제목은 안정적인 AI 서빙 시스템으로 하겠습니다. 근데 이제 자동화를 곁들인…
요즘 음식점에 가면 서빙 로봇이 음식 서빙을 해주는 모습을 종종 보셨을 겁니다. 음식을 손님에게 제공하기까지는 재료 준비, 손질, 요리 서빙 등 여러 단계를 거쳐야 하는데요. 서빙 로봇을 사용하게 되면 서빙하는 과정을 생략하고 요리에만 더욱 집중할 수 있습니다.
데이터를 학습하여 AI 모델을 만들고 서비스로 배포하는 과정 또한 식당에서 음식을 제공하는 과정이랑 비슷합니다. 실제 서비스로 배포하는 과정을 크게 신경 쓰지 않게 된다면 AI 모델 학습에만 집중할 수 있을 겁니다.
우아한형제들의 AI플랫폼에서는 서빙 자동화 시스템을 구성하여 AI 모델을 생성만 하면 모델 배포 및 관리 등의 작업을 알아서 처리해 줍니다. 오늘 우리는 이 서빙 자동화 시스템이 어떻게 구성되어 있는지 알아보겠습니다.
AI플랫폼이란?
AI 기술을 비즈니스에 접목하려면 매우 많은 기술이 필요합니다. 데이터를 관리하는 것뿐만 아니라, AI 모델을 학습하기 위한 파이프라인부터 AI 모델을 사용할 수 있게 서빙하는 과정 등 여러 컴포넌트가 복잡하게 얽혀 있습니다.
이러한 각 컴포넌트를 유기적으로 결합하여 쉽게 사용할 수 있게 만든 것이 바로 AI플랫폼입니다. AI플랫폼을 구성한 환경은 아래 그림과 같고, 기술블로그 글 "배민 앱에도 AI 서비스가? AI 서비스와 MLOps 도입기"에서도 확인하실 수 있습니다.

그중에서도 서빙이란, 학습된 AI 모델을 실제 운영 환경에 배포하여 사용자가 실시간으로 요청할 수 있도록 API 형태로 제공하는 과정입니다. AI 모델이 안정적이고 빠르게 응답할 수 있도록 성능 최적화, API 생성, 확장성 관리, 버전 관리, 모니터링 등을 포함합니다.
매일 엄청난 양의 데이터가 생성되고 이 데이터를 이용해 새로운 AI 모델이 꾸준히 학습되므로, AI 모델을 안정적으로 빠르게 서빙하는 것이 가장 중요합니다. 현재 AI플랫폼의 서빙 시스템은 월 약 20억 건의 트래픽을 처리하고 있습니다. 이를 위해 모델을 변경하기 위한 버전 관리, 새로 배포하는 과정에 유실이 없도록 하는 무중단 배포, 문제가 있을 때 빠르게 복구하기 위한 롤백 처리 등이 철저히 이루어져야 합니다. 오늘은 서빙 환경에 대해 알아볼 것이므로 학습된 모델은 Model Registry(AI 모델의 버전 관리가 가능한 저장소)에 저장된 상황을 가정하겠습니다.
서빙 컴포넌트
AI 서비스 개발자는 PyTorch, TensorFlow, CatBoost, Scikit Learn 등 다양한 프레임워크/라이브러리를 사용해 AI/ML 모델을 학습합니다. 그러나 이처럼 다양한 프레임워크로 모델을 서빙할 때는 모델을 불러오고 추론하는 방식이 달라 코드 일관성 유지와 유지 보수가 어려워지고 시스템 복잡성이 증가합니다.
위와 같은 문제를 해결하기 위해 AI플랫폼은 여러 프레임워크를 지원하며 빠른 개발이 가능한 BentoML을 활용해 모델 서빙 환경을 구성했습니다. BentoML은 컨테이너화를 쉽게 지원해 이후 Kubernetes 배포를 편리하게 하고, 전/후처리와 같은 비즈니스 로직을 간편하게 추가해 서비스 구성을 빠르게 완성할 수 있다는 장점이 있습니다.
