Spark on Kubernetes로 이관하기
안녕하세요, 우아한형제들 데이터플랫폼팀 박준영입니다.
이번 글에서는 Spark on Kubernetes 환경 도입 과정과 운영 경험에 대해 소개해 드리려 합니다.
데이터플랫폼팀은 다양한 서비스 데이터를 수집하고 처리, 분석할 수 있는 환경을 제공하고 있습니다.
지난 몇 년간 대용량 데이터 처리를 위해 AWS EMR 기반의 Spark를 사용해왔습니다.
운영하면서 여러 개선 작업을 진행했지만 크게 두 가지 측면에서 근본적인 문제를 마주치게 되었습니다.
1. 클러스터 비용
그동안 데이터와 사용자가 늘어난 만큼 EMR 클러스터 비용이 크게 증가했습니다.
목적에 따라 여러 클러스터를 사용하고 있는 만큼 EMR master와 core 노드 비용이 추가로 발생하게 됩니다.
managed scaling을 사용했지만 Scale-In 시간이 내부 기준에 부합하지 못해 더 민감한 오토스케일링 환경이 필요했습니다.
2. 운영 업무
EMR 클러스터에서는 분석, 모델링을 위해 PySpark도 함께 사용하는데 각 작업에서 필요한 파이썬 패키지들의 의존성 문제가 빈번하게 발생했습니다. conda를 통해 관리하고 있었지만 기록이 남지 않아 매번 새로운 환경을 생성하는 경우가 많았습니다.
성능 개선을 위해 주기적으로 Spark 버전 업데이트를 진행하는데 EMR 클러스터는 단일 Spark 버전만 사용할 수 있어
매번 클러스터를 새로 만들어야 하는 부담이 있었습니다.
Spark on Kubernetes
위와 같은 문제를 해결하기 위해 Spark on Kubernetes를 고려하게 되었습니다.
데이터플랫폼팀에서는 이미 로깅, 모니터링 등 주요 기능을 갖춘 EKS 클러스터에서 Airflow, JupyterHub 등 다양한 환경을 K8S 기반으로 운영하고 있었습니다.
따라서 컴퓨팅에 필요한 리소스도 EKS에 통합한다면 인프라 단일화를 통해 간소화하고 리소스 활용도를 높일 수 있다고 생각했습니다.
Spark on Kubernetes를 도입한다면 일반적으로 spark-submit을 통해 pod를 생성하거나
spark-on-k8s-operator의 SparkApplication CRD를 통해 실행하는 방식을 많이 사용합니다.
하지만 AWS 환경에서 Glue metastore와 S3 스토리지를 사용하고 있었기에
만약 위 방법을 사용한다면 Glue, Hive 의존성과 S3A Committer가 추가된 이미지를 직접 운영해야 합니다.
이 방법은 Spark 버전 업데이트 노력을 최소화하기 위한 목표와 맞지 않기에 비슷한 시기에 오픈한 EMR on EKS 서비스를 테스트해보기로 결정했습니다.
도입 과정
EMR on EKS는 EKS상에서 Spark 애플리케이션을 실행하기 위한 AWS 최적화 이미지와 인터페이스를 제공하는 서비스입니다.
EMR on EKS를 사용하면서 얻을 수 있는 장점은 아래와 같습니다. 공식 문서를 통해 더 자세한 내용을 확인하실 수 있습니다.
- EMR 클러스터 대비 빠른 프로비저닝 시간 소요(15분 → 2분)
- master, core 등 상시 운영 노드가 필요 없음
- 단일 클러스터 내에서 여러 Spark 버전을 쉽게 사용 가능
- Karpenter를 통해 노드 오토스케일링을 더 빠르게 수행
- IAM 기반 사용자 권한 제어를 쉽게 적용 가능
TPC-DS 벤치마크 테스트
비교적 신규 서비스였기에 TPC-DS 데이터를 통해 직접 100개 쿼리의 벤치마크 테스트를 수행했습니다(2021년 6월 기준).
