Spring Boot에서 S3에 파일을 업로드하는 세 가지 방법
안녕하세요. 세일즈서비스팀에서 전자계약서 시스템을 개발하고 있는 박민규입니다.
최근 저는 Spring Boot + Kotlin을 활용한 프로젝트에서 특별한 도전과제에 직면했습니다. 바로 최대 3GB의 파일을 안정적으로 업로드하는 기능을 구현하는 것이었습니다. 대용량 파일 업로드에는 다양한 고려 사항과 복잡성이 따르기 때문에 많은 고민이 필요했습니다. 그 과정에서 다양한 방법을 탐색하게 되었고, 대부분 아래 세 가지 방법에서 기술적으로 크게 벗어나지 않다는 것을 알게 되었습니다.
- Stream 업로드
- MultipartFile 업로드
- AWS Multipart 업로드
이 글에서는 위 세 가지 방법의 기술적 원리와 특징을 상세히 정리하였습니다. 이 글을 통해 여러분 프로젝트에 가장 적합한 방법을 선택하는 데 도움이 되시길 바랍니다. 🙂
기본 세팅
제가 담당하는 전자계약서 시스템은 AWS SDK for Java1.x를 사용하고 있기 때문에 AWS SDK for Java2.x 대신 AWS SDK for Java1.x로 예제 코드가 작성되었습니다. 예제 코드에서 사용되는 interface는 AWS SDK v2에서도 계속 지원하고 있으니, 이 문서를 참고하여 변환 후 작성하시면 같은 결과를 확인하실 수 있습니다.

먼저 프로젝트에 Dependency를 추가합니다.
// build.gradle.kts
dependencies {
...
implementation("com.amazonaws:aws-java-sdk-s3:1.12.174")
}그리고 AWS SDK에서 제공하는 S3 업로드 인터페이스를 빈으로 등록합니다.
@Configuration
class S3Config(
@Value("\${aws.s3.accessKey}")
private val accessKey: String,
@Value("\${aws.s3.secretKey}")
private val secretKey: String,
) {
@Bean
fun amazonS3Client(): AmazonS3 {
return AmazonS3ClientBuilder.standard()
.withCredentials(
AWSStaticCredentialsProvider(BasicAWSCredentials(accessKey, secretKey))
)
.withRegion(Regions.AP_NORTHEAST_2)
.build()
}
}아래 예제에서 사용되는 모든 amazonS3Client는 위에서 정의된 빈으로 사용됩니다.
Stream 업로드
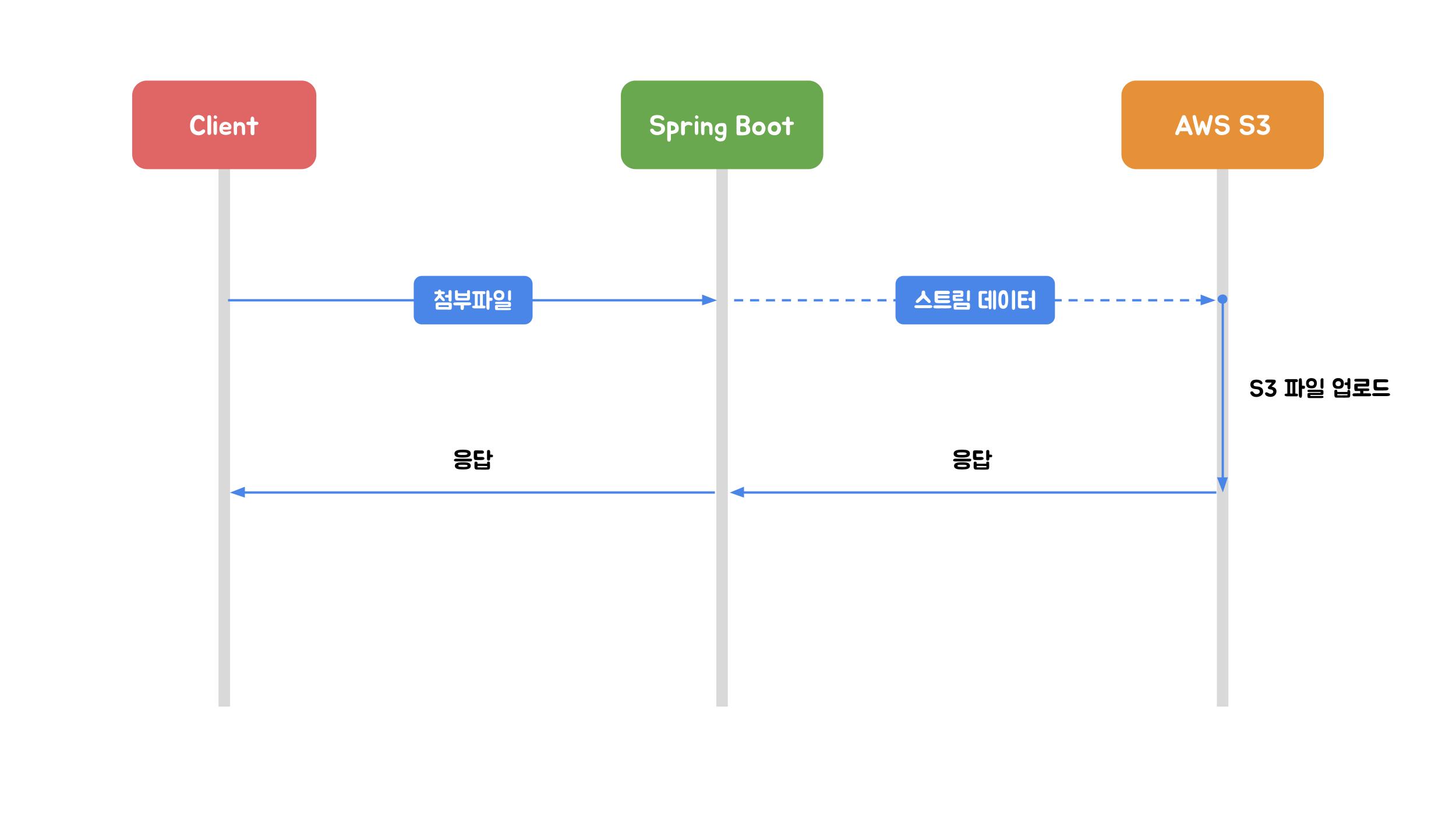
첫번째로 Stream 업로드는 HttpServletRequest의 InputStream을 이용하여 AWS S3에 다이렉트로 파일을 전송하는 방식입니다. 이 방식의 가장 큰 특징은 업로드할 파일의 바이너리 전체를 Spring Boot 애플리케이션을 실행하고 있는 서버의 디스크나 힙 메모리에 저장하지 않는다는 점입니다. 물론 업로드를 위해 파일의 청크를 메모리에 로드하기 때문에 약간의 메모리를 사용하게 됩니다.
