[배민스토어] 우리만의 자유로운 WebFlux Practices
혹시 배민에서 음식 말고 다른 것들을 주문해 보신 적 있나요?
배민은 각종 전자기기부터 꽃, 화장품, 건강기능식품 등을 배달 받아볼 수 있는 배민스토어 서비스를 운영하고 있습니다.
얼마 전 배민스토어가 개편되면서 지역에서 품질 좋은 꽃이나 정육 등을 판매하는 사장님들도 입점할 수 있게 되었습니다.
이때 화면도 개편되었지만, 코드 차원에서도 아예 저장소를 새로 만들어서 대부분의 기능을 재개발하는 야심찬 공수를 들였는데요.
Spring MVC 기반에서 Spring WebFlux 기반으로 코드를 재작성하면서 겪은 여러 가지 시행착오 경험을 공유하고자 합니다.
특히 WebFlux를 도입하면서 접근성 높은 한국어 자료가 많이 없다는 것을 뼈저리게 느꼈습니다.
이 글에서는 WebFlux 코드를 작성하면서 어느 정도 공감하게 되었던 관례(Practice)들을 공유하고자 합니다.
처음 WebFlux를 도입하시는 분들에게 조금이나마 도움이 되었으면 좋겠습니다.
그럼 왜 WebFlux를 도입하게 되었는지부터 소개하겠습니다.
WebFlux를 도입하게 된 이유
배민스토어 4월 개편 당시에 WebFlux를 도입하게 된 데에는 여러 가지 배경이 있는데요.
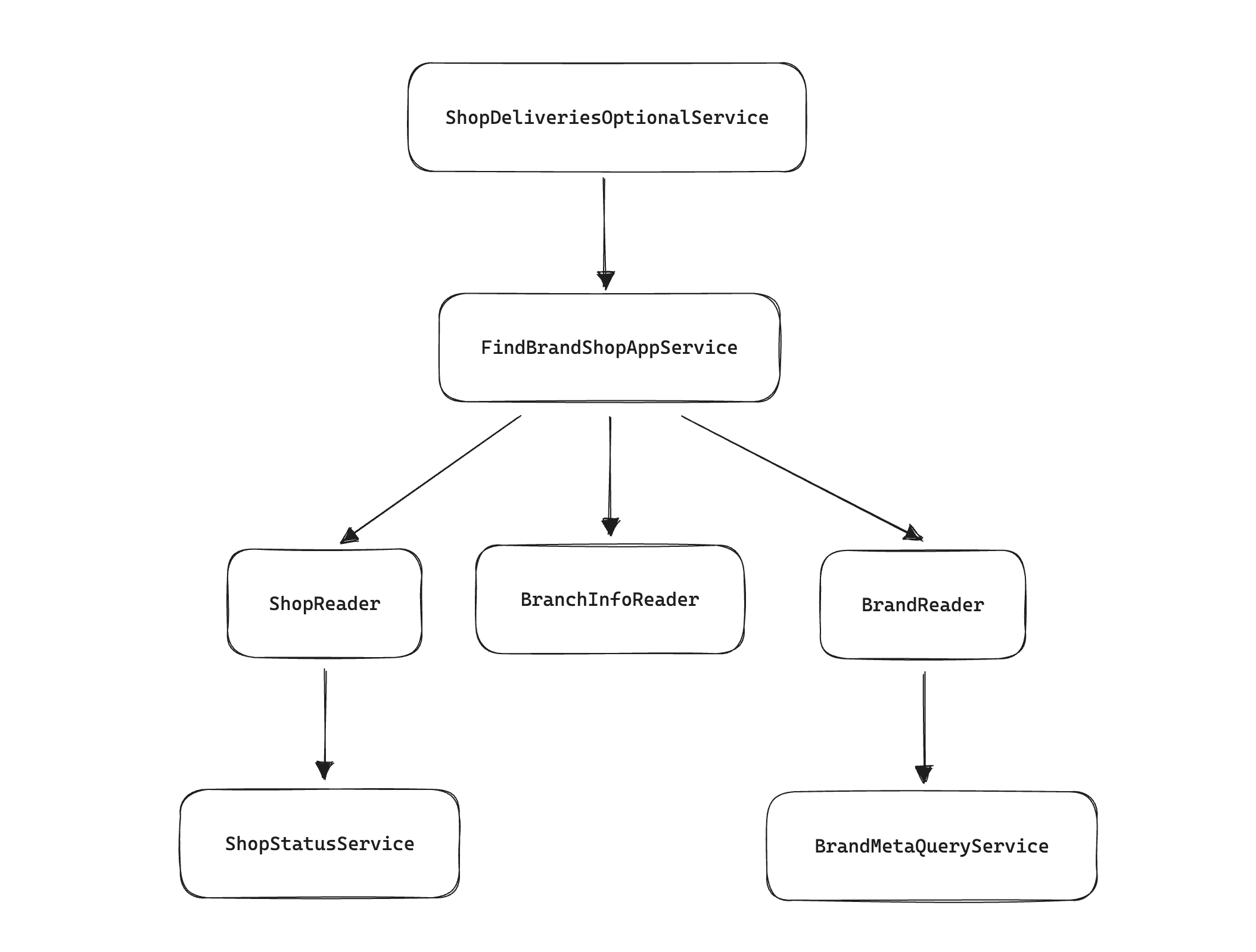
우선 배민 앱 화면에 보일 정보를 만드는 ‘전시 API’를 담당하는 팀이
외부 API 연동/셀러정보/어드민 등을 담당하는 팀과 나뉘어 있던 점도 중요한 배경이었습니다.
전시 API를 담당하는 팀은 비교적 신생 팀이었고, 기존 코드를 유지 보수하는 데 상당한 부담을 느끼고 있었어요.
기존 코드는 같은 계층 안에서 서비스들이 복잡하게 서로를 호출하고 있었고,
따라서 특정 코드를 수정할 때 프로젝트 전체에 얼마나 파급력을 미칠지 파악하기가 어려웠습니다.
계층의 경계도 엄격하지 않아서 서비스에서 리더를 호출하면, 리더가 또 다른 서비스를 호출하는 경우도 있었고요.
게다가 기존의 레거시 API를 유지해야 하면서도 짧은 기간 안에 프로젝트를 진행하다 보니,
특정 API에는 페이지네이션을 도입하지 못해서 전체 결과를 한꺼번에 전달하거나,
Elasticsearch 기반의 사내 검색플랫폼을 도입하지 못해서 RDB에서 LIKE 검색을 사용하는 등 성능 개선의 측면에서 한계점이 많았습니다.
그 결과 기존 배민스토어 홈의 API 응답 속도는 고객이 체감할 만큼 느린 상태였고
상품 검색은 고객이 원하는 수준의 결과를 내지 못하는 데다,
성능 문제로 인해 최대 100개의 상품까지밖에 검색하지 못하는 상황이었습니다. 🥲
여러모로 기존 API 및 코드를 유지하기 어렵겠다고 생각해
4월 서비스 개편에 맞춰서 새로운 버전의 API를 만들고, 코드도 새로 작성하기로 마음을 먹었습니다.
그리고 이때 어떤 기술을 도입할지를 결정해야 했었어요.
당시 가장 기술적으로 해결하고 싶었던 문제는
배민스토어 홈에서 외부 API를 7~8개씩 호출하면서 데이터를 모아 응답을 구성하는 부분이었습니다.