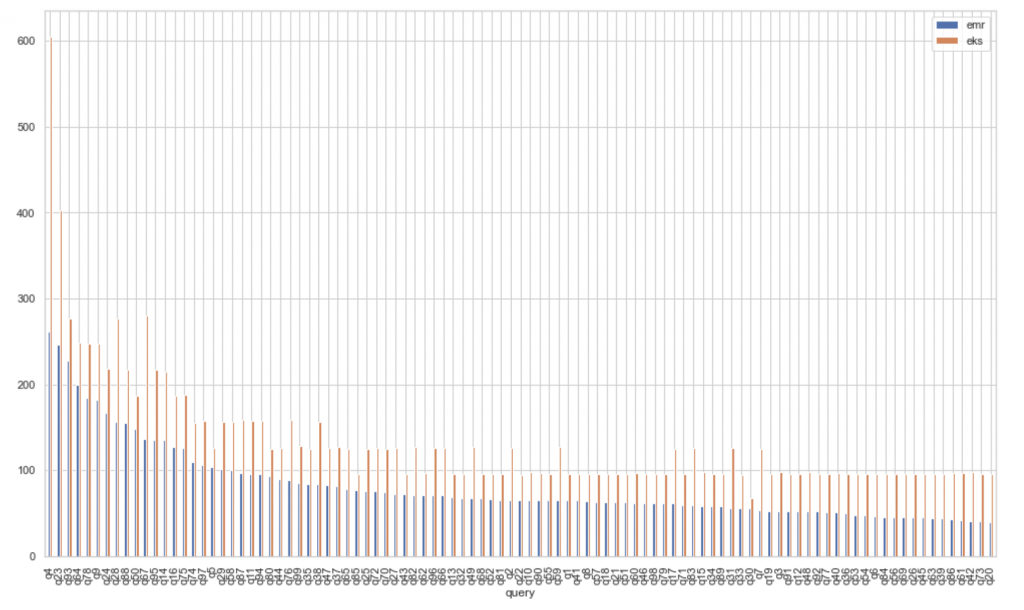
EMR 환경과 비교했을 때 일부 대용량 셔플이 발생하는 쿼리에서 더 낮은 성능을 보였지만
대부분의 쿼리에서 비슷한 수준의 성능이 나오는 것을 확인했습니다.
테스트 과정에서 흔히 알려진 최적화 방법으로 Scratch Space를 기본값 emptyDir에서 hostPath로 변경했을 때
대용량 셔플이 발생하는 쿼리에서 약 10% 정도 성능 향상을 확인할 수 있었습니다.
작업 수행 시간과 리소스 사용량을 통해 계산한 비용은 EMR on EKS가 더 나은 결과를 보였습니다.
여러 이점을 고려하여 도입을 결정하고 이후 기존 파이프라인 이관을 위해 필요한 작업을 진행하게 되었습니다.
spark 이벤트 로그
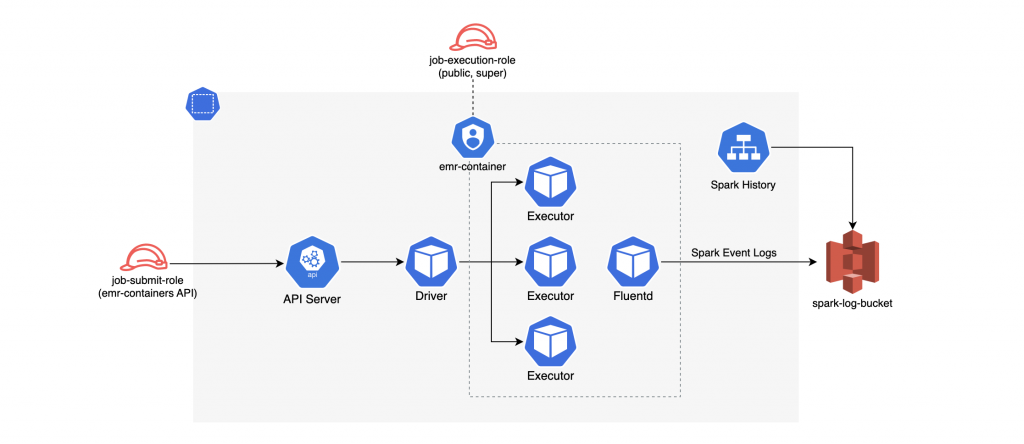
EMR on EKS는 작업 단위로 접속할 수 있는 Spark UI를 제공합니다.