그리고 애플리케이션 로직을 통해 모든 바이너리를 메모리에 로드하지 않는 이상 전 전처리(ex. 이미지 리사이징)가 불가능한 특징을 가지고 있습니다.
@PostMapping("/file/stream")
fun streamUpload(
request: HttpServletRequest,
) {
val metadata = ObjectMetadata()
metadata.contentType = request.contentType
metadata.contentLength = request.contentLengthLong
amazonS3Client.putObject("bucketName", "objectKey", request.inputStream, metadata)
}Stream 업로드 방식의 특징은 1회 API 호출에 1개 파일만을 업로드할 수 있습니다. 요청 본문 바이너리에서 여러 개 파일 데이터를 구분할 수 있는 기준이 없기 때문입니다.
위 예제 코드에서 ObjectMetadata 변수를 구성할 때 HTTP 요청 헤더에서 가져온 content-type과 content-length 값으로 설정합니다. 이 값은 AWS S3에 업로드될 객체 정보를 알리기 위한 용도입니다. 만약 Javascript 파일을 업로드하면서 content-type 헤더에 image/jpeg 값으로 요청을 보낸다면 AWS S3는 content-type 헤더가 JPEG 형식의 이미지 파일을 나타내지만 요청 본문의 이진 데이터가 해당 콘텐츠 유형과 일치하지 않는다는 것을 인식하여 업로드를 거부하게 됩니다.
이러한 Stream 업로드 방식은 파일을 업로드할 때 메모리에 큰 영향이 없어 대용량 업로드에 적합한 방법으로 보일 수 있습니다. 하지만 전혀 적합하지 않습니다. 업로드할 파일 용량이 커질수록 우리는 업로드 속도에 유의해야 합니다. 어쩌면 1GB 파일을 업로드하는 사용자가 컴퓨터 앞에서 10분을 기다려야 할 수도 있습니다.
따라서 대용량 파일 업로드로 Stream 업로드 방식을 채택하기 전 아래와 같은 사항을 고려하는 것이 좋습니다.
- 클라이언트 네트워크 환경, 클라우드 인스턴스 유형에 따라 업로드 속도 편차가 크기 때문에 운영환경과 동일한 인프라로 충분한 속도 테스트가 필요합니다.
- Stream 업로드 방식은 구조적으로 클라이언트에게 업로드 현황을 제공할 수 없습니다. 따라서 클라이언트가 기다릴 수 있을만큼 적당한 파일사이즈 제한이 필요합니다.
- 대용량 파일을 업로드 중 오류가 발생했을 때 전체 파일을 처음부터 다시 업로드해야하기 때문에 시간과 대역폭이 낭비될 수 있습니다.
실제 힙 메모리를 사용하지 않는지 확인하기 위해 Grafana를 이용하여 메모리 사용량을 모니터링하면서 용량이 큰 파일을 업로드 해보겠습니다. 만약 Spring boot 프로젝트가 Nginx를 통해 요청을 받고있다면 아래와 같은 설정이 필요합니다.
location /example/file/stream {
client_max_body_size 1000M;
}이제 메모리 사용여부를 명확하게 확인하기 위해 약 1GB 정도되는 파일을 업로드하겠습니다.
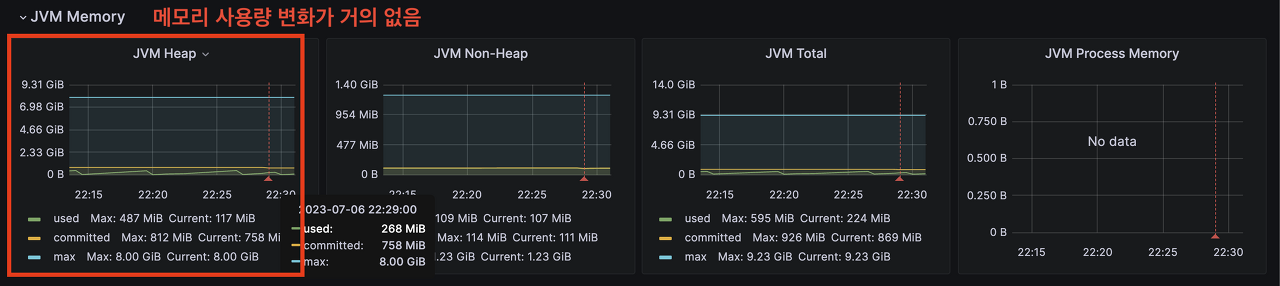
실제 메트릭을 확인했을 때 메모리 사용량이 거의 없다고 볼 수 있습니다. 하지만 제 로컬에서 실행한 Spring Boot 프로젝트를 통해 937MB 파일을 AWS S3에 업로드하는데 걸린 시간은 16분정도 소요되었습니다. Stream 업로드 방식은 서버의 리소스가 한정적이고 작은 용량의 파일을 업로드할 때 효과적입니다. 만약 프로덕트에 Stream 업로드 방식을 채택한다면, 위에서 이야기한 것처럼 운영 환경과 동일한 인프라로 충분한 업로드 속도 테스트가 필요합니다.