아래의 코드는 AI플랫폼에서 BentoML을 이용해 AI 모델을 API 형태로 서빙하는 예제입니다.
@service
class SampleProject:
# 생성자. Model Registry에서 모델을 불러옵니다.
def __init__(self):
self.model = load_model(...)
# 추론 함수. 들어온 입력에 대해 모델을 추론하고 그 출력을 반환합니다.
@api
def inference(self, text: str) -> int:
output = self.model.infer(pre_process(text))
return post_process(output)이렇게 간단히 작성만 해주면 /inference path로 호출 시 모델 추론 결과를 얻을 수 있는 API를 띄울 수 있게 됩니다. 나머지 모든 작업은 AI플랫폼에서 자동으로 해줍니다. 이로써 AI 서비스 개발자는 다른 것은 신경 쓰지 않고 모델 개발에만 집중할 수 있어 개발 속도가 빨라지며 개발 코드 사이에 일관성 또한 유지됩니다. 그렇다면 어떻게 나머지 작업을 자동화할 수 있었는지 살펴보겠습니다.
CI (Continuous Integration): 이미지 생성 자동화
위에 보신 것과 같은 서비스 코드가 GitLab 코드 저장소로 푸시되면 GitLab CI 파이프라인에서 여러 테스트를 거쳐 Docker 이미지가 생성됩니다. AI플랫폼에서는 하나의 레포에서 모든 서비스를 관리하는 모노레포 방식으로 관리하고 있는데요, 이때 CI는 동적으로 파이프라인을 생성하도록 설계하여 새로운 서비스가 생성될 때 추가 작업이 필요 없습니다.

이미지를 빌드하는 과정에서는 모델을 이미지 내에 넣는 방식을 사용했습니다. 빌드 시간이 오래 걸리고 데이터를 많이 차지한다는 단점이 있지만, Model Registry와의 연결이 생략되어 SPOF(Single Point Of Failure, 하나의 구성 요소가 장애일 때 전체 시스템이 중단될 위험이 있는 지점) 이슈를 회피하며 안정성을 높이는 장점이 있습니다. 그리고 서빙 로직과 모델 버전을 일치시키는 과정이 없어 문제가 있으면 빠르게 복구하며 코드 복잡도를 낮출 수 있다는 장점이 있습니다. 이렇게 생성된 이미지는 Docker Registry에 저장되고 이후 Kubernetes 환경에 배포됩니다.
이때 각 서비스의 버전을 2.5.3과 같은 Semantic Versioning 방식을 이용해 관리하고 있는데요, 아래 그림처럼 각각 {Major Version}.{Minor Version}.{Patch Version}으로 구분해 변경 사항의 영향을 직관적으로 나타내는 버전 관리 방식입니다.

앞서 설명해 드린 CI 파이프라인에서 이미지가 빌드되는 경우는 일단 코드 수정이 있었을 것입니다. 단순히 로직만 변경되는 경우에는 Minor 버전이 올라가고 (2.5.3 → 2.6.0), API 입출력이 변경된 경우에는 Major 버전이 올라가게 됩니다 (2.5.3 → 3.0.0). 매일 새로 학습되거나 특정 주기를 가지고 새로운 데이터를 이용해 학습할 수가 있습니다. 이렇게 재학습 파이프라인에 의해 모델이 새로 학습되는 경우에는 Patch 버전이 올라가게 됩니다 (2.5.3 → 2.5.4).
Minor/Patch 버전이 변경된 경우에는 새로 배포해도 큰 문제가 없으므로 Rolling Update(서비스를 중단하지 않고 점진적 업데이트) 방식으로 무중단 자동 배포를 진행합니다. 만약 Major 버전이 변경된 경우에는 기존 API와 연동이 되지 않을 것입니다. 그래서 CI 파이프라인에 oasdiff(OpenAPI 명세의 변경 사항을 비교하는 하는 도구)를 이용해 현재 서빙되고 있는 API와 새로 생성될 API 사이에 breaking changes(기존 버전과 호환되지 않는 변경 사항)가 있는지 감지할 수 있게 구성했습니다. 이때는 Blue Green(두 개의 환경을 사용해 전환) 방식을 이용하는데요, 새 버전이 생성되고 API 호출을 모두 새로운 버전으로 전환하고 기존 버전을 삭제하는 형태로 수동 배포를 진행하고 있습니다.
