실험과 기능플래그를 위한 실험플랫폼 구축하기
실험과 기능 플래그란?
실험(AB 테스트)과 기능 플래그(Feature Flag 혹은 Feature Toggle)에 대해 알고 계신가요?
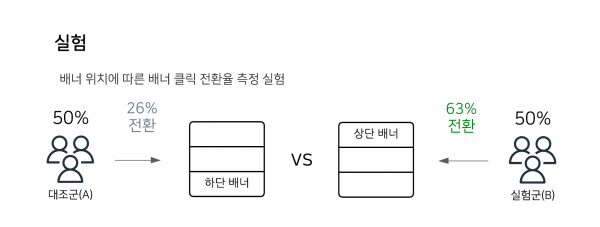
실험은 대조군(A)과 실험군(B)을 나누어 유입되는 사용자들의 반응을 통해 어떤 방법이 가장 효과적인지를 검증하는 과정입니다. 서비스에서는 사소한 변화 하나가 생각보다 큰 영향을 미칠 수 있습니다. 실험을 통해 어느것이 가장 효과적인 방법인지 검증하고 적용한다면 그에 따른 사용자의 이탈이나 비용 낭비를 최소화할 수 있습니다.
배달의민족에서는 화면이 어떻게 변경되었을 때 고객의 반응이 좋을지 혹은 주문이 늘어나는지 등의 여러 케이스를 실험을 통해 검증하고 의사결정을 진행하고 있습니다.
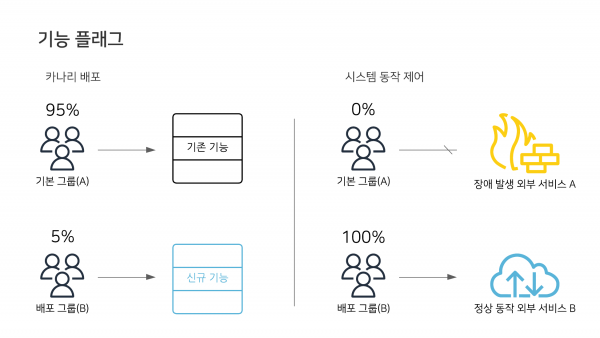
기능 플래그는 코드의 수정, 배포 없이 서비스의 동작을 변경할 수 있는 기능입니다. 기능 플래그를 사용하면 점진적으로 비율을 늘려가며 배포할 수 있는 카나리 배포(canary release)나 롤백, 시스템의 동작 제어(외부 시스템 이중화 등)를 런타임에 쉽게 할 수 있습니다.
배달의민족을 비롯해 우아한형제들 내 다양한 서비스에서는 위에서 소개한 실험과 기능 플래그를 활용해 의사결정을 진행하거나 시스템의 안정성을 높이고 있습니다. 이번 글에서는 위에서 소개드린 실험과 기능 플래그가 실험 플랫폼을 통해 어떻게 제공되는지와 플랫폼이 어떻게 설계되었는지에 대해 소개드리려고 합니다.
실험 플랫폼 아키텍처
실험 플랫폼은 여러 서버들(그룹 분배, 실험 플랫폼 어드민, 게이트웨이 등)과 데이터의 추출 및 집계 두 가지 파트로 나누어서 살펴볼 수 있습니다. 먼저 서버 파트 아키텍처를 살펴보겠습니다.
서버 파트 아키텍처
실험 플랫폼 내부에 어떤 도메인이 존재하는지 살펴보겠습니다.
여기서 다루는 도메인은 인터넷 브라우저에서의 도메인이 아닌 해결하고자 하는 문제 영역을 의미합니다.