MultipartFile 업로드
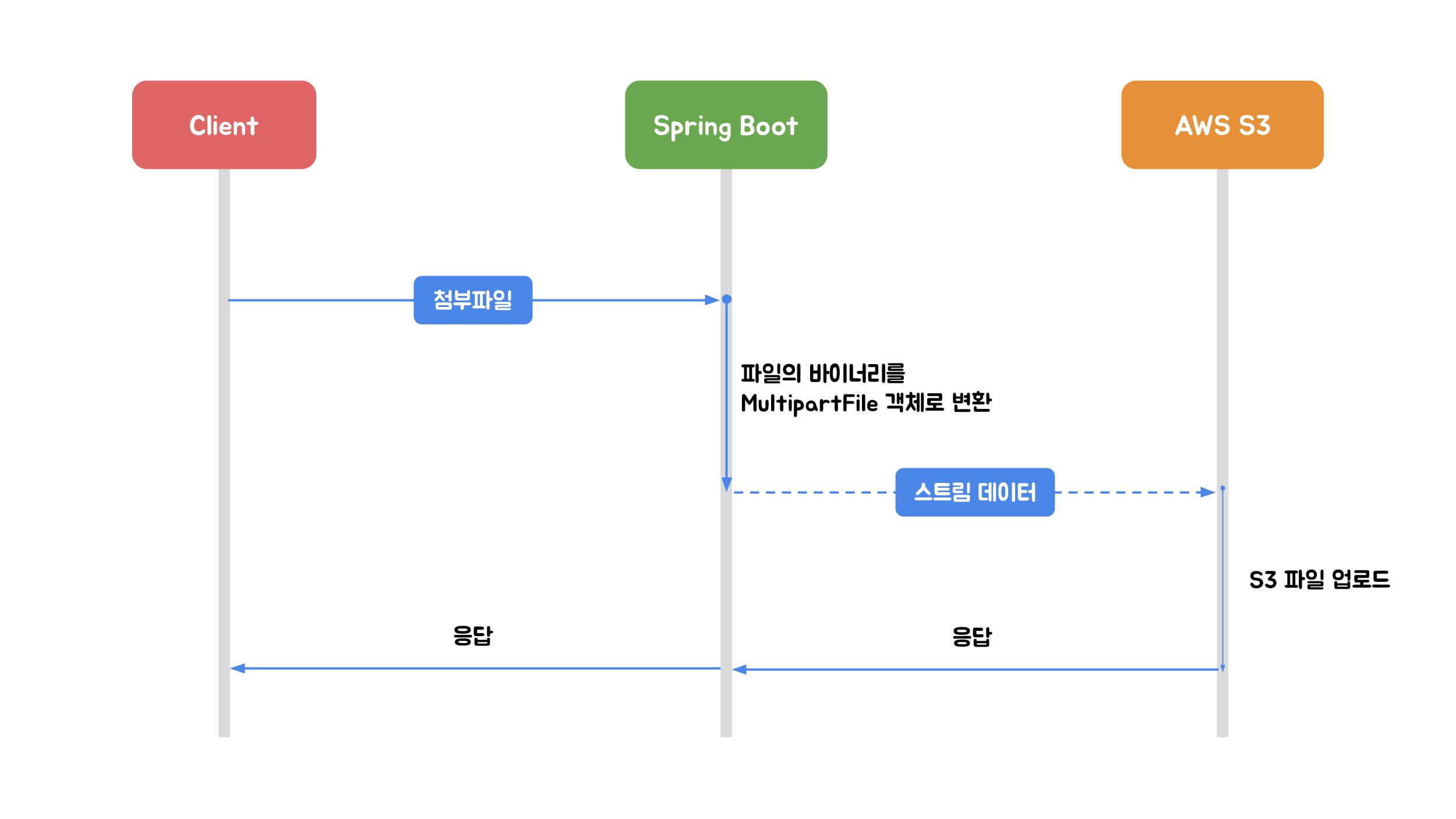
MultipartFile 업로드는 Spring에서 제공하는 MultipartFile 인터페이스를 이용하여 파일을 업로드하는 방식입니다. 이 인터페이스는 파일의 이름, 크기, 내용과 같은 업로드된 파일의 내용에 액세스하는 방법을 제공합니다. MultipartFile은 Stream 업로드에 비해 더 높은 수준의 추상화와 편의성을 제공하고 있습니다. MultipartFile 업로드 방식을 사용하려면 아래와 같은 설정이 필요합니다.
spring:
servlet:
multipart:
enabled: true # 멀티파트 업로드 지원여부 (default: true)
file-size-threshold: 0B # 파일을 디스크에 저장하지 않고 메모리에 저장하는 최소 크기 (default: 0B)
location: /users/charming/temp # 업로드된 파일이 임시로 저장되는 디스크 위치 (default: WAS가 결정)
max-file-size: 100MB # 한개 파일의 최대 사이즈 (default: 1MB)
max-request-size: 100MB # 한개 요청의 최대 사이즈 (default: 10MB)클라이언트가 파일을 업로드했을 때 WAS(Tomcat)가 해당 파일을 임시 디렉터리(location)에 저장합니다. 여기서 임시 디렉터리에 저장된 파일은 힙 메모리에 올라가는 것이 아닌 Servlet Container Disk(컨테이너가 실행되고 있는 서버의 디스크)에 저장됨을 의미합니다. 요청 처리가 끝나면 임시 저장된 파일이 삭제됩니다. 하지만 업로드 중 배포가 되었다든지, 장애가 발생했다든지 등 가끔 삭제되지 않고 남아있을 수 있습니다. 그럴 경우에 삭제 작업을 별도로 해야 하기 때문에 작업과 관리가 용이하도록 경로를 직접 설정해 주는 것이 좋습니다. 또한 Spring은 임시 디렉터리에 저장된 파일을 MultipartFile 변수에 매핑함으로써 업로드된 파일의 바이너리를 힙 메모리에 할당하지 않고 해당 콘텐츠 메타데이터에 액세스할 수 있습니다.
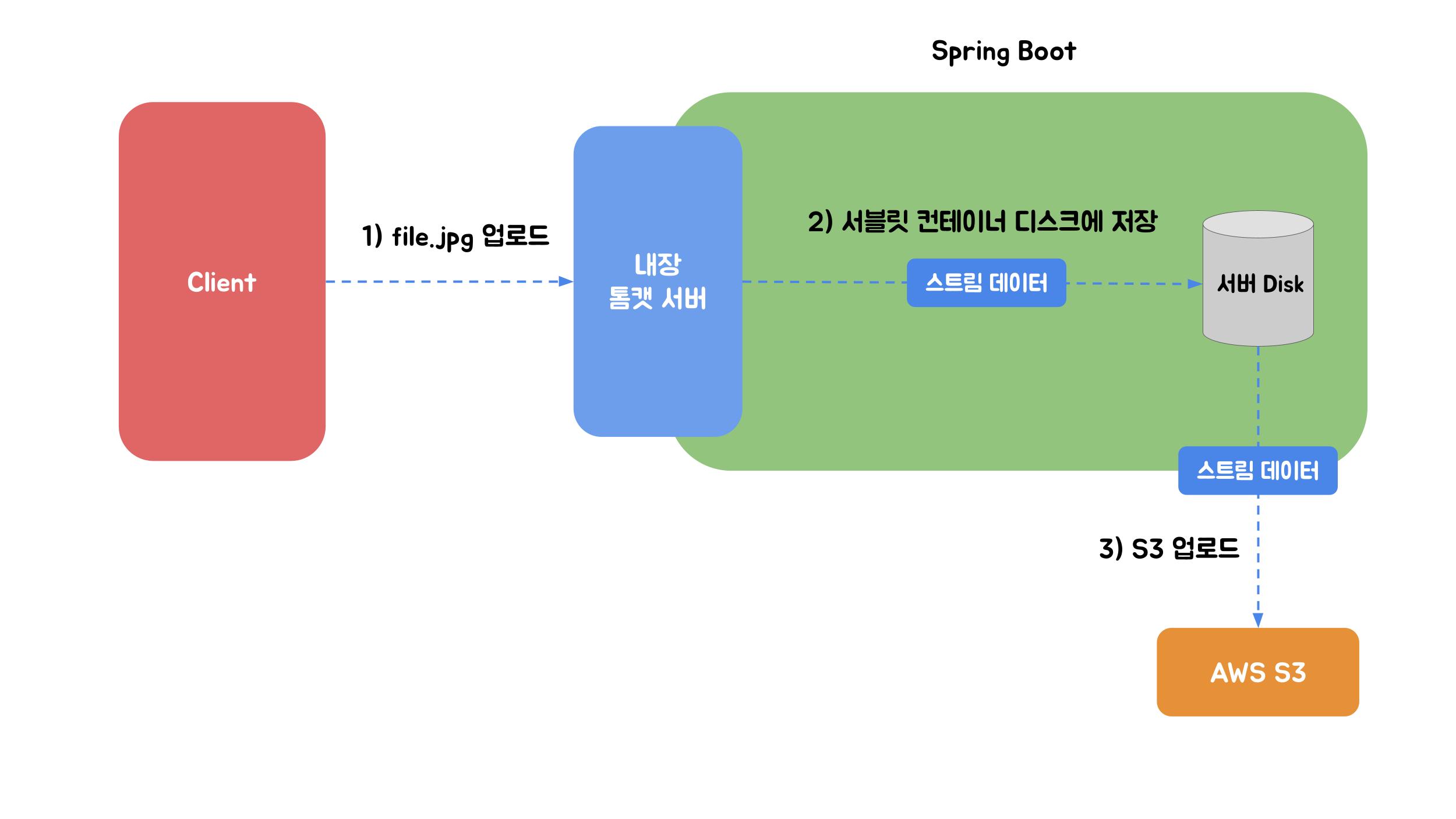
즉 업로드된 파일의 크기가 fize-size-threshold 값 이하라면 WAS가 임시파일을 생성하지 않고 파일 바이너리를 메모리에 다이렉트로 할당하게 됩니다. 파일 처리 속도는 더 빠르겠지만, 스레드가 작업을 수행하는 동안 부담이 될 수 있기 때문에 충분한 검토가 필요합니다. 만약 파일 크기가 fize-size-threshold 값을 초과한다면 파일은 location 경로에 저장되고 Spring에서 필요할 때 해당 파일을 읽어 작업할 수 있습니다.