CD (Continuous Deployment): 서빙 자동화
이후 Kubernetes 환경에 API를 배포하게 되는데, 아래 그림과 같은 구성을 가지고 있습니다.
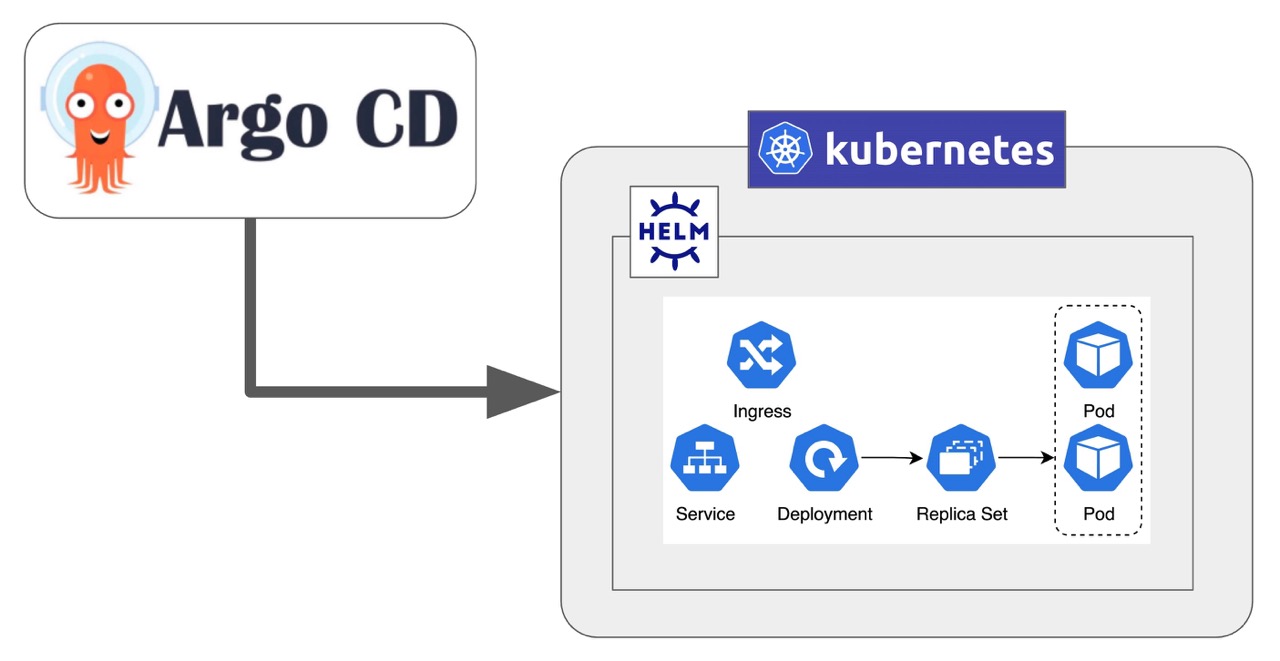
서비스별로 Namespace를 사용하며, Deployment를 이용해 Pod 형태로 컨테이너가 배포됩니다. 이렇게 배포된 Pod는 스케줄링 시스템에 의해 동적으로 리소스가 조절됩니다. 호출이 많아지면 Replica를 늘리고 (scale out) 적어지면 다시 줄이게 됩니다 (scale in).
사용자의 호출은 Ingress, Service를 거쳐 Pod로 전달됩니다. 이때 Ingress는 AWS의 ALB(Application Load Balancer)를 사용하는데, 요청량에 따라 로드밸런서의 가용량이 자동으로 설정됩니다. 그리고 Route53을 이용해 도메인을 자동으로 등록해 서비스별로 endpoint가 생성됩니다.
