 의미합니다. ES는 Payload 값을 색인할 수 있도록 Delimited payload token filter를 제공합니다.
Payloads
A payload is user-defined binary data associated with a token position and stored as base64-encoded bytes.
아래와 같은 형태로 데이터를 색인하면서 Payload 값을 점수로 저장해두고, 검색한 키워드가 매칭될 경우 해당 점수를 부여하도록 구현했습니다. 다만, ES는 기본적으로 검색 시 Payload 값을 활용한 스코어링 기능을 제공하지 않습니다. 이를 해결하기 위해 커스텀 쿼리 플러그인을 구현하여 검색 시 Payload 값을 점수에 반영할 수 있도록 처리했습니다.
"ctrScore": "배추|0.0127 종가집|0.7036 김치|0.4284"ctrScore 점수 연산 쿼리
{
커스텀 쿼리 플러그인으로 정의한 쿼리 이름
"woowa_payload_score": {
"query": {
Lucene의 PayloadScoreQuery는 SpanQuery를 파라미터로 전달받게 되어 있어 span_term 을 사용
"span_term": {
"ctrScore": {
"value": "검색키워드"
}
}
},
"score_mode": "max",
"decode_type": "float",
"include_span_score": false
}
}Recommend Score
이 점수는 상품에 대한 정적인 데이터로, 추천팀에서 생성한 다양한 상품 랭킹 피처 값을 기반으로 합니다. 기존 스크립트 코드에서는 여러 필드의 값을 합산하거나 특정 수식을 적용했지만, 이를 색인 시점에 미리 계산하여 저장하도록 변경했습니다. 이후 검색 시에는 function_score 쿼리의 field_value_factor를 활용해 해당 점수를 반영하도록 구현했습니다.
쿼리 예시
{
"bool": {
"should": [
{
"function_score": {
"query": {
"term": {
"recommendScore.enable": {
"value": true
}
}
},
"functions": [
{
"filter": {
"match_all": {}
},
"field_value_factor": {
"field": "recommendScore 필드",
"factor": 1,
"missing": 0
}
}
],
"score_mode": "sum",
"boost_mode": "replace"
}
}
]
}
}여기서도 마찬가지로, function_score 쿼리에 별도의 조건을 지정하지 않으면 match_all 쿼리가 적용됩니다. 이에 따라, 스코어가 있는 문서들만 대상으로 필터링을 수행하도록 설정했습니다.
이 과정을 통해 Painless 스크립트 쿼리를 제거하였으며, 최종 쿼리는 다음과 같은 형태가 되었습니다.
{
"from": 0,
"size": N,
"query": {
"bool": {
"must": [
{
"bool": {
"must": [
{
"function_score": {
"query": {
"bool": {
"filter": [
상품상태와 관련된 매칭 조건, 키워드 매칭 조건 필터링
]
}
},
"functions": [
부스팅 조건을 만족할때의 점수부여하는 쿼리들
],
"score_mode": "",
"boost_mode": ""
}
}
],
필드별 매칭 조건에 따른 점수부여
"should": [
keywordMatchingScore 점수 연산 쿼리
{
"constant_score": {
"filter": {
필드 A 에 대한 조건 쿼리
}
},
"boost": 10 * 점수보정연산
},
ctrScore 점수 연산 쿼리
{
"woowa_payload_score": {
"query": {
"span_term": {
"ctrScore: {
"value": "검색키워드"
}
}
},
"score_mode": "max",
"decode_type": "float",
"include_span_score": false
}
},
recommendScore 점수 연산 쿼리
{
"function_score": {
"query": {
"term": {
"recommendScore.enable": {
"value": true
}
}
},
"functions": [
{
"filter": {
"match_all": {}
},
"field_value_factor": {
"field": "recommendScore 필드",
"factor": 1,
"missing": 0
}
}
],
"score_mode": "sum",
"boost_mode": "replace"
}
}
],
}
},
],
(이하 생략)개선 결과
-
aggregation 수행 속도가 2배 이상 향상되었습니다.
-
배포 전후 API의 평균 레이턴시 비교한 결과, p99.9와 p99.99의 응답 속도가 20% 개선되었습니다.
-
API 응답 시간이 0.7초 이상인 슬로우 쿼리 횟수가 절반으로 감소했습니다.
track_scores: true → false 로 변경, 분석되는 term 개수에 따른 쿼리 최적화
현상
Painless 정렬 스크립트를 제거한 이후, 레이턴시가 크게 개선된 것을 확인한 뒤 ES 데이터 노드의 스펙을 기존의 절반 수준으로 낮춰보았습니다. 그러나 트래픽이 집중되는 시간대에는 줄어든 코어 개수로 인해 데이터 노드의 CPU 사용률이 85%까지 치솟는 문제가 발생했습니다. 안정성을 확보하기 위해 데이터 노드 스펙을 다시 이전 스펙으로 되돌렸고, 슬로우 쿼리가 완전히 제거되지 않아 추가적인 쿼리 개선 포인트를 찾아내야만 했습니다.