하지만 생성까지 시간이 오래 걸리고 이전 기록을 확인할 수 없어 독립된 spark-history-server를 운영하게 되었습니다.
Helm 차트로 개발하여 S3에 저장된 spark 이벤트 로그를 사용자가 확인할 수 있도록 구성했습니다.
Airflow EMRContainerOperator
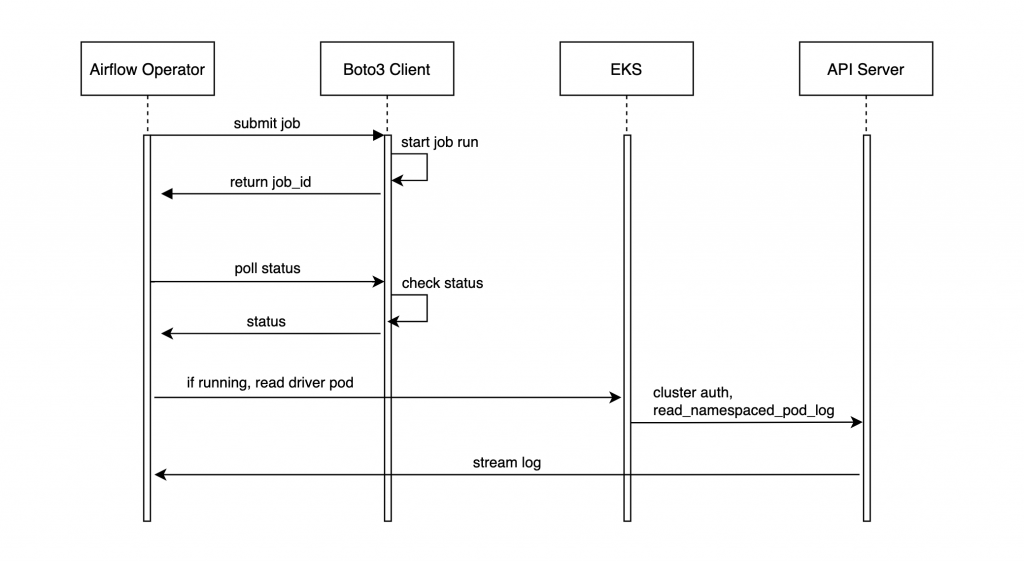
기존에는 Airflow UI에서 실시간으로 작업의 spark 로그를 확인하기 위해 client 모드로 spark-submit을 수행하고 있었습니다.
EMR on EKS 환경에서는 client 모드를 사용하더라도 spark driver가 별도의 pod로 생성됩니다.
따라서 emr-containers API와 함께 pod 로그를 실시간 확인할 수 있도록 custom operator를 추가로 개발해서 사용하게 되었습니다.
Operator에서 전달하는 사용자의 SQL 파일들은 driver pod의 initContainer에 gitSync 컨테이너를 추가하여 받아올 수 있도록 설정했습니다.
사용자 커스텀 이미지
사용자가 직접 필요한 의존성을 정의한 컨테이너 이미지를 만들 수 있는 프로세스를 제공했습니다.
또한 EMR on EKS 이미지를 기반으로 JupyterHub 프로필을 추가하여
Spark on Kubernetes 환경을 노트북에서 인터랙티브하게 실행할 수 있도록 구성했습니다.
이를 통해 파이썬 패키지들의 의존성 문제를 해결하고 동일한 이미지를 Airflow와 JupyterHub에서 모두 실행할 수 있게 되었습니다.
운영 과정
안정적으로 스팟 인스턴스 사용하기
스팟 인스턴스 유형을 사용하면 온디맨드에 비해 70~90%의 비용을 절감할 수 있습니다.
하지만 스팟 인스턴스는 가격 입찰, 가용성 등 여러 이유로 중단될 수 있습니다.
따라서 이를 안정적으로 운영하기 위해 다음과 같은 방법을 사용하고 있습니다.
1. Driver는 온디맨드에 할당하기
driver pod가 노드 회수로 인해 종료되는 경우, Spark 작업은 실패하게 됩니다.
executor pod가 종료되는 경우, 캐시 데이터 또는 셔플 파일을 잃게 되지만
새로운 executor를 통해 이를 다시 계산하기 때문에 전체 작업이 실패하지는 않습니다.
