고르곤졸라는 되지만 고르곤 졸라는 안 돼! 배달의민족에서 금칙어를 관리하는 방법
안녕하세요! 셀러시스템팀에서 서버 개발을 하고 있는 김예빈이라고 합니다.
배달의민족에는 금칙어를 관리하는 "통합금칙어시스템"이라는 것이 있습니다.
금칙어란?
법 혹은 규칙으로 사용이 제한된 말을 뜻하며, 서비스에서는 사용자로 하여금 사용을 제한하는 단어를 의미합니다.
배달의민족에서는 통합금칙어시스템을 통해 부적절한 단어를 사전에 제한하고 있는데요. 이번 글에서는 통합금칙어시스템이 어떻게 개발되었는지 그 과정과 개발 중 겪었던 시행착오들을 소개해 보려고 합니다.
들어가기 전에
배달의민족이라는 하나의 서비스 내에서도 금칙어 검사는 다양한 영역에 필요합니다.
사장님이 가게 소개를 작성할 때에도, 고객이 리뷰를 작성할 때에도 사용이 불가능한 단어가 포함되어 있는지 확인하는 과정이 필요합니다.
그리고 MSA(microservice architecture, 이하 MSA) 구조로 이루어진 배달의민족에서는 이 과정을 각 시스템에서 별도 구축해 처리하고 있었습니다.
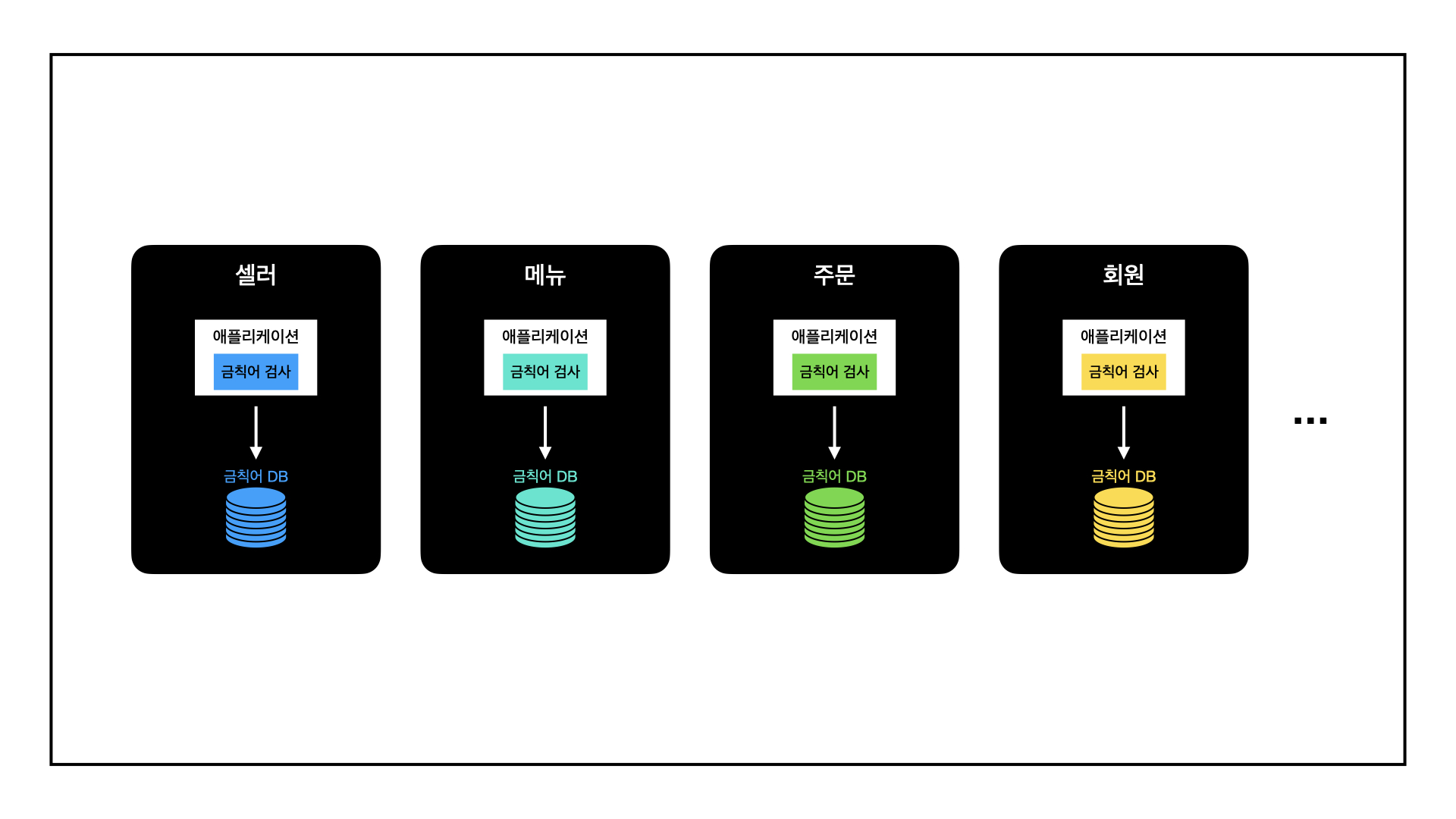
셀러시스템팀에서도 사장님이 입력하는 가게 정보에 대해 별도의 금칙어 검사 로직과 금칙어 테이블을 구축한 상태였습니다.
그런데 위와 같은 구조, 어딘가 비효율적이지 않나요?
게다가 "비속어"처럼 서비스 내에서 공통으로 처리되어야 하는 단어들이 서로 다른 정책으로 처리되고 있었습니다.
그럼, 한곳으로 통합해 보자!
때마침 금칙어 통합 관리에 대한 요구사항이 있었습니다. 여러 시스템에 동일한 정책을 도입하고, 같은 기능을 여러 부서에서 각기 개발하는 리소스 낭비를 줄여 효율성을 향상시키고자 했습니다.
그렇게 "통합금칙어시스템"이 시작되었습니다.
