로봇을 위한 MLOps #2: 엣지 파이프라인의 구성
"로봇을 위한 MLOps #1: Edge device와 K3s, Airflow" 편에서는 로봇을 위한 머신러닝 모델을 개발하는 과정을 소개하고 이를 위해 MLOps 인프라스트럭처를 어떻게 구축하였는지를 설명하였습니다. GPU workstation 및 엣지 디바이스(edge device)들에 워커(worker) 노드를 설치하고 Kubernetes 및 Airflow를 사용해 이들 노드에서 전체 파이프라인을 실행하는 방법을 살펴보았습니다.
이번 편에서는 엣지 디바이스에서 작동하는 엣지 파이프라인(edge pipeline)의 구성, 그리고 이 파이프라인에서 사용한 도구들과 특징을 소개하겠습니다. 특히 다중 모델을 동시에 추론할 때의 성능을 평가하기 위하여 자체 개발한 도구인 Trt-Infersight를 이 글에서 처음으로 소개하고자 합니다.
엣지 파이프라인의 필요성
자율주행 로봇의 시스템 구성
로봇, 자동차, 드론 등에 쓰이는 자율주행 기술은 이제 우리의 일상에서 흔히 접할 수 있게 되었습니다. 이러한 장비들에는 우리가 사용하는 컴퓨터와 유사한 기능을 하는 하드웨어가 탑재되어 있습니다. 이 하드웨어는 일반적으로 Arm 아키텍처를 기반으로 하는 CPU를 사용합니다. Arm 기반 CPU는 낮은 전력 소모 덕분에 발열도 적고 배터리도 적게 사용한다는 장점이 있기 때문이죠. 또한, 이 하드웨어는 보통 GPU를 포함하고 있어, 그래픽 디스플레이 처리뿐만 아니라 딥러닝 모델의 추론, 이미지 및 비디오 처리 등 고성능의 병렬 연산을 요구하는 작업을 수행할 수 있습니다.

우리가 개발하는 자율주행 로봇 ‘딜리(Dilly)’에도 CPU, GPU뿐만 아니라 DLA(Deep Learning Accelerator), VIC(Video Image Compositor), HW encoder/decoder 등과 함께 여러 센서 인터페이스가 패키징된 NVIDIA Jetson 플랫폼을 기반으로 하는 임베디드 보드가 내장되어 있습니다. 임베디드 보드에 GPU, IMU, LiDAR, 카메라 등 다양한 센서들을 로봇에 연결할 수 있고, 자율주행과 관련된 복잡한 연산들이 로봇에서 효율적으로 수행될 수 있습니다. 이와 같은 임베디드 보드가 우리의 엣지 디바이스가 됩니다.
엣지 디바이스에서의 AI 연산이 필요한 이유
최근 on-device AI라는 용어를 많이 들어보셨을 텐데요. 이는 클라우드나 기타 서버에 의존하지 않고 엣지 디바이스 자체에서 AI 연산을 수행하는 것을 말합니다. 이를 위해서는 디바이스 내부의 연산 자원만을 활용하여 많은 연산을 하는 기술이 필요합니다.
이러한 on-device AI 기술은 자율주행 로봇과 자율주행 자동차에 필수적입니다.
첫째, 자율주행 기계들은 실제 주행 환경에서 일어나는 일들에 대해 실시간으로 기민하게 반응해야 하기 때문입니다. 연산을 할 때마다 서버와의 무선 통신이 필요하다면 시간 지연이 생길 것입니다.
둘째, 주행 중 인터넷 연결이나 기타 무선 통신 연결이 잠시 단절되는 일이 종종 발생할 텐데, 그런 상황에서도 자율주행 기계는 멈추지 않고 작동해야 하기 때문입니다.
셋째, 민감한 개인 정보를 보호하는 데에도 on-device AI가 유리하기 때문입니다.
엣지 파이프라인의 목적
엣지 디바이스에는 비용, 전력, 무게, 부피 등에 대한 제약이 있기 때문에, 시스템 자원과 성능이 한정된 하드웨어를 사용합니다. 사용할 하드웨어를 결정하고 전체 시스템을 설계하고 나면, 하드웨어를 확장하거나 변경하기도 어렵습니다.
⭐️ 따라서 주어진 자원 내에서 단위 시간당 연산 처리량을 높이고, 각 모듈의 데이터 처리 지연 시간을 최소화하는 것이 매우 중요합니다.
엣지 파이프라인이란, Airflow가 작동시키는 DAG 중 엣지 디바이스에서 동작하는 부분을 말합니다. 이러한 엣지 파이프라인은, 한정된 시스템 자원 하에서 다수의 머신러닝 모델들이 정해진 시간 안에 문제없이 동작하는지를 검토하기 위해 필요합니다.
우리의 엣지 파이프라인은 여러 도구를 활용해서 구성되었습니다. 이 도구들의 역할을 설명하기 전에, 필요한 배경 지식을 먼저 소개하고자 합니다.