배민스토어 홈 API 하나가 화면에 있는 모든 섹션의 데이터를 전달해야 하니 응답 구조가 너무 컸던 게 1차적 문제였지만,
외부 API를 이렇게 많이 호출하는 상황에서는 순차적으로 호출하고, 기다리고, 모든 데이터를 받은 뒤에야
사용자에게 전달할 응답을 구성하는 비효율적인 과정이 지연을 유발할 수 있겠다고 생각했습니다.
따라서 자연스럽게, I/O가 일어나는 상황에서 응답을 기다리지 않고 다른 처리를 진행할 수 있다면 성능 개선이 가능할 거라고 생각했던 것 같습니다.
여기서 사실 "WebFlux를 도입하지 않고도, API를 나누면 되지 않을까?"라고 물으신다면 어느 정도는 맞는 얘기라고 생각합니다. 😅
Spring MVC로도 얼마든지 좋은 서비스를 만들 수 있다는 데 의심의 여지는 없는데요.
다만 전시개발팀으로서 앞으로 배민스토어에 놓인 과제를 해결하다 보면 자연스럽게 연동해야 할 플랫폼도 늘어나게 되고,
그러다 보면 서버가 외부 API를 호출하고 스레드를 놀리면서 응답을 기다리는 시간도 점차 늘어날 거라고 생각했습니다.
개편 과정에서 기존의 검색 기능에 사내 검색플랫폼을 도입해 완전히 새로 만든 것처럼,
배민스토어는 점차 사내의 여러 플랫폼을 도입하면서 다양한 API를 호출하게 될 거라고 생각했어요.
거기에 Redis + DynamoDB로 저장소 구조를 결정하면서,
두 저장소들이 논 블로킹 API를 제공한다는 것도 감안하게 되었습니다.
RDB를 메인으로 사용했다면 기본적으로 JDBC가 블로킹이라는 게 허들이 되고,
그렇다고 해서 R2DBC를 도입하기에는 아직 전사적인 경험이나 가이드가 부족할 것 같아
결국 WebFlux를 도입하지 않았을 가능성이 높을 것 같은데요.
RDB를 저장소로 사용하지 않는 구조를 택하면서
WebFlux의 성능상 이점을 잘 활용할 수 있는 환경이 만들어졌다는 것도 도입의 큰 이유가 되었습니다.
그리고 솔직히 말하자면 전시개발팀이기 때문에 WebFlux를 도입하자고 해도 받아들일 수 있을 거라는 생각을 했습니다.
WebFlux는 러닝 커브가 높은 기술인데요. 이 러닝 커브를 넘어가려면 개발자에게도 기술적으로 도전하고픈 동기가 있어야 하지 않을까 싶습니다.
배민에는 WebFlux 도입을 통해 다량의 트래픽을 처리하고 있는 가게노출 시스템이 존재하기 때문에 기술적으로 큰 자극이 되었던 것 같습니다.
요약하자면 (현시점에서는) Spring MVC로 구현해도 문제는 없는 서비스이지만 향후 서비스가 성장했을 때 성능에서 이점을 얻을 수 있다는 것,
그리고 팀원들 모두가 기술적으로 도전하고 싶은 패기(?)가 있어서 WebFlux 도입이 이루어졌다고 생각합니다.
그렇지만 WebFlux를 도입하는 과정은 쉽지 않았습니다.
험난한 도입 과정
저는 이전에 쇼핑라이브에서 채팅을 만들면서 WebFlux를 이미 도입했었고, 좋은 성능을 얻었던 경험이 있었는데요.
이 경험을 바탕으로 WebFlux를 도입하자는 의견을 냈고, 자연스럽게 팀 스터디를 진행하는 역할을 맡게 되었습니다.
스터디를 통해서 팀원들이 WebFlux에 익숙해지고, 대부분의 비즈니스 로직을 무리 없이 작성하도록 만드는 것이 제 목표였습니다.
하지만 스터디를 진행한다고 하면 스터디 자료가 있어야겠죠.
특히 프로젝트를 시작하던 2월 당시에는 Kotlin도 낯설었기 때문에 Kotlin 스터디와 WebFlux 스터디를 병렬로 진행해야 했습니다.
가뜩이나 공부할 것이 많은 상황에서 팀원들이 스터디를 따라오게 하려면 한국어 자료가 필수라고 생각했어요.
하지만 당시에는 서점에서 WebFlux만을 다루는 한국어 책이 보이지 않았습니다.
(운명의 장난처럼 팀이 개편을 마무리한 4월 말이 되어서야 책이 한 권 나왔고요… 🥹)
개인적으로 Project Reactor의 홈페이지에 있는 튜토리얼이 상당히 좋은 자료라고 생각했어요.
직접 코드를 작성해 보고 테스트를 통해 검증받는 과정에서 연산자의 쓰임새도 빠르게 감을 잡을 수 있고,
테스트를 하나하나 성공시키는 과정도 재미있다고 생각했습니다.
하지만 영어였죠.
결국 대안이 없었기 때문에 해당 튜토리얼을 직접… 한 땀 한 땀 번역해서 스터디 자료로 사용했습니다.
이때 스터디 자료의 접근성을 어떻게 높일까 하다가, JetBrains에서 제공하는 Kotlin Koans를 흥미롭게 했던 기억이 떠올라서
이런 교육 자료를 만들 수 있는 JetBrains Academy(구 EduTools) 플러그인을 사용했습니다.
그 결과 원래 튜토리얼의 내용 및 형식은 손상시키지 않으면서, 팀원들이 익숙해하는 IntelliJ IDEA 환경에서 자료를 제공할 수 있었습니다.
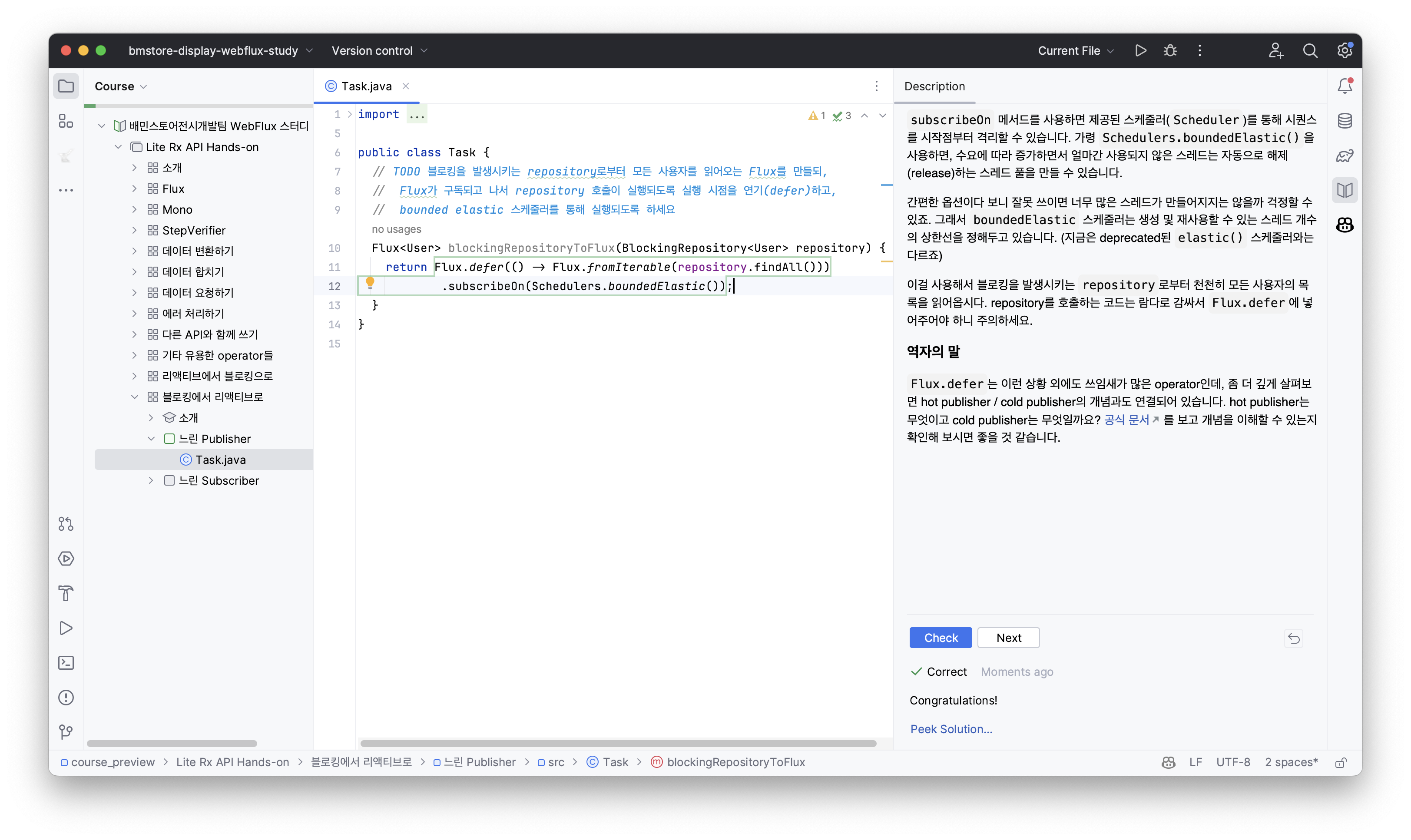
이걸 가지고 1주 차에 기본적인 연산자 및 개념을 학습한 뒤, 2주 차에는 간단한 핸즈 온 워크숍을 진행했고,
이후에는 각자 코드를 작성해 보면서 생긴 궁금증을 해결하는 Q&A 시간을 지속적으로 가졌습니다.