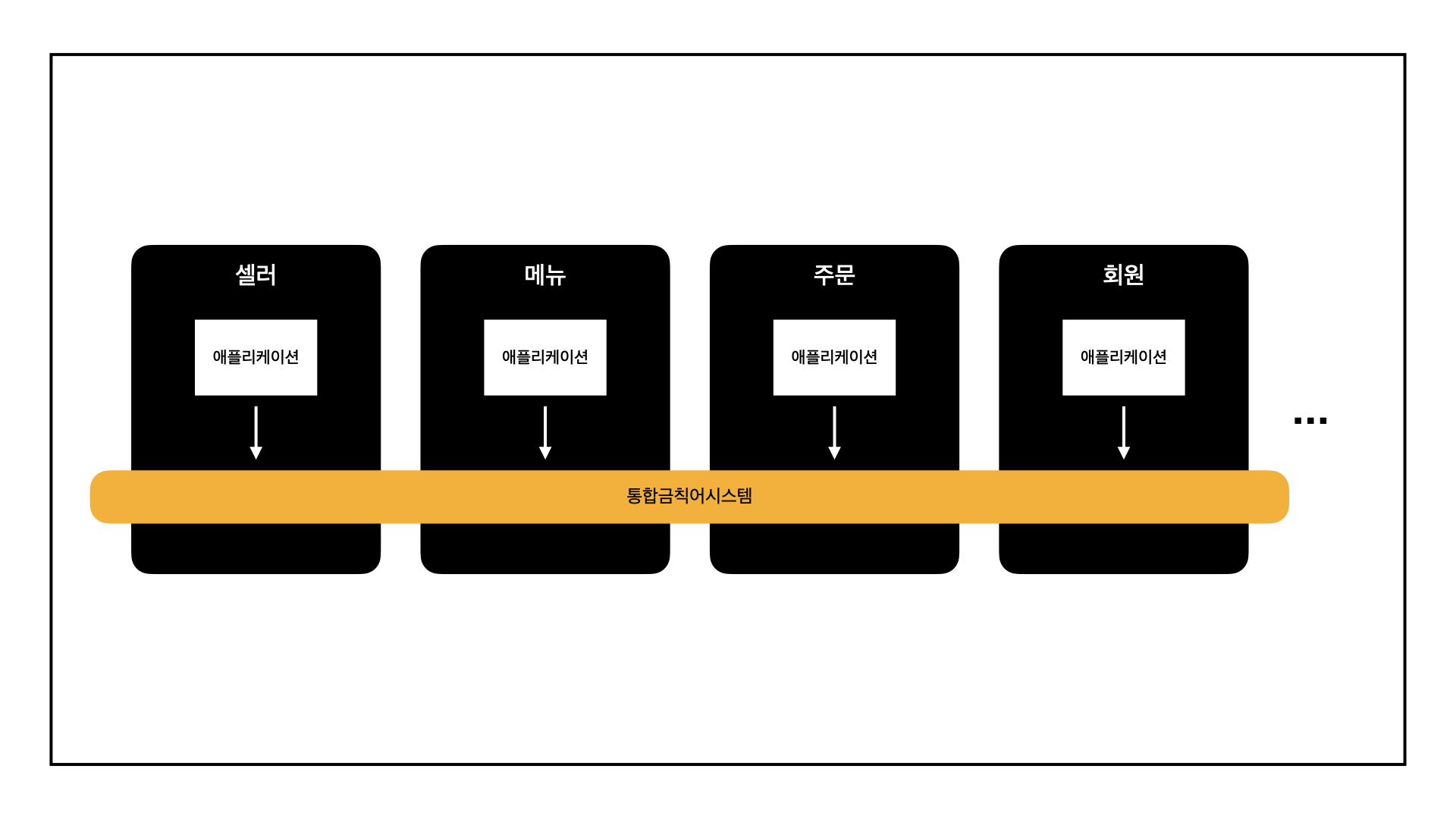
가장 구체화하기 쉬운 부분부터
우선 "통합"금칙어시스템에 맞는 데이터 구조가 필요했습니다.
"비속어"처럼 전체 시스템에 적용되어야 하는 금칙어도 있는 반면, "계좌번호" 같은 특정 시스템에서만 필요한 금칙어가 존재했습니다.
따라서 금칙어의 성격을 2가지로 나누었습니다.

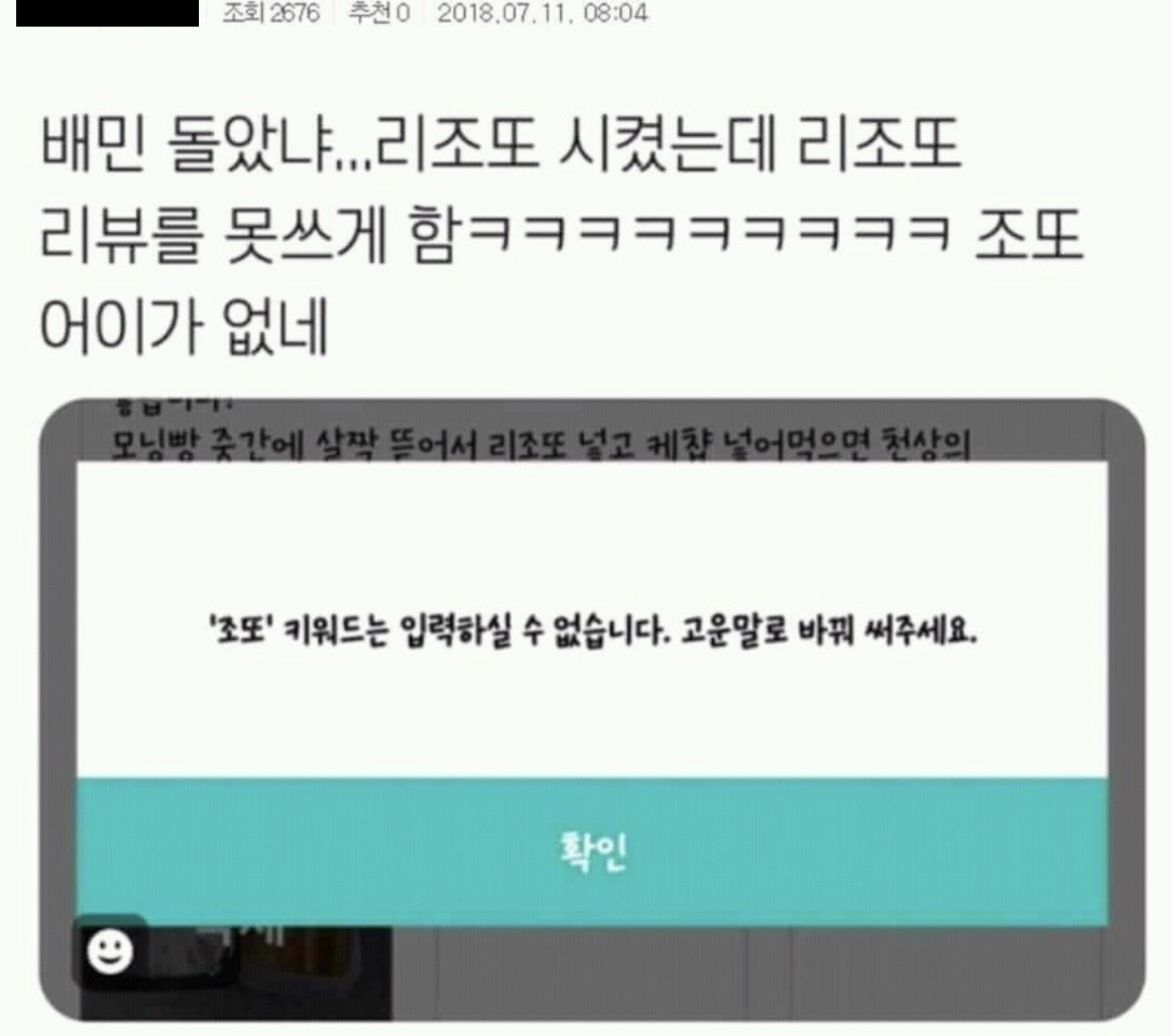
또한, 단어에 금칙어가 포함되지만, 사용에 문제가 없는 단어들이 있습니다.