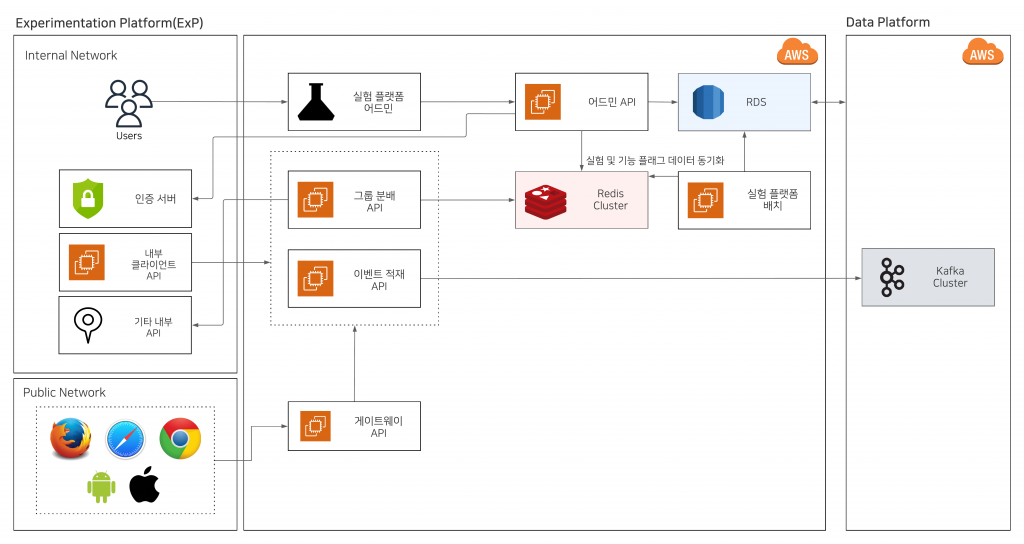
서버 파트 아키텍처는 크게 4개로 나눠 볼 수 있습니다.
- 실험 플랫폼 어드민
- 실험과 기능 플래그를 생성하고 관리할 수 있습니다.
- 실험에 설정된 목표에 따라 집계된 결과를 확인할 수 있습니다.
- 그룹 분배
- 사용자들이 어떤 그룹(A, B)에 할당되었는지를 연산하고 결과를 반환합니다.
- 이벤트 적재
- 데이터서비스실을 통해 로그가 수집되지 않는 경우 각 서비스에서 REST API를 통해 이벤트 데이터를 적재할 수 있도록 별도의 서버를 제공하고 있습니다.
- 게이트웨이
- 외부망에서 들어오는 그룹분배 혹은 이벤트 적재 요청을 내부망 서버로 라우팅하기 위한 역할을 수행합니다.
실험 데이터 수집/집계 아키텍처
실험 플랫폼에서는 데이터서비스실에서 제공하는 데이터 플랫폼과 데이터를 활용하고 있습니다.
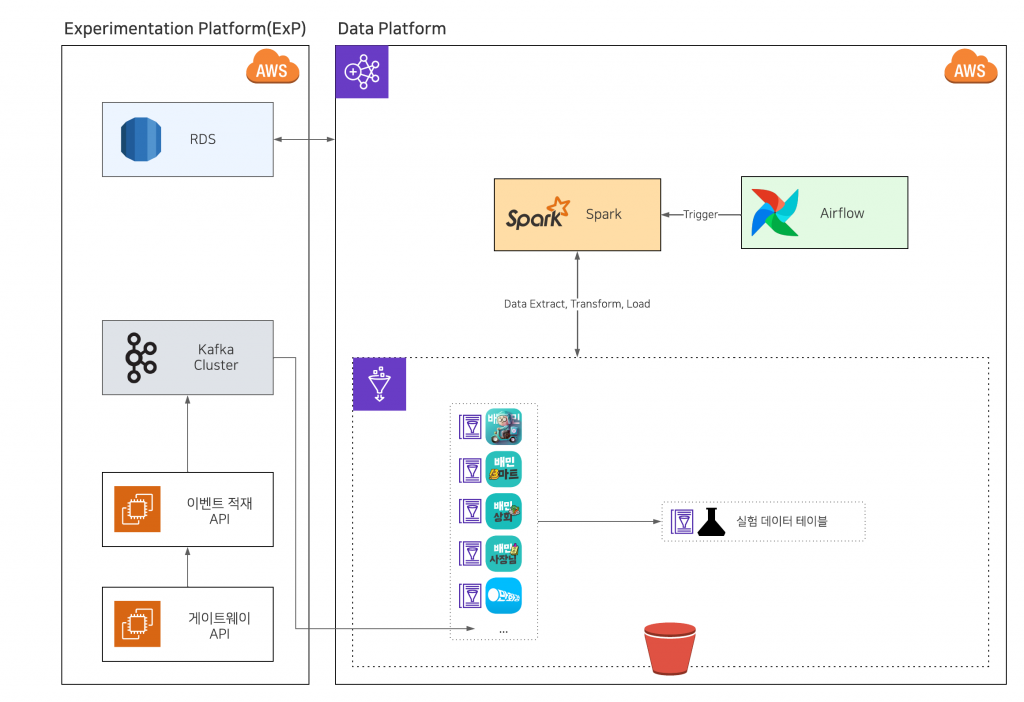
데이터 플랫폼에서 제공하는 Airflow를 활용해 우아한형제들 내부 여러 서비스의 로그를 활용하고 데이터를 추출하거나 집계하고 있습니다.