원래 Q&A보다는 좀 더 알찬 내용으로 스터디를 진행하고 싶었지만… 업무를 진행하면서 교육 자료를 구성하는 일이 쉽지 않았습니다. 🥲
따라서 제가 조금이나마 더 알고 있는 스킬이나 노하우를 팀원들과 공유하는 게 최선이라는 생각이 들었고,
“내가 하고 싶은 게 있는데, 이걸 어떻게 파이프라인으로 구성해야 원하는 동작이 나올까?”를 팀원들로부터 듣고 같이 고민하고 해결하는 데 집중했습니다.
Q&A는 주에 한 번 정도 정기적으로 시간을 만들었었고, 그 외 시간에도 질문이 생기면 수시로 슬랙 허들을 열어놓고 같이 고민해 보았습니다.
(마침 슬랙을 메신저로 쓰고 있었기 때문에, 팀 채널에서 간단하게 음성 회의를 할 수 있는 허들이라는 기능을 많이 활용했습니다. 😁)
그 과정에서 저도 WebFlux에 대해서 배우는 게 많았습니다.
제가 기존에 사용했던 연산자들이 팀원들이 겪는 문제에 적용되지 않는 상황을 자주 겪으면서 저 자신도 WebFlux를 충분히 모른다는 것을 느꼈고요.
Mono나 Flux의 Javadoc을 전체적으로 몇 번 훑어보면서 생소한 연산자도 머릿속에 넣어두려고 노력했고,
그 결과 알고 있던 연산자이지만 몰랐던 오버로드를 알게 된다거나, 알고 있던 연산자의 새로운 쓰임새를 알게 되기도 했습니다.
이런 것들은 팀 채널에서 몇 번 공유했었는데, 생각보다 많이 호응해 주시고 코드에 적용해 주셔서 감사했습니다.
여러모로 팀원들도 그렇지만 저도 많이 WebFlux에 대해 알아갔던 것 같고,
지금 생각해 보면 어떤 자료로 스터디를 진행했더라도 이런 Q&A 시간이 없으면 기술적인 성장이 어려웠을 것 같다고 생각합니다.
다만 적절한 자료가 없다 보니 팀원들이 시행착오를 많이 겪게 된 것은 안타까웠고,
동작하지 않는 코드를 쓰면서 헤매는 상황에서는 미안한 마음도 들었습니다.
각종 시행착오들
어떤 기술이든 그렇겠지만 API에 대한 이해가 부족하면 버그로 고생하는 경우가 많습니다.
WebFlux 도입 초반에는 이런 시행착오를 겪으면서 팀원들이 고생했었고, 종종 A/S 기사처럼 끼어들어서 같이 문제를 봐주곤 했는데요.
가장 흔한 시행착오는 zip()과 관련된 것이었습니다. 설명을 위해서 예를 하나 들어 볼게요.
배민스토어에는 본사(seller)와 지점(shop)이 1:N 관계로 구성되어 있습니다.
이때 본사에 연결된 모든 지점의 정보를 가져온 뒤, 본사 정보와 지점 정보를 조합해 사용자에게 보여줄 수 있겠죠.
본사 정보를 가져오는 함수의 반환형은 Mono이고, 지점 정보를 가져오는 함수의 반환형은 Flux가 될 것입니다.
(부연 설명을 하자면… 프로젝트 리액터에서 Mono는 0~1개, Flux는 0~N개의 값을 내보내는 Publisher입니다.
본사 정보는 한 개이니 Mono, 지점 정보는 여러 개이니 Flux를 사용하는 것이 자연스럽겠죠.)
fun getSeller(sellerId: String): Mono<Seller> = sellerRepository.findById(sellerId)
fun getShops(shopIds: Collection<String>): Flux<Shop> = shopRepository.findAllByIds(shopIds)본사 정보에는 ‘삼성스토어’, ‘CU’와 같은 본사 이름이, 지점 정보에는 ‘송파점’, ‘방이헤리츠점’과 같은 지점 이름이 들어 있습니다.
이걸 합쳐서 ‘삼성스토어 송파점’, ‘CU 방이헤리츠점’으로 보여주고 싶습니다. 어떻게 코드를 작성해야 할까요?
Publisher를 조합하는 건 역시 zip()이라고 생각하면서 이렇게 코드를 작성하는 경우가 있습니다.
(실제 코드를 단순화해서 소개하고 있는 점 양해 부탁드립니다.)
getShops(shopIds)
.zipWith(getSeller(sellerId))
.map { (shop, seller) -> "${seller.name} ${shop.name}" }이렇게 작성하면 놀랍게도 지점이 한 개만 나오는 마법 같은 버그가 발생합니다.
이것은 zip() 연산자의 특성에 대해서 충분히 이해하지 못해 발생하는 실수인데요.
zip()은 3개의 Publisher를 넘기면 3개의 Publisher가 모두 한 개씩은 값을 내보내야 zip() 연산자도 한 묶음의 값을 내보냅니다.
만약 100개의 값을 내보내는 Publisher와 한 개의 값을 내보내는 Publisher를 zip()하면 한 개의 값만 전달받게 되는데요.
머리로는 "응 그렇지" 하며 알고 있지만 코드를 쓰다 보면 무심코 이렇게 써버리고는 부랴부랴 버그를 수정하는 경우가 생깁니다.
안타깝게도 이렇게 쓴다고 해서 컴파일이 실패하거나 IDE에서 경고가 뜨지 않습니다.