문제 원인 분석 및 해결
track_scores: true → false 로 변경
기존 Painless 정렬 스크립트에서는 _score 값을 사용하여 스코어를 역산하여 추가적인 점수를 부여하는 형태로 구성되어 있었습니다. Painless 스크립트에서 _score를 참조하려면 track_scores 값을 true로 설정해야만 참조가 가능합니다. 이 track_scores 값은 검색 성능에 아주 큰 영향을 주는 부분이었습니다.
- track_scores : ES 검색 쿼리에서 각 문서의 관련성 점수(
_score)를 계산하고 저장할지 여부를 결정하는 설정 - true / false 차이
- true: 모든 문서에 대해 점수를 계산하고 저장
- false: 점수를 계산할 필요가 있는 경우에만 계산, 상위 N개에 대한 문서를 찾기 위해 ES에서는 효율적인 알고리즘을 사용하여 필요한 문서만을 선별하여 계산함.
Painless 정렬 스크립트는 이제 더 이상 사용하지 않고 있기에 track_scores 값을 false 로 변경하였습니다.
분석되는 term 개수에 따른 쿼리 최적화
슬로우 쿼리를 계속해서 분석하다보니, 특정 일부 키워드들에 대해서 오래 걸리는 현상이 발견되었습니다. 쿼리를 분석하다보니 성능에 영향을 주는 부분은 키워드의 부스팅 조건을 만족할때 추가점수를 부여하도록 하는 쿼리에서 발생하는 것을 확인했습니다. 부스팅 조건을 확인할 때 입력한 검색어와 매칭되는 필드의 순서 보정을 위하여 match_phrase쿼리를 사용하고 있는데요.
예) 피자치즈 키워드로 검색시, 피자 / 치즈로 형태소분석되지만 문서에는 피자 – 치즈 순서로 색인되어 있는 문서만 적용되어야 함. 치즈 – 피자에는 적용되면 안 됨
단일 term일 경우 match_phrase 쿼리가 아니라 match 쿼리로도 요구사항을 만족할 수 있기 때문에 분석된 term에 따라 쿼리를 변경하도록 쿼리를 분기하였습니다. 커머스 검색 API 는 API 호출 흐름상 검색 쿼리를 수행하기 전 검색어에 대해 _analyze 를 수행하고 있기에 term 개수를 미리 확인할 수 있었습니다.
if (tokens.size() == 1) {
return QueryBuilders.matchQuery(fieldName, keyword);
} else {
return QueryBuilders.matchPhraseQuery(fieldName, keyword)
.slop(0);
}개선 결과
- 검색 API 레이턴시 2배 개선되었고, 연초부터 모니터링하던 응답시간 0.7초 이상 슬로우쿼리가 모두 제거되었습니다.
- 피크 시간대 기준으로 ES 데이터노드 CPU 사용량이 10% 감소하였습니다.
analyzer 라이브러리화
현상
커머스검색 시스템 내에서 검색 API, admin, batch 동작 중 키워드 분석에 대한 형태소 분석 과정이 존재합니다. 이를 ES의 analyze API로 이용하고 있었는데 admin, batch에서는 큰 문제가 발생하진 않지만 검색 API의 경우 아래와 같은 현상이 있었습니다.
- 검색 API 수행 중 1회 요청에 총 2회의 analyze API 요청이 발생하게 되는데, 이때의 네트워크 통신 비용과 ES 부하가 생기게 됩니다. 또한, 짧은 timeout으로 인한 실패하는 경우도 발생했습니다.
- 색인이 다량 발생하는 시점에 ES 내부에서 segment merge가 발생할 경우 analyze 요청이 reject되는 상황이 생겼습니다.
문제 원인 분석 및 해결
형태소분석기는 ES의 plugin 형태로 적용이 되어있습니다. plugin의 내용을 라이브러리화하고, 이를 사내 nexus에 업로드하여 application(검색 API , admin, batch)에서 분석하도록 코드를 심었습니다. ES 인덱스의 분석기에 적용된 char filter, tokenizer, filter 등 모든 정보를 analyzer 라이브러리에서도 동일하게 적용되도록 하여 _analyzer API와 analyzer 라이브러리의 동작이 일치하도록 구현했습니다.
개선 결과
- ES analyze API 호출 없이(네트워크 호출 없이) 내부 라이브러리로 analyze를 할 수 있게 되었습니다.
- ES 에서 analyze 요청이 다량 발생했을 때 rejected 현상이 더 이상 발생하지 않도록 개선했습니다.
- ES coordinate node (searcher) CPU 사용률이 max 기준 20% → 13%으로 개선되었습니다.
- analyze rejected 현상이 사라졌습니다.
- analyze timeout 현상 제거 : timeout 발생시 error 로그로 남던 케이스들이 배포 이후 완전히 사라졌습니다.