서버 파트와 데이터 추출 및 집계 파트 아키텍처를 간략하게 살펴보았습니다. 이제 각 파트별로 조금 더 자세한 내용을 다루어보겠습니다.
서버 파트
실험 플랫폼 어드민
실험 플랫폼 어드민에서는 서비스별로 실험이나 기능 플래그를 생성하고 관리할 수 있습니다.
실험과 기능 플래그는 실험 조건, 강제 할당, 진행 상태 등 다양한 정보를 가지고 있습니다.
기능 플래그의 경우 실험 대상 범위를 제외하면 실험과 동일한 정보와 구조를 가지고 있습니다. 따라서 실험에 대해서만 다루고 기능 플래그는 별도로 소개하겠습니다.
상태 정보와 기본 정보
실험은 준비, 일시정지, 진행 중, 종료, 보관이라는 상태를 가집니다. 각각의 상탯값이 무엇을 의미하는지 어드민 화면과 함께 살펴보겠습니다.

준비 및 일시정지
- 준비 및 일시정지 상태에서는 실험이 진행되고 있지 않기 때문에 기본 그룹(A)을 반환합니다.
진행 중
- 진행 중 상태에서는 설정된 실험 조건에 따른 그룹 분배 결과를 반환합니다.
종료
- 종료 상태에서는 설정된 위너(A, B 중 더 효과적이라고 판별된 그룹)를 반환합니다. 종료하기 위해서는 반드시 위너가 지정되어야 합니다.
보관
- 보관 상태의 실험은 더 이상 수정할 수 없습니다. 그룹분배 요청 시 기본 그룹(A)를 반환합니다. 실험이 종료된 이후 그룹 분배와 관련된 코드를 모두 제거하고 보관 상태로 변경해야 합니다.
다음으로는 실험이 가지는 기본 정보를 살펴보겠습니다.
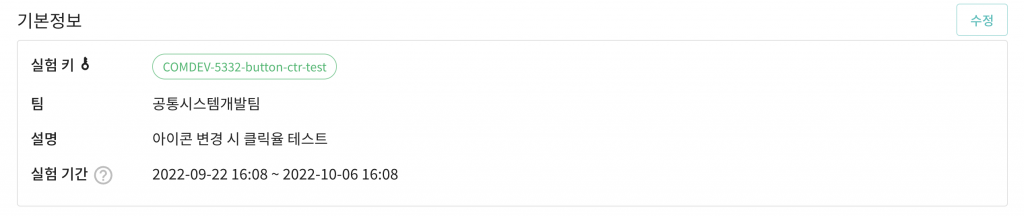
기본 정보에는 실험 키, 팀, 설명, 실험 기간 등을 표시합니다. 실험 키는 그룹분배 시 실험을 식별하기 위해 사용하는 변하지 않는 값입니다.
실험 강제 할당
강제 할당은 특정 조건에 해당하는 사용자를 강제로 특정 그룹에 지정할 수 있는 기능입니다. 실험에 존재하는 그룹의 지면들이 정상적으로 동작하는지 QA를 진행하기 위한 목적으로 사용할 수 있습니다.

위와 같이 설정하는 경우 0009608E9-0000-000E-000F-0000000000 라는 unitId(회원 번호나 디바이스 아이디 등의 식별자)를 가진 사용자는 설정된 다른 조건과 무관하게 그룹 B에 분배됩니다.
실험 조건
실험 조건에서는 실험에 존재하는 그룹의 비율 및 실험에 참여할 대상과 실험의 슬롯 범위를 지정할 수 있습니다. 실험 조건에 존재하는 항목들을 살펴보겠습니다.
