배달의민족 광고데이터 이관기
이 글은 배달의민족 플랫폼 내에서 광고데이터를 이관한 작업 과정을 소개한 글입니다.
광고데이터 이관 작업은 고객 경험에는 직접적인 변화를 주지 않았지만, 시스템 측면에서는 상당한 위험도를 안고 진행된 중대한 과제였습니다.
고객 입장에서 변화가 없는 작업이지만 해야만 했던 이유가 있었습니다. 그 배경을 설명드리기 전에 먼저 광고데이터가 배달의민족앱 내에서 어떻게 활용되고 있는지 간단히 살펴보겠습니다.
광고데이터가 활용되는 곳
예를 들어 사용자가 배달의민족 앱에서 ‘치킨’ 카테고리를 선택하면, 오픈리스트, 울트라콜, 배민1과 같은 광고 상품들이 다양한 가게와 함께 표시됩니다.
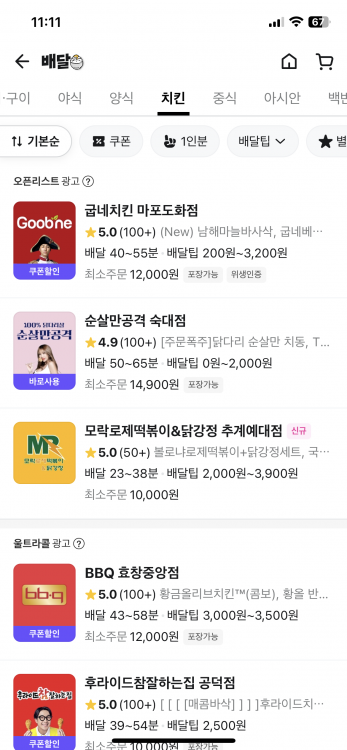
이때, 광고 노출 시스템은 이러한 가게들이 어떤 순서로 보여질지를 결정합니다. 노출 순서를 결정하는 데는 여러 데이터가 활용되는데, 예를 들어 사용자와 가게의 거리, 가게의 영업 상태, 배달 비용, 예상 배달 시간 등이 포함됩니다. 이러한 다양한 요소들이 광고 상품의 효율성과 관련성을 높이는 데 기여합니다.
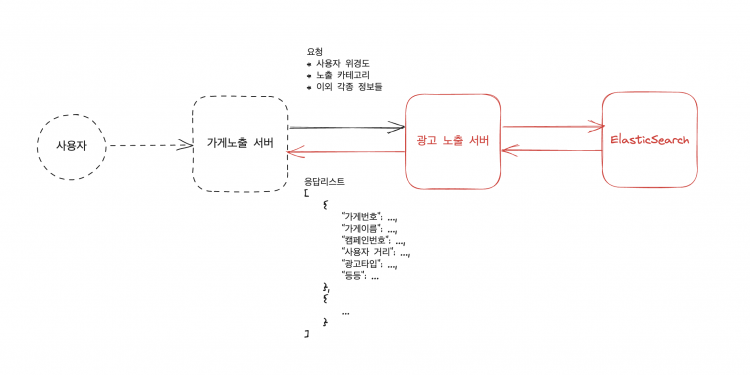
도식으로 간단히 보면 위와 같습니다. 응답에 사용되는 데이터는 가게가 적절히 노출이 될 수 있도록하는 핵심 데이터입니다. 이런 데이터는 ElasticSearch에 저장이 되어 서빙이 되고 있습니다. ElasticSearch는 높은 처리 능력과 확장성을 제공하여, 대량의 데이터를 신속하게 처리하고 사용자에게 최적화된 검색 결과를 제공하는 데 중요한 역할을 합니다
작업 배경
월드컵이나 아시안컵과같은 축구경기등과 같은 대규모 이벤트 기간에는 평소보다 높은 트래픽을 처리하기 위해 Elasticsearch data node와 client node를 미리 scale-out하는 등의 선조치가 필요합니다. 대규모 트래픽이 지나간 이후에는 다시 원래의 대수만큼 scale-in을 해야 합니다.
여기서 문제가 하나 있었는데요, 늘어난 데이터노드를 줄이려면 단순히 서버를 내리면 안 되었습니다. Elasticsearch가 구축형으로 만들어져 있었기 때문에 아래의 과정을 거쳐야합니다.
먼저 AWS 콘솔에서 ES auto scaling group을 찾아 내릴 서버를 일일이 detach해야 합니다. detach도 zone별로 균일하게 detach를 하지 않으면 자동으로 균형을 맞추기 위해 서버가 자동으로 만들어집니다. 또한 detach된 인스턴스에 접속하여 ES docker 컨테이너를 종료시키고 난 이후에 실제 인스턴스를 종료해야 합니다.