타입상으로는 틀린 부분이 하나도 없기 때문에 개발자가 zip() 연산자에 대해서 이해도를 높여야 하고,
언제 어떤 연산자를 쓰는 게 좋다는 걸 알아나가야 이런 실수를 덜 할 수 있다고 생각합니다.
종종 발생하는 시행착오를 하나 더 살펴보자면, Kotlin 확장 함수를 잘못 쓰는 경우가 있습니다.
Kotlin 환경에서는 프로젝트 리액터에서 제공하는 확장 함수를 자연스럽게 사용하게 되는데요.
Flux.fromIterable(shopIds) -> shopIds.toFlux()코드를 줄일 수 있어서 편하지만 이것도 함수의 내부 구현을 잘 모르면 이상한 버그를 만나게 됩니다.
특히 WebFlux를 처음 도입할 때는 연산자에 대한 이해가 부족한 상태에서,
개발자 자신도 모르게 타입에 맞춰서 손 가는 대로 파이프라인을 짤 때가 있는데 정확하게 이 부분에서 실수가 발생합니다.
이것도 예를 들어 볼게요.
가령 상품의 정보를 담고 있는 이벤트를 메시지 큐로부터 받아서 DB에 저장하는 로직을 작성한다고 해 보겠습니다.
이 코드는 제대로 동작할까요?
fun mapToEntity(event: ProductEvent): ProductEntity
fun saveEventsToDB(events: Flux<ProductEvent>): Mono<ProductEntity> =
events
.flatMap { event ->
val entity = mapToEntity(event)
productRepository.save(entity)
}
.toMono()이렇게 작성하면 놀랍게도 이벤트가 몇 개 저장되다가 마는 현상이 일어납니다.
아마도 개발자는 이 코드를 쓰면서 이벤트가 전부 DB에 저장되고 나서 완료되는 파이프라인을 만들었다고 생각했을 겁니다.
하지만 Flux.toMono() 확장 함수의 구현은 Mono.from(flux)와 같고,
Mono.from() 정적 함수는 아규먼트로 전달된 Publisher의 첫 번째 값만 받아와서 Mono로 내보낸 뒤 업스트림에 대한 구독을 취소해 버립니다.
따라서 이벤트가 파이프라인에 들어오고, flatMap을 통해서 몇 개가 DB에 병렬로 저장되는 동안,
제일 먼저 저장된 값이 다운스트림으로 전달되면 그 즉시 구독이 취소되고 모든 처리가 멈추게 되는 것입니다.
개발자가 예상한 것과는 전혀 다른 동작이죠.
즉 Kotlin 환경에서는 Flux와 Mono의 연산자뿐 아니라, 사용 중인 확장 함수에 대해서도 내부 동작을 잘 이해하고 사용해야 합니다.
하지만 급하게 WebFlux를 도입해야 하는 입장에서는
개발자들이 레퍼런스 문서를 읽고, 사용하는 모든 연산자에 대해서 이해한 뒤 코드를 작성하는 것을 기대하기 힘들었습니다.
특히 마블 다이어그램은 (지금은 그렇지 않지만) 아무래도 생소하게 느끼는 경우가 많아서 몇 번 설명하기도 했는데,
마블 다이어그램에 정말 핵심적인 정보가 많기 때문에 이게 익숙해지지 않는 상황에서는 레퍼런스 문서도 읽기 어려워하는… 경우가 많았습니다.
이런 상황에서 프로젝트를 우선 진행해야 하다 보니,
우선은 안 되는 코드라도 작성한 뒤에 리뷰를 통해서 문제를 짚어내고 개선 방안을 같이 생각해 보는 경우가 많았습니다.
그 과정에서 파이프라인을 짤 때 나름의 안티 패턴이나,
“이렇게 사용하면 좋더라”와 같은 경험이 쌓였던 것 같고, 이게 어느 정도 팀 내의 관례 혹은 패턴으로 자리 잡게 되었습니다.
이런 관례는 가독성 측면에서 정한 것도 있고, 변경에 강한 코드나 안정적으로 작동하는 코드를 만들기 위해 터득한 것도 있는데요.
지금부터는 팀에서 코드 리뷰를 통해 자주 얘기했던 관례들을 몇 가지 소개해 보겠습니다.
(WebFlux의 기본 개념에 대해서는 분량상 생략하겠습니다.
혹시 궁금하신 분들은 프로젝트 리액터 홈페이지를 참고하시면 도움이 될 것 같습니다 😁)
배민스토어서비스개발팀의 WebFlux 관례
가독성
여기서는 가독성에 관련해서 바람직하다고 생각하는 관례들을 정리해 보았습니다.
파이프라인은 변수 말고 함수로 분리
파이프라인을 구성할 때에는 Flux, Mono를 반환하는 일련의 로직을 변수가 아니라 함수로 분리하는 걸 선호합니다.
즉 아래와 같이 변수를 할당해서 Flux, Mono를 저장하기보다는…
val seller = sellerRepository.findById(sellerId)
val shops = shopRepository.findAllByIds(shopIds)
Mono.zip(
seller,
shops.collectList(),
)함수를 호출하는 방식으로 로직을 분리하는 것을 더 선호합니다.
fun getSeller(sellerId: String): Mono<Seller> = sellerRepository.findById(sellerId)
fun getShops(shopIds: Collection<String>): Flux<Shop> = shopRepository.findAllByIds(shopIds)
Mono.zip(
getSeller(sellerId),
getShops(shopIds).collectList(),
)파이프라인을 변수로 분리하지 않는 가장 큰 이유는 변수의 이름이 마땅한 게 없다는 점에 있습니다.
가령 Mono<Seller>, Flux<Shop>의 이름을 어떻게 지을 수 있을까요?
위에서처럼 seller, shops라고 이름을 짓게 되면 변수를 사용할 때 헷갈릴 가능성이 높습니다.
seller의 타입은 Seller일까요? Mono<Seller>일까요?
shops의 타입은 Collection<Shop>일까요? Flux<Shop>일까요?
변수가 선언된 곳을 확인하지 않는 이상 seller의 타입을 알 수 있는 방법이 없고,
특히나 Kotlin 코드에서는 변수의 타입이 생략되는 경우가 많기 때문에 더욱 가늠하기가 어렵습니다.
이렇게 타입이 헷갈리게 되면 코딩에 방해가 될 가능성이 높다고 생각했습니다.
그렇다면 타입을 잘 알 수 있도록 sellerMono, shopsFlux라고 이름을 짓는 게 좋을까요?
타입을 변수의 이름에 명시하는 게 안티 패턴이라는 건 많이들 공감하는 부분인 것 같습니다.
Flux, Mono를 변수에 할당하면 이름을 짓기 애매해지는 이유는
이들이 파이프라인 안에서 사용되어야 하는 특수한 타입이라는 데에 있습니다.
변수를 사용하지 않고 대신 Flux, Mono를 리턴하는 함수들을 사용하게 되면,
개발자는 자연스럽게 “함수를 호출했으니 비동기적인 응답, Flux/Mono가 온다”는 것을 기대할 수 있고
타입을 따로 살펴볼 필요 없이 반환되는 Flux, Mono를 사용할 수 있을 거라고 생각했습니다.
다만 이 관례에는 한 가지 예외가 있는데요.
특정 Mono/Flux를 캐싱해 두고 파이프라인 하나에서 여러 번 구독해서 사용하는 경우입니다.
cache() 연산자를 사용하는 경우가 대표적인데요,
이런 경우에는 반환되는 Mono/Flux를 파이프라인에서 여러 번 참조해야 하기 때문에 어쩔 수 없다고 생각합니다.
val cachedSeller = sellerRepository.findById(sellerId).cache()flatMap() 지옥에서 벗어나는 방법: zipWhen()을 자주 활용하기
고객에게 데이터를 전달하기 위해서는 으레 여러 값들을 조합해야 하는 상황이 생깁니다.