이전 편인 "로봇을 위한 MLOps #1: Edge device와 K3s, Airflow"에서 설명한 바와 같이, 충분한 GPU 자원을 가진 학습 서버에서 모델 학습, PTQ(Post Training Quantization), QAT(Quantization Aware Training) 등의 과정이 수행되고 그 결과로 ONNX 포맷의 파일이 생성됩니다.
ONNX는 Open Neural Network Exchange의 약자로, TensorFlow, PyTorch 등 다양한 딥러닝 프레임워크 중 어느 것으로 모델을 생성하더라도 다른 프레임워크에서 이를 해석할 수 있게 한 공유 포맷입니다.
이 ONNX 포맷의 모델은 엣지 디바이스에서 NVIDIA 사가 제공하는 도구인 TensorRT를 사용하여, NVIDIA의 하드웨어에서 쓸 수 있도록 변환됩니다. 그 결과 엣지 디바이스의 GPU 또는 DLA에서 이 모델의 추론(inference)을 수행하는 런타임 엔진이 만들어집니다.
TensorRT란
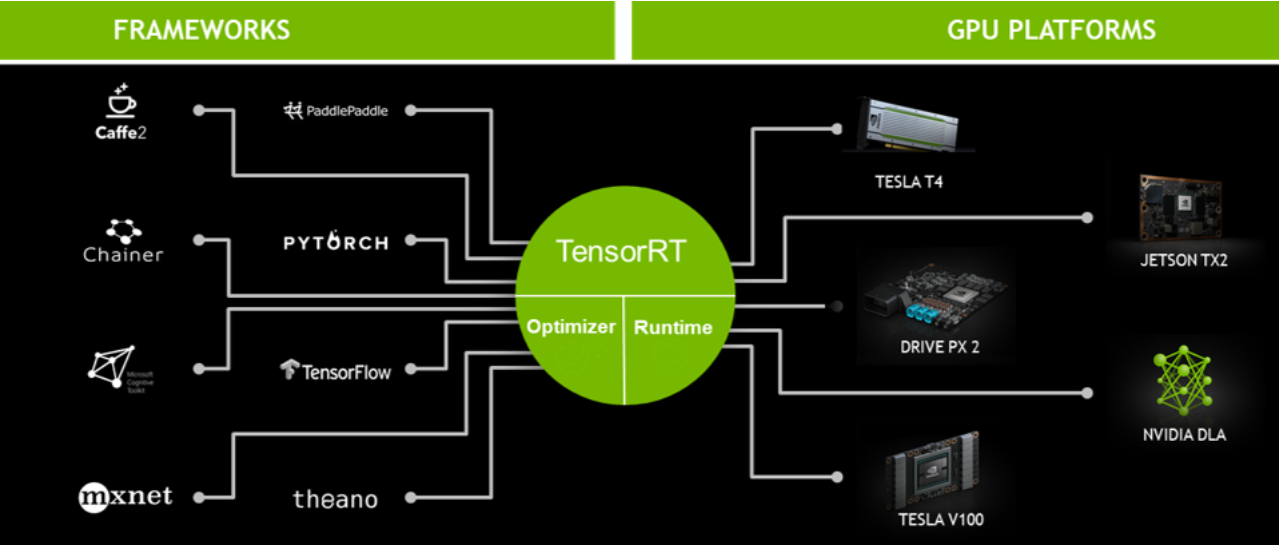
출처: NVIDIA 기술 블로그
TensorRT는 NVIDIA 사에서 제공하는 software development kit(SDK)입니다. 머신러닝 모델이 NVIDIA 사의 GPU 플랫폼에서 효율적으로 실행될 수 있도록 만드는 데에 필요한 도구입니다.
이는 TensorFlow, PyTorch, MXNet, Caffe 등 다양한 딥러닝 프레임워크들과 호환됩니다.
TensorRT를 사용하는 개발 워크플로는 아래와 같습니다.
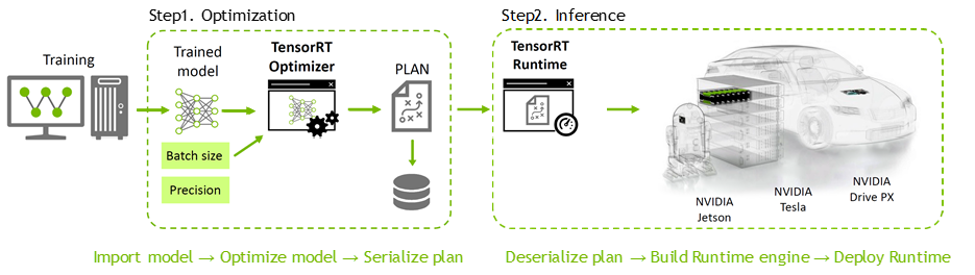
출처: NVIDIA 기술 블로그
Step1. Optimization
- 학습된 머신러닝 모델 파일을 읽어서, 탐색할 수 있는 컨텍스트(context)로 변환합니다.
- TensorRT Optimizer를 사용하여, 컨텍스트를 디바이스의 accelerator(GPU, DLA)에서 동작될 수 있도록 최적화합니다.
- 최적화가 완료된 모델은 plan이라는 엔진으로 변환됩니다.