@PostMapping("/multipart-files")
fun uploadMultipleFile(
@RequestPart file: MultipartFile,
) {
val objectMetadata = ObjectMetadata().apply {
this.contentType = file.contentType
this.contentLength = file.size
}
val putObjectRequest = PutObjectRequest(
"bucketName",
"objectKey",
file.inputStream,
objectMetadata,
)
amazonS3Client.putObject(putObjectRequest)
}위 코드는 단일 API 호출로 한 개의 파일을 업로드할 수 있는 예제입니다. 하지만 아래와 같이 작성 시 단일 API 호출로 여러 개의 파일을 동시에 업로드할 수도 있습니다.
@PostMapping("/multipart-files")
suspend fun uploadMultipleFiles(
@RequestPart("uploadFiles") multipartFiles: List<MultipartFile>,
@RequestParam type: String,
): String {
multipartFiles.map {
val objectMetadata = ObjectMetadata().apply {
this.contentType = it.contentType
this.contentLength = it.size
}
val putObjectRequest = PutObjectRequest(
"bucketName",
"objectKey",
it.inputStream,
objectMetadata,
)
amazonS3Client.putObject(putObjectRequest)
}
return "업로드 완료"
}또한 코루틴 병렬처리를 이용하면 아래와 같이 작성할 수 있습니다.
@PostMapping("/coroutine/multipart-files")
suspend fun uploadMultipleFilesWithCoroutine(
@RequestPart("uploadFiles") multipartFiles: List<MultipartFile>,
@RequestParam type: String,
) = withContext(Dispatchers.IO) {
val uploadJobs = multipartFiles.map {
val objectMetadata = ObjectMetadata().apply {
this.contentType = it.contentType
this.contentLength = it.size
}
async {
val putObjectRequest = PutObjectRequest(
"bucketName",
"objectKey",
it.inputStream,
objectMetadata,
)
amazonS3Client.putObject(putObjectRequest)
}
}
uploadJobs.awaitAll()
return@withContext "업로드 완료"
