Polars로 데이터 처리를 더 빠르고 가볍게 with 실무 적용기

배달시간예측서비스팀은 배달의민족 앱 내의 각종 서비스(배민배달, 비마트, 배민스토어 등)에서 볼 수 있는 배달 예상 시간과 주문 후 고객에게 전달되기까지의 시간을 데이터와 AI를 활용하여 예측하는 시스템을 개발합니다. 고객, 라이더, 사장님의 만족을 위해 앱 사용자에게 보이지 않는 다양한 시간과 리소스도 함께 예측합니다. 팀 내에서 데이터를 더 효율적이고 빠르게 처리하기 위해 고민했던 내용과 이를 해결하기 위해 Polars라는 라이브러리를 적용하고 성능을 개선한 경험담을 공유하려고 합니다.
예상 독자
- Pandas보다 메모리 효율적이고 빠른 DataFrame 라이브러리를 원하시는 분들
- TB, PB 단위도 아니고 GB 단위의 데이터를 처리하는 데에 Spark를 써야 할지 고민이신 분들
- 편의성, 비용, 학습 곡선, 복잡성(인프라, 관리 등)을 고려하니 Spark는 과한 것 같아서 대체제를 찾고 계신 분들(주로 데이터 처리 작업을 하는 DS나 MLE 분들)
- Pandas의 가독성, 표현식에 아쉬움을 느끼고 계신 분들
1. 배경
1.1. Pandas나 Spark를 대체하기 위한 도구를 탐색한 이유?
배달시간예측서비스팀에서는 학습 데이터 가공, 피처 엔지니어링, 추론 결과 처리 및 적재, 마트 생성 등의 데이터 처리 작업을 수행하고 있습니다. 이러한 작업을 할 때는 주로 아래와 같은 구조로 작업을 수행합니다.
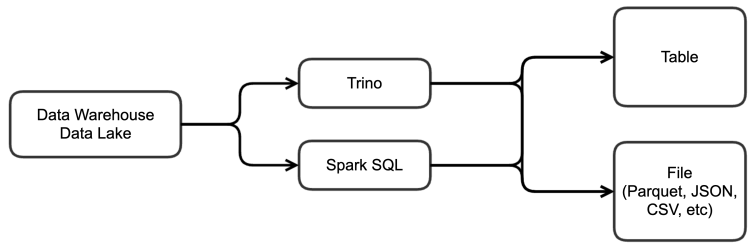
대용량 분산 처리가 필요한 부분은 Trino나 Spark 기반의 SQL을 사용하여 1차 전처리를 하고, 이를 테이블 형태 또는 S3 내에 파일 형태로 저장합니다. 데이터 처리의 중간 산출물을 저장해두는 이유는 파이프라인의 개발 및 운영 용이성을 향상하고 이슈 추적이나 데이터 드리프트 판단, 시뮬레이션 및 오프라인 섀도우 테스트에 사용하기 때문입니다. 이러한 작업을 거치고 나면 수 MB에서 수 십 GB 정도의 데이터로 줄어들게 되고, 이를 가지고 데이터 과학자와 데이터 엔지니어가 SQL로 처리하기 어려운 작업(예: UDF 적용 등)이나 피처 엔지니어링 등의 후속 작업을 수행하게 됩니다.
이 과정에서 본격적으로 제시하고자 하는 문제점과 기술 탐색의 동기가 드러나게 됩니다.
- Pandas의 문제점:
- 느리고 리소스(CPU, Memory)가 많이 소모된다.
- 멀티 코어를 제대로 지원하지 않고 병렬처리가 미흡하다.
- 가독성이 떨어진다.
- Spark의 문제점:
- 모든 데이터 과학자가 Spark로 데이터 처리 로직을 구현하고 튜닝하는 것에 익숙지 않다. (러닝 커브 존재)
- 비용 효율성이 낮다. (비싼 리소스, driver & executor 리소스 고려)
- 대용량 데이터가 아닐 때는 오히려 오버헤드 발생, slow start 문제
즉, 데이터를 분석하고 처리하는 데에 있어 Pandas는 너무 느리고 무겁고, Spark는 과하고 비싼데, 뭔가 이들을 대체할 라이브러리 또는 프레임워크가 없을까라는 고민에서 시작됐습니다.