게다가 scale-in작업은 보통 새벽에 사람에 의해서 직접 수행되기 때문에 이러한 절차는 실수를 유발할 수 있습니다.
Elasticsearch에 문제가 발생하면 앱 내의 가게 노출에 심각한 장애가 발생할 수 있으며, 이는 회사와 가맹점에 금전적 손해와 최악의 고객 경험을 초래하는 심각한 문제로 이어질 수 있습니다.
클라우드 이관 시 장점
이러한 문제를 해결하기 위해 AWS 클라우드 서비스로 전환을 결정하게 되었습니다. 클라우드 서비스로 전환시 다음과 같은 이점을 기대했습니다.
- 잦은 scale in/out에도 버튼 클릭 한 번으로 수월하게 진행하여 휴먼에러 발생 가능성 차단
- 구축형 클러스터 관리 리소스 및 비용 절감
- Elasticsearch 클러스터의 편리한 업데이트
- AWS의 기술지원
작업 목표
작업목표는 크게 2가지 였습니다.
- 절대 시스템 다운타임이 발생하면 안 됨
- 기존 코드 변경 최소화
위 작업은 개발 개선 작업이면서 서비스에 어떠한 변화도 미쳐서는 안 됩니다. 무엇보다 고객입장에서는 바뀌는 부분이 전혀 없기 때문에 아무 일도 일어나지 않은 것처럼 느껴져야 합니다. 때문에 전환 시에 시스템 다운타임이 발생하면 절대 안 됩니다. 이 작업은 큰 작업이기 때문에 돌아가고 있는 기존 코드들에 대한 개선 작업은 하지 않기로 하였습니다.
작업을 담당하는 입장에서 회사 내 매출의 큰 부분을 차지하는 지면을 담당하는 데이터저장소를 통째로 교체하는 작업은 매우 부담스러웠는데요, 순간 왜 한다고 했을까 하는 생각이 잠시 머릿속을 스쳐..가는 찰나 팀에서 꼭 필요한 작업이기 때문에 실수 없이 잘해보자라고 마음을 다잡았습니다.
기존 아키텍처
마이그레이션 과정을 설명하기 전에 기존에 광고데이터가 어떻게 적재되고 활용되고 있는지 간단히 살펴보겠습니다.
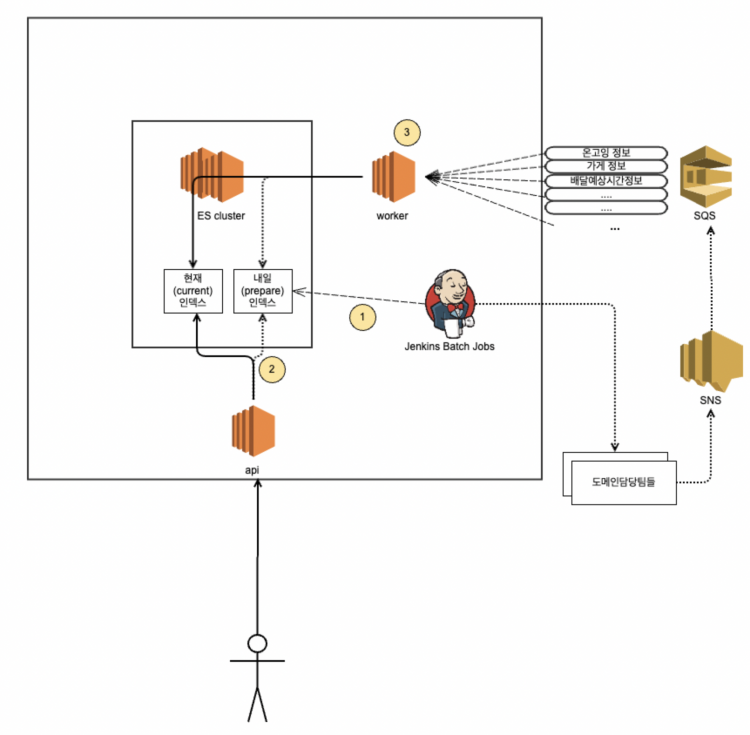
광고시스템에서는 내일 송출될 광고데이터를 전날에 미리 적재(이하 풀 인덱싱)하고 있습니다.