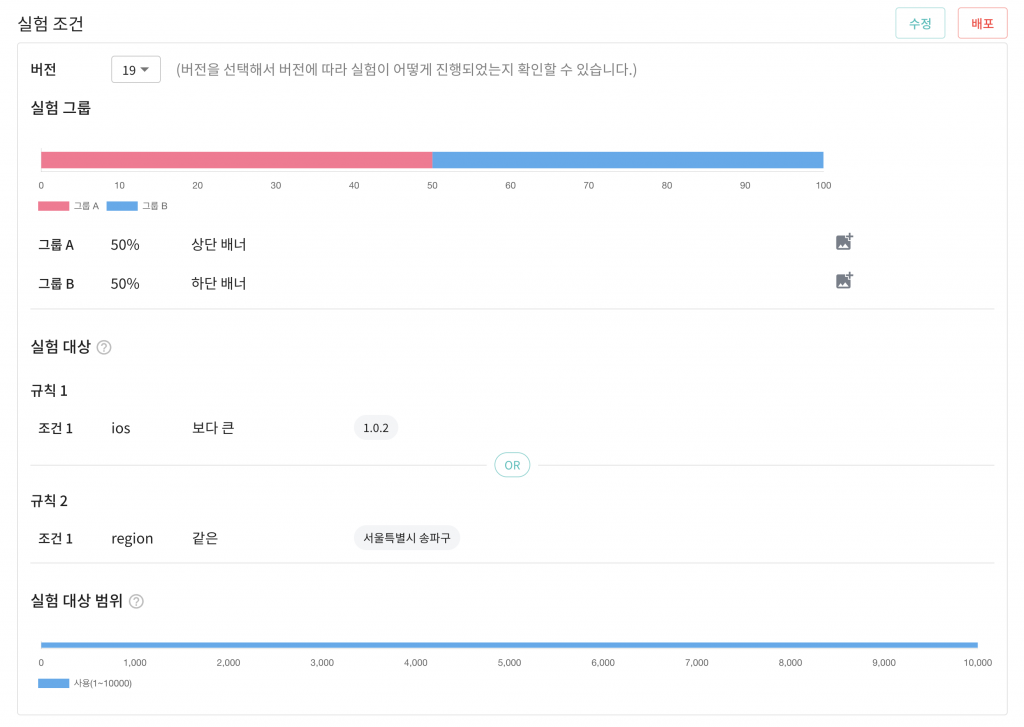
위 실험은 그룹 A, B 각각 50%의 비율을 가지며 설정된 실험 대상 규칙에 따라 아래와 같이 실험 대상이 제한됩니다.
- iOS 사용자이며 앱 버전이 iOS 1.0.2 이상인 사용자
- 또는 서울특별시 송파구에 거주하는 사용자
각각의 규칙은 OR 조건으로 설정되며 AND 조건으로 설정하고 싶은 경우 하나의 규칙 내에 여러 조건을 정의하면 됩니다.
위 조건을 충족하지 않는 사용자는 모두 기본 그룹(A)을 반환하게 되며 실험 대상에 포함되지 않기 때문에 결과 데이터 집계에서 제외됩니다.
실험이 진행중인 경우 조건을 수정하더라도 즉시 반영되지 않으며 배포를 통해 반영할 수 있습니다. 배포 시 실험의 버전 정보가 변경되며 이는 실험 결과 데이터에 반영됩니다.
사용자의 그룹이 어떻게 결정되는지, 동일 지면에서 여러 실험을 진행할 때 충돌을 방지하기 위한 실험 대상 범위가 어떻게 동작하는지에 대한 부분은 다음 단락에서 자세히 살펴보겠습니다.
그룹 분배와 슬롯
실험을 위해서는 사용자를 어떤 그룹(A, B)에 분배할지를 결정해야 하며 그룹 분배 결과는 실험의 조건이 변경되지 않는 한 같은 사용자에 대해 항상 같은 그룹분배 결과를 보장해야 합니다.
실험 플랫폼에서는 일관된 그룹분배 결과를 보장하기 위해 10,000개의 슬롯을 사용합니다. 슬롯은 실제로 물리적으로 존재하는 저장 공간이 아니며 사용자를 무작위로 할당하고 그룹을 나누기 위해 논리적으로만 존재하는 개념입니다.
슬롯 할당 알고리즘
슬롯 할당에는 사용자의 식별자 값(회원번호, 디바이스 아이디 등)을 이용합니다. 자세한 과정을 아래 그림을 통해 살펴보겠습니다.