그래서 요구사항을 정리하면 아래와 같았습니다.
- 로컬 환경에서도 편하게 개발 및 테스트가 가능해야 하고,
- 별다른 인프라가 필요 없고,
- 성능도 좋고,
- 러닝 커브도 적고,
- Airflow 환경 또는 컨테이너 기반으로 잘 패키징해서 운영 데이터 파이프라인에서 문제없이 돌릴 수 있고,
(너무 큰 욕심일 수도…)
1.2. 그래서 스터디를 진행
이를 위해 팀 내에서도 기술 조사와 테스트를 해보고 있었는데 문득 아래와 같은 생각들이 스쳤습니다.
- 이런 고민은 우리만 할까?
- 다른 회사나 팀에서는 이와 관련된 고민을 했을까? 했다면 어떻게 해결했을까?
- 다들 거대한 데이터만 다루기 때문에 Spark를 무조건 써야 할까?
- 우리가 알지 못한 다른 방식은 없을까?
- 관련 경험과 아이디어를 공유하면 더 좋은 해결책을 얻을 수 있지 않을까?
그래서 이를 사내/외 다양한 분들과 함께 고민해 보면 어떨까 싶어서 저희 회사에서 주기적으로 주최하는 우아한스터디에 관련 스터디를 열었습니다. 스터디 그룹을 모집할 당시엔 Polars는 하나의 후보였고 주로 Ray, Dask를 위주로 공부하면서 위 고민을 해결하려고 했습니다. 다양한 회사, 다양한 분야의 데이터 과학자와 엔지니어가 의견을 나누고 공부하면서 Pandas나 Spark를 대체할 오픈소스를 조사하고 테스트했습니다.

2023 우아한스터디 겨울 시즌 모집 공고

Ray, Dask 스터디 신청서
이 글의 주제인 Polars를 본격적으로 소개하기에 앞서, 이 당시 공부했던 내용을 아주 간략하게 정리하면서 다른 라이브러리들은 왜 실무에 채택되지 않았는지, 어떤 한계가 있었는지 등을 말씀드리도록 하겠습니다. 이렇게 다른 경쟁자들의 장/단점을 이야기하면 이후 이 글의 핵심인 Polars의 장점이 더욱 두드러질 것 같습니다.
- Ray
- Ray 자체는 데이터 처리보단 분산처리 프레임워크에 가깝지만, Ray Dataset API를 사용하면 Spark나 Dask처럼 병렬/분산 처리를 할 수 있지 않을까? 라는 생각에 살펴보았습니다.
- 분산 처리에 초점이 맞춰져 있고 데이터 처리 기능이 부족했고, Spark와 비슷하게 작은 데이터엔 더 비효율적이었습니다.
- 운영 배포 시 어느 정도 인프라 구축이 필요했습니다. 분산 학습과 튜닝 등 분산처리를 쉽게 적용할 수 있어서 좋은 발견이었으나 데이터 처리 목적에 맞지 않아서 탈락했습니다.
- Dask
 Pandas와 문법이 비슷하면서 상대적으로 성능이 좋았습니다. 하지만 Dask의 DataFrame은 병렬화를 위해 Pandas DataFrame을 잘게 나눈 여러 파티션으로 구성되어 있어서 성능상의 한계가 존재했습니다.
Pandas와 문법이 비슷하면서 상대적으로 성능이 좋았습니다. 하지만 Dask의 DataFrame은 병렬화를 위해 Pandas DataFrame을 잘게 나눈 여러 파티션으로 구성되어 있어서 성능상의 한계가 존재했습니다.- 병렬처리뿐만 아니라 여러 노드에 분산처리까지 가능하다는 장점이 있었지만, 성능상 아쉬운 부분, 특히나 pandas DataFrame 사용 때문인지 메모리 소모 면에서 약점을 보였습니다.
- Modin
- Pandas와의 호환성을 완벽하게 지원하여 러닝 커브나 코드 수정 없이 기존 데이터 처리 성능을 개선할 수 있다는 큰 장점이 있었습니다.
- 하지만 성능 향상에 한계가 있었습니다.