개선 후 결과
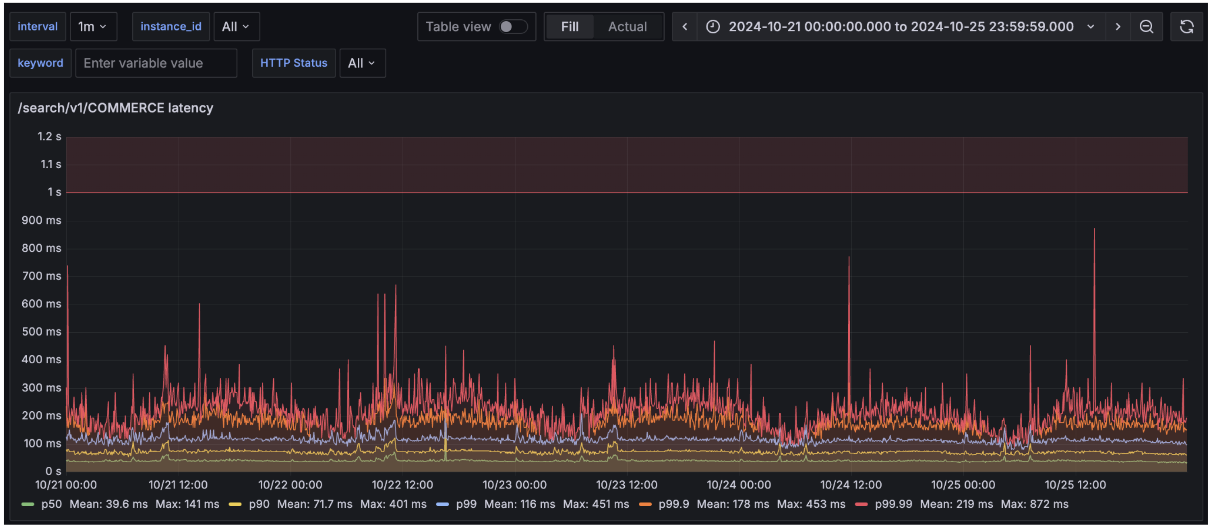
위 5가지 작업을 통해 커머스 검색 API의 레이턴시 매트릭이 개선되었습니다. 특히, p99.9와 p99.99 지표가 눈에 띄게 향상되었습니다.
-
개선 전(2024년 1월)
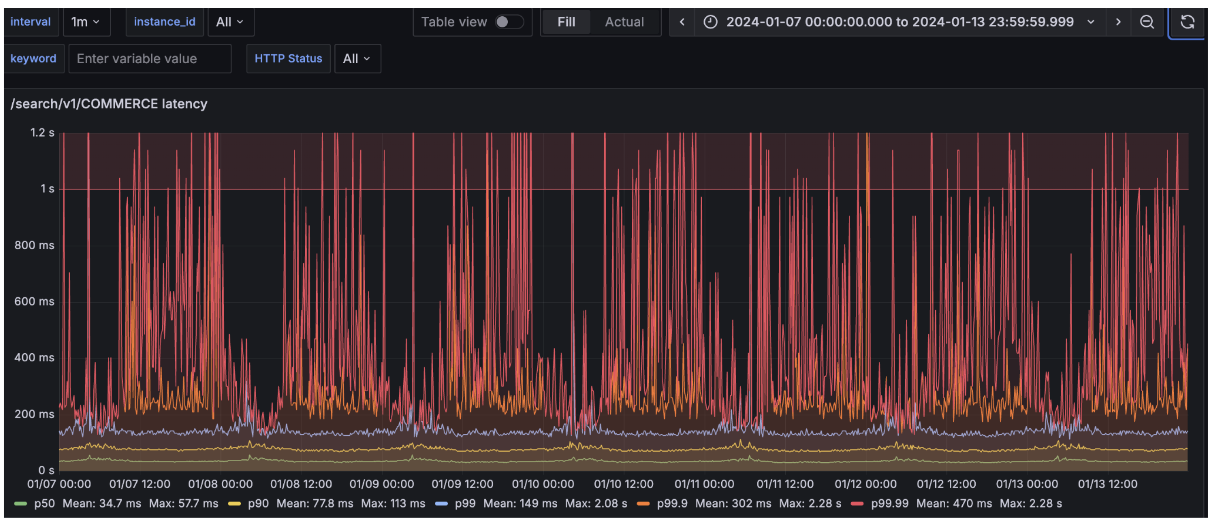
-
개선 후(2024년 10월)
맺으며
소개한 다섯 가지 API 성능 개선 사례는 Elasticsearch 공식 문서에서 제공하는 기본적인 원칙과 내용을 바탕으로 이루어졌습니다. 단순히 “쿼리는 ES가 알아서 최적화해 주겠지”라는 생각에서 벗어나, 원리를 이해하고 직접 개선한 결과였습니다. 이번 글에서는 검색 쿼리와 관련된 성능 개선 작업에 초점을 맞췄지만, 색인 구조와 관련한 성능 최적화 작업도 병행하고 있습니다.
커머스검색개발파트에서는 배달의민족 커머스의 성장에 발맞추어 색인량과 검색량의 증가에 따른 다양한 개선 포인트를 찾아내고 해결하는 과정에서 즐거움을 느끼고 있습니다. 앞으로도 커머스에서 더 편리한 검색 경험을 제공하도록 노력하겠습니다.