Pod가 배포되는 Node는 워크로드 수요에 맞춰 필요한 Node를 자동으로 생성하고 관리 해주는 확장 도구인 Karpenter를 사용합니다. 그중 NodePool을 이용하여 특정 속성을 지닌 Node 그룹을 설정해 워크로드 요구에 따라 적합한 리소스를 자동으로 할당할 수 있게 관리합니다. NodePool별로 필요한 리소스에 맞는 EC2 인스턴스를 정의해 두고 각 서비스에서는 어떤 NodePool을 사용할지 정합니다. 이후 Pod가 새로 생성되는 경우 NodePool에 해당하는 가용 Node에 생성됩니다. 만약 가용 Node가 없다면 NodePool에 정의되어 있는 EC2 인스턴스로 새로운 Node를 생성하게 됩니다.
이러한 Kubernetes 명세는 모두 Helm(Kubernetes 애플리케이션의 패키지 관리자)을 통해 관리합니다. 공통 템플릿을 정의해 두고 각 서비스에 필요한 부분만 수정하여 배포할 수 있는 유연함이 큰 장점입니다. 템플릿을 통해 생성된 차트들은 ArgoCD(애플리케이션을 자동으로 배포, 관리하는 도구)를 활용해 배포되며 Git을 통해 배포 명세를 체계적으로 관리합니다.
특히, ArgoCD Image Updater 플러그인을 사용해 Docker 이미지가 변경될 때 자동으로 배포되도록 구성했습니다. 이미지 태그를 감지하다가 앞서 설명한 것처럼 minor/patch version이 변경되었을 때 Rolling Update가 실행됩니다. 이를 통해 이미지 생성부터 배포까지의 모든 과정이 자동화되어 효율적인 운영이 가능해집니다.
모니터링 및 알람
AI플랫폼에서는 Grafana를 이용해 서빙 인프라와 서비스 각각의 메트릭을 모니터링하고 있습니다. 그리고 Prometheous를 이용해 Kubernetes 환경의 메트릭과 BentoML의 메트릭을 확인하고, CloudWatch를 이용해 ALB의 메트릭을 확인하고 있습니다. GPU를 사용하는 서비스를 모니터링할 때는 DCGM Exporter를 사용하고 있습니다.
아래는 AI플랫폼에서 구성한 모니터링 시스템의 일부분입니다.

이때 서비스별로 대시보드를 만드는 대신 하나의 대시보드에서 여러 서비스를 조회할 수 있도록 구성했습니다. 왼쪽 그림처럼 대시보드 상단에서 선택한 서비스에 해당하는 메트릭을 확인할 수 있는 구조입니다. Variables에는 service_name을 생성하는데요, Kubernetes 환경에서 Namespace 이름을 serving-sample-project-beta와 같은 포맷으로 통일해 사용하며, 오른쪽 그림처럼 정규 표현식 serving-(.*)-beta를 활용해 쿼리합니다. 이를 통해 현재 사용 중인 Namespace 이름을 모두 가져오고 필터링을 통해 sample-project와 같은 서비스명을 추출할 수 있습니다.
AI플랫폼의 서빙 알람 시스템은 크게 인프라 알람, 서비스 알람 두 가지로 나뉩니다. 인프라 알람은 AI플랫폼 관점의 알람으로 주로 시스템상의 문제이며 AI플랫폼 개발자가 담당하고 있습니다. 서비스 알람은 각 서비스에 필요한 알람으로 주로 로직상의 문제를 포함하며 AI 서비스 개발자가 문제를 해결하고 있습니다.

인프라 알람은 모니터링할 수 있는 Grafana 대시보드를 제공해 주고 메트릭이 임계치를 벗어나면 메시지를 보내게 됩니다. CPU/memory 사용량이 임계치를 넘는 경우, 특정 기간 요청량이 없는 경우 등의 알람을 전송하고 있습니다.