Step2. Inference
- plan을 역직렬화(deserialization)합니다.
- TensorRT Runtime을 이용하여 plan을 실행합니다.
NVIDIA TensorRT는 C++과 Python 언어를 위한 API를 제공합니다. 엔진으로 변환될 코드를 이 API를 사용하여 직접 구현할 수 있고, 이 API를 기반으로 구현된 여러 오픈소스 도구가 제공됩니다.
이러한 이미 공개된 도구들을 이용하면, 엣지 디바이스에서 동작하는 추론 모델을 비교적 손쉽게 생성할 수 있습니다.
NVIDIA 도구들 소개
NVIDIA에서 제공하는 개발 도구인 Trtexec, TREx, Nsight Systems에 대해 간단하게 소개해 드리고자 합니다.
Trtexec
Trtexec는 TensorRT를 가장 쉽고 편하게 사용할 수 있는 CLI(command line interface)입니다. 이 도구를 사용하면, 별도의 애플리케이션을 개발하지 않고도 모델의 변환과 추론 성능을 손쉽게 평가할 수 있습니다.
Trtexec의 Git 리포지토리에 있는 README 파일에 소개된 이 도구의 핵심 기능은, 다음 두 가지로 요약됩니다.
1. 디바이스에 최적화된 plan을 생성
트레이닝된 모델을 타깃이 되는 엣지 디바이스에 최적화한 엔진 파일을 생성할 수 있습니다. 이 엔진을 plan이라고 부릅니다. 이렇게 생성된 엔진 파일은 추론 작업을 수행하고자 하는 다른 애플리케이션에 통합하여 사용할 수 있습니다.
2. 생성된 plan의 추론 성능을 간단히 벤치마크
빌드로 생성된 plan, 또는 입력 값으로 지정된 plan을 사용하여 네트워크의 추론 성능을 테스트할 수 있습니다. 사용자에게 여러 추론 관련 옵션이 제공되고, 이를 통해 입력과 출력, 성능 측정을 위한 반복 횟수, 정밀도 등을 설정할 수 있어, 네트워크가 실제 환경에서 어떻게 동작할지 미리 확인할 수 있습니다.
이처럼 Trtexec를 이용하면 복잡한 개발 과정을 거치지 않고도 신속하게 추론 성능을 테스트하고 최적화할 수 있습니다. TensorRT를 처음 접하는 분들이나 변환된 단일 모델의 성능을 빠르게 확인하고자 하는 분들에게 유용할 것입니다.
Trtexec가 지원하는 다양한 옵션을 사용하는 것만으로도, C++이나 Python을 통해 구현할 수 있는 대부분의 모델 변환과 추론을 수행할 수 있습니다.
trtexec <model option> <build option> <inference option> <reporting option> <system option>모델 옵션
--uff, --onnx, --model, --deploy를 사용하여 변환 전 input 모델 파일의 경로를 전달합니다.
빌드 옵션
TensorRT C++ Builder를 사용하여 plan을 생성할 때 사용자 설정 값을 전달할 수 있습니다. 설정 값들을 전달하지 않는 경우에도, TensorRT는 기본값을 사용하거나 모델을 탐색하여 input shape, output shape, 레이어(layer) 포맷 등을 자동으로 추출하여 사용합니다.
이때 --fp16 , --int8 등의 옵션을 사용하여 레이어의 정밀도를 낮춤으로써, 모델 추론에 소요되는 시간을 줄일 수 있습니다. --layerPrecisions를 사용하면 특정 레이어의 정밀도를 지정할 수도 있습니다. 예를 들어, 특정 레이어에 대해서만 --fp16 또는 --int8 옵션을 사용하여 정밀도를 지정할 수 있습니다. 이러한 방법으로, 모델의 일부 레이어에서는 높은 정밀도를 유지하면서도 다른 레이어는 낮은 정밀도로 처리하여 성능을 최적화할 수 있습니다.
--maxBatch, --minShapes, --optShapes, --maxShapes와 같은 옵션들을 사용하면 모델의 입력 형태 및 배치 크기를 지정할 수 있습니다. 이러한 옵션들은 input shape가 바뀔 수 있는 경우에도 같은 모델을 테스트하거나 사용할 수 있는 유연성을 제공합니다.
--saveEngine을 사용하면 변환된 plan을 파일로 저장할 수 있으며, --loadEngine 옵션으로는 빌드 과정에서 소요되는 시간을 줄이고 추론 동작을 즉시 테스트해볼 수 있습니다. 한편 --buildOnly 옵션을 사용하여 추론 단계를 건너뛰고 빌드만 수행할 수도 있습니다.
옵션 --profilingVerbosity는 엔진을 빌드하는 과정에서 엔진 자체, 각 레이어, 그리고 바인딩에 대한 정보들을 얼마나 자세히 표시할지를 정합니다. 이 옵션을 detailed로 설정하여 verbosity 단계를 높이면, 리포팅 과정에서 결과물이 더 상세하게 보이게 되어, plan의 구조와 특징을 더 자세히 파악할 수 있습니다.