- vaex
- 문법 구조가 다르고 기능이 부족했으며, 사용 사례가 매우 적어서 탈락했습니다.
- Numba
- 일부 연산을 병렬화 및 고속화할 수 있지만 범용성은 떨어졌습니다.
2. Polars 소개
고성능 데이터 분석 및 처리 라이브러리를 선택하려고 고민했던 내용을 전달하고 싶어서 앞쪽에 여러 내용을 넣다 보니 서론이 길어졌습니다. 이제 본격적으로 이 글의 주인공인 폴라스(Polars)를 소개하겠습니다.
![]()
Polars 로고
Polars는 판다스(Pandas)와 같은 기존의 데이터 처리 라이브러리가 가진 성능적 한계를 극복하기 위해 탄생했습니다. Rust라는 프로그래밍 언어로 작성된 Polars는 멀티스레딩과 병렬 처리를 지원하여, 대규모 데이터셋을 보다 빠르고 효율적으로 처리할 수 있도록 설계되었습니다. 주요 목적은 데이터 과학자와 엔지니어들이 대용량 데이터를 다룰 때 직면하는 성능 문제를 해결하고, 메모리 사용을 최적화하며, 직관적이고 간결한 API를 통해 사용성을 높이는 것입니다. 단일 머신의 자원을 최대한 활용할 수 있도록 병렬 처리와 벡터화 연산을 통해 칼럼 기반 처리를 최적화하고, 캐싱도 효율적으로 관리하여 Vectorized Query Engine 라이브러리라고 불리기도 합니다.
한 줄 요약: "성능이 엄청 뛰어난 DataFrame 라이브러리"
오픈소스라면 아무리 성능이 좋고 사용성이 뛰어나도 사용자가 적다면 금방 없어질 수도 있고 버전업이 더딜 수도 있습니다. Polars의 Github star수를 보면 빠른 성장세를 보여주고 있습니다. 아래 그래프에서 볼 수 있듯이 이 분야의 오랜 강자인 Pandas가 2008년에 첫 공개되어 10여 년이 넘게 사용되고 있는데 이를 빠르게 추격하는 것을 볼 수 있습니다.

Polars Github star의 성장세(출처: https://star-history.com/)
이제 Polars를 기술적인 장점과 사용성 측면에서의 장점을 나누어서 설명해 드리도록 하겠습니다.
2.1. 기술적인 장점: Polars가 왜 성능이 좋은가?
2.1.1. Rust로 작성
Polars의 이름을 보면 Pola + rs(rust)일 정도로 러스트로 구현됐다는 것을 강조하고 있습니다. 러스트의 소유권 모델 덕분에 메모리 관리에 대한 오버헤드가 없으며, 안전한 동시성과 병렬 처리가 가능합니다. 메모리 캐싱과 재사용성 또한 높습니다. 이러한 특징이 데이터 처리 성능을 극대화하는 데에 크게 기여합니다.
이처럼 Polars의 코어는 러스트로 구현되어 있으며 이를 사용하기 위한 인터페이스로 Python, R, Javascript를 지원한다고 이해하시면 됩니다. 인터페이스 역할을 하는 언어는 앞으로도 계속 추가 예정이라고 합니다.
2.1.2. Apache Arrow 기반
Apache Arrow 모델을 사용하여 메모리상에서 칼럼 구조로 데이터를 정의하고, 이를 기반으로 벡터화(vectorized) 연산과 SIMD(Single Instruction Multiple Data)를 사용한 CPU 최적화를 하여 성능을 높였습니다. zero-copy 데이터 공유가 가능하고 직렬화/역직렬화 효율이 매우 높아서 여러 코어나 프로세스가 작업할 때 데이터 교환 비용을 줄일 수 있습니다.

출처: wikipedia의 SIMD 이미지
SIMD란?