- 고르곤졸라
- 리조또
이러한 단어를 "허용 단어"로 정의했습니다.

(여담이지만, 과거에는 "리조또"를 고운말로 바꿔 써야 했던 시절이 있었습니다. 사과드립니다…)
시스템 구조를 그려보자
다시 본문으로 돌아와서, 데이터 구조에 대한 대략적인 설계가 끝났으니 이제 금칙어 검사 기능을 유관부서에 어떻게 제공하는지에 대한 설계 부분으로 넘어가겠습니다.
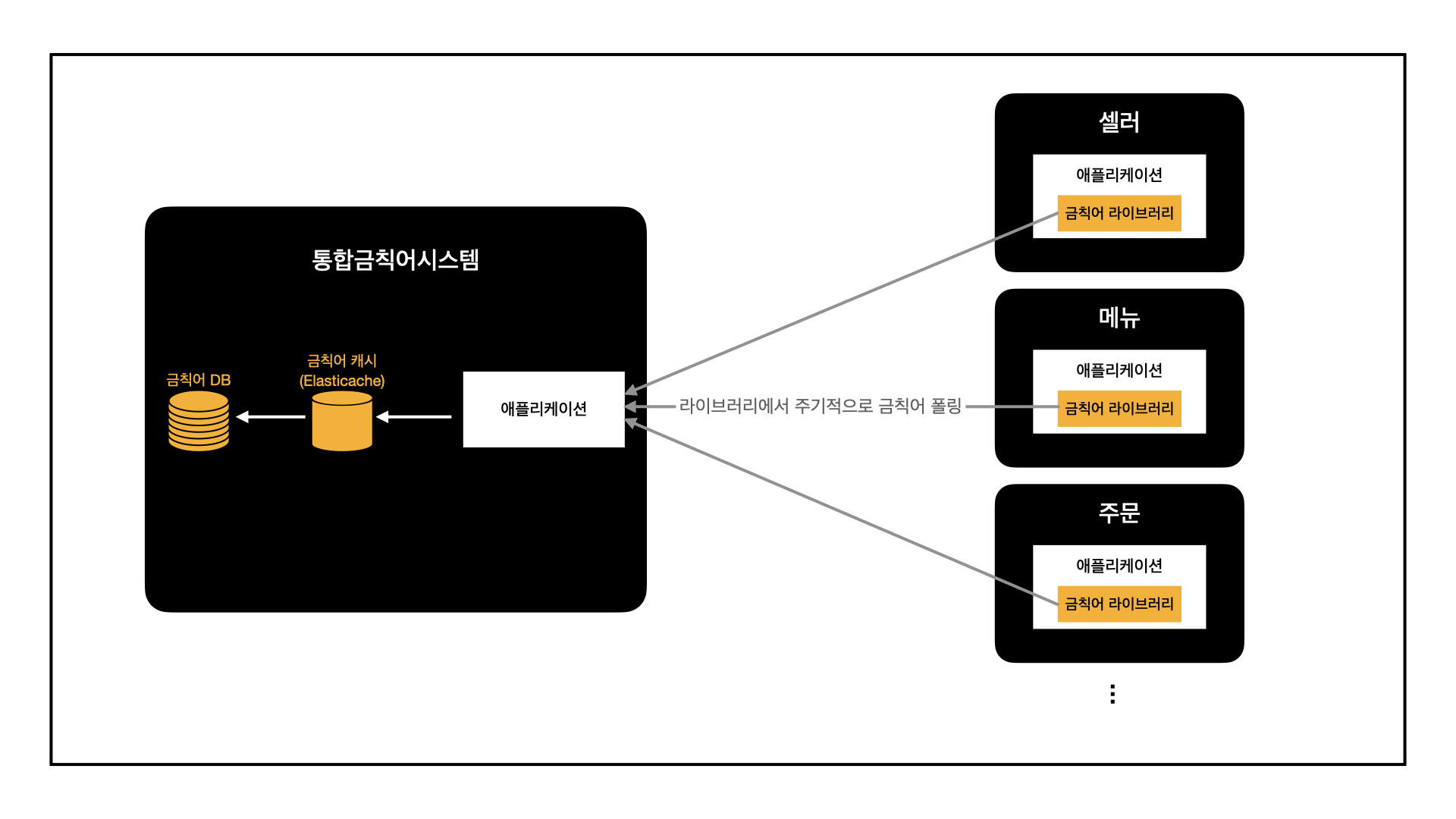
결론부터 말씀드리자면, 통합금칙어시스템에서는 금칙어 검사 라이브러리를 제공하고 있습니다.
라이브러리?
라이브러리를 제공한다는 것이 생소하실 수도 있는데요. (저희도 그랬습니다..ㅎㅎ)
그 배경에는 트래픽 문제가 있었습니다.
통합금칙어시스템에서 제공할 "금칙어 검사" 기능은 단순합니다. 문장을 입력하면 그 속에 금칙어가 포함되어 있는지 검사해 결과를 반환하는 것인데요, 이는 아래처럼 API로도 충분히 제공할 수 있습니다.