값 A의 특정 필드를 통해 값 B를 가져오고, A와 B를 조합해서 값 C를 만들어야 하는 경우가 생기는데요.
이때도 개발자가 flatMap()으로 구현하려고 하는 경우가 많습니다.
shopRepository.findById(shopId)
.flatMap { shop ->
sellerRepository.findById(shop.sellerId)
.flatMap { seller ->
mapper.toDto(shop, seller)
}
}이렇게 의존 관계가 있는 값들을 모두 가져와서 사용해야 하는 경우 flatMap() 안에 flatMap()이 들어가는 경우를 쉽게 볼 수 있습니다.
두어 번 정도 들어가는 건 괜찮지만 세 번을 넘어가게 된다면 여기서부터는 flatMap() 지옥이라고 표현을 하고 있습니다.
(JavaScript의 콜백 지옥처럼… WebFlux에는 flatMap() 지옥이 생길 수 있다는 것을 표현하기 위해 이름 붙여 보았습니다. 😅)
이런 경우에는 Mono.zipWhen()을 활용하면 어느 정도 도움을 얻을 수 있습니다.
zipWhen()이 어떤 연산자인지는 아마 코드를 보면 바로 아실 수 있을 것 같아요.
shopRepository.findById(shopId)
.zipWhen { shop -> sellerRepository.findById(shop.sellerId) }
.map { (shop, seller) ->
mapper.toDto(shop, seller)
}Mono<A>의 값을 활용하여 Mono<B>를 가져오고, 결과적으로 Tuple을 통해 A와 B의 값을 묶어 전달받을 수 있습니다.
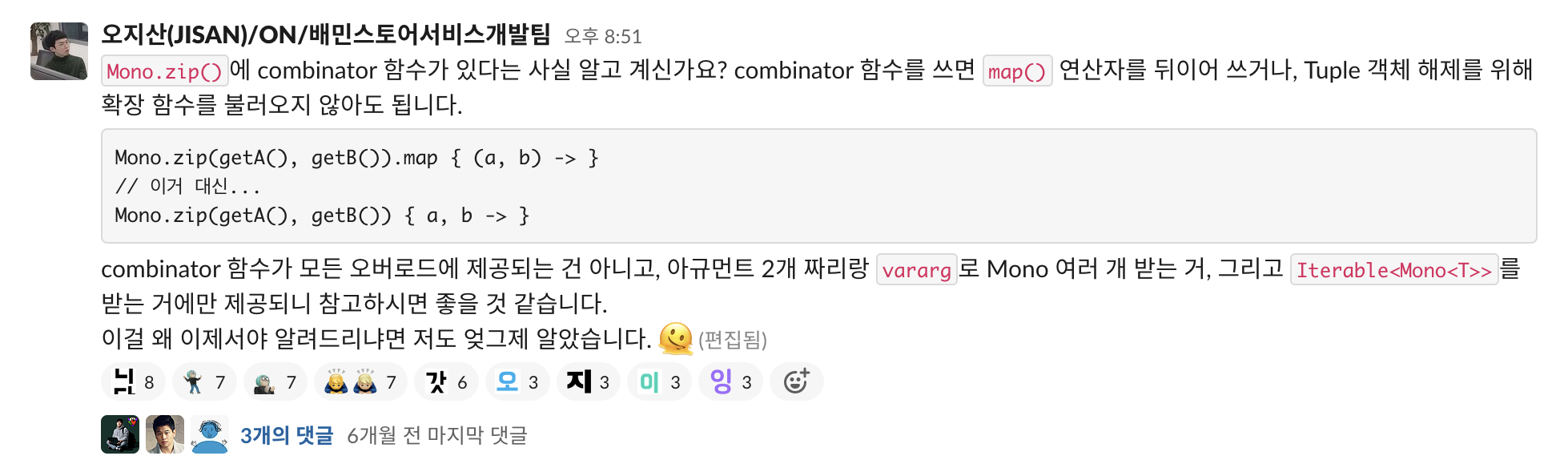
특히 zipWhen은 combinator를 받는 오버로드가 있기 때문에 여기 있는 map() 연산자는 생략할 수도 있습니다.
shopRepository.findById(shopId)
.zipWhen({ shop -> sellerRepository.findById(shop.sellerId) }) { shop, seller ->
mapper.toDto(shop, seller)
}람다 두 개를 전달하다 보니 조금 산만하긴 하지만, 그래도 map() 연산자를 쓸 필요가 없어져서 자주 사용하는 오버로드입니다.
zipWhen()은 Mono만 조합할 수 있고, 게다가 Mono를 2개 조합할 때만 사용할 수 있기 때문에 활용 범위가 넓지 않지만,
필요할 때 사용하면 flatMap()을 조금이라도 덜 쓸 수 있어서 활용하는 것을 권장하고 있습니다.
값이 없을 때의 처리
Flux, Mono에 값이 없는 경우 기본값을 전달해야 하는 상황이 있습니다.
보통 이럴 때 switchIfEmpty()를 많이 사용하는데요.
shopRepository.findById(shopId)
.map { shop -> shop.name }
.switchIfEmpty("알 수 없는 지점".toMono())기본값을 비동기적으로 가져오는 상황이 아니라면 defaultIfEmpty()를 쓰는 게 더 간결하기 때문에 추천하고 있습니다.
shopRepository.findById(shopId)
.map { shop -> shop.name }
.defaultIfEmpty("알 수 없는 지점")그리고 응답 객체를 만들 때 Flux의 값을 List로 만들어서 활용할 때가 많은데요.
이때 collectList() 연산자를 많이 사용합니다.
shopRepository.findAllByIds(shopIds)
.map { shop -> shop.name }
.collectList()
.map { shopNames -> ShopNameListRes(status = "OK", shopNames = shopNames) }그런데 collectList()에 defaultIfEmpty()와 같은 연산자를 조합해서 쓰는 경우가 있습니다.
shopRepository.findAllByIds(shopIds)
.map { shop -> shop.name }
.collectList()
.defaultIfEmpty(emptyList())
.map { shopNames -> ShopNameListRes(status = "OK", shopNames = shopNames) }collectList()는 Flux에 값이 없으면 빈 리스트를 전달하는 연산자이기 때문에 이러한 처리는 불필요합니다.
Collect all elements emitted by this Flux into a List that is emitted by the resulting Mono when this sequence completes, emitting the empty List if the sequence was empty.
이렇듯 연산자를 이해할 때는 마블 다이어그램뿐 아니라 설명에도 중요한 사항들이 많이 있으니 참고할 만합니다.
값이 없을 때의 처리에 대해서 하나만 더 얘기해 보면, 에러 처리랑 조합했을 때 중복 코드가 생기는 경우가 있습니다.
가령 어떤 데이터를 우선 캐시에서 가져와보고, 값이 없거나 에러가 발생할 때 DB에서 가져오도록 처리할 수 있는데요.
shopCacheRepository.findById(shopId)
.onErrorResume { shopDBRepository.findById(shopId) }
.switchIfEmpty { shopDBRepository.findById(shopId) }이러면 두 처리가 중복 코드를 발생시키죠. 특히 배민스토어는 에러 상황에서의 폴백과 값이 없는 상황에서의 폴백이 동일한 경우가 많았습니다.
여기서 중복을 없애려면 에러가 발생한 경우 값이 없는 Mono로 처리하면 되겠죠.