도식의 1번을 보면 전날 저녁에 내일 송출할 광고를 위한 인덱스를 batch job을 통해 미리 만들어 놓습니다. 광고시스템 내의 정보와 부가 정보를 위해 각 도메인 담당팀들의 정보도 필요합니다. 이렇게 만들어진 인덱스는 다음날 0시가 되면(도식의 2번) API 요청을 받는 current 인덱스의 alias가 전날 만들어 놓았던 인덱스로 변경됩니다. 또한 도식 3번처럼 실시간으로 광고데이터의 변경이 일어나기 때문에 배달의민족 각 도메인을 담당하는 팀으로부터 Amazon SQS(Simple Queue Service)를 통해 이벤트를 수신하고 있습니다. 실제 풀 인덱싱이 시작되면 광고데이터 변경 사항에 대해서는 current 인덱스와 prepare 인덱스 모두 정보가 반영되어야 합니다. 이에 따라 도식엔 존재하지 않지만 여벌의 SQS가 존재하고 풀 인덱싱이 끝나면 prepare 인덱스는 여벌의 SQS에 있는 이벤트를 그제야 소모하여 current 인덱스와 싱크를 맞추게 됩니다.
요약하면 아래와 같습니다.
- 새로운 인덱스를 생성
- 새로운 인덱스에 광고데이터 인덱싱
- full indexing 과정에서 변경된 광고데이터를 current와 prepare index에 모두 반영
- 0시가 됐을 때 prepare를 current로 전환
마이그레이션 과정
Elasticsearch 클러스터 검토
기존 구축형에서 사용하고 있었던 버전은 아래와 같습니다.
- Elasticsearch: 7.3.2
- Lucene: 8.1.0
영향도를 최소화하기 위해서는 동일한 버전으로 마이그레이션을 해야 합니다. AWS OpenSearch에서 지원가능한 버전은 기가 막히게도 동일한 버전이 없었습니다. ElasticSearch는 버전별로 차이가 꽤나 존재했기 때문에 버전을 내리거나 올리기가 부담스러웠는데요. 관련해서 AWS support TAM(technical account manager)께 정말 버전을 지원하지 않는 건지 확인차 물어봤고 결과적으로 미지원으로 답변을 받았습니다.
역시 처음부터 난관에 부딪혔습니다. 어쩔 수 없이 버전별로 테스트를 할 수밖에 없었습니다. 버전별 테스트는 아래와 같은 2가지를 핵심 확인사항으로 봤습니다.
- index에 데이터 적재 시 문제가 없는가?
- API 조회 시 기존로직의 여러 filter와 sort 등의 쿼리가 수행되어도 문제가 없는가?
버전별 테스트결과를 요약하자면(7.3.2 기준) 아래와 같은 3개의 버전에서 테스트를 진행하였습니다. 해당 버전들의 선택의 이유는 현재 사용하는 버전의 바로 아래 버전(7.1.1), 바로 위 버전(7.4.1) 그리고 현재 팀에서 운용하고 있는 OpenSearch 버전(7.10.1), 이렇게 3가지 버전에서 테스트하면 충분하다고 생각했습니다.
- 7.1.1
- randomScore 함수를 미지원하였습니다. Elasticsearch script에서 random한 점수를 계산하는 로직이 있기 때문에 이 버전은 사실상 사용 불가했습니다.
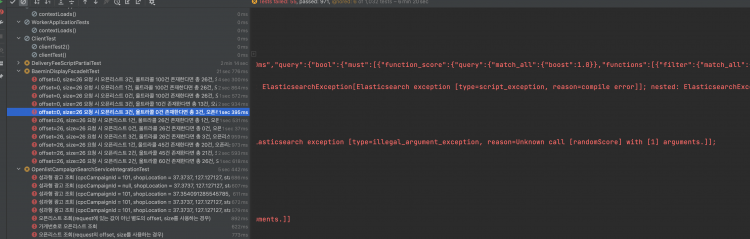
- 7.4.1
- geo_shape 데이터타입 parsing Error
{ ... "root_cause": [ { "type": "mapper_parsing_exception", "reason": "failed to parse field [shopDeliveryAreaGeoFence] of type [geo_shape]" } ], "type": "mapper_parsing_exception", ... }
- geo_shape 데이터타입 parsing Error
- 7.10.1
- 현재 API에서 사용 중인 부분들이 몇 가지 deprecated되었습니다.
현재 일부 클라우드서비스로 운용 중인 Elasticsearch 버전이 7.10이기 때문에 이 버전을 쓸지를 많이 고민을 했었습니다. 운용하고 있는 여러 Elasticsearch 클러스터의 버전을 동일하게 가져가는 게 관리 측면에서 좋다고 생각했고 7.4 버전에 발생한 매핑 문제도 발생하지 않았기 때문입니다. 해당 버전에서의 이슈를 수정할 수 있는 해결책도 찾았지만 버전을 너무 건너뛰어서 업그레이드를 하는 것에 대한 리스크, 또한 노출 관련 script의 변동등이 존재했기 때문에 최대한 보수적으로 마이그레이션 하자는 취지에 맞지 않다고 판단하여 딱 1단계만 올리는 7.4.1 버전을 선택하였습니다.