위와 같은 이유로 driver는 온디맨드 인스턴스에 할당하고 있습니다.
nodeSelector를 통해 driver는 온디맨드에서, executor는 스팟에서 실행하도록 설정할 수 있습니다.
2. 적절한 인스턴스 유형 선택하기
일부 인스턴스 유형은 해당 시점의 spot market 상황에 따라 안정적으로 확보하지 못할 수도 있습니다.
확보를 못하면 executor는 계속 pending 상태에 머무르게 되고 전체 수행 시간도 지연됩니다.
사용량에 비해 크기가 큰 인스턴스 유형을 선택했다면, 여러 executor pod가 하나의 노드에 할당됩니다.
이때 해당 노드가 중단된다면 여러 executor가 종료되므로 재계산에 더 많은 시간이 소요됩니다.
위와 같은 이유로 적절한 인스턴스 유형을 선택하는 것이 spot kill을 줄이는 데 도움이 됩니다.
Karpenter를 통해 여러 인스턴스 유형을 지정하여 Pod의 리소스 요청량에 가장 적합하고, 안정적으로 확보 가능한 인스턴스를 프로비저닝하도록 설정했습니다.
3. Graceful Executor Decommissioning 적용하기
Graceful Executor Decommissioning은 Spark 3.1 버전에 추가된 기능입니다.
이 기능을 통해 노드가 중단되더라도 최소한의 손실로 Spark 작업이 지속되도록 설정할 수 있습니다.
이를 사용하려면 먼저 클러스터에 AWS Node Termination Handler가 설치되어 있어야 합니다.
노드가 중단되었을 때 과정은 다음과 같습니다.
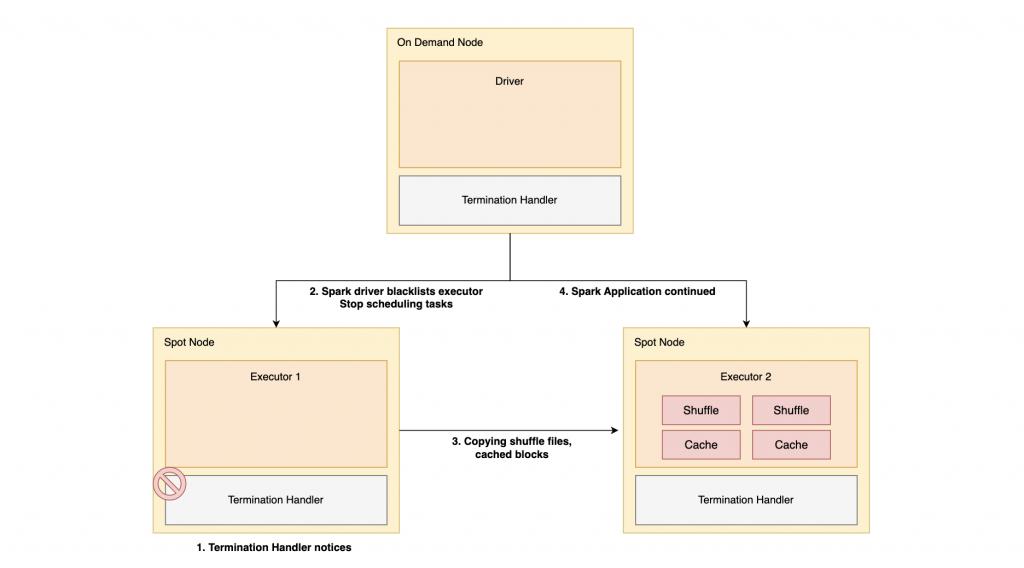
- 스팟 인스턴스가 중단되기 약 120초 전에 Termination Handler의 notice 발생
- driver가 해당 executor를 blacklist에 추가하고 신규 task의 스케줄링을 차단
- 중단되는 노드에 있던 캐시 데이터, 셔플 파일을 다른 노드로 복제
- 실패 처리된 task를 이어서 수행 (복제한 파일을 그대로 활용)
이 설정을 통해 노드가 중단되었을 때 재계산을 최소화할 수 있습니다.