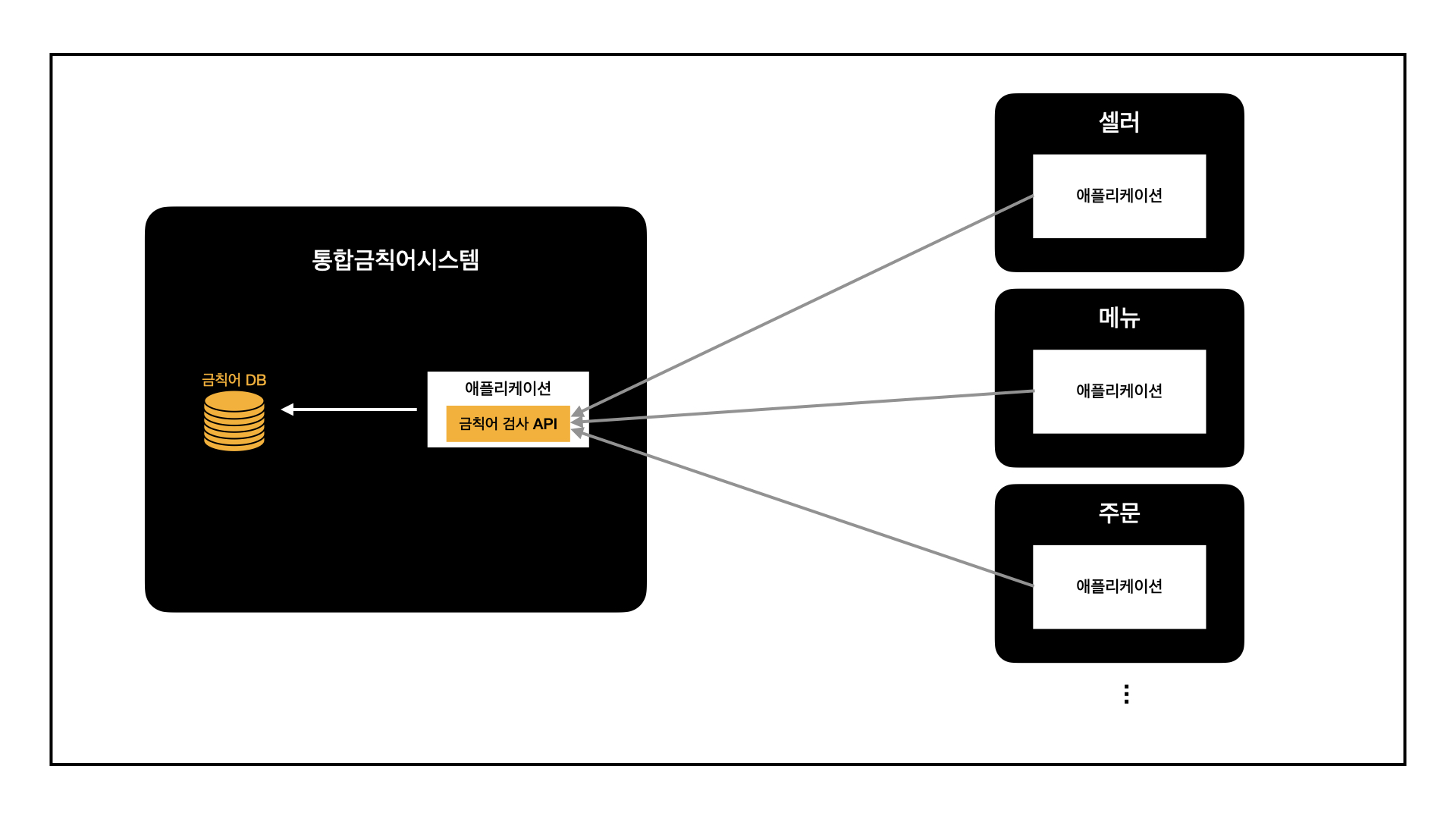
하지만 이 구조에서는 각 시스템에서 금칙어 검사가 필요할 때마다 통합금칙어시스템 API를 호출하게 되고, 이는 곧 트래픽으로 이어집니다. 개발 당시 금칙어 검사가 필요한 필드 중에는 고객이 작성하는 리뷰, 검색창에 입력되는 단어 등도 포함되어 있었기에 막대한 트래픽이 예상되었습니다.
더욱이 여러 부서에서 함께 사용할 "통합" 시스템에서는 안정된 트래픽 성능을 보장해야 했기에, 각 애플리케이션의 내부 자원만으로 충분히 검사를 진행할 수 있도록 라이브러리를 만들어 제공하게 되었습니다.
그럼 이쯤에서 검사에 필요한 금칙어 데이터는 어디서 가져오는지에 대한 의문이 드실 겁니다.
금칙어 데이터는 라이브러리에서 주기적으로 폴링하는 방식을 사용합니다.
금칙어 검사를 진행할 때마다 통합금칙어시스템 DB를 직접 호출해 가져오기엔 불필요한 조회가 너무 많이 발생합니다. 금칙어 데이터는 아래와 같은 특징이 있기 때문입니다.
한 번 생성되면 수정이 잘 발생하지 않고,
생성 빈도는 조회보다 훨씬 적다.
즉, 검사 시마다 DB를 호출하게 되면 동일한 데이터를 계속 받아오게 되므로 조회 낭비가 발생합니다. 따라서 라이브러리에서 10초, 1분 등 일정 주기로 금칙어를 폴링해 오도록 설계했습니다.
(이외의 폴링 관련 내용은 아래에서 더 자세히 다루겠습니다.)
또한, 다양한 부서의 다양한 서버에서 동시에 조회를 하기 때문에 조회 속도가 빠른 레디스를 활용해 보았습니다. RDB 앞에 레디스를 캐시 레이어로 두고, 라이브러리에서는 레디스를 조회하는 구조입니다.
이때 폴링한 금칙어는 애플리케이션 메모리에 올려둔 채로 검사에 활용합니다.
애플리케이션 메모리에 무언가를 올려 둔다는 발상이 조금 위험하긴 했는데요, 그래서 오픈 전 충분한 데이터를 세팅해두고 철저한 검증을 거쳤습니다.
아래 사진은 금칙어 데이터를 5만 개 정도 세팅했을 때의 모습입니다. 이때 1.2MB 정도의 아주 적은 메모리를 차지하는 것을 보실 수 있습니다.
현재 실제 운영 중인 금칙어 총 개수는 1만 개를 넘지 않으므로 훨씬 적은 메모리를 차지하고 있습니다.
최종적으로 아래와 같은 구조가 완성되었습니다.
금칙어 찾아내기
이제 라이브러리에서 제공할 주요 기능인 "문장 속에서 금칙어를 찾아내는 작업"이 필요합니다.
개인적으로 설계부터 구현까지 가장 어려움이 많았던 부분이었는데요. 이유는 다음과 같았습니다.
모든 서비스에 적용될 수 있는 범용적인 로직이어야 한다.
길이가 긴 문장이 입력되어도 금칙어 검사 속도는 빨라야 한다.
통합금칙어시스템에서 금칙어를 찾아내는 메인 로직은 "아호코라식 알고리즘"을 사용합니다.
아호코라식 알고리즘이라는 것이 생소하실 것 같은데, 개발 초기부터 해당 알고리즘을 사용하는 방향으로 접근했던 것은 아닙니다. 개발 당시 여러 가지 선택지가 있었는데요, 각 선택지에 대한 이야기와 함께 아호코라식 알고리즘을 최종 선택하게 된 배경도 소개해 드리겠습니다.