그리고 값이 없는 상황에서의 폴백만 남기면 두 가지 경우에 대해서 모두 폴백이 작동될 수 있습니다.
Mono에서는 보통 onErrorComplete()으로 처리하면 무리가 없는 것 같았습니다.
덤으로 onErrorComplete()가 중요한 에러를 숨기는 일이 없도록, 폴백 처리를 하기 전에 에러 로그를 남기는 것을 권장하고 있습니다.
shopCacheRepository.findById(shopId)
.doOnError { e -> log.error("Received error on shop cache.", e) }
.onErrorComplete()
.switchIfEmpty { shopDBRepository.findById(shopId) }Kotlin 확장 함수를 적극 사용
Kotlin 환경에서는 아무래도 코루틴이 잘 어울리기는 합니다. 😅 그러다 보니 Kotlin + WebFlux 조합에 대해서 어떻게 생각하실지 모르겠지만…
개인적으로는 Java보다 Kotlin에서 WebFlux를 훨씬 편하게 사용했던 것 같습니다. 다양한 확장 함수가 존재한다는 것도 그 이유 중 하나입니다.
기본적으로 toMono(), toFlux()를 사용해서 웬만한 값들을 Mono나 Flux로 변환할 수 있습니다.
T.toMono() -> Mono.just(T)
T?.toMono() -> Mono.justOrEmpty(T)
Throwable.toMono() -> Mono.error(Throwable)
List<T>.toFlux() -> Flux.fromIterable(List<T>)각종 타입에 맞게 확장 함수가 만들어져 있어서 코드를 좀 더 편하게 작성할 수 있습니다.
특히 nullable한 타입을 적당히 empty Mono로 바꿔주는 것도 참 마음에 드는 부분입니다.
테스트와 관련해서도 StepVerifier.create()를 매번 작성할 필요가 없어지는 데에서 오는 간결함이 좋았습니다.
StepVerifier.create(Flux) -> Flux.test()그리고 zip()과 함께 사용할 수밖에 없는… Tuple의 경우에는 componentN()이 확장 함수로 준비되어 있어서,
거의 필수로 import하면서 객체 해제에 사용했던 것 같습니다. 만약 요게 없었다면 가독성에서 큰 손해를 봤을 것 같네요.
import reactor.kotlin.core.util.function.*
Mono.zip(getA(), getB())
.flatMap { (a, b) -> … }안정성
여기서는 주로 이벤트 처리 로직에서 안정성을 높이기 위해 지켰던 관례들을 적어 보았습니다.
값의 처리에는 then(), and(), delayUntil()을 사용
이벤트를 처리하다 보면 하나의 이벤트를 가지고 여러 처리를 실행해야 하는 경우가 종종 있습니다.
가령 상품 등록 이벤트를 받으면 그걸 DB에 저장하고 나서 캐시에 저장해야 할 수 있습니다.
이때 개발자가 무심코 flatMap()을 사용해서 모든 처리를 작성하려고 하는 경우가 있는데요.
fun saveToDB(event: ProductEvent): Mono<ProductEvent> =
productDBRepository.save(toEntity(event))
.thenReturn(event)
fun saveToCache(event: ProductEvent): Mono<ProductEvent> =
productCacheRepository.save(toCacheObject(event))
.thenReturn(event)
fun process(event: ProductEvent): Mono<Void> =
saveToDB(event)
.flatMap { saveToCache(event) }
.then()flatMap()이 아무래도 가장 만만하지 않습니까?
이렇게 작성해도 돌아는 가지만… 이런 코드는 변경에 상당히 취약하다고 생각합니다.
여기서 가장 문제가 되는 부분은 각각의 처리를 담당하는 함수들이 입력값을 그대로 반환하지 않으면 망한다는 점입니다.
누군가 로직을 수정하면서 입력값을 돌려주는 부분을 지워버렸다면 어떻게 될까요?
fun saveToDB(event: ProductEvent): Mono<Void> =
productDBRepository.save(toEntity(event))
fun saveToCache(event: ProductEvent): Mono<Void> =
productCacheRepository.save(toCacheObject(event))컴파일 오류는 나지 않습니다. 하지만 saveToDB()는 이제 아무 값도 내보내지 못하기 때문에,
뒤이어 오는 flatMap()을 실행할 수 있는 값이 사라지게 되고 결국 캐시 저장 로직은 절대 실행되지 않게 됩니다.
문제의 핵심은 함수를 호출하는 외부 사정에 의해서 함수의 구현이 영향을 받고 있다는 점입니다.
외부 사정을 모르는 누군가가 잘못 수정해 버리면 금방 고장이 날 수 있는 코드가 되겠죠.
flatMap()은 값을 변환하는 데에 사용하도록 만들어진 연산자라고 생각합니다.
따라서 만약 DB 저장 로직이 Entity를 반환하고 나서, 그 Entity로 캐시 저장 로직이 실행되어야 한다면
flatMap()을 사용하는 게 자연스럽습니다. 이 경우는 캐시 저장 로직이 DB 저장 로직에 의존하는 상황이라고 볼 수 있겠죠.
하지만 서로 간의 의존 관계가 없는 로직들을 실행할 때는 굳이 flatMap()으로 모든 것을 처리할 필요가 없습니다.
이것도 WebFlux를 도입한 초반에 발생했던 안티패턴인데요.
여러 가지 연산자를 알아나가다 보면, 예전에 무작정 flatMap()으로 처리했던 것들을 더 적절한 연산자로 처리할 수 있게 되는 것 같습니다.
가령 DB에 저장하고 나서 캐시를 저장하도록, 순차적으로 실행해야 한다면 then()을 쓰는 게 간단하겠죠.
saveToDB(event).then(saveToCache(event))DB와 캐시에 저장하는 순서가 중요하지 않고, 병렬로 저장해도 된다면 Mono.and()도 좋을 것 같습니다.
(3개 이상을 실행해야 한다면 Mono.when()도 써볼 만할 것 같네요)
saveToDB(event).and(saveToCache(event))그런데 만약 입력값을 반환할 수밖에 없는 경우는 어떻게 해야 할까요?
가령 DB에 저장한 뒤 그 Entity를 가지고 캐시를 저장하되, 최종적인 반환값은 Entity가 되어야 하는 경우를 가정해 보겠습니다.
fun saveToCache(entity: ProductEntity): Mono<Void> =
productCacheRepository.save(toCacheObject(entity))
fun process(event: ProductEvent): Mono<ProductEntity> =
saveToDB(event)
.flatMap { entity ->
saveToCache(entity).thenReturn(entity)
}이렇게 할 수는 있지만 좀 번거롭죠. delayUntil()을 쓰면 코드를 조금 줄일 수 있습니다.
delayUntil()은 원래 Flux/Mono의 값이 전달되는 시점을 다른 Publisher가 실행되는 동안 지연시키는 역할을 하는데,
“캐시에 저장하고 돌아오세요~”라는 의미로 생각하면, 이런 유즈케이스에도 잘 어울리는 것 같다고 느꼈습니다.
fun process(event: ProductEvent): Mono<ProductEntity> =
saveToDB(event)
.delayUntil { entity -> saveToCache(entity) }이벤트 처리 시에는 배압 조절되는 연산자만 사용
오픈 직전에 이벤트 처리 로직을 작성하면서 가장 골머리를 앓던 문제를 소개해 드리고자 합니다.
배민스토어는 상품 저장 및 수정 시점에 카프카를 통해 시스템 간에 이벤트를 전달하고 있습니다.