추론 옵션
--iterations, --duration, --warmUp 등으로 추론 수행 방식과 반복 횟수를 조정할 수 있습니다. 예를 들어, --iterations=100 옵션을 사용하여 100번의 추론을 반복 수행하고, --warmUp=200 옵션을 사용하여 200ms 동안에 모델을 warm-up 할 수 있습니다. 이는 모델의 성능을 초기화가 진행되는 warm-up 이후에 일관된 방법으로 측정할 수 있습니다
리포팅 옵션
추론 결과와 성능 데이터를 기록하고 분석할 때 사용하는 옵션들도 있습니다.
--exportTimes 옵션을 사용하면 추론 시간 데이터를 JSON 파일로 내보낼 수 있습니다. --exportOutput, --exportProfile 옵션으로 추론 및 프로파일링(profiling) 결과를 JSON 파일로 저장할 수 있습니다. 또한 --dumpOutput, --dumpProfile, --dumpLayerInfo 등의 옵션을 사용하여 추론 결과와 각 레이어의 프로파일링 정보를 출력할 수 있습니다.
시스템 옵션
--device=N 옵션을 사용하여 특정 GPU 디바이스를 선택하거나, --useDLACore=N 옵션으로 DLA(Deep Learning Accelerator) Core를 활용할 수 있습니다. 또한, --allowGPUFallback 옵션을 사용하면 DLA가 지원하지 않는 레이어를 GPU에서 처리하도록 설정할 수 있습니다.
예제
아래는 이러한 옵션들을 활용한 Trtexec 명령어의 간단한 예시입니다.
trtexec \
--onnx=/root/ml/onnx/object_detector/model.onnx \
--noDataTransfers \
--buildOnly \
--separateProfileRun \
--saveEngine=/root/ml/tensorrt/object_detector/model.plan \
--exportTimes=/root/ml/tensorrt/object_detector/model.timing.json \
--exportProfile=/root/ml/tensorrt/object_detector/model.profile.json \
--exportLayerInfo=/root/ml/tensorrt/object_detector/model.graph.json \
--timingCacheFile=/root/ml/tensorrt/object_detector/model.timing.cache \
--plugins=/root/ml/plugins/libcustom_tensorrt_ops.so \
--profilingVerbosity=detailed \
--int8 \
--dumpProfile이처럼 Trtexec을 사용하면 모델을 NVIDIA 플랫폼에서 TensorRT를 이용해 동작하는 plan으로 변환할 수도 있고 추론을 간편하게 수행할 수도 있습니다.
TREx(trt-engine-explorer)
TREx는 Python 패키지 모듈입니다. TREx는 변환된 plan과 추론 과정에서 추출된 생성물을 분석합니다. 이 도구는 Jupyter Notebook과 함께 사용할 수 있습니다. 모델의 변환과 추론 과정에서 생성된 결과물을 입력 값으로 하여 초기 성능과 plan의 계층구조를 시각화할 때에 유용합니다. 이 도구는 TensorRT Git 리포지토리에 포함되어 있습니다.
빠르게 TREx의 동작 환경을 구성하고 TREx를 설치하는 방법은 다음과 같습니다.
git clone <https://github.com/NVIDIA/TensorRT.git>
cd TensorRT/tools/experimental/trt-engine-explorer
python3 -m pip install virtaulenv
python3 -m virtualenv env_trex
source env_trex/bin/activate
python3 -m pip install -e .앞서 말씀드린 것처럼 TREx는 Python 기반의 여러 스크립트들로 구성되어 있는데, 그 중 TensorRT를 통해 변환된 plan을 그래프로 시각화 해주는 스크립트를 유용하게 사용할 수 있습니다. 보통 .tflite, .caffemodel, .pth, .onnx 포맷의 파일들은 Netron과 같은 도구를 이용해서 input, output, 세부 레이어들의 구조를 파악할 수 있지만, TensorRT에 의해 변환된 plan에 대해서는 그러한 도구들이 시각화를 지원하지 않습니다.
따라서 아래 스크립트를 이용하면, 엔진을 간단히 시각화해 볼 수 있습니다.
import argparse
import shutil
import sys
import trex
def draw_engine(engine_json_fname: str):
plan = trex.EnginePlan(engine_json_fname)
formatter = trex.layer_type_formatter
display_regions = True
expand_layer_details = False
graph = trex.to_dot(plan,
formatter,
display_regions=display_regions,
expand_layer_details=expand_layer_details)
trex.render_dot(graph, engine_json_fname, "png")
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Draw engine graph from JSON file")
parser.add_argument("--graph", type=str, help="Path to the graph file")
args = parser.parse_args()
if args.graph is None:
parser.print_help()
sys.exit(1)
draw_engine(args.graph)
sys.exit(0)참고: NVIDIA 기술 블로그 – Exploring NVIDIA TensorRT Engines with TREx
NVIDIA Nsight Systems
NVIDIA Nsight Systems는 NVIDIA에서 제공하는 강력한 성능 분석 도구입니다. CPU와 GPU뿐만 아니라 다양한 accelerator들을 분석하여 병목(bottleneck)을 파악하고 최적화하는 데에 쓰입니다. 특히 멀티 코어 CPU와 멀티 GPU, DLA 등에서 멀티 스레드와 병렬 연산이 동작하게 되는 복잡한 애플리케이션을 이해하고 최적화할 때에 유용한 도구입니다.