- 형태소 분석기
- String.contains()
- 아호코라식 알고리즘
첫 번째 시도, 형태소 분석기
통합금칙어시스템이 개발되기 전부터 형태소 분석기를 사용해 금칙어 검사를 진행하던 부서들이 있었습니다. 저는 이 프로젝트를 진행하면서 형태소 분석기라는 것을 처음 사용해 보았고, 사내 가장 많이 쓰이던 nori 형태소 분석기를 위주로 테스트하게 되었습니다.
nori 형태소 분석기는 Elastic에서 개발한 한국어에 특화된 분석기입니다.
문장을 입력하면 문장 속 단어들의 형태소를 분석해 조사, 어미 등 부가적인 부분은 제외하고 명사 등 순수 단어로 탐색할 수 있는 기능을 제공합니다. 또한, 탐색에 제외할 품사를 개발자가 직접 지정할 수 있다는 점 등 커스터마이징이 용이합니다.
하지만 계속해서 테스트를 진행하다보니 단점이 조금씩 보이기 시작했습니다.
우선, 예상치 못했던 엣지 케이스가 발견되었습니다. 예를 들면, 형태소 분석기는 아래 문자에 금칙어가 있다고 판단했습니다.
- 맛있게 만들고자
어떤 형태의 문장이 입력될지 모르는 상황에서 형태소 분석기의 검사 결과를 자신 있게 예측하기 어렵다는 점이 가장 큰 단점이었습니다. 더욱이 통합금칙어시스템처럼 범용적인 검사 로직을 제공해야 하는 시스템에서 이 방식을 채택하기에는 더욱 리스크가 높았습니다. 또한, 형태소 분석기에는 자체 구축된 단어 사전이 존재하는데, 이 사전에 어떤 단어들이 존재하는지 개발자가 열어보기 어려웠습니다. 따라서 추후에 사전 관련 요구사항이 발생할 경우, 확장이 어렵다는 단점이 있었습니다.
그래서 형태소 분석기를 사용하지 않고 문장에 금칙어가 "포함"되어 있는지를 직접 확인하는 방향으로 방법을 바꿔보았습니다.
두 번째 시도, String.contains() 메서드
가장 단순하게 java의 String.contains() 메서드부터 접근해 보았습니다.
금칙어를 List에 넣어두고, for 문을 돌면서 문자열에 금칙어가 포함되어 있는지 확인하는 방식으로 코드를 작성해 보았는데요.
List<Banword> banwords = List.of(...);
BanwordValidationResult validate(String originSentence) {
for (Banword banword : banwords) {
if (originSentence.contains(banword.getWord())) {
// 금칙어 발견
}
}
return BanwordValidationResult.notDetected(originSentence);
}
성능 테스트 결과는 처참했습니다.
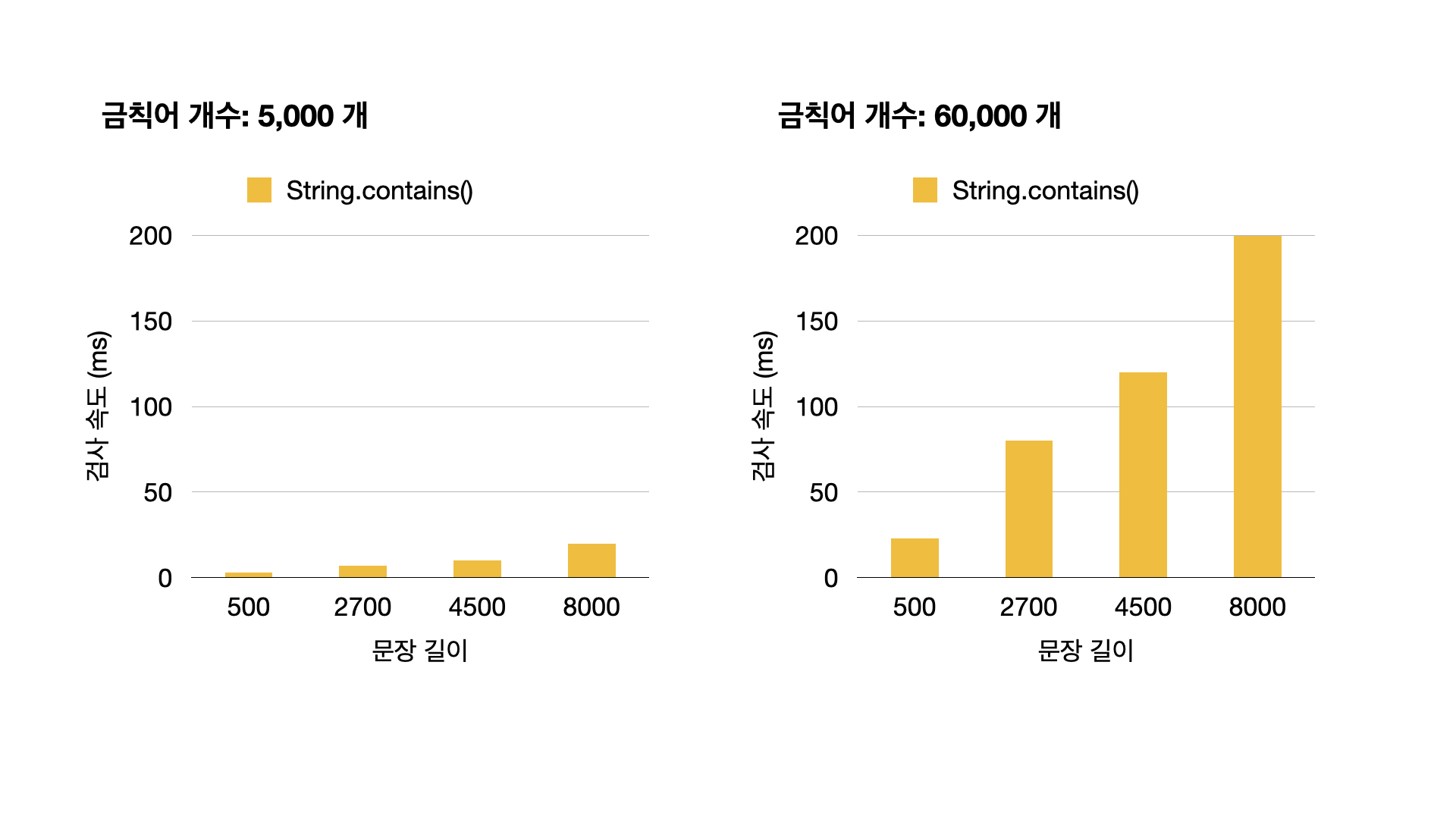
다들 예상하셨겠지만, 위 코드의 시간복잡도는 O(nm), n : 문장 길이, m : 금칙어의 개수 이기 때문에 당연히 느릴 수밖에 없습니다.