7.4.1 버전에서의 문제인 특정 필드가 매핑되지 않는 문제를 해결할 수 있는지 살펴보았고 다행히도 문제가 발생하는 필드는 과거에 참조되고 있었던 필드였고 현재 쿼리에서는 참조하고 있지 않는 필드로 확인했습니다. 결과적으로 geo shape가 없다면 null로 인덱싱되게 수정했습니다.
마이그레이션 아키텍쳐
마이그레이션 방법을 크게 2가지로 고민해 보았습니다.
- 적재 job을 두 번을 수행하여 기존 Elasticsearch와 신규 Elasticsearch에 적재해 둔다.
- 기존 Elasticsearch의 인덱스 적재 작업이 끝나면 remote reindex로 신규 Elasticsearch에 복사한다.
두 번째 마이그레이션 방법은(AWS doc 참고) 기존 Elasticsearch의 인덱스를 복사하는 작업이 추가되는 것이고 이는 기존 리소스를 건드리는 행위가 됩니다. 트래픽이 적은 시간에 수행될 거고 이론상 문제가 없지만 최대한 보수적으로 마이그레이션을 하자는 취지에 걸맞지 않은 것으로 판단했습니다. 결국 1번 방식으로 독립된 인덱싱 환경을 따로 구축하기로 하였습니다.
구축된 환경은 아래 도식과 같습니다.
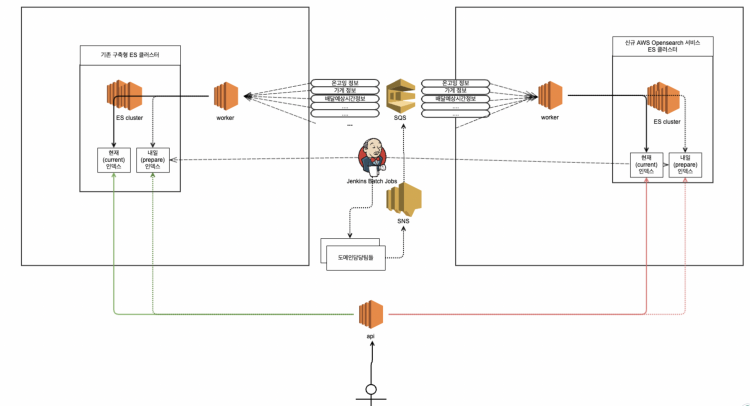
기존에 적재되고 있던 광고데이터는 변동 없이 그대로 적재되고 있어야 합니다.(좌측) 신규 아키텍처(우측)에서 문제가 생겼을 때 곧바로 롤백을 하기 위해서는 기존 리소스가 평소처럼 그대로 존재하고 있어야 하기 때문입니다. 그리고 API 서버들의 트래픽을 한 번에 전환하는 게 아닌 카나리(canary) 형태로 1대만 신규 Elasticsearch를 바라보도록 배포 후에 모니터링을 해야 합니다. 특이사항이 없다면 모든 API 서버의 트래픽을 신규 Elasticsearch를 바라보도록 전환하게 됩니다.
위 방향성을 만족시키려면 요구사항은 아래 2가지로 정의할 수 있습니다.
- 매일 적재되는 광고데이터를 두 Elasticsearch에 동일하게 적재해야 한다.
- 실시간으로 변경되는 광고데이터를 두 Elasticsearch에 동일하게 반영해야 한다.
첫 번째 요구사항을 만족시키기 위해서는 매일매일 광고데이터를 풀 임포트를 할 때 두 개의 인덱스에 적재해야 하는데요. 적재를 위해서는 배달의민족의 여러 도메인 정보가 필요합니다. 결과적으로 타 팀까지 호출하면서 진행되기 때문에 평소 요청량이 얼마인지 계산해 보고 해당 트래픽의 2배를 타 팀에서 받아도 되는지 먼저 확인해 봐야 합니다. 또한 자정이 되기 전에 이 2가지의 작업이 모두 끝나야 합니다. 기존 풀 임포트는 아래와 같은 배치 파이프라인으로 진행되고 있었는데요.

최초에 광고데이터를 먼저 인덱싱합니다. 이 과정을 캠페인 색인이라고 합니다. 캠페인 색인 도중 광고데이터에 변경이 일어나는 것을 반영하기 위해 여러 B2B팀의 변경사항에 대한 메시지 큐를 따로 만들어 두고 잠시 보관했다가 광고데이터 인덱싱이 끝난 이후에 차례로 반영합니다.
신규 Elasticsearch의 풀 임포트를 담당할 배치 파이프라인을 똑같이 만들어야 했습니다. 해당 배치 내에서 파라미터로 신규 Elasticsearch를 바라보도록 주솟값을 넣으면 배치 앱 내에서 해당 Elasticsearch를 바라보고 수행되게 됩니다.