Nsight Systems는 GUI와 CLI의 두 가지 방식의 유저 인터페이스 방식을 제공합니다.
GUI에서도 프로파일링을 시작하는 것이 가능하지만, GUI를 동작시킬 때 약간의 오버헤드가 있기 때문에, 프로파일링은 nsys-cli를 통해 수행하고 그에 의해 생성된 결과물을 nsys-ui에서 읽어와서 시각적 분석을 하는 것이 편리하다고 생각합니다.
설치
Nsight Systems은 다양한 OS 기반의 호스트 및 다양한 타깃 디바이스에서 프로파일링을 실행하거나 결과를 분석할 수 있습니다. 그러나 가장 간편하게 사용하는 방법은 NVIDIA Jetson Platform의 Tegra 시스템에서 NVIDIA Jetpack의 일부로 제공되는 Nsight Systems Embedded Platforms Edition을 실행하는 것입니다. 여기에는 타깃 디바이스에 사용할 수 있는 검증된 버전이 설치되어 있으므로 로컬 머신에서 이를 바로 실행할 수 있습니다.
만약 Jetpack 시스템 이미지를 최초로 설치할 때에 Nsight Systems 패키지 설치가 누락되었다면, Jetson Jetpack Repo에서 타깃에 적합한 버전의 Nsight를 설치할 수 있습니다.
Ubuntu Linux 시스템에서는 Nsight를 아래와 같은 방법으로 설치할 수 있습니다.
sudo apt-key adv --fetch-keys <https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub>
sudo add-apt-repository "deb <https://developer.download.nvidia.com/devtools/repos/ubuntu$>(source /etc/lsb-release; echo "$DISTRIB_RELEASE" | tr -d .)/$(dpkg --print-architecture)/ /"
sudo apt install nsight-systemsNsight System CLI Tool
Nsight Systems의 CLI 도구는 다양한 옵션을 제공합니다. 자세한 내용은 User Guide를 참고해 주세요. 이 중 가장 대표적으로 전체 프로파일링을 수행하는 커맨드 옵션은 profile이며 이를 통해 CPU와 GPU의 실행 타이밍, 메모리 사용량, API 호출 등의 정보를 수집하여 성능상의 병목을 파악할 수 있습니다.
아래는 Nsight Systems CLI Tool을 사용하여 프로파일링을 수행하는 스크립트입니다. 이 스크립트는 run_inference.sh라는 실행 파일을 프로파일링하고, 결과를 /root/profile.nsys-rep 라는 파일로 저장합니다.
sudo nsys profile \
--trace=cuda,osrt,nvtx,cudnn,cudla,tegra-accelerators \
--cuda-memory-usage=true \
--output=/root/profile \
--show-output=true \
--stop-on-exit=true \
--stats=false \
--force-overwrite=true \
--cpuctxsw=system-wide \
--gpuctxsw=true \
./run_inference.sh프로파일링을 할 때에는 꼭 관리자 권한으로 실행해 주어야 합니다. 그래야 시스템 전체 자원에 접근하며 프로파일링할 수 있습니다.
| 옵션 | 설명 |
|---|---|
| –trace=cuda,osrt,nvtx,cudnn,cudla,tegra-accelerators: | CUDA, OS 런타임, NVTX, cuDNN, cuDLA, Tegra 가속기 등의 트레이스를 캡처합니다. 다양한 라이브러리와 HW accelerator가 어떻게 쓰이는지 분석하기 위해 사용합니다. |
| –cuda-memory-usage=true | CUDA 메모리 사용량을 캡처합니다. GPU 메모리 사용을 분석하는 데 유용합니다. |
| –output=/root/profile | 프로파일링 결과를 /root/ 폴더에 profile 파일명으로 저장합니다. 이 파일은 나중에 분석에 쓰입니다. |
| –show-output=true | 프로파일링 실행 중 출력 내용을 화면에 표시합니다. |
| –stop-on-exit=true | 프로파일링하던 프로세스가 exit되거나 지정된 시간이 지나면, 데이터 수집을 자동으로 종료합니다. |
| –stats=false | 기본 통계를 출력하지 않습니다. (필요시 true로 변경 가능) |
| –force-overwrite | 기존 프로파일링 결과 파일을 덮어씁니다. |
| –cpuctxsw=system-wide | 시스템 전체의 CPU 컨텍스트 스위칭을 캡처합니다. |
| –gpuctxsw | GPU 컨텍스트 스위칭을 캡처합니다. |
이 스크립트를 실행하면 /root/profile.nsys-rep 파일이 생성되고 이를 Nsight Systems GUI에서 분석할 수 있습니다.