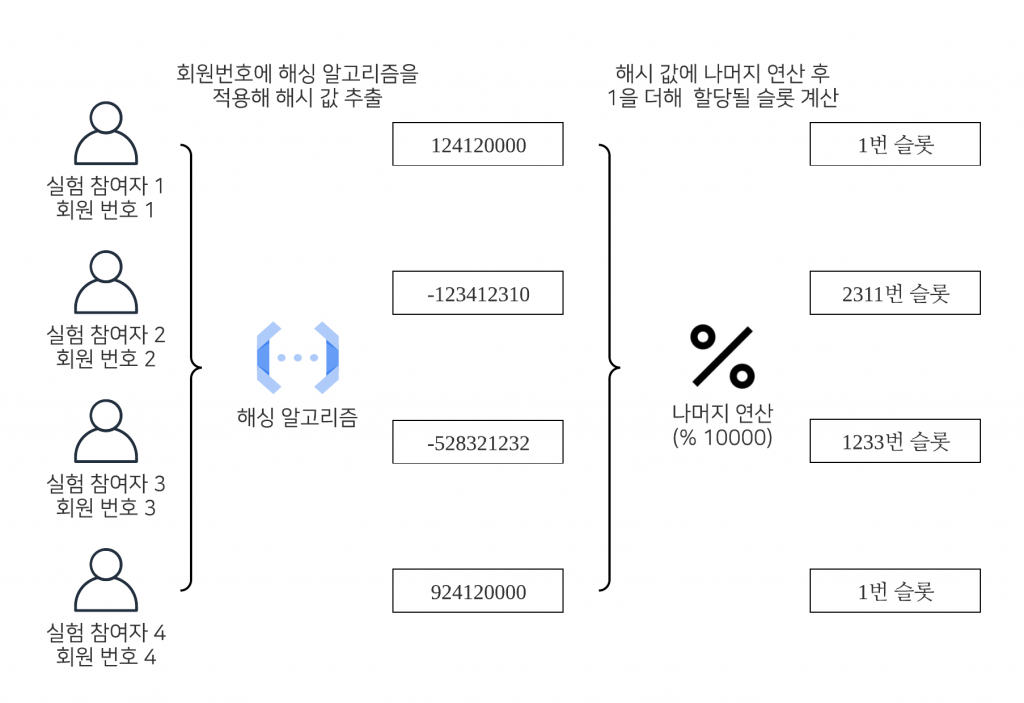
그림의 1번 참여자와 4번 참여자의 케이스처럼 회원 번호가 다른 사용자이더라도 동일한 슬롯에 할당될 수 있습니다.
- 유저의 식별자 값에 해싱 알고리즘을 적용해 해시값을 추출합니다.
- 도출된 해시값의 절댓값에 나머지 연산(% 10000)을 적용합니다.
- 슬롯은 1번부터 시작하기 때문에 나머지 연산의 결과값에 1을 더합니다.
위 과정을 통해 사용자의 슬롯을 할당할 수 있습니다. 이제 그룹별 설정된 비율에 따라 사용자가 어떤 그룹에 속하게 되는지 살펴보겠습니다.
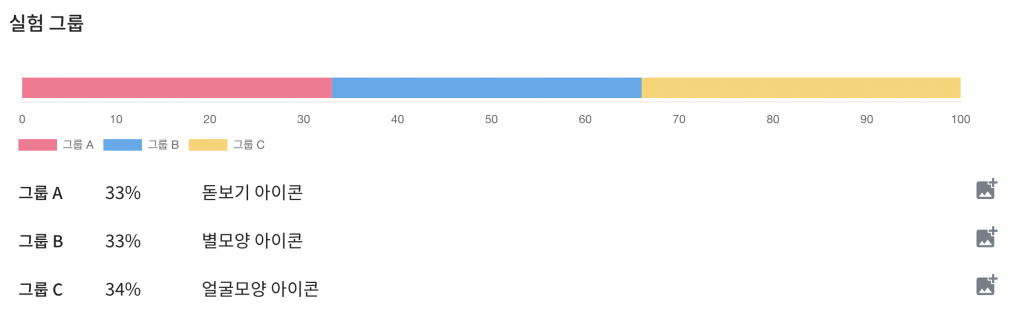
위 사진처럼 실험 조건이 설정된 경우라면 각각의 그룹은 아래와 같은 슬롯 범위를 가집니다.
- A 그룹(1 ~ 3,300번)
- B 그룹(3,301 ~ 6,600번)
- C 그룹(6,601번 ~ 10,000번)
특정 사용자가 3,400번 슬롯을 할당받는다면 해당 사용자는 B 그룹(3,301 ~ 6,600번 슬롯)에 속하게 됩니다.