}Stream 업로드 및 MultipartFile 업로드 방식을 사용할 때 다수의 사용자로부터 동시에 요청이 들어올 경우, 서버의 스레드가 빠르게 소진될 위험이 있습니다. 이에 따라 스레드 풀 설정이 적절하지 않으면 스레드 고갈로 인해 타임아웃이 발생할 위험이 있습니다.
이러한 문제를 대비해 resilience4j의 bulkhead 패턴을 활용하여 동시에 처리될 수 있는 작업의 최대 수를 제한하고, 별도의 스레드 풀을 사용함으로써 다른 비즈니스 로직에 영향을 주지 않도록 방지할 수 있습니다. 또한 파일 업로드를 전담하는 서버를 별도로 분리하는 전략도 고려해볼 수 있습니다.
AWS Multipart 업로드
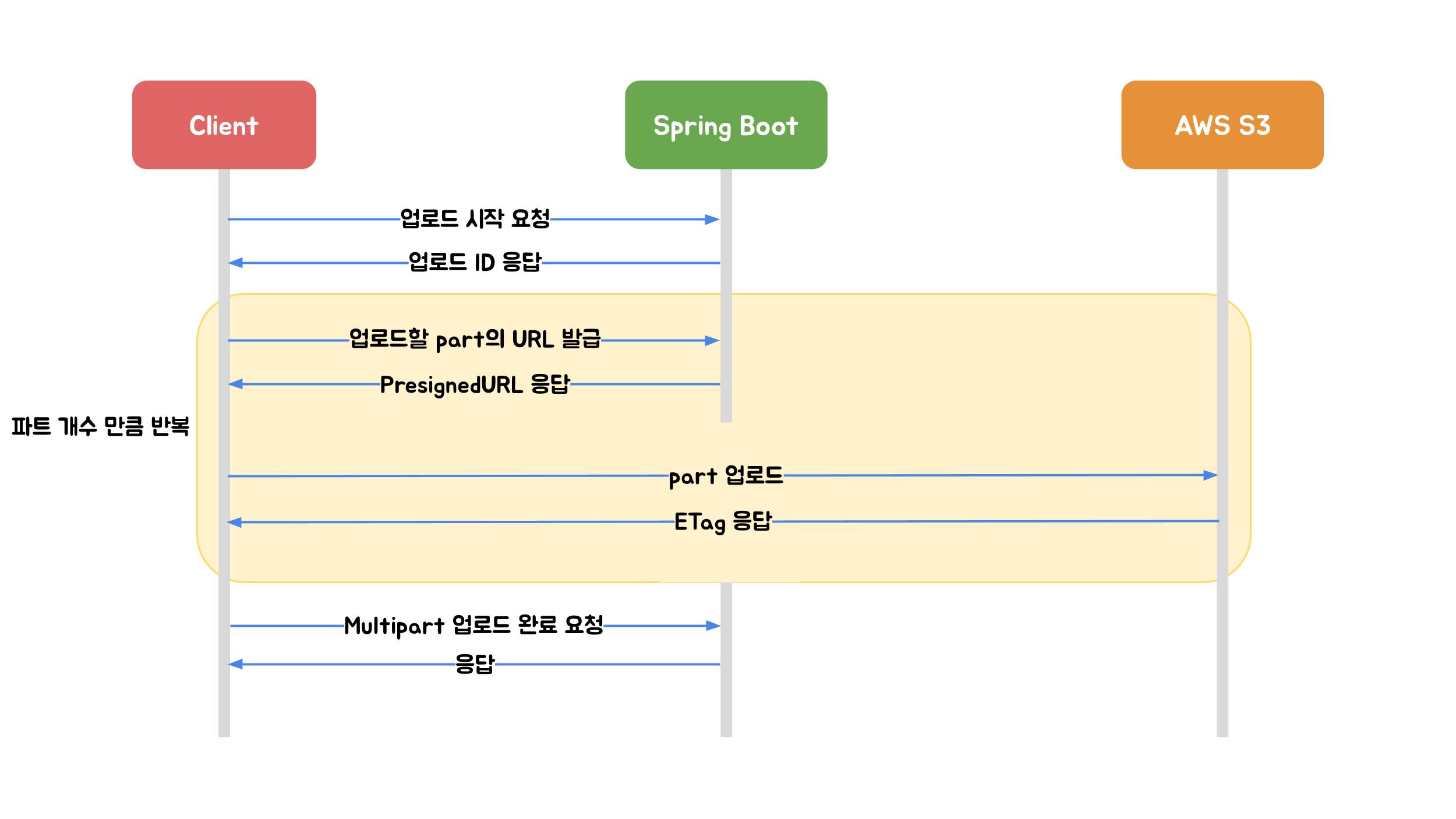
Multipart Upload는 AWS S3에서 제공하는 파일 업로드 방식입니다. 업로드할 파일을 작은 part로 나누어 각 부분을 개별적으로 업로드합니다. 그리고 파일의 바이너리가 Spring Boot를 거치지 않고 AWS S3에 다이렉트로 업로드되기 때문에 서버의 부하를 고려하지 않아도 된다는 큰 장점이 있습니다.
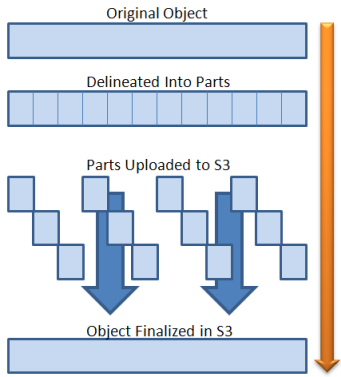
만약 모든 part가 업로드가 되었을 경우 AWS에서 하나의 객체로 조립하여 저장합니다.

또한 몇 개의 파트가 업로드되었는지 확인하여 위와 같이 사용자에게 업로드 진행사항을 제공할 수 있습니다.
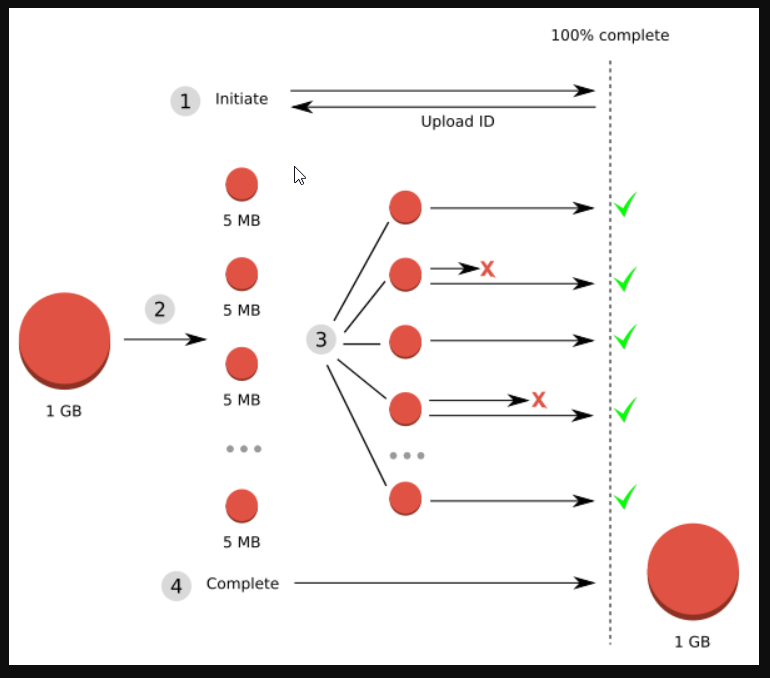
Multipart Upload는 총 4단계 프로세스로 구성되어 있습니다.
1. Multipart 업로드 시작
멀티파트 업로드 시작(initiate-upload)을 요청하면 서버는 멀티파트 업로드에 대한 고유 식별자인 Upload ID를 응답합니다. 부분 업로드, 업로드 완료 또는 업로드 중단 요청 시 항상 Upload ID를 포함해야 하기 때문에 클라이언트는 이 값을 잘 저장해야 합니다.
2. PresignedURL 발급
업로드를 위한 AWS의 서명된 URL을 발급받는 요청입니다. 멀티파트 시작 요청에서 받은 Upload ID 그리고 PartNumber 값을 함께 요청해야 합니다. PartNumber는 1부터 10,000까지 파트 번호 지정이 필요합니다. AWS에서 파트 번호를 이용하여 업로드하는 객체의 각 부분과 그 위치를 고유하게 식별하기 때문입니다. 파트 번호는 연속적인 시퀀스로 선택할 필요는 없습니다 (예를 들면 1, 5 및 14를 선택해도 됩니다).
만약 이전에 업로드한 부분과 동일한 부분 번호로 새 부분을 업로드할 경우 이전에 업로드한 부분을 덮어쓰게 됩니다.
3. PresignedURL part 업로드
발급받은 PresignedURL에 PUT 메소드로 파트의 바이너리를 실어서 요청합니다. 이때 파트의 용량은 클라이언트에서 결정하여 업로드합니다.
분할된 파트는 5MB~5GB의 크기만 가능합니다. 다만 마지막 파트는 5MB 이하도 괜찮습니다. 만약 업로드할 파일의 크기가 5MB 이하라면 파트 업로드는 한번 수행되어야 합니다. 즉, 첫 번째 파트가 마지막 파트이기도 하다면 위 규칙은 위반되지 않으며 AWS S3는 멀티파트 업로드로 수락하여 객체를 생성하게 됩니다. 파트는 최대 5GB까지 10,000개까지 업로드할 수 있으니 이론상 5TB 크기의 파일까지 업로드할 수 있습니다.