배민스토어에 입점한 셀러들은 상품의 대량 등록 및 수정이 잦기 때문에 이벤트가 몰리는 상황이 많은데요.
이때 이벤트를 몇백 건 정도로 묶어서 처리하면서 어느 정도 부하를 줄이고 있습니다.
전시에서는 당시에 이벤트를 500건 정도로 묶어서 처리하기 위해 bufferTimeout()과 같은 연산자를 사용했었습니다.
(카프카를 통해 무한히 이벤트가 들어오는 Flux에서 buffer()를 사용하게 되면,
이벤트가 소강상태일 때 버퍼 사이즈가 다 채워지지 않아 다운스트림에서 버퍼를 오랫동안 전달받을 수 없는 문제가 생깁니다.
따라서 버퍼에 시간제한을 두는 bufferTimeout()을 사용했었습니다.)
fun process(events: Flux<Event>): Mono<Void> =
events
.bufferTimeout(500, Duration.ofMillis(500))
.flatMap { buffer -> process(buffer) }
.then()보시는 것처럼 버퍼는 이벤트 500개를 모으거나 500ms가 지나는 시점에 처리됩니다.
이렇게 코드를 작성하고 나니 OverflowException이 자주 발생했는데요.
처음에 에러를 인지했을 때는 버퍼 사이즈 문제일까? 혹은 타임아웃 시간이 짧아서 발생하는 문제일까? 등을 고민하면서
두 값을 열심히 조정했습니다. 하지만 에러가 없어지지는 않았죠.
그러다 bufferTimeout(maxSize, maxTime)이 배압을 제대로 처리하지 못한다는 것을 알게 되었습니다.
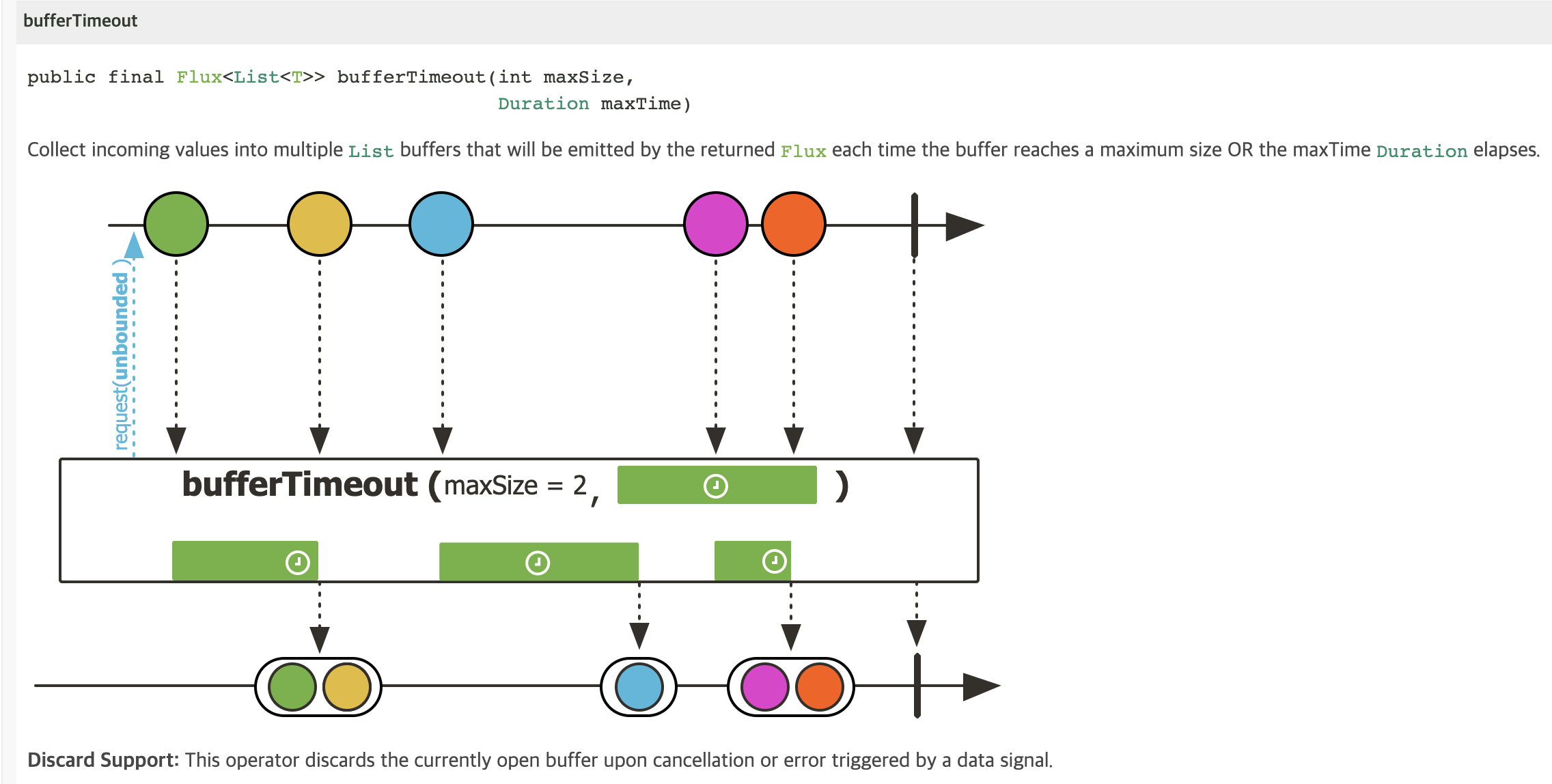
마블 다이어그램을 보면 request(unbounded)라고 쓰여 있죠.
즉 bufferTimeout(maxSize, maxTime)은 업스트림에 무한한 request를 보내서 값을 있는 대로 다 받고 버퍼를 내보내는 연산자입니다.
업스트림에서 값을 있는 대로 받아오다 보니 버퍼의 크기가 계속 불어날 수밖에 없는데요.
하지만 Reactive Streams의 개념상 Subscriber의 request()가 있어야 bufferTimeout도 Publisher로서 버퍼를 내보낼 수가 있습니다.
만약 버퍼가 maxSize 혹은 maxTime 조건을 달성해서 다운스트림으로 전달되어야 하는 상황인데,
다운스트림에서 request()를 충분히 하고 있지 않다면 어떻게 될까요?
이때 bufferTimeout(maxSize, maxTime)이 OverflowException을 발생시킵니다.
따라서 OverflowException이 발생하지 않도록 업스트림의 값을 다운스트림에서 요청하는 만큼만 적절하게 받아오는,
즉 배압을 고려하는 연산자가 필요한데요.
최근 추가된 fairBackpressure 파라미터를 사용하면 이렇게 배압을 고려한 버퍼 처리가 가능해집니다.
fun process(events: Flux<Event>): Mono<Void> =
events
.bufferTimeout(500, Duration.ofMillis(500), true) // fairBackpressure를 활성화
.flatMap { buffer -> process(buffer) }
.then()팀에서 4월에 reactor-core 3.5.1 버전을 쓸 때만 해도, windowTimeout()에만 이 파라미터가 있었습니다.
그 때문에 배민스토어는 windowTimeout()과 buffer()를 조합하는 식으로 파이프라인을 구성했는데요.
얼마 전에 나온 3.5.7 버전에서는 bufferTimeout()에도 fairBackpressure 파라미터가 추가된 것 같더라고요. 😁
아무튼 windowTimeout(fairBackpressure = true)을 통해 배압을 조절하면서 버퍼를 만드는 쪽으로 코드를 수정했습니다.