Nsight System GUI

GUI 도구에서는 위와 같이 샘플링 주기에 맞추어 측정된 시스템 자원의 timeline-view가 제공되며, 또한 여기에서는 성능을 추적하는 accelerator나 라이브러리의 API 호출 스택 및 통계를 분석할 수 있습니다. 추적하는 자원이 많을수록 프로파일링에 따른 시스템 부하가 있으므로, 프로파일링 할 때에 캡처하는 자원의 수를 최소로 하고, 필요하다면 어떤 자원들은 따로 프로파일링 하기를 권장합니다.
GUI 도구의 사용법은 이 글에서 다루지 않겠습니다. 기본 매뉴얼이나 기타 사용법을 다룬 글을 읽고 배우는 것도 중요하지만, 실제로 도구를 사용하며 결과물을 분석하다 보면 프로파일링 요령이 점점 좋아질 수 있을 것입니다.
Trt-Infersight 개발
개발 배경
Trtexec는 훌륭한 도구이지만, 다중 모델 추론을 동시에 하는 시스템의 성능을 검증할 때에는 몇 가지 한계가 있습니다. Trtexec의 성능 벤치마크는 변환된 단일 모델의 성능 프로파일링에 초점을 맞추고 있으며, 실제 센서 입력 주기에 따른 지연 시간(latency) 설정, 또는 다수 모델의 동기(synchronous) 또는 비동기(asynchronous) 추론 방식을 고려하는 옵션을 제공하지 않습니다.
자율 주행 분야에서는 카메라, 라이다, 레이더 등 여러 센서를 동시에 사용하는 것이 일반적이며, 이러한 센서들로부터 전달받은 정보를 이용해 주변 환경을 인지하는 데에 딥러닝을 사용합니다. 따라서 다양한 종류의 센서 데이터를 활용하기 위해 다수의 딥러닝 모델이 로봇에 탑재될 수 있습니다. 각 센서는 주기적으로 주변 환경을 스캔하고 엣지 디바이스 컴퓨터에 자료를 전달하며, 로봇은 센서 데이터가 전달될 때마다 적절한 딥러닝 모델의 추론을 수행해야 합니다. 결국, 여러 개의 머신러닝 모델들의 추론이 동시에 수행되어야 합니다. 엣지 디바이스에서 이 모델들이 센서 주기들에 맞추어 모두 잘 동작함을 검증할 필요가 있습니다.
또한, 프로파일링을 커스터마이즈할 수 있고, 기능을 유연하게 확장할 수 있고, 실제 자율주행과 관련된 로직들도 검증할 수 있는 도구가 필요했습니다.
이러한 요구사항들을 충족시키는 도구를, NVIDIA TensorRT C++ API를 이용하여 자체 개발하기로 하였습니다. 이렇게 해서 탄생한 것이 Trt-Infersight입니다.
주요 동작 단계 및 기능
모델 초기화
도구가 시작되는 단계에서는, 입력되는 파일에 따라 초기 설정을 수행합니다. 이 단계는 전체 프로세스의 시작으로, 사용자가 설정한 바에 따라 동작시켜야 하는 모든 모델의 인스턴스를 생성하고 초기화합니다.
모델 Deserialization 및 탐색
각 모델을 순환하며, TensorRT로 변환된 엔진을 역직렬화합니다. 그리고 역직렬화된 컨텍스트를 탐색하여, 모델이 요구하는 input 및 output을 포함한 모델의 특성을 추출합니다. Input generator는 탐색 후에 추출된 input shape 및 output shape와 포맷을 활용하여, input tensor와 output tensor를 생성합니다. 또한, 적절한 범위를 가지는 임의의 값을 input tensor에 저장합니다. 사용자가 input 파일을 제공한 경우, 파일을 통해 input tensor의 값을 생성합니다.
성능 프로파일러 생성
Trt-Infersight에서 구현된 프로파일러는 설정 파일에 포함된 평가 옵션에 따라 생성됩니다. 프로파일러는 성능 프로파일링에 필요한 기능들을 수행하고, 추론 시간을 측정하거나 시스템 성능을 수집하는 등의 작업을 수행한 후 그 결과를 report 인스턴스에 저장합니다.
추론 실행 및 스레드 관리
Trt-Infersight에서 구현된 Executor는 각 모델에 설정된 accelerator의 타입(GPU, DLA)에 따라 추론을 하는 스레드를 다르게 생성합니다. 그리고 아래에 서술하는 방식들 중 한 가지 방식으로 추론을 수행한 뒤, 모든 iteration이 완료될 때까지 대기합니다.
단일 모델의 추론만 할 때에는 비교적 간단합니다. 이 모델의 input data 주기에 따라 추론을 해야 하는 경우, 현재 iteration에서 대기하다가 다음 input data가 들어올 때 다음 iteration을 시작합니다.
모델이 2개 이상으로 늘어나게 되면, 모델들의 동작이 동기적인지 비동기적인지, input data의 주기는 어떠한지, iteration마다 대기해야 하는지 등의 설정에 따라, 아래의 [그림 5], [그림 6], [그림 7], [그림 8]과 같은 다양한 방식으로 CUDA stream들이 동작하게 됩니다.