파트를 업로드 후 받는 응답 헤더에 MD5 Checksum 값인 ETag(Entity Tag)가 포함되어 있습니다. 클라이언트는 각 파트 업로드 시 PartNumber와 ETag 값을 매칭하여 보관해야 합니다. 이후 멀티파트 업로드 완료 요청에 이러한 값을 포함해야 하기 때문입니다.
4. Multipart 업로드 완료
멀티파트 업로드 완료는 Upoad ID, 각 PartNumber와 매칭되는 ETag 값이 배열로 포함되어야 합니다. 업로드 완료가 수행되어야 AWS S3에서 PartNumber와 ETag를 기준으로 객체를 재조립합니다. 객체가 매우 클 경우 이 프로세스는 몇 분 정도 걸릴 수 있습니다.
만약 업로드 완료를 하지 않을 경우 S3 버킷에 파일이 생성되지 않습니다.
예외. Multipart 업로드 취소
하나 이상의 파트가 업로드된 상태에서 예기치 못한 이슈가 발생한다면 멀티파트 업로드를 완료하거나 취소해야 업로드된 파트의 스토리지 비용이 청구되지 않습니다.
따라서 클라이언트에서 예외 발생 시 멀티파트 업로드를 취소할 것을 권장 드립니다. 단, 한번 취소된 Upload ID로 다시 파트를 업로드할 수 없습니다.
위 4단계 프로세스를 클라이언트와 데이터 저장소 관점에서 정리하면 아래와 같습니다. (1, 2, 5, 6번은 Spring Boot 서버를 거치게됩니다.)
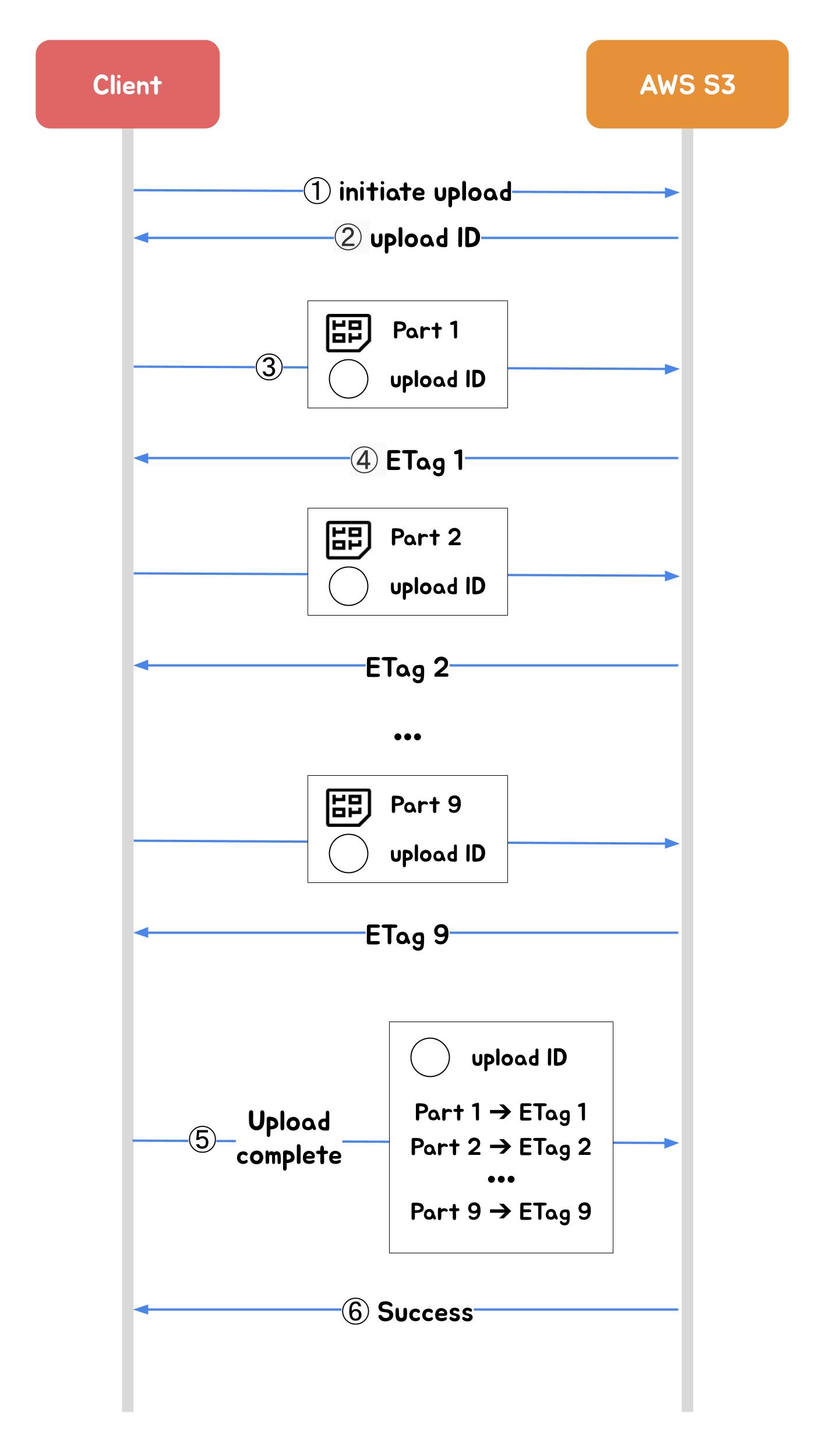
위 ③번~④번 단계를 반복하면서 클라이언트는 사용자에게 업로드가 어디까지 수행되었는지 사용자에게 제공할 수 있습니다.
또한 ③번 단계에서 클라이언트 도메인(example.com)과 요청받는 도메인(amazonaws.com)이 다르기 때문에 브라우저에서 CORS 에러가 발생합니다. 따라서 아래와 같이 AWS S3 bucket에 CORS 설정이 필요합니다.