마이그레이션 준비 과정
마이그레이션 준비과정은 신규 Elasticsearch 클러스터, 여벌의 SQS와 배치 job이 필요합니다.
참고로 큐의 종류가 매우 많고 각기 설정이 조금씩 다르기 때문에 하나라도 잘못 구성하게 되면 문제가 발생할 수 있습니다. 실수하지 않기 위해서 생성한 모든 큐들의 구성과 링크를 아래와 같이 위키에 정리하고 크로스체크하고 여러 번 검토를 진행하였습니다.

다음은 구성한 배치 파이프라인 모습입니다.
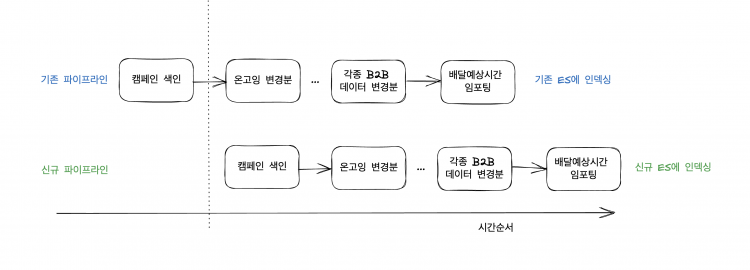
기존 파이프라인의 첫 번째 job인 캠페인 색인 job이 끝나면 곧바로 신규 파이프라인의 첫 번째 job인 캠페인 색인 작업을 트리거합니다.
캠페인 색인 job이 기존, 신규 Elasticsearch에 동시에 수행되면 유관부서들에 동시에 2배의 트래픽이 가기 때문에 동시 실행은 하면 안 됩니다. 캠페인 색인 job이 시작되는 기준으로 광고데이터 변경분에 대한 SQS에 메시지들이 쌓이기 시작할 것이기 때문에 두 환경에서 변경분 SQS에 들어갈 메시지는 각기 다릅니다. 하지만 최종으로 일관성이 맞춰질 것이고 이 맞춰진 인덱스에 대해서는 00시부터 호출이 일어날 것이기 때문에 상관없었습니다.
성능 테스트
이 작업에 대한 성능 테스트는 구축한 신규 Elasticsearch에 대해서 최소 현재 운영환경만큼의 트래픽을 받아낼 수 있는지 확인하는 과정입니다.
먼저 현재 피크 시간대 API별 요청량 비율을 확인합니다. 요청량이 아닌 비율을 확인하는 이유는 실제 ngrinder에서 성능 테스트를 진행할 때 API별로 호출비율을 동일하게 하기 위해서입니다. 동일한 비율로 호출했을 때 현재 운영에서 받고 있는 요청량을 견딜 수 있는지 확인해야 합니다.
운영 환경의 데이터를 dump하여 성능 테스트 환경에 적재해 두고 가게들이 많이 위치한 강남역 기준으로 운영 환경과 동일한 비율의 API를 호출하며 테스트했습니다.
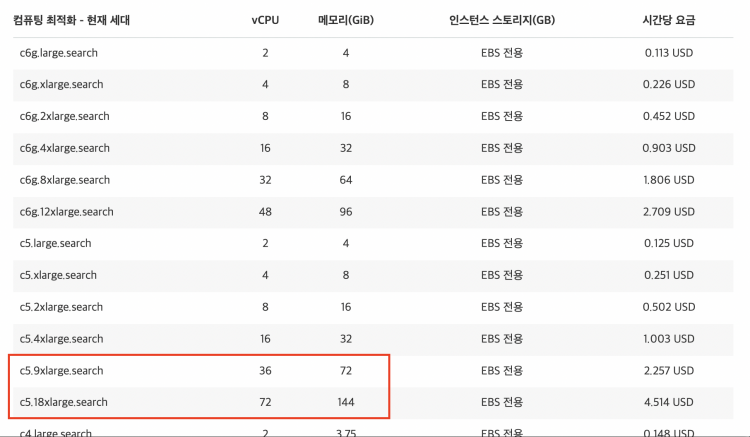
적절한 장비 스펙을 확정하기 위해 아래와 같은 케이스를 후보군으로 선정하였고 각각 테스트를 진행했습니다.
- c5.18xlarge.search x 4대
- c5.18xlarge.search x 6대
- c5.9xlarge.search x 4대
- c5.9xlarge.search x 6대
눈여겨볼 지표들은 아래와같습니다.
- Elasticsearch, API 서버 cpu usage
- search rate
- Elasticsearch 클러스터에서 수행되는 검색 요청의 비율입니다.
- jvm memory pressure
- Elasticsearch 클러스터 내 JVM이 메모리를 효율적으로 사용하고있는지 판단하는데 사용됩니다. 압력이 높아져 가비지 컬렉션(garbage collection, GC)이 자주 발생하는지 지속적으로 압력이 높을 경우 메모리 누수가 발생하는지 파악할 수 있습니다.