그렇게 조금 더 빠른 방법이 필요해졌고, 알고리즘을 활용하게 되었습니다.
세 번째 시도, 아호코라식 알고리즘
아호코라식 알고리즘이란?
문자열 탐색 알고리즘 중 하나로, 하나의 문장에서 여러 개의 문자열을 찾고자 할 때 적합한 알고리즘입니다.
아호코라식 알고리즘은 내부적으로 아래와 같은 Trie 라는 자료구조를 사용하는데, 찾고자 하는 단어 목록을 트리 형태로 만들어두고, 트리를 따라가면서 일치/불일치 여부를 판단합니다.
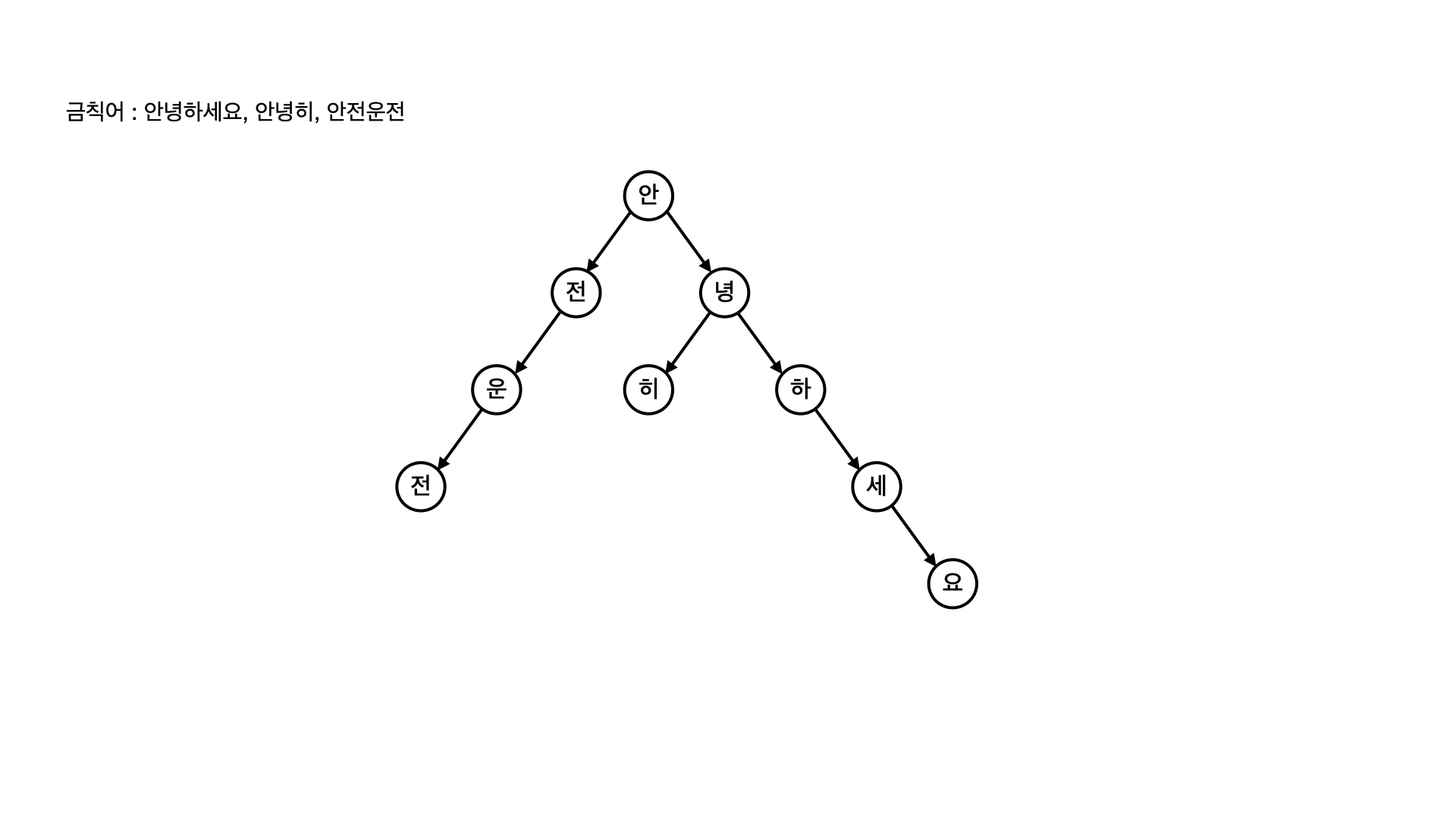
결과적으로 금칙어가 100개든 1000개든, 문장을 한 번만 훑으면 원하는 단어를 모두 찾을 수 있습니다.
아호코라식 알고리즘의 시간복잡도는 다음과 같습니다.
O(n + m + z), n : 문장 길이, m : 트라이를 구성하는 노드 개수, z : 매칭된 금칙어의 총 개수
이를 코드로 작성하면 다음과 같습니다.
dependencies {
implementation 'org.ahocorasick:ahocorasick:0.6.3'
}BanwordValidationResult validate(String originSentence) {
// 금칙어 검사. 아호코라식 알고리즘에서는 발견된 금칙어를 PayloadEmit 타입으로 return합니다.
Collection<PayloadEmit<Banword>> banwordResult = wordBundle.getBanwordTrie().parseText(originSentence);
return new BanwordValidationResult(originSentence, banwordResult);
}
테스트 결과, 기존 대비 아주 빠른 성능을 얻을 수 있었습니다!