실험 대상 범위와 실험 간 충돌
아래 예시 화면처럼 동일 지면 내에서 여러 실험이 동시에 진행되는 경우 각각의 실험이 서로의 결과에 영향을 줄 수 있습니다. 아주 작은 변경으로도 사용자가 클릭하거나 접근하는 지면이 달라질 수 있기 때문입니다.
실험 플랫폼에서는 실험간 충돌을 방지하기 위해서 각각의 실험이 가지는 슬롯의 범위를 변경할 수 있는 기능을 제공하고 있습니다.
실험 대상 범위를 이용해 어떻게 실험 간에 영향을 주지 않게 설정하는지 살펴보겠습니다. 우선 실험 대상 범위가 다르게 설정된 A와 B라는 두가지 실험이 있다고 가정하겠습니다.
실험 대상 범위가 설정된 첫번째 실험 A를 살펴보겠습니다.
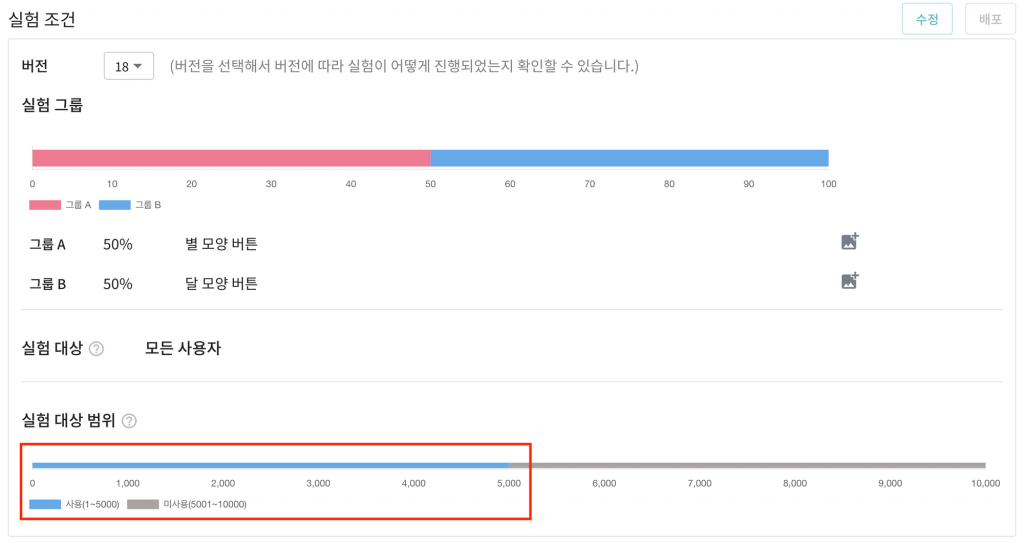
실험 A는 실험 대상 범위가 1 ~ 5,000번까지의 슬롯으로 지정되어 있습니다. 이런 경우라면 해당 실험 내의 그룹은 아래와 같은 슬롯 범위를 가지게 됩니다.
- A 그룹(1 ~ 2,500번)
- B 그룹(2,501 ~ 5,000번)
나머지 5,001 ~ 10,000번 슬롯에 할당된 유저에 대해 그룹 분배를 요청하는 경우 기본 그룹을 반환하며 해당 사용자의 데이터는 집계 대상에 포함되지 않습니다.
그리고 동일한 지면에서 진행되는 두번째 실험 B를 살펴보겠습니다.