만약 데이터 볼륨 설정으로 PVC를 사용한다면 Spark 3.2 버전에서 추가된 Executor PVC Reuse 설정을 통해
spot kill 이후 동일한 PVC를 연결하여 데이터 볼륨을 재사용할 수 있습니다.
task 단위 Prometheus 메트릭 활용하기
Spark을 사용하면서 많은 사용자들이 어려워하는 부분은 리소스 설정이었습니다.
사용자가 지나치게 많은 메모리를 할당하게 된다면 클러스터 리소스가 낭비됩니다.
시간이 지나면서 데이터가 증가하여 성능 저하 또는 장애가 발생하면 리소스를 재설정하기도 합니다.
작업에 대한 메트릭을 Spark UI에서 확인할 수 있지만 여러 메트릭의 기간 대비 변화를 모니터링하기는 어렵습니다.
Spark Prometheus 메트릭을 활용한다면 Grafana 대시보드, 알람과 연계하여 task에 적절한 리소스를 설정할 수 있습니다.
[
{
"classification": "spark-defaults",
"properties": {
"spark.ui.prometheus.enabled": "true",
"spark.kubernetes.driver.annotation.prometheus.io/scrape": "true",
"spark.kubernetes.driver.annotation.prometheus.io/path": "/metrics/executors/prometheus",
"spark.kubernetes.driver.annotation.prometheus.io/port": "4040"
}
},
{
"classification": "spark-metrics",
"properties": {
"*.sink.prometheusServlet.class": "org.apache.spark.metrics.sink.PrometheusServlet",
"*.sink.prometheusServlet.path": "/metrics/prometheus",
"master.sink.prometheusServlet.path": "/metrics/master/prometheus",
"applications.sink.prometheusServlet.path": "/metrics/applications/prometheus"
}
}
]EKS에 이미 Prometheus 기반 모니터링 시스템을 구성해두었기 때문에 그대로 활용할 수 있었고,
Spark Prometheus 설정도 위와 같이 간단히 적용할 수 있습니다.
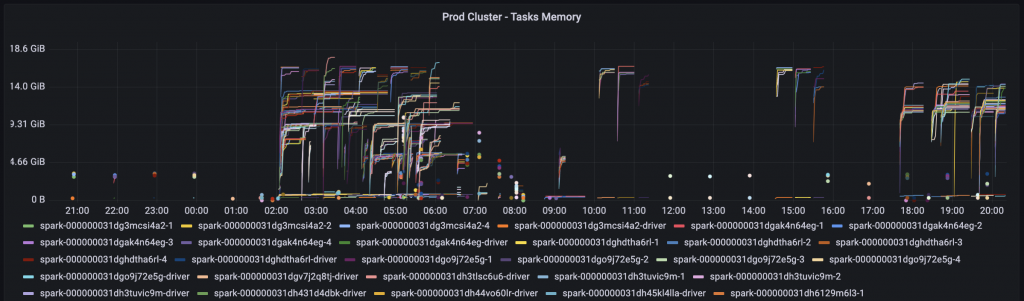
적용 이후에 위와 같이 task의 driver, executor pod의 memory, disk 등 다양한 메트릭을 Grafana에서 확인할 수 있게 되었습니다.
이를 통해 직관적으로 OOM kill, spill과 같은 상황을 감지할 수 있습니다.
이러한 메트릭을 활용한다면 적정 리소스를 자동으로 결정하는 기능도 추가할 수 있습니다.
Airflow Operator에서 과거 N일 메트릭을 통해 적정 리소스를 계산하여 submit 시점에 할당해 주는 방식입니다.
이를 통해 사용자들이 리소스 고민 없이 편하게 개발하고 운영 대응을 최소화할 수 있습니다.
마치며
지금까지 Spark on Kubernetes를 도입하고 운영한 경험에 대해 살펴보았습니다.
이외에도 Volcano를 통한 스케줄링 최적화 등 더 나은 환경을 위해 고도화하고 개선해 나가려고 합니다.
이 글이 클라우드 환경에서 Spark on Kubernetes를 도입하는 데 도움이 되었으면 좋겠습니다.
마지막까지 읽어주셔서 감사합니다!