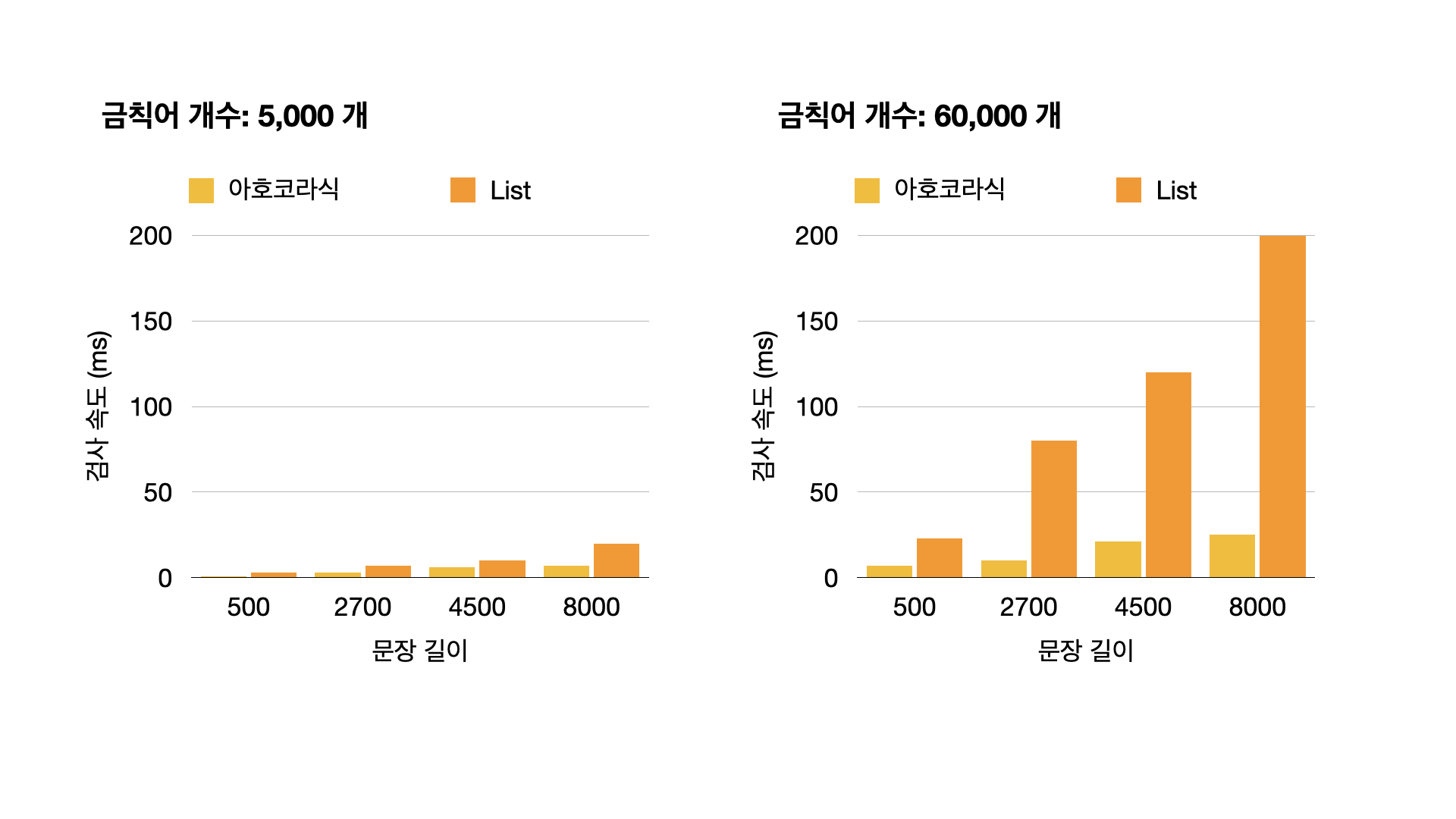
검사 로직에 살 붙이기
허용 단어 처리하기
어느 정도 금칙어 검사 로직이 완성되었으니, 이제 허용 단어를 처리하는 로직을 넣어줍니다.
문장에서 발견된 금칙어 중 허용 단어에 속하는 단어가 있을 경우 검색 결과에서 제거해주어야 하는데요.
허용 단어를 찾는 방법도 여러 가지가 있지만, 통합금칙어시스템에서는 검사 속도를 최대한 높이고 싶었습니다. 따라서 금칙어와 마찬가지로 허용 단어 Trie 를 별도 정의해 아호코라식 알고리즘을 활용하는 방식으로 개발했습니다.
흐름은 다음과 같습니다.

우회 단어 처리하기
아래 내용은 통합금칙어시스템 오픈 후 실제 인입된 요구사항입니다.
계좌1번호,계좌 번호와 같은 우회 단어들도 금칙어로 걸러주세요!
위와 같은 기능의 필요성은 충분히 공감이 되었으나, 기존에 이미 사용 중인 서비스의 로직을 바꿀 수는 없었습니다.
따라서 숫자, 공백 등 우회 단어의 종류를 구분하고, 이에 따라 사용처별로 원하는 종류의 문자를 제거하고 검사할 수 있도록 기능을 추가했습니다.
(라이브러리 코드)
public enum BanwordFilterPolicy {
NUMBERS("[\\p{N}]"),
WHITESPACES("[\\s]"),
FOREIGNLANGUAGES("[\\p{L}&&[^ㄱ-ㅎ가-힣ㅏ-ㅣa-zA-Z]]"),
...
private final String regex;
BanwordFilterPolicy(String regex) {
this.regex = regex;
}
}
사용처에서 아래와 같이 검사를 진행하면,
banwordValidator.validate(originSentence, Set.of(BanwordFilterPolicy.NUMBERS, BanwordFilterPolicy.WHITESPACES));
아래와 같은 로직을 거쳐 숫자와 공백을 포함한 우회 단어도 금칙어로 얻을 수 있습니다.

이렇게 검사 로직이 완성되었습니다.
라이브러리를 개발하며 고민한 부분들
라이브러리를 개발하면서 가장 어려웠던 부분은 바로 라이브러리 사용처에 대한 부분이 블랙박스라는 것이었습니다.
다양한 시스템의 다양한 코드에 대응이 되어야 했고, 이에 따라 통합금칙어시스템에서도 여러 가지 선택지를 제공하게 됩니다. 그중 폴링에 대해서 조금 더 이야기해 보겠습니다.
첫 번째 고민, 폴링 주기
라이브러리에서 금칙어 데이터를 주기적으로 폴링하는 부분에 대해 위에서 말씀드렸습니다. 그런데 라이브러리 사용처마다 필요한 폴링 주기가 달랐습니다. 어떤 서비스에서는 실시간 반영이 중요해 10초마다 반영이 필요했고, 어떤 서비스에서는 1분마다 반영되어도 무방했습니다.
이를 해소하기 위해 Spring properties를 통해 폴링 주기를 사용처에서 커스터마이징할 수 있도록 개발했습니다.
woowa:
banword:
polling: true
refreshMilliSeconds: 10000 #10초
두 번째 고민, 폴링 시점
또한, 위에서 금칙어는 생성/수정보다 조회가 훨씬 빈번하다고 말씀드렸는데요. 금칙어 데이터에 변경사항이 없는데 10초마다 계속 조회하는 것은 불필요합니다. 이러한 불필요한 조회를 최소화하기 위해 timestamp 를 기반으로 최신 금칙어를 폴링했는지 여부를 확인했습니다.
금칙어를 마지막으로 폴링한 시각과, 금칙어의 마지막 수정 시각을 서로 비교해 새로운 금칙어 목록을 응답할지 여부를 결정합니다.