서비스 알람 중 배포 알람은 ArgoCD에서 자동으로 배포되었을 때 메시지로 결과를 보내주는 역할입니다. 에러 알람은 Sentry를 이용하는데요, 로직상의 문제가 발생했을 때의 여러 정보를 모아주는 역할을 합니다. 각 사용자에게 어떤 에러가 발생했는지, trace 정보로 어떤 에러일지 쉽게 유추할 수 있게 해줍니다. Kubecost를 이용해 서비스별 대략적인 비용을 알려주며, 각 환경에 맞는 비용 최적화 방법을 고려하고 있습니다.
운영 중 맞이한 문제와 해결 사례
서빙 환경을 구성하면서 발생했던 몇 가지 문제가 있었는데요, 혹시나 비슷한 경험을 하실 때 도움이 될 수도 있을까 하여 하나씩 소개해 드리겠습니다.
1. Keep Alive로 발생한 간헐적 응답 에러
서비스를 운영하던 중 왼쪽 그림과 같이 ALB에서 5xx 에러가 간헐적으로 발생하는 문제가 있었습니다. 재시도 로직이 적용되어 있어 큰 문제는 없었지만 빠른 해결이 필요했습니다. 여러 경우를 파악하던 중, Keep Alive가 원인일 것으로 판단했습니다.

Keep Alive 옵션은 HTTP 연결을 지속해 하나의 연결로 여러 요청을 보낼 수 있도록 하는 설정입니다. Keep Alive 옵션을 사용하면 연결을 재설정하지 않고도 다수의 요청/응답을 처리할 수 있어 성능이 향상됩니다. 또한 연결이 유휴 상태가 되면 일정 시간이 지난 후 종료되는데요, ALB에서 이 시간을 기본적으로 60초로 사용했습니다. BentoML에서는 따로 설정할 수 있는 옵션이 없어서 ASGI 서버로 사용되는 Uvicorn(ASGI 표준을 지원하는 Python의 웹 서버)의 기본값인 5초로 설정되어 있었는데요, 이렇게 서버 timeout이 ALB timeout보다 작게 설정되었기 때문에 문제가 발생했습니다.
오른쪽 그림처럼 서버에서 설정한 5초가 지나면 해당 커넥션은 종료하게 되는데, ALB에서는 60초로 설정돼 있으므로 끊겼다는 사실을 인지할 수 없게 됩니다. 그래서 이후 요청을 보내는 경우 요청이 실패할 수 있습니다. 커넥션 종료에 의한 에러를 방지하기 위해서는 서버의 timeout 값을 ALB에 설정한 timeout 값 이상으로 설정해야 합니다. 하지만 BentoML에는 timeout 값을 설정할 수 있는 기능이 없었고 PR(feat: add uvicorn timeouts options)을 생성해 timeout 값을 설정하는 기능을 추가했습니다. 이 설정을 추가한 후 간헐적으로 발생하던 에러를 해결할 수 있었습니다.
2. Pod와 ALB의 동기화 지연으로 인한 재배포 시 응답 에러
AI 모델이 재학습되어 재배포될 때 응답 에러가 발생하는 경우가 있었고, 원인을 파악하기 위해 이를 재현할 필요가 있었습니다. 왼쪽 그림은 테스트로 재배포를 몇 번 시도한 결과이고, 중간에 요청이 끊기면서 에러가 발생하는 것을 확인할 수 있습니다. 이는 Pod의 생명 주기와 ALB Target Group의 주기가 맞지 않아 동기화가 늦어져 발생하는 문제입니다.

새로운 Pod가 준비되어 ready 상태가 되면 기존 Pod는 삭제됩니다. 이때, ALB를 사용하는 경우에는 Target Group 또한 같이 업데이트되는데요. 아직 Target Group은 준비되지 않아 요청받을 수 없는 상태가 발생할 수 있습니다. 이를 위해 Readiness Gate(Pod가 특정 조건을 충족할 때까지 트래픽을 받지 않게 대기하는 설정) 옵션을 설정해야 하고 이 덕분에 Target Group이 ready 상태가 되어야 기존 Pod가 삭제됩니다.