병렬 컴퓨팅의 한 종류로, 하나의 명령어로 여러 개의 데이터를 동시에 계산하는 방식(GPU 등과 같은 벡터 프로세서에서 많이 사용되는 방식)
최근 Pandas(v2.0 이후)나 Dask, Ray 등의 오픈소스에서 Arrow를 채택하고 있고 이를 위해 PyArrow라는 구현체를 사용하는데 Polars에서는 이것도 러스트로 개발된 구현체를 사용하여 내부에서 사용합니다. Arrow를 사용하는 경우, ArrowTable 형태로 타 오픈소스와의 호환성을 어느 정도 유지하면서 데이터를 주고받을 수 있습니다.(예: Ray Dataset과 Polars DataFrame)
import ray
import polars as pl
# Ray Dataset -> Polars DataFrame
ds = ray.data.read_parquet("data.parquet")
pl_df = pl.from_arrow(ray.get(ds.to_arrow_refs()))
# Polars DataFrame -> Ray Dataset
pl_df = pl.read_parquet("data.parquet")
ds = ray.data.from_arrow(pl_df.to_arrow())2.1.3. IO 기능
로컬 파일, 클라우드 스토리지, 데이터베이스 등 다양한 데이터 스토리지 계층을 지원하고 성능 또한 매우 우수합니다. 기본적으로 CSV, JSON, Parquet, Avro 등 다양한 포맷에 대한 읽기/쓰기를 지원하고 파일을 읽을 때도 별표(asterisk, *)와 같은 Globs Pattern을 활용해서 여러 파일을 읽어올 수 있어서 매우 편리합니다. 실무에서는 데이터베이스나 Trino와 같은 쿼리 엔진에 쿼리를 제출하고 그 결과로 polars.DataFrame을 반환하는 read_database() 기능도 자주 사용하고 있습니다.
import polars as pl
# data-1.parquet, data-2.parquet 등과 같은 파일 한 번에 읽기
df = pl.read_parquet("docs/data/data-*.parquet")
df.write_parquet("docs/data/total_data.parquet")
# Cloud Storage에서 데이터 읽어오기
df = pl.read_parquet("s3://bucket/*.parquet")
# read from DB
df = pl.read_database_uri(
query="SELECT * FROM foo",
uri="postgresql://username:password@server:port/database"
)
df = pl.read_database(
query="SELECT * FROM test_data",
connection=user_conn,
schema_overrides={"normalised_score": pl.UInt8},
) read_* 와 같은 함수 대신 scan_* 이라는 함수를 사용하게 되면 Lazy API를 위한 LazyFrame으로 반환되어 이를 활용하여 바로 Lazy 연산을 수행할 수 있습니다. 이렇게 되면 즉각적으로 모든 데이터를 메모리에 올리는 것이 아닌 최적화를 한 후 실제 연산을 수행하여 더 효율적으로 처리할 수 있습니다.
테스트해 본 IO 성능 실험을 간단하게 공유해드리면 아래와 같습니다.
- 710MB parquet file (7,373,092 rows * 64 columns) 읽기 실험
- Polars의 read_parquet: 4s 554ms
- Pandas의 read_parquet: 33s 916ms
2.1.4. Lazy API와 쿼리 최적화
Polars의 Lazy API는 즉시 연산을 수행하지 않고, Query Plan이라고 하는 연산 계획을 수립한 후 최적의 시점에 연산을 실행하는 지연 평가(Lazy Evaluation) 방식입니다. 이는 불필요한 중간 연산을 줄여주고 필터링과 pushdown 등의 최적화 기술을 사용하여 필요한 데이터만 읽어와서 처리하기 때문에 메모리 소모와 연산 복잡도를 줄여줍니다. Polars에서는 polars.DataFrame 말고 polars.LazyFrame이 있는데 이는 즉각적으로 연산을 하는 게 아니라 쿼리 플랜만 담아두고 있다가 값이 필요할 때, 즉 구체화(materialize)할 때 collect() 함수를 호출하여 연산하는 방식입니다.
아래 코드와 실험 결과를 통해 즉시 연산과 지연 연산의 차이를 보여드리겠습니다. 아래 코드는 점심/저녁 주문 피크 시간대(11시 ~ 14시, 18시 ~ 21시)에 배달 거리가 2KM 이상이고, 지역별로 배달예상시간을 평균 내는 코드입니다.