그 후로는 OverflowException이 발생하지 않았고, 워커의 처리량대로 카프카 메시지가 알맞게 소비되는 것을 확인할 수 있었어요.
디버그 가능성
마지막으로 디버깅 팁 하나만 소개하고 글을 마무리하겠습니다.
로그는 파이프라인 안에서 남기기
WebFlux 코드를 처음 짜시는 분들에게 한 번은 말씀드리게 되는 부분인데요.
보통 처음에는 이렇게 로그를 남기시는 경우가 많습니다.
fun getSeller(sellerId: String): Mono<Seller> {
log.debug("셀러 조회 발생: {}", sellerId)
return sellerRepository.findById(sellerId)
}얼핏 보면 문제가 없어 보이는 코드이지만 사실 WebFlux의 파이프라인은 함수 호출 시점에 실행되는 것이 아닙니다.
함수가 호출되면 Flux 혹은 Mono가 생성될 뿐, 실제로 값이 흐르는 건 Flux/Mono가 구독되는 때부터죠.
즉 위의 로그는 Seller를 가져오는 시점이 아니라 파이프라인이 구성되는 시점에 찍히기 때문에 개발자를 혼란하게 만들 수 있습니다.
만약 개발자가 이 함수를 호출해 놓고 깜빡해서 Mono를 사용하지 않았다면 어떻게 될까요?
val seller = getSeller(sellerId)
Mono.zip(
getShop(shopId),
getDeliveryTime(shopId),
// 앗… 리팩토링하면서 getSeller() 호출이 필요 없어졌는데... 코드를 미처 삭제하지 못했네요.
)이러면 디버그 로그는 남지만 셀러를 가져오는 처리는 조금도 실행되지 않기 때문에,
의미 없는 로그를 가지고 오랫동안 디버깅을 해야 할지도 모릅니다.
따라서 로그를 남길 때에는 파이프라인 안에서 남기도록 강하게 권고하고 있습니다.
Flux/Mono의 구독이 시작될 때 로그를 남기려면 doFirst(), doOnSubscribe() 같은 연산자를 활용할 수 있어요.
fun getSeller(sellerId: String): Mono<Seller> =
sellerRepository.findById(sellerId)
.doFirst { log.debug("셀러 조회 발생: {}", sellerId) }성과 그리고 남아 있는 길
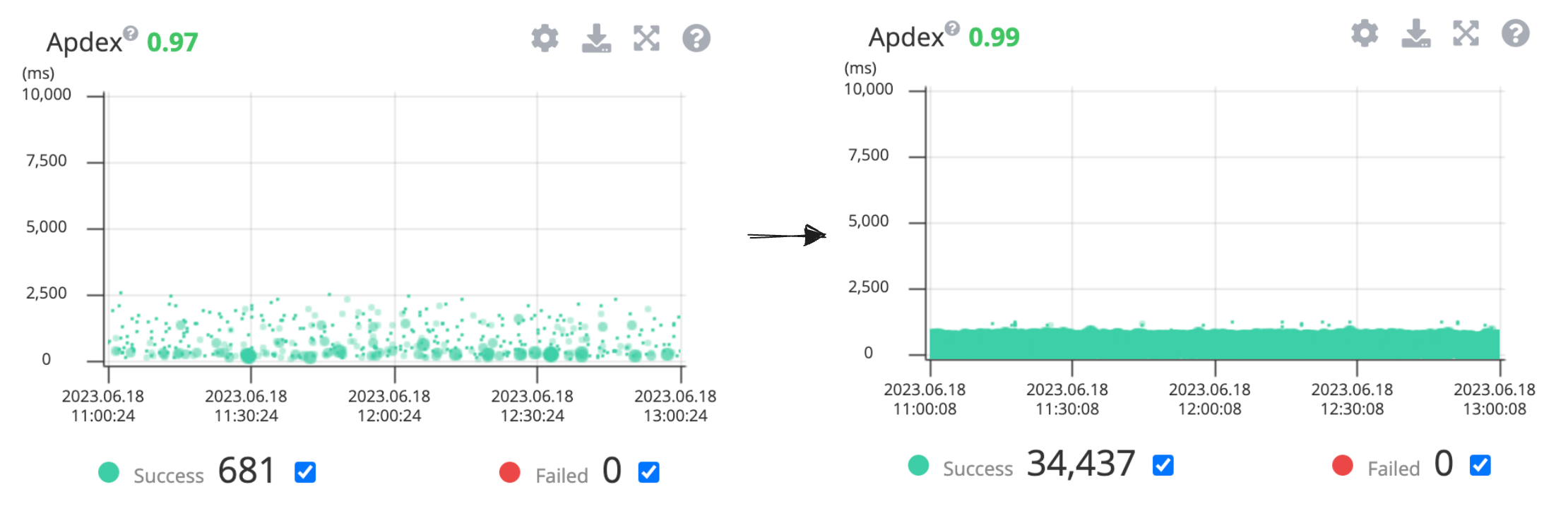
개편 이후 배민스토어는 응답 시간 및 성능이 좋아졌습니다.
6월 중순에 성능 테스트를 진행한 결과 응답 시간이 개선된 것을 확인했고요.
- 배민스토어 홈은 평균 응답시간 722ms에서 195ms로 73% 개선
- 특정 가게를 누르면 나오는 가게 홈 화면은 평균 496ms에서 152ms로 70% 개선
- 가게 홈 하단의 추천 상품 및 카테고리 영역은 평균 809ms에서 228ms로 72% 개선
다만 API 구조 및 표시되는 데이터가 같이 변경되었기 때문에 온전히 WebFlux 도입만으로 성과를 본 것은 아닙니다.
응답 시간 개선의 여러 요인 중 하나로 봐 주시면 좋을 것 같습니다.
성능 또한 내부적으로 만족할 만한 수준을 달성할 수 있었으며 서비스 성장을 뒷받침할 준비는 어느 정도 완료되었습니다. 😁
팀에서 사용 중인 APM에서도 좀 더 많은 양의 요청을 빠른 시간 안에 처리한다는 것을 확인할 수 있었고요.
사실 팀 단위로 짧은 시간 안에 WebFlux를 공부하고 도입하면서 경험을 쌓아 나가는 게 쉽지 않았습니다.
WebFlux 도입 과정에서 팀원들의 코드를 가능한 많이 보면서 트러블슈팅을 같이 하고, 개선점을 찾아보려고 했는데
그럼에도 불구하고 개편 오픈 직전에 보았던 팀원들의 잿빛 얼굴이 자꾸 떠오르면서 미안한 마음도 같이 듭니다.
실제 프로젝트에서 WebFlux를 적용해 본 저의 소감은…
WebFlux는 풍부한 연산자를 제공해서, 여러 비동기 로직의 실행 시점을 조율하기 쉽지만
한편으로 여러 데이터를 조합하는 상황에서는 생소한 API가 개발자의 발목을 잡을 가능성이 크다는 생각이 들었습니다.
그런 관점에서 코루틴과 WebFlux를 조합해서 사용하는 쪽에 관심을 보이는 팀원들도 제법 있습니다.
지금 팀에서 코루틴 스터디가 진행되고 있는데, 코루틴도 WebFlux처럼 깊게 사용해 보고 경험을 공유할 수 있는 기회가 다시 왔으면 좋겠네요. 💪
그리고 이 글이 WebFlux 도입을 고민하는 분들이나, 자료가 없어서 고생하시는 분들께 서툴게나마 도움이 될 수 있다면 기쁠 것 같습니다.
[배민스토어] 일반셀러 프로젝트 시리즈 더 보기