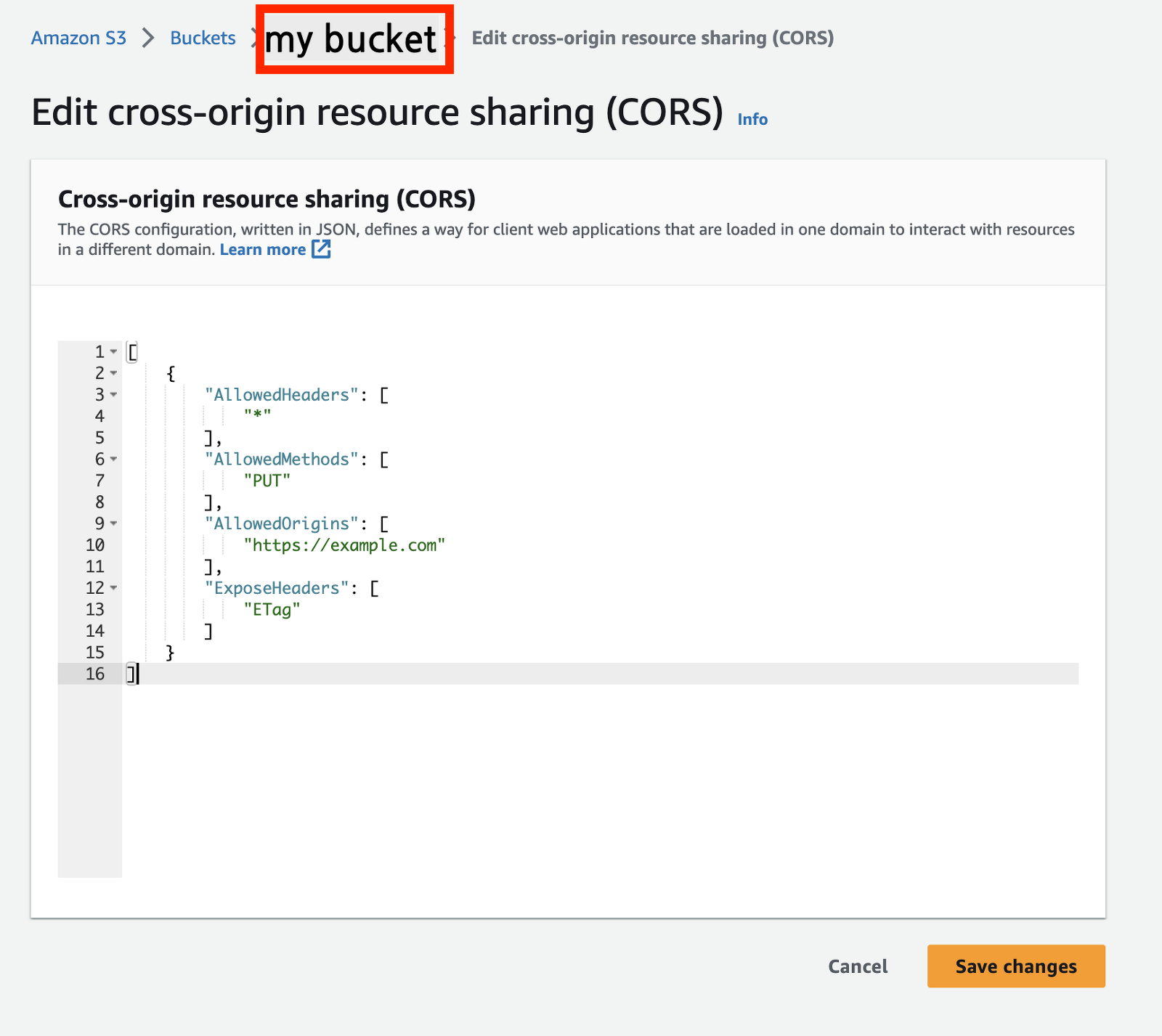
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"PUT"
],
"AllowedOrigins": [
"https://example.com"
],
"ExposeHeaders": [
"ETag"
]
}
]AWS Multipart 업로드 예제 코드
1. Multipart 업로드 시작
data class PreSignedUploadInitiateRequest(
val originalFileName: String,
val fileType: String,
val fileSize: Long,
)@PostMapping("/initiate-upload")
fun initiateUpload(
@RequestBody request: PreSignedUploadInitiateRequest,
): InitiateMultipartUploadResult {
val objectMetadata = ObjectMetadata()
objectMetadata.contentLength = request.fileSize
objectMetadata.contentType = URLConnection.guessContentTypeFromName(request.fileType)
return amazonS3Client.initiateMultipartUpload(
InitiateMultipartUploadRequest("bucketName", "objectName", objectMetadata)
)
}2. PresignedURL 발급
data class PreSignedUrlCreateRequest(
val uploadId: String,
val partNumber: Int,
)@PostMapping("/presigned-url")
fun initiateUpload(
@RequestBody request: PreSignedUrlCreateRequest,
): URL {
val expirationTime = Date.from(
LocalDateTime.now().plusMinutes(10).atZone(ZoneId.systemDefault()).toInstant()
)
val generatePresignedUrlRequest =
GeneratePresignedUrlRequest("bucketName", "objectName")
.withMethod(HttpMethod.PUT)
.withExpiration(expirationTime) // presigned url 만료 시간 설정
generatePresignedUrlRequest.addRequestParameter("uploadId", request.uploadId)
generatePresignedUrlRequest.addRequestParameter("partNumber", request.partNumber.toString())
return amazonS3Client.generatePresignedUrl(generatePresignedUrlRequest)
}3. Multipart 업로드 완료
data class FinishUploadRequest(
val uploadId: String,
val parts: List<Part>,
) {
data class Part(
val partNumber: Int,
val eTag: String,
)
}@PostMapping("/complete-upload")
fun initiateUpload3(
@RequestBody finishUploadRequest: FinishUploadRequest,
): CompleteMultipartUploadResult {
val partETags = finishUploadRequest.parts.map { PartETag(it.partNumber, it.eTag) }
val completeMultipartUploadRequest = CompleteMultipartUploadRequest(
"bucketName",
"objectName",
finishUploadRequest.uploadId,
partETags,
)
return amazonS3Client.completeMultipartUpload(completeMultipartUploadRequest)