- es thread pool
- ThreadPoolSearchThreads: 검색 스레드 풀에서 현재 활성화된 스레드의 수를 나타냅니다. 검색 작업은 병렬로 처리될 수 있으며, 각 작업은 검색 쿼리나 요청에 따라 분산되어 처리됩니다. 일정한 수의 스레드가 활성화되어 있어야 전체 검색 처리량을 효율적으로 다룰 수 있습니다.
- ThreadPoolSearchThreads: 검색 작업이 처리되기를 기다리는 대기열의 길이를 나타내는 지표입니다. 검색 요청이 들어왔지만 처리되기 위해 대기하고 있는 작업들이 몇 개인지 알려주는것으로 시스템이 현재 처리 능력을 초과하고 있는지, 작업이 지연되고 있는지 등을 파악할 수 있습니다.
- ThreadPoolSearchRejected: 검색 작업이 거부된 횟수를 나타내는 지표입니다. 이 지표는 검색 요청이 들어왔지만 현재 시스템 상태에서 처리할 수 없어서 거부된 요청의 수를 보여줍니다.
각 지표들이 얼마만큼 부하를 주었을 때 위험수치까지 올라가는지 확인하였습니다.
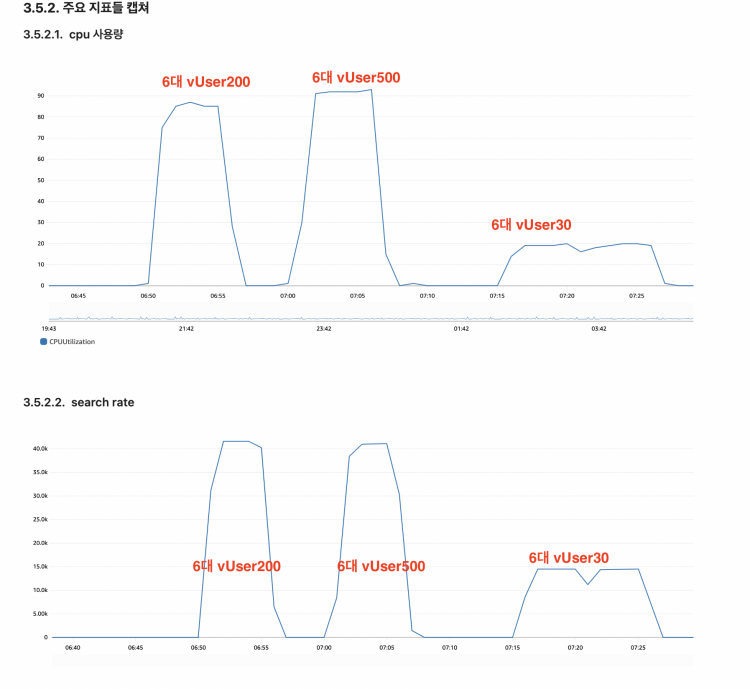
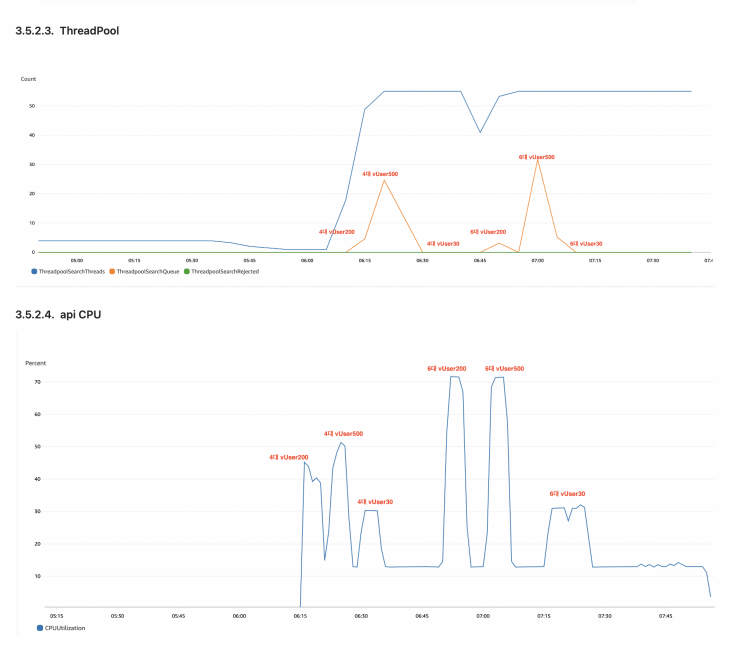
운영환경보다 더 많은 부하를 주는 테스트를 진행한 후에 실제 운영수준의 부하를 주는 테스트를 진행하였습니다. 실제 운영수준에서의 부하는 충분히 견디고 남을 만큼의 성능을 보여주었습니다. 물론 비싼 장비를 더 많이 사용하게 되면 더 많은 부하를 처리할 수 있지만 장비 사용 금액도 만만치 않기 때문에 비용절약과 안정적 트래픽수용 두 마리 토끼를 다 잡기위한 최적의 조건을 찾는 것이 중요하였습니다.