# Eager API
df = pl.read_parquet("predicted_data-1.parquet")
result = (df
.filter(pl.col("distance") >= 2 & pl.col("created_hour").is_in([11, 12, 13, 18, 19, 20]))
.group_by("pickup_zone_id").agg(
pl.mean("delivery_time").alias("avg_delivery_time")
))
# Lazy API (scan_parquet 함수 사용과 마지막 collect 함수 호출이 유일한 차이)
df = pl.scan_parquet("predicted_data-1.parquet")
result = (df
.filter(pl.col("distance") >= 2 & pl.col("created_hour").is_in([11, 12, 13, 18, 19, 20]))
.group_by("pickup_zone_id").agg(
pl.mean("delivery_time").alias("avg_delivery_time")
)).collect()성능 비교
predicted_data-1.parquet는 약 1.8GB의 parquet 파일(70,765,275 rows * 26 columns)입니다.
| 메모리 소모(peak) | 실행 시간 | |
|---|---|---|
| Eager API | 17.84 GB | 9.07 초 |
| Lazy API | 5.9 GB | 1.009 초 |
같은 Polars로 처리했지만, 어떤 방식으로 처리했는지에 따라 엄청난 차이가 나는 것을 확인할 수 있습니다. 이와 같이 큰 차이가 나는 것은 지연 연산 시에 내부적으로 여러 최적화를 한다고 말씀드렸습니다. 많은 최적화를 수행하고 있지만, 이 글에서는 푸시다운 최적화만 짧게 다뤄보도록 하겠습니다.
푸시다운(pushdown)이란?
쿼리 연산을 스토리지 계층으로 한 단계 내려서 데이터 로드 비용을 최소화하는 기술입니다. 푸시다운에 대한 정책과 구현은 솔루션이나 오픈소스마다 다르지만, 해당 개념은 최적화를 위해 대부분 채택하고 있습니다.
Polars에서는 아래 세 가지 푸시다운을 수행하여 최적화를 수행합니다.
- Predicate pushdown(조건자 푸시다운): 필터를 적용해 요청한 데이터만 읽는 방식(filter pushdown이라고도 함)
- Project pushdown: 필요한 열만 읽는 방식
- Slice pushdown: 필요한 슬라이스(일부 행)만 읽는 방식
자세한 최적화 정보는 Polars user guide의 Optimizations 자료를 참고해 주세요.
2.1.5. Out of core 방식(Streaming API)
Polars에서는 streaming이라는 기능을 활용해서 out of core 방식으로 연산을 수행할 수 있습니다. 여기서 out of core 방식이란 external memory 알고리즘이라고도 하는데, 메모리에 담기 너무 큰 데이터를 처리할 때 디스크나 네트워크 등을 통해 일정 단위로 데이터를 가져와서 처리하는 방식을 말합니다. 즉, 한 번에 모든 데이터를 메모리에 올리는 것이 아니라 일정 단위로 데이터를 자르고 그 조각을 가져와서 처리하고 이를 반복하는 것이죠. 아래 그림을 보면 이해가 쉬울 것 같습니다.

out of core의 동작 방식: 하나의 데이터셋을 배치 단위로 나누어서 작업
이 streaming 기능의 사용법은 매우 간단합니다. 아래 코드는 위에서 Lazy API와 Eager API를 비교할 때 사용한 로직입니다. 거의 같은 코드이지만 streaming 기능의 극적인 차이를 확인하기 위해 처리하는 데이터의 양을 늘렸습니다. 이전 실험에서는 1.8GB 파일이었는데 여기서는 다수의 parquet 파일을 가지고 테스트를 할 예정이며 용량의 총합은 8.8GB입니다.
# scan_parquet에서 *를 사용하여 같은 패턴의 파일을 모두 읽어오도록 변경
df = pl.scan_parquet("predicted_data-*.parquet")
result = (df
.filter(pl.col("distance") >= 2 & pl.col("created_hour").is_in([11, 12, 13, 18, 19, 20]))
.group_by("pickup_zone_id").agg(
pl.mean("delivery_time").alias("avg_delivery_time")
)).collect(streaming=True)streaming API를 사용한다고 했는데 무슨 차인지 모르시겠다고요? 바로 collect 함수 내에서 streaming=True 옵션만 추가했습니다. 정말 간단하죠!