}4. Multipart 업로드 취소
data class PreSignedUrlAbortRequest(
val uploadId: String,
)@PostMapping("/abort-upload")
fun initiateUpload3(
@RequestBody request: PreSignedUrlAbortRequest,
) {
val abortMultipartUploadRequest =
AbortMultipartUploadRequest("bucketName", "objectName", request.uploadId)
amazonS3Client.abortMultipartUpload(abortMultipartUploadRequest)
return
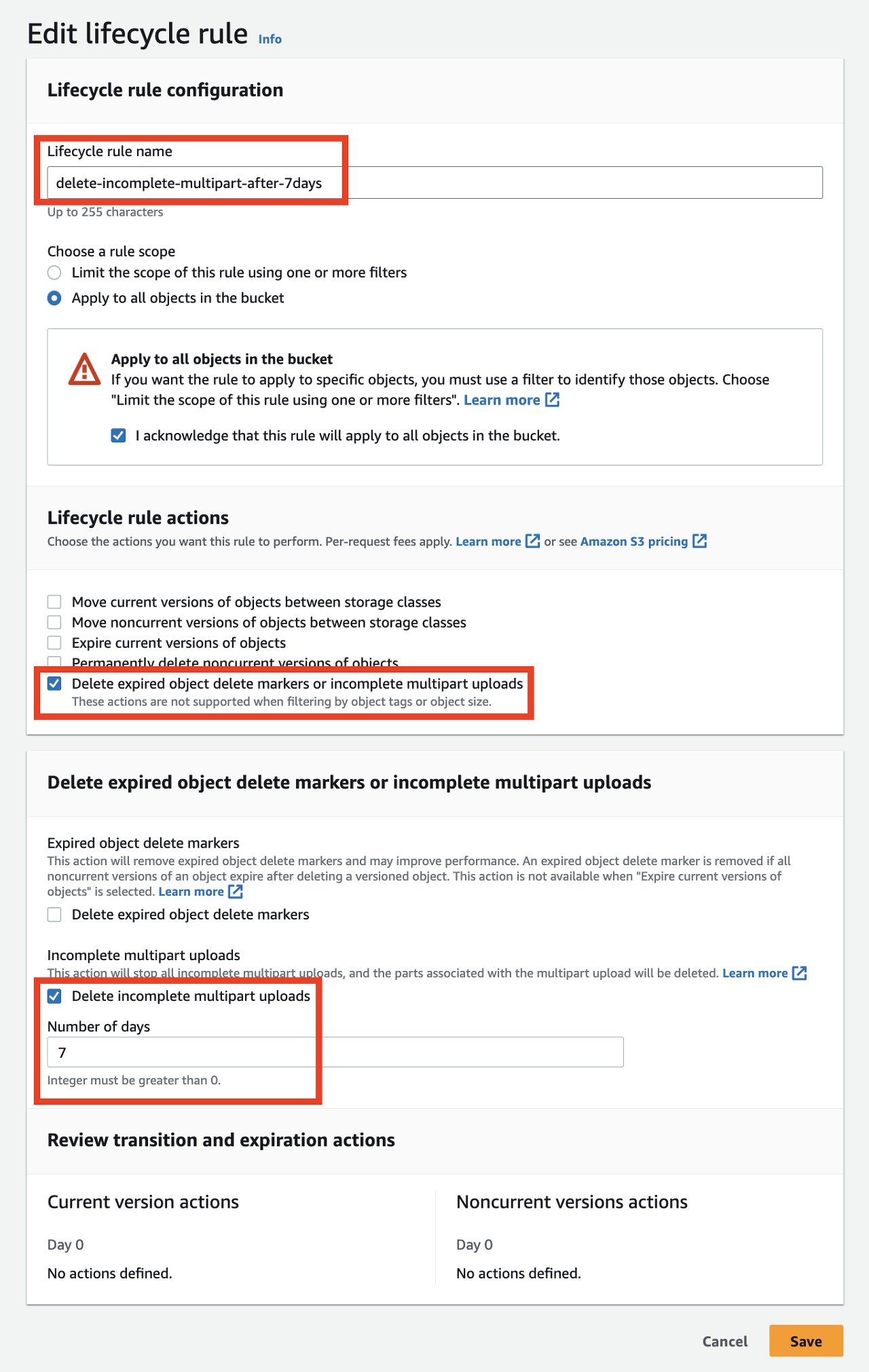
}업로드가 취소되지 않고 남아있는 불완전한 멀티파트(incomplete multipart) 파일들은 계속해서 스토리지 비용이 부과됩니다. 따라서 AWS CLI를 통해 직접 삭제해야 하는 번거로움이 생길 수 있습니다. 하지만 아래와 같은 S3 LifeCycle 설정으로 자동으로 삭제되게 설정할 수 있습니다.
해당 Bucket -> Management -> Create Lifecycle rule 로 이동하여 아래와 같이 설정할 수 있습니다.
결론
| 특징/방식 | Stream | MultipartFile | AWS Multipart |
|---|---|---|---|
| 파일 크기 제한 | 이론상 없음 | 디스크/메모리에 의존(설정에 따라 제한 가능) | 최대 5TB |
| 파일 바이너리 서버 경유 유무 | △ (Buffer) | ○ (설정에 따라 발생 가능) | ✕ |
| 구현 복잡성 | 단순 | 중간 | 복잡 |
| 업로드 과정의 복잡성 | 단순 | 중간 | 복잡 |
| AWS S3 의존성 | 일반적 | 일반적 | 높음 |
| 진행 상태 표시 가능 여부 | ✕ | ✕ | ○ |
| CORS 설정 필요 여부 | ✕ | ✕ | ○ |
| 운영 유지보수 | ✕ | ○ (주기적인 임시파일 삭제) | ✕ (S3 Lifecycle) |
우리에게 가장 중요한 것은 동작하는 코드를 정해진 일정 내 만드는 것입니다. 꼭 그렇다고 데드라인 주도 개발(Deadline-Driven Development)을 지향하라는 것은 아닙니다. 하지만 기술을 선택함에 있어서 성능뿐 아니라 구현 복잡도 또한 중요하게 고려해야 한다는 점입니다.
"프로그래머에게 요구되는 것은 100점이 아닌 80~90점짜리 프로그램을 기한 내에 완성하는 일이다."
나카지마 사토시, 『오늘 또 일을 미루고 말았다』
(https://jojoldu.tistory.com/686)
만약 최대 20MB 프로필 이미지 업로드 기능을 개발하면서 AWS Multipart 업로드 방식으로 구현한다면 오버 엔지니어링이라 볼 수 있습니다. 1주일이면 개발할 수 있는 일에, 본인 호기심을 대입하거나 과도한 모듈화를 핑계로 일을 크게 벌이게 된다면 이는 곧 팀 생산성 저하로 이어지게 됩니다. 따라서 우리는 기술을 선택할 때 최고의 방식도 좋지만, 상황에 따라 타협적인 방식도 필요합니다.
여기까지 Spring Boot에서 S3에 파일을 업로드하는 세 가지 방법이었습니다.
마지막으로 저희 세일즈서비스팀 소개 한번 드리겠습니다.
제가 소속되어 있는 세일즈서비스팀은 배달의민족에 입점하기 위해 필요한 데이터를 정책에 따라 입력받을 수 있는 전자계약서 시스템과 승인 담당자가 이 데이터를 검수 완료하면 각 도메인에 입점에 필요한 데이터를 전달하는 요청 관리 시스템을 담당하고 있습니다.
세일즈서비스팀의 역할은 단순히 데이터를 입력받고 각 도메인에 전달하는 역할에 그치지 않습니다. 더 나아가 사장님이 빠르게 입점할 수 있도록 입점 프로세스를 간소화하고 자동화하여 사장님이 신속하게 입점할 수 있도록 노력하고 있습니다.
최근 셀러시스템팀 김효건 님이 "배달의민족 앱 모든 곳에서 사용되는 업주/가게 데이터를 관리하고 있는 셀러시스템은 마치 ‘배달의민족의 심장’과 같다고 소개했습니다. 비슷한 맥락으로 저희 세일즈서비스팀은 데이터를 유실되지 않고 신속하게 전달함으로써 배달의민족 심장이 멈추지 않고 뛸 수 있게 노력하고있습니다.