[그림 5]에서는 두 개의 CUDA stream이 생성되며, 한 개의 모델 추론이 완료되면 다음 모델의 추론이 시작됩니다. 모든 모델들의 추론이 한 번씩 일어나면 한 iteration이 끝나게 됩니다.

[그림 6]에서는 두 개의 CUDA stream이 생성되며, 두 개의 CUDA stream에서 동시에 추론이 수행됩니다. 여러 추론 작업이 단일 GPU에서 병렬로 실행될 경우, GPU의 시간당 처리량이 제한되어 있으므로 각각의 추론 시간이 길어질 수 있습니다. 따라서 GPU, DLA가 다수 존재할 경우, 각각의 모델을 다른 accelerator에 효율적으로 배치하여 시간당 처리량을 높이기를 권장합니다.

[그림 7]에서는 두 개의 CUDA stream이 생성되어 동시에 추론되지만, 각 iteration마다 모든 추론이 완료될 때까지 대기한 후 다음 iteration으로 넘어갑니다.

[그림 8]에서는 각 모델별로 센서의 input 주기를 설정하고, 매 iteration마다 모든 모델의 센서 input 주기가 끝날 때까지 대기합니다.
Output 생성
성능 측정 결과를 저장하는 아래와 같은 파일들이 생성됩니다.
profile_report.yaml: 여러 모델의 추론이 동시에 실행될 때, 각 모델에 대해 측정된 시간, 시스템 지표(GPU 점유, CPU 점유, 온도 등) 등의 결과를 종합하여 YAML 형식으로 저장합니다.system_profile.txt:tegrastats를 사용하여 일정 주기마다 취득한 시스템 성능 데이터를 텍스트 형식으로 저장합니다.system_profile_graph.png:system_profile.txt를 기반으로, 시간에 따른 시스템 성능 변화 추이를 그래프로 저장합니다.
엣지 파이프라인의 구성
개요
지금까지 소개한 Trtexec, TREx, Nsight Systems, Trt-Infersight를 활용하여 아래와 같은 작업을 수행하는 파이프라인을 구성할 수 있습니다.
- 학습된 머신러닝 모델이 엣지 디바이스에서 추론 가능한 plan으로 변환될 수 있는지를 확인합니다. 지원되지 않는 레이어가 있는 경우, 사용자는 해당 레이어를 제거하거나 custom operation 라이브러리를 만들어야 합니다. (Trtexec)
- 여러 모델이 동작할 때 시스템 성능 요구 조건을 충족하는지를 판단할 수 있는 지표들을 추출합니다. (Trt-Infersight)
- 프로파일링 후에는, 변환된 엔진을 분석하는 데에 쓸 수 있는 자료를 제공합니다. (TREx, Nsight Systems)

이처럼, 주어진 역할을 수행하는 데 필요한 모든 task들을 정의하고, 각 task를 수행할 수 있는 도구들을 적절히 사용하여, 간단한 엣지 파이프라인을 구성할 수 있습니다.
이제부터는 실제로 Airflow DAG 형태로 구성한 엣지 파이프라인을 살펴보겠습니다.

구현
각 단계에 필요한 task들을, KubernetesPodOperator를 사용하여 정의하고 실행합니다. 아래에는 각 작업을 위한 간단한 소스 코드와 설명이 있습니다.
기본 설정
먼저 Airflow DAG의 기본 설정 값들 및 변수들을 선언합니다.
from datetime import datetime, timedelta
import json
from airflow import DAG
from airflow.providers.cncf.kubernetes.operators.kubernetes_pod import KubernetesPodOperator
from utils.common import read_json
from kubernetes.client import models as k8s
CONFIG_FILE_NAME = "model_config.json"
EDGE_NODE_NAME = "edge-node"
OUTPUT_DIR = "/root/dags/edge/output"
COPY_ONNX_FROM = "/root/dags/edge/onnx"
default_args = {
"owner": "airflow_user",
"depends_on_past": False,
"start_date": datetime(2024, 1, 1),
"email_on_failure": False,
"email_on_retry": False,
"retries": 0,
}
dag = DAG(
"edge_pipeline",
default_args=default_args,
description="Edge pipeline DAG running on Kubernetes",
schedule_interval=timedelta(days=1),
)
config = read_json("/opt/airflow/dags/config/" + CONFIG_FILE_NAME)
config_json = json.dumps(config)볼륨 및 마운트 설정
Airflow DAG에서 쓰일 Kubernetes 볼륨과 볼륨 마운트를 설정합니다.
volume = k8s.V1Volume(
name="airflow-dags-pvc",
persistent_volume_claim=k8s.V1PersistentVolumeClaimVolumeSource(
claim_name="airflow-dags-pvc"
),
)
volume_mount = k8s.V1VolumeMount(
name="airflow-dags-pvc",
mount_path="/root/dags",
sub_path=None,
read_only=False,
)
nsight_volume = k8s.V1Volume(
name="nsight-volume",
host_path={"path": "/opt/nvidia/nsight-systems"},
)
nsight_volume_mount = k8s.V1VolumeMount(
name="nsight-volume",
mount_path="/root/nsight-systems",
read_only=False,
)
tegra_volume = k8s.V1Volume(
name="tegra-volume",
host_path={"path": "/usr/bin"},
)
tegra_volume_mount = k8s.V1VolumeMount(
name="tegra-volume",
mount_path="/root/bin",
read_only=False,
)노드 어피니티 설정
작업이 엣지 디바이스에서 실행되도록 노드 어피니티를 설정합니다.