최초 고려한 c5.18xlarge보다 장비 스펙을 한단계 낮춘 c5.9xlarge 6대로 운용하는것으로 결정했는데요. 비용을 더 낮추면서 충분한 트래픽 수용이 가능하다는 판단에서 였습니다. 물론 ThreadPoolSearchThreads가 발생하는 상황은 있었지만 해당 상황은 현재 운영환경 이상의 훨씬 많은 부하를 주었을 때 발생하였고 그 결과가 rejected까지 이어지지는않았습니다. 또한 주말피크트래픽이상의 트래픽이 예상이되는 이벤트상황에서는 미리 scale-out을 해두기 때문에 무방하다고 판단하였습니다.
참고 – 마스터노드와 클러스터 상태
참고로 마스터노드의 경우 클러스터내 관리되고있는 인스턴스 수에 따라서 설정해야 합니다. 마스터 노드는 ES 클러스터 전체의 메타데이터 관리와 클러스터 상태 모니터링을 담당하며, 노드의 추가 또는 제거, 인덱스의 생성 및 삭제 등과 같은 클러스터 레벨의 작업을 수행하는 등 중요한 역할을 담당합니다.
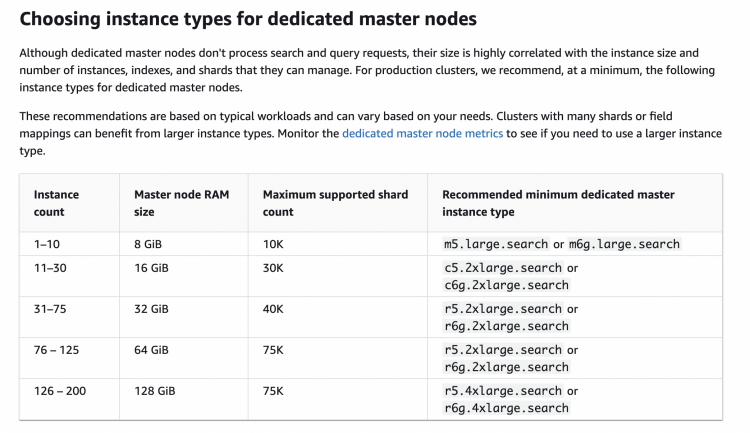
(출처: Dedicated master nodes in Amazon OpenSearch Service
예를 들어, 데이터노드가 10대로 유지되고있다면 표의 2번째 칸인 11~30 range로 간주하고 마스터노드의 스펙을 결정해야 합니다. Elasticsearch 업데이트 등으로인해 내부적으로 blue green 배포가 일어나고 일시적으로 노드의 수가 2배로 유지되기 때문입니다. 실제로 마스터노드의 스펙이 부족하여 blue green배포때 Elasticsearch 클러스터 상태가 일시적으로 RED상태가 된 적이 있었습니다. AWS 내부에서 동작하는 self healing script를 통해서 자동으로 복구가 되었지만 해당시간동안 문제가 발생하였습니다. primary shard가 할당된 노드만의 문제로 replica shard에서 조회가 처리되고 있었기 때문에 다행히도 조회쪽에는 문제가 없었습니다. 하지만 인덱싱이 수분 간 모두 실패하였습니다. 이마저도 SQS 메시지를 소모할때 retry가 존재하기 때문에 RED 상태에서 정상으로 복귀됐을 때 이벤트가 유실되지 않고 모두 처리가 되었습니다. 해당 사건이후 AWS 측에 case open을 하였고 일시적 하드웨어이슈로 발생했던 상황으로 공유받았습니다.
retry 기간이상으로 RED 상태가 유지된다면 dlq및 로그로 모든 이벤트를 복구해야 합니다. 참고로 RED상태가 발생하는 이유는 아래와 같습니다.
- 여러 데이터 노드 장애
- scale-in시 primary shard가 할당되어있는 특정 노드 제거 지연시
- 높은 JVM 메모리압력, CPU 사용
- 디스크 공간 부족
릴리즈 시나리오
성능테스트도 마쳤으므로 이제 배포 준비를 해야 합니다. 참고로 배민리스팅광고개발팀은 누락없는 꼼꼼한 배포를 위해 배포시나리오를 템플릿화하여 관리하고있습니다.
주요변경사항, 사전준비, 베타환경 릴리즈플랜 재현, 운영배포, 롤백시나리오, 피드백 및 사후작업 으로 구분됩니다.