즉, 일반적인 Lazy 연산으로 개발하시고 마지막 구체화 시점에 streaming 옵션만 추가해 주면 됩니다.
위 연산은 Pandas로는 애초에 OOM으로 불가능하며 Polars 기본 연산으로도 수십 기가의 메모리를 소모합니다. 하지만 streaming 기능을 이용하면 아래와 같은 수치가 나옵니다.
| 메모리 소모(peak) | 실행 시간 | |
|---|---|---|
| Streaming API | 3.71 GB | 6.835 초 |
5배 가까이 큰 데이터를 처리했는데 피크 메모리는 더 적고 실행 시간도 큰 차이가 나지 않습니다.
Polars의 발표 자료를 보면 이 기능을 활용하면 200GB 정도의 데이터도 개인 랩톱 환경에서 처리할 수 있다고 합니다. 잘 활용한다면 매우 유용할 것 같습니다.
Polars의 성능에 대한 자료는 많지만 최근 업데이트된 벤치마킹 자료를 참고해보시면 도움이 될 것 같습니다.(https://pola.rs/posts/benchmarks/)
2.2. 사용성 측면에서의 장점: 왜 편리한가?
2.2.1. SQL과 비슷한 구조
Polars는 SQL과 비슷한 표현식과 직관적인 문법을 가지고 있기 때문에 배우기 쉽고 가독성도 좋은 편입니다.

2.2.2. 칼럼 선택 시 편리함
데이터를 분석하거나 피처 엔지니어링을 할 때 원하는 칼럼을 선택해야 하는 경우가 많습니다. 그럴 때 칼럼 이름을 리스트로 받아오거나 타입을 받아와서 필터링하기도 하는데 Polars에서는 타입에 따라 선택할 수도 있고 정규식을 활용할 수도 있습니다. 학습이나 추론을 할 때 인코딩된 칼럼을 굉장히 자주 다루는데 아래 코드에서처럼 정규식으로 처리할 때 무척 편리했었습니다. 테이블 생성을 위해 데이터 타입을 일괄 변경할 때 정수형이나 숫자형 열을 일괄 선택하는 기능도 자주 사용했었습니다.
자세한 사례는 아래에서 코드와 주석으로 설명해놓겠습니다.
import polars as pl
# 모든 칼럼 선택
selected_df = pl_df.select(pl.col("*"))
selected_df = pl_df.select(pl.all())
pl_df.select(pl.col(pl.Int64)) # 데이터 타입과 타입의 크기에 따라 선택 가능
import polars.selectors as cs
# int64, int32인지 구분하지 않고 정수형 칼럼을 선택하고 싶을 때
pl_out_with_int = pl_df.select(cs.integer())
# int64, int16, float32인지 구분하지 않고 실수형 칼럼과 문자열 칼럼을 선택하고 싶을 때
pl_out_with_num = pl_df.select(cs.numeric(), cs.string())
# 칼럼 이름에 정규식을 적용해서 선택(_encoded로 끝나는 칼럼)
pl_df.select(pl.col("^.*_encoded$"))
# 일부 열만 제외
pl_df.select(pl.exclude("name", "private_number"))2.2.3. 시계열 연산
Polars는 시계열 지원이 좋은 편인데 시간과 관련된 여러 타입을 지원하며, 리샘플링이나 시간 윈도우 기반 그룹화 등의 기능도 제공합니다. 그리고 일치하는 키가 존재하지 않을 때 가장 가까운 값을 기준으로 join하는 기능인 asof join도 지원해서 실무에서 자주 사용하고 있습니다. 아래는 시계열 연산에 관련된 간단한 예시를 준비했습니다. 코드와 함께 살펴보시면서 이해하시면 될 것 같습니다.
upsample 예시
아래 코드는 30분 단위로 데이터를 생성하고, 이를 15분 간격으로 업샘플링하기 위해 중간 보간법을 사용하는 코드입니다. 업샘플링을 했을 때 빈 값을 fill_null로 채우게 됩니다.