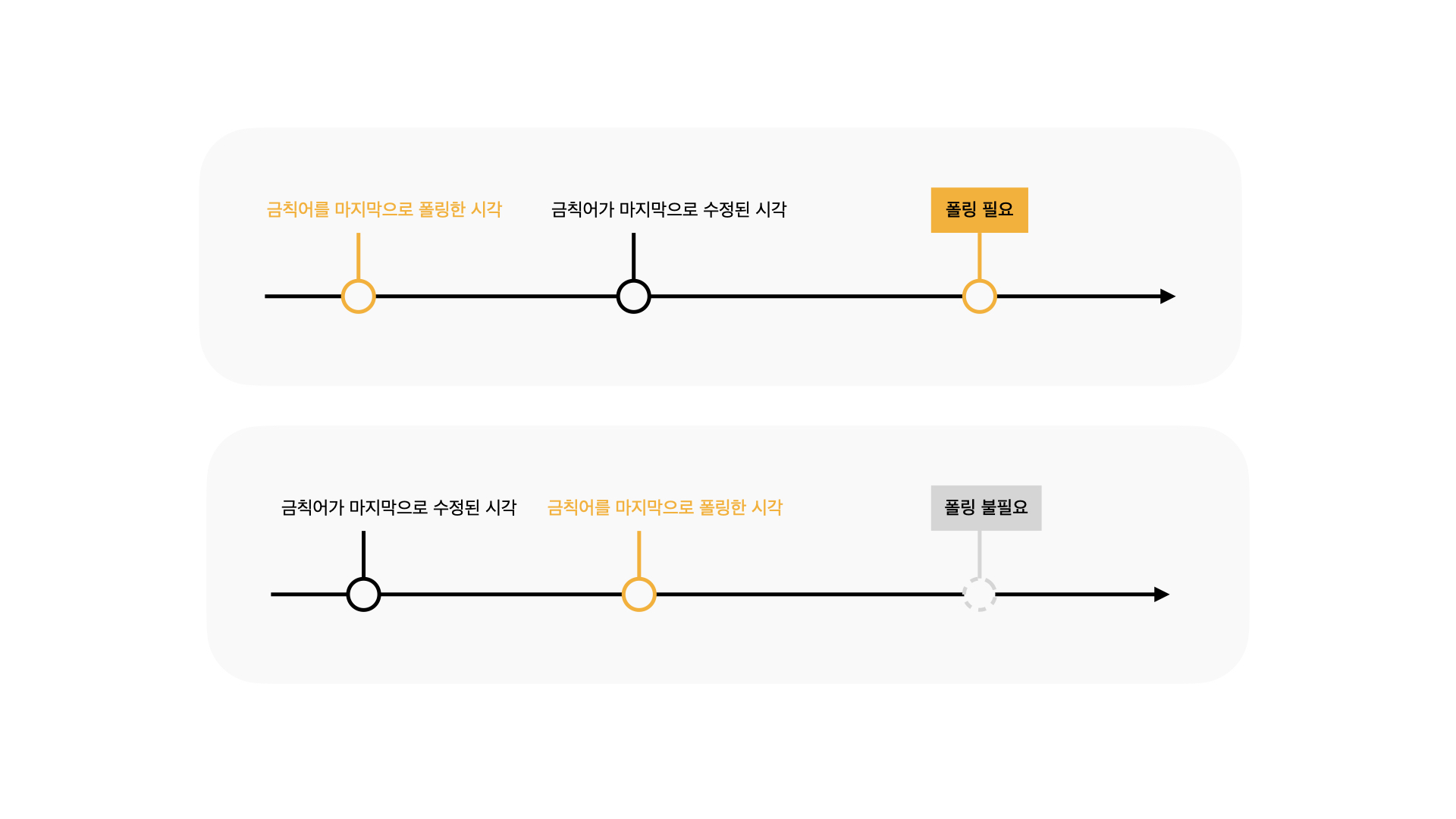
public class PollingBanwordFetcher extends BanwordFetcher {
private final String channelName;
private Long lastSearchedTimestamp; // 금칙어를 마지막으로 폴링한 시각 (통합금칙어시스템 캐시 레이어에서 보유하는 값)
public PollingBanwordFetcher(WoowaBanwordProperties properties) {
this.channelName = properties.getChannel();
}
@Scheduled(fixedDelayString = "${woowa.banword.refreshMilliSeconds}") // 라이브러리 사용처에서 입력한 폴링 주기
public void fetch() {
BanwordProviderResponse response = fetchWords(channelName, lastSearchedTimestamp); // 금칙어 폴링 API 호출
if (response.isRefreshed()) {
this.lastSearchedTimestamp = response.getLastSearchedTimestamp();
}
}
}
...
public class BanwordFetchService {
public BanwordAndAllowWordCacheResponse fetchWords(String channelName, Long lastSearchedTimestamp) {
if (needToSearch(lastSearchedTimestamp)) { // 폴링 필요 여부 판단
// 폴링 필요. 금칙어를 새로 조회해서 응답
}
// 폴링 불필요. 빈 객체 응답
}
}
세 번째 고민, 폴링 시 사용할 http client
배달의민족 서비스의 각 모듈은 대부분 Spring Boot 로 구성되어 있고, 대부분 OpenFeign 또는 Spring 에 내장된 RestTemplate client를 사용합니다. 이 중에서도 가장 많이 사용하는 client는 OpenFeign 인데요.
따라서 금칙어를 폴링할 때 Feign 관련 빈이 있을 때에는 FeignClient를 우선적으로 사용할 수 있도록 옵션을 제공했습니다.
@Configuration
@EnableBanwordProviderFeignClient // Feign 클라이언트 활성화
...
public class WoowaBanwordAutoConfiguration {
...
@Bean
@ConditionalOnMissingBean(BanwordProviderClient.class)
public BanwordProviderClient banwordProviderRestTemplateClient() {
RestTemplate restTemplate = new RestTemplateBuilder()
.setConnectTimeout(Duration.ofMillis(1000))
.setReadTimeout(Duration.ofMillis(3000))
.build();
return new BanwordProviderRestTemplateClient(restTemplate);
}
...
}
마무리
지금까지 통합금칙어시스템의 개발 과정과 함께 통합금칙어시스템에 대해 소개해 드렸는데요.
여전히 해결해야 할 숙제가 많이 남아 있지만, 약 2년간 9개의 서비스와 연동되어 안정적으로 운영되고 있습니다.(네…, 벌써 만든 지 2년이 지났는데 이제야 글을 쓰네요 ㅎㅎ)
저에게는 신입 개발자로 입사해 처음으로 프로젝트의 전 과정에 참여한 경험이어서 더욱 뜻깊고 재미있는 프로젝트였습니다. 무엇보다도 사내 흩어져있던 비슷한 기능을 하나로 통합해 개발 및 운영 리소스를 많이 덜어냈다는 사실이 뿌듯하고, 더 나아가 이런 요구사항은 어느 회사나 존재할 수 있기에 이 글을 읽고 계신 분들께 조금이나마 도움이 되면 좋겠습니다!