- 주요변경사항: 이 배포로 인해 주요하게 변경되는 내용을 기록합니다.
- 사전준비: 운영 배포일 전에 준비해야할 것들 (예를 들어, 테이블생성 운영 리스소 생성, 유관부서 협의, 스키마변경, 릴리즈브랜치 준비 등)을 기록합니다.
- 베타환경 릴리즈플랜 재현: 여러 서버군들이 존재하고 스키마나 데이터의 변경이 필요한 상황에서 운영 배포시 순서를 지키지 않아서 문제가 발생하는 경우가 존재합니다. 베타환경에서는 순서에 둔감하게 작업하거나 순서를 인지하지 못하고 작업하는 경우가 있어도 크게 문제가 되지 않지만 운영은 바로 장애로 이어질 수 있습니다. 이에 따라 베타환경을 현재 master버전으로 롤백시켜두고 운영배포시나리오대로 똑같이 베타에서 수행하여 문제가 있는지 확인하는 과정입니다.
- 운영배포: 운영배포 순서를 정확한 시간과 함께 기록합니다.
- 롤백시나리오: 문제가 발생했을 때 즉각행동할 수 있도록 롤백시나리오를 작성합니다.
위 템플릿에 맞추어 내용들을 작성하고 팀 내 공유를 합니다.
모니터링
이벤트를 받아 신규 Elasticsearch에 광고데이터를 적재 및 수정하는 worker를 먼저 배포한 상태에서 첫 광고데이터적재 배치를 저녁시간에 수행합니다. 이 때까지는 운영에 큰 문제가 없습니다. 저장된 클러스터가 트래픽을 받고 있지 않기 때문인데요. 그럼에도불구하고 구 클러스터의 데이터와 신규 클러스터의 데이터가 싱크가 맞는지 계속해서 모니터링해야 합니다. 처음에는 수동으로 검증을 하려고했으나 규칙적으로 확인하기가 어렵고 새벽시간에도 싱크가 맞는지 확인을 해야하는데 현실적으로 힘들다고 판단했습니다. 이에 따라 매 분마다 모니터링을 할 수 있게 배치를 하나 구성하고 광고상품별 count가 신규 Elasticsearch와 구 Elasticsearch에서 차이가 나면 곧바로 slack 알람을 받을 수 있게 설정하였습니다.
모니터링 할 내역은 노출 불가시 상대적으로 큰 타격을 입을 수 있는 월간 결제 상품, 성과형 광고 위주로 봐야한다고 생각했고 아래와 같이 선정하였습니다.
- 캠페인 타입별 개수(울트라콜, 오픈리스트 등..)
- 성과형 캠페인 개수
- Elasticsearch 버전 이슈로 다르게 인덱싱되는 필드 개수
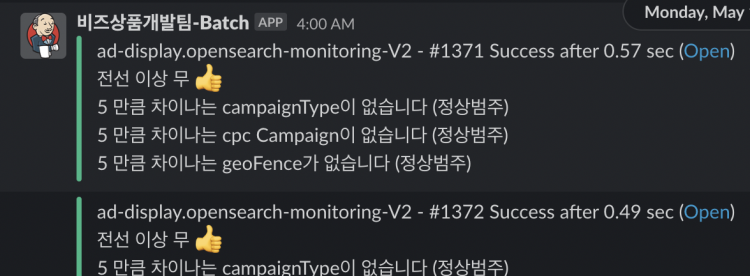
또한 신/구 클러스터별로 지면별 API 응답을 비교해 차이가 있는지 확인하였고 API 서버는 카나리 배포로 안전하게 진행하였습니다.
결과
크게 아래와 같은 두 가지 성과가 있었습니다.
- 개발자 운영 리소스 절감 및 운영환경 리스크 감소
- AWS의 기술지원과 Elasticsearch 소프트웨어 업데이트 등을 간편하게 지원받을 수 있게 되었고 수동 scale in/out에 대한 부담감과 리스크를 없앨 수 있었습니다.
- 서버 비용 축소
- 구축형으로 master, indexer, data, search노드들을 모두 관리하는 비용에서 AWS opensearch를 사용함에 따라 master, data노드만을 운영하게되었고 성능테스트를 통해 장비스펙을 최적화하여 월간 운용비용을 약 40%정도 감소시켰습니다.
중간중간 상세한 과정을 생략하고 주요한 부분만 요약해서 설명드렸는데요, 배민리스팅광고개발팀에서는 이외에도 배달의민족 앱 내에서 변화를 만들 수 있는 재밌고 다양한 프로젝트들이 있습니다.
관심 있는 분들은 우아한인재영입 사이트에서 자세한 내용을 확인하실 수 있습니다. 🙂