import polars as pl
from datetime import datetime
df = pl.DataFrame(
{
"time": pl.datetime_range(
start=datetime(2024, 7, 23),
end=datetime(2024, 7, 23, 2),
interval="30m",
eager=True,
),
"name": ["a", "a", "a", "b", "b"],
"value": [1.0, 2.0, 3.0, 4.0, 5.0],
}
)
print(df)
result = (
df.upsample(time_column="time", every="15m")
.interpolate()
.fill_null(strategy="forward")
)
print(result)

업샘플링 결과: 15분 단위로 값이 채워진 결과
group_by_dynamic 예시
group_by_dynamic을 사용하게 되면 고정 윈도우 연산이나 롤링 윈도우 연산도 가능합니다. 아래 코드는 불규칙한 시간 단위로 생성된 데이터를 10분 윈도우로 평균과 합을 구하는 코드입니다.
import polars as pl
# 데이터프레임 생성
df = pl.DataFrame(
{
"timestamp": [
"2024-07-23 00:00:00", "2024-07-23 00:01:00", "2024-07-23 00:02:00",
"2024-07-23 00:10:00", "2024-07-23 00:12:00", "2024-07-23 00:20:00"
],
"value": [10, 20, 30, 40, 50, 60]
}
)
# timestamp 열을 날짜시간 형식으로 변환
df = df.with_columns(pl.col("timestamp").str.strptime(pl.Datetime, "%Y-%m-%d %H:%M:%S"))
print(df)
# 데이터프레임을 timestamp 열 기준으로 정렬
df = df.sort("timestamp")
# 10분 윈도우로 데이터프레임을 그룹화하고 각 그룹별로 평균과 합을 계산
result = (df
.group_by_dynamic(index_column="timestamp", every="10m")
.agg([
pl.col("value").mean().alias("mean_values"),
pl.col("value").sum().alias("sum_values"),
])
)
print(result)

10분 윈도우로 그룹화하여 연산
2.2.4. SQL 직접 사용
최근 DuckDB와 같은 도구에서 로컬 및 클라우드 스토리지 내 파일이나 DataFrame 객체에 직접 SQL 쿼리를 할 수 있도록 지원하는데, Polars 역시 비슷한 기능을 제공합니다. Python 기반으로 연산하는게 익숙치 않다면 SQL을 사용할 수도 있고, 이 기능을 사용하면 쿼리 최적화가 수행되기 때문에 성능을 높일 수도 있습니다.
pl_df = pl.DataFrame({
"VendorID": ["A", "A", "B", "B", "B"],
"passenger_count": [1, 1, 2, 2, 1],
"trip_distance": [0.95, 1.2, 2.51, 2.9, 1.53],
"payment_type": ["card", "card", "cash", "cash", "card"],
"total_amount": [14.3, 16.9, 34.6, 27.8, 15.2]
})
# 위에서 만든 DataFrame에 my_table이라는 이름을 붙여준다.
ctx = pl.SQLContext(my_table=pl_df, eager_execution=True) # eager_execution은 lazy evaluation을 끄고 즉시 결과를 보겠다는 것
result = ctx.execute("SELECT * FROM my_table WHERE trip_distance > 2")
print(result)3. 실무 적용 사례 소개
3.1. 배달예상시간 학습 파이프라인 개선
수천만 행의 학습 데이터(parquet 파일)를 가져와서 읽고 이를 전처리하는 부분이 학습 파이프라인에 포함되어 있었습니다. 기존에도 성능을 고려하여 Dask를 적용해서 처리했었는데 이 부분을 Polars로 변경했고, Dask 대비 실행시간은 80% 수준으로 단축하고 메모리는 40% 수준으로 감소시켰습니다.
3.2. 사용자 정의 함수 적용시 개선
Pandas에서는 apply를 활용해 사용자 정의 함수(User Defined Function, UDF)를 행 단위로 수행합니다. Polars도 같은 기능을 지원합니다. 사용자 정의 함수를 적용하여 변환하는 부분을 Polars로 변경하고 나서 성능 개선을 체감할 수 있었습니다. 물론 Polars도 Python UDF를 적용할 때는 자체 지원 함수를 사용할 때보다 성능이 현저하게 떨어지게 되고 이에 대한 경고 또한 공식 문서에 포함되어 있습니다. 왜냐하면 UDF 실행 때문에 러스트 코어의 장점이나 벡터화 연산의 장점을 많이 잃어버리기 때문이죠. 하지만 Pandas 대비 훌륭한 실행시간 개선을 보여줬습니다.