edge_affinity = {
"nodeAffinity": {
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
"key": "kubernetes.io/hostname",
"operator": "In",
"values": [EDGE_NODE_NAME],
}
]
}
]
}
}
}Task 정의
각 작업을 KubernetesPodOperator를 사용하여 정의합니다.
make_output_dir_task = KubernetesPodOperator(
namespace="airflow",
image="myregistry.com/myimage/ml_pipeline:0.0.0",
cmds=["python3"],
arguments=[
"env_setup/make_output_dir.py",
"--output_dir", OUTPUT_DIR,
"--ts", "{{ ts_nodash }}",
"-use_env_vars"
],
env_vars=[{"name": "CONFIG_JSON", "value": config_json}],
name="make_output_dir_task",
task_id="make_output_dir",
volumes=[volume],
volume_mounts=[volume_mount],
get_logs=True,
dag=dag,
affinity=edge_affinity,
is_delete_operator_pod=True,
image_pull_policy="Never",
startup_timeout_seconds=300,
)
make_onnx_dir = KubernetesPodOperator(
namespace="airflow",
image="myregistry.com/myimage/ml_pipeline:0.0.0",
cmds=["python3"],
arguments=[
"env_setup/make_onnx_dir.py",
"--output_dir", OUTPUT_DIR,
"--ts", "{{ ts_nodash }}",
"--copy_onnx_from", COPY_ONNX_FROM,
],
name="make_onnx_dir",
task_id="make_onnx_dir",
volumes=[volume],
volume_mounts=[volume_mount],
get_logs=True,
dag=dag,
affinity=edge_affinity,
is_delete_operator_pod=True,
)
build_trt_engine_task = KubernetesPodOperator(
namespace="airflow",
image="myregistry.com/myimage/ml_pipeline:0.0.0",
cmds=["python3"],
arguments=[
"tensorrt_builder/build_trt_engine.py",
"--output_dir", OUTPUT_DIR,
"--ts", "{{ ts_nodash }}",
],
name="build_trt_engine_task",
task_id="build_trt_engine",
volumes=[volume],
volume_mounts=[volume_mount],
get_logs=True,
dag=dag,
affinity=edge_affinity,
is_delete_operator_pod=True,
)
run_trt_infersight_task = KubernetesPodOperator(
namespace="airflow",
image="myregistry.com/myimage/ml_pipeline:0.0.0",
cmds=["python3"],
arguments=[
"tensorrt_profiler/run_trt_infersight.py",
"--output_dir", OUTPUT_DIR,
"--ts", "{{ ts_nodash }}",
],
name="run_trt_infersight_task",
task_id="run_trt_infersight",
volumes=[volume, nsight_volume, tegra_volume],
volume_mounts=[volume_mount, nsight_volume_mount, tegra_volume_mount],
get_logs=True,
dag=dag,
affinity=edge_affinity,
is_delete_operator_pod=True,
)
run_trex_task = KubernetesPodOperator(
namespace="airflow",
image="myregistry.com/myimage/ml_pipeline:0.0.0",
cmds=["python3"],
arguments=[
"tensorrt_profiler/run_trex.py",
"--output_dir", OUTPUT_DIR,
"--ts", "{{ ts_nodash }}",
],
name="run_trex_task",
task_id="run_trex",
volumes=[volume],
volume_mounts=[volume_mount],
get_logs=True,
dag=dag,
affinity=edge_affinity,
is_delete_operator_pod=True,
)Task 순서 설정
마지막으로, 정의한 task들이 실행될 순서를 설정합니다.
make_output_dir_task >> make_onnx_dir >> build_trt_engine_task >> run_trt_infersight_task >> run_trex_task
결론
앞에서 설명한 코드로 Airflow DAG를 구성하여, 엣지 디바이스에서 다중 모델의 추론과 프로파일링을 수행하는 자동화된 파이프라인을 만들 수 있습니다. 각 작업은 KubernetesPodOperator를 사용하여 정의되며, Kubernetes 클러스터에서 실행됩니다.
더 나아가, GPU 서버에서 모델을 학습시키는 학습 파이프라인과 이 엣지 파이프라인을 연결하면 모델의 학습, 배포, 검증 등이 모두 자동으로 수행되는 MLOps 시스템을 구성할 수 있습니다.
글을 마치며
이 글에서는 자율주행 로봇을 위한 머신러닝 모델 개발을 자동화하고 개발된 모델들을 검증하는 방법들을 가볍게 소개하였습니다
앞으로도 다양한 머신러닝 모델들이 ‘딜리(Dilly)’ 안에서 잘 동작하도록 기술 개발에 힘쓰겠습니다. 많은 응원과 관심 부탁드립니다.🙇