하지만 이렇게 해도 새로 생성할 때의 트래픽은 문제없어지지만, 삭제되는 경우의 트래픽은 여전히 문제가 발생할 수 있습니다. 기존 Pod는 삭제되었으나 Target Group은 아직 업데이트되지 않아 요청을 보내는 경우입니다. 준비되지 않은 Target Group으로의 요청을 방지하려면 Pod가 종료되는 지연시간을 추가해야 하는데요, preStop hook(Pod이 종료되기 전에 지정된 작업을 수행할 수 있도록 설정하는 훅)에 강제로 지연 로직을 추가하면 됩니다. 충분한 지연시간(지금의 경우는 30초)을 설정해 Target Group이 정상적으로 업데이트될 때까지 기다려주면 문제를 방지할 수 있습니다.
이렇게 지연시간을 설정하면 이 시간 동안 Target Group이 업데이트되기 때문에, 앞서 설정한 Readiness Gate 옵션이 없어도 그동안 업데이트가 완료됩니다. 그래서 결론적으로는 Pod 삭제 시 지연시간을 적절하게 부여한다면 문제를 전부 해결할 수 있게 됩니다.
3. BentoML 메모리 릭 버그
기존 사용하던 BentoML을 버전을 업그레이드하던 과정에서 메모리 사용량 알람을 받은 적이 있습니다. 살펴보니 아래 그림처럼 memory leak이 발생해 점진적으로 메모리가 증가하고 있었는데요, 원인 파악을 위해 이것저것 변경해 보아도 같은 현상이 발생했습니다.

내부 로직의 대부분을 생략해 봐도 같았고 기존 버전에서 사용하던 방식인 Runner를 사용하는 형태로 해도 똑같았습니다. 그리고 최종적으로 아무 로직이 없는 튜토리얼 샘플 코드에서도 똑같이 메모리가 증가하는 것을 확인할 수 있었습니다. 이는 우리의 로직 문제가 아닌 BentoML 자체의 문제라는 것으로 파악했습니다.
이 경우에는 이슈(bug: memory leak when I am using bentoml>=1.2)를 리포팅하여 현재 상황에 대해 공유하고 메인테이너들과 소통을 이어갔습니다. 테스트해 볼 사항을 공유받으면 실험해 보고 결과를 다시 공유했습니다. 몇 차례 주고받은 후 결론적으로 새로 추가된 파일 관련 기능이 오작동해 발생한 문제였고, 해당 기능에 문제가 있는 부분을 수정해 이 문제 또한 해결할 수 있었습니다.
적극 소통을 해가며 문제를 해결하는 경험도 새로웠고 이렇듯 다양한 방법으로 헤쳐 나갈 수 있다는 점도 흥미로웠습니다. 간단히 수정할 수 있는 부분이라면 Keep Alive의 경우처럼 직접 오픈 소스에 기여하는 것이 빠를 것이고, 난도가 조금 있다면 메인테이너의 수정을 기대하며 적극 이슈를 리포팅하는 것입니다.
마무리
여기까지 우아한형제들의 AI플랫폼에서 서빙 자동화 시스템을 어떻게 구성했는지 알아보았습니다. AI플랫폼의 비전은 한마디로 하자면 "모든 사람을 AI서비스 개발자로"입니다. 즉, 누구나 쉽고 빠르게 AI서비스를 개발하고 서비스하는 환경을 만드는 것이 AI플랫폼의 주된 목적입니다.
이후에는 UI를 구성해 웹페이지에서 쉽게 서비스 생성 및 수정을 할 수 있게 개발하려고 합니다. 그리고 AI를 이용해 어떤 기능이 필요한지 설명만 해주면, 처음부터 끝까지 자동으로 생성해 주는 플랫폼을 만들고자 하는 목표가 있습니다.
AI플랫폼에 앞으로 어떤 발전이 있을지 지켜봐 주시기를 바랍니다. 🌈
이 블로그는 우아한형제들의 모회사인 ‘Delivery Hero’의 기술 블로그에도 영문으로 소개되었습니다. Stable AI Serving System, with a Touch of Automation