팀에서 데이터 전처리를 할 때 위/경도 데이터를 가져와서 H3 index로 변환하는 부분이 있습니다. 이 부분을 아래와 같이 Polars 코드로 변경했더니 기존 Pandas로 24.3초 정도 걸리던 연산이 5.87초로 단축되었습니다. 거의 5배 가량 빨라진 것이죠.
h3idx_p9_null = h3idx_p9_null.with_columns(
pl.Series(
h3idx_p9_null.map_rows(
lambda x: h3.geo_to_h3(
x[shop_loc_pnt_lat_idx], x[shop_loc_pnt_lon_idx], 9
)
)
).alias("h3idx_p9"),
)중요하고 많이 사용하는 UDF의 경우 함수 자체를 러스트로 개발하고 이를 파이썬 코드에서 호출해서 사용하면 성능을 높일 수 있으니 참고해 주세요.
3.3. 준실시간 추론 파이프라인
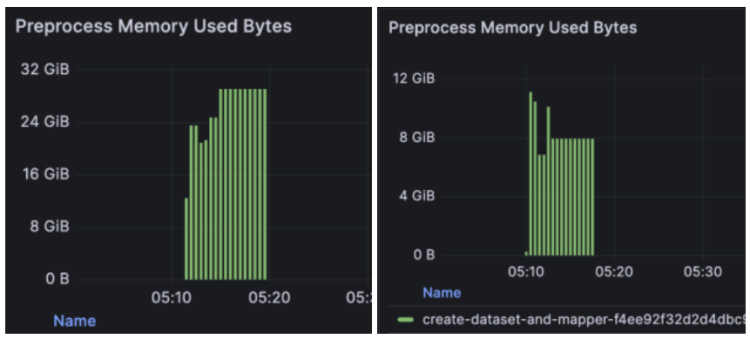
저희는 고객에게 더 정확한 시간을 안내하기 위해 준실시간 추론을 하게 됩니다. 배달예상시간의 경우, 사용자가 지면을 조회하면서 여러 가게에 대한 시간을 확인하기 때문에 모든 케이스를 고려하여 미리 피처를 생성해 놓고 준실시간 추론 시점에 피처를 가져와 메모리에 올리고 간단한 처리를 하여 모델에 넣게 됩니다. 그리고 이 모델의 추론 결과를 비즈니스 로직과 전시를 담당하는 쪽에 이벤트로 만들어 전달해야 하죠. 이 과정에서도 Polars를 적용하여 눈에 띄는 성능 효율화를 가져올 수 있었습니다. 이때 수행한 작업은 파일 읽기, group_by 및 aggregation 작업, 이벤트 형태로 변환하기 위한 UDF 적용 작업이었습니다. 매번 실행할 때마다 24GB 정도의 메모리를 소모하던 것을 대략 40% 이하로 줄여서 10GB 정도로 감소한 것을 보실 수 있습니다. 이를 통해 k8s pod 사이즈를 줄여서 비용효율을 높일 수 있었습니다.

4. 결론
Polars를 선택하기까지의 과정과 이 기술의 장점을 살펴보았습니다. 이 라이브러리가 은총알은 아니지만 적절한 데이터 크기를 가진 환경에선 효율적인 도구가 될 것입니다. Pandas로 분석을 돌리고 기약 없이 기다리거나 주피터 노트북이 메모리 초과로 죽어서 고생하셨던 데이터 분석가나 과학자분들에게도 좋은 도구가 될 것입니다.
저희 팀에서는 대용량 데이터나 증가세가 뚜렷한 데이터는 Spark로 처리하고 그 이외 로직은 Polars로 처리하면서 성능과 생산성, 비용효율성을 챙기고 있습니다. 앞으로도 생산성과 비용효율성을 고려한 데이터 엔지니어링과 ML 서빙을 위해 다양한 기술을 조사하고 적용해보려고 합니다. 좋은 결과가 있어서 또 공유드릴 수 있었으면 좋겠습니다.