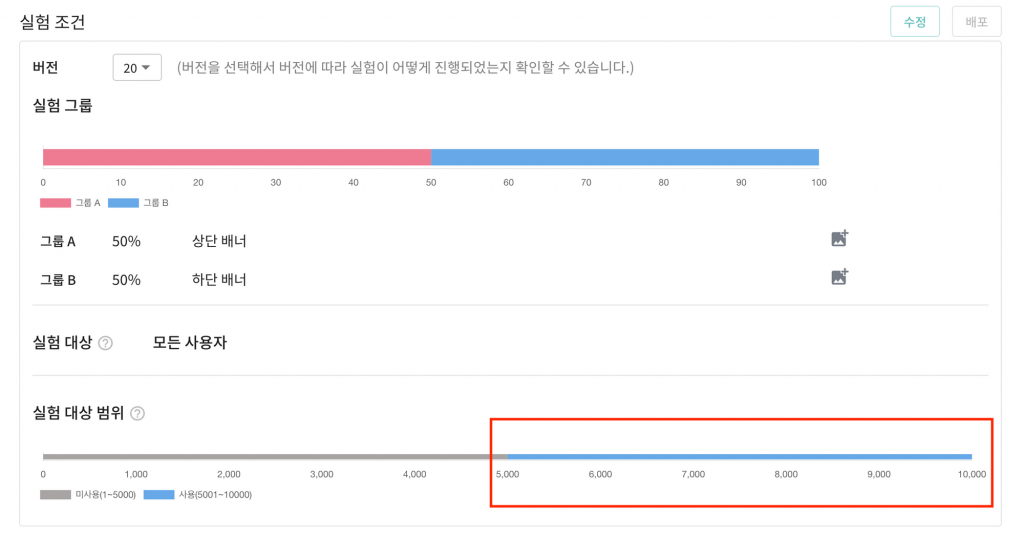
실험 B는 5,001 ~ 10,000번 까지의 슬롯을 가지고 있기 때문에 1 ~ 5,000번 까지 슬롯에 할당된 유저의 데이터는 집계 대상에 포함되지 않습니다.
결과적으로 실험 A는 1 ~ 5,000번 슬롯, B 실험은 5,001 ~ 10,000번까지의 슬롯에 할당된 유저에 대해서만 결과 집계 대상에 포함하기 때문에 서로의 실험 결과에 영향을 끼치지 않습니다.
위와 같이 인접한 지면에서 동시에 여러 실험을 진행하는 경우 각각 실험의 실험 대상 범위를 다르게 설정하면 실험 간 충돌로 인해 결과가 오염되는 것을 방지할 수 있습니다.
실험 대상 범위를 조정하는 경우 실험의 전체 모수가 줄어들게 됩니다. 이에 따라 실험 결과의 정확도가 떨어질 수 있습니다. 충분한 모수가 확보되지 않은 경우라면 충돌을 감수하더라도 전체 범위를 지정하는게 더 나은 판단일 수 있습니다.
실험 이벤트
실험 이벤트 탭에서는 실험에서 발생한 모든 이벤트의 유형을 조회하거나 등록할 수 있습니다. 수집된 이벤트 유형은 실험의 목표를 설정할 때 사용됩니다.
특정 유저가 주문을 하거나 장바구니에 진입, 배너를 클릭하는 모든 행위들은 실험 플랫폼에 수집됩니다. 수집된 이벤트 데이터를 통해 사용자의 클릭률, 전환율 등을 계산할 수 있습니다. 이벤트 데이터의 예시를 살펴보겠습니다.
| 실험 키 | 실험 버전 | 그룹 | 그룹 분배 사유 | 회원 번호 | 디바이스 아이디 | 이벤트 키 | 이벤트 설명 |
|---|---|---|---|---|---|---|---|
| COMDEV-9999-test | 1 | A | ASSIGNMENT | 1111 | 1111 | OrderEvent | 유저가 주문을 했을 때 발생하는 이벤트 |
| COMDEV-9999-test | 1 | B | ASSIGNMENT | 2222 | 2222 | OrderEvent | 유저가 주문을 했을 때 발생하는 이벤트 |
| COMDEV-9999-test | 1 | A | ASSIGNMENT | 3333 | 3333 | CartAccessEvent | 장바구니 진입 이벤트 |
| COMDEV-9999-test | 1 | A | ASSIGNMENT | 3333 | 3333 | BannerClickEvent | 배너 클릭 이벤트 |
| COMDEV-9999-test | 1 | B | ASSIGNMENT | 4444 | 4444 | CartAccessEvent | 장바구니 진입 이벤트 |
이벤트에는 실험 정보와 사용자의 정보, 그룹 분배 결과 그리고 어떤 행위를 수행했는지를 식별하기 위한 이벤트 키 정보가 저장됩니다.
수집된 모든 이벤트에서 이벤트 키로 중복을 제거하면 실험 내에서 발생한 모든 이벤트 유형들을 식별할 수 있습니다. 실험 플랫폼에서는 1시간마다 실험 내에서 발생한 이벤트 유형(이벤트 키, 이벤트 설명)을 추출하고 중복을 제거해 실험 플랫폼 데이터베이스에 저장하고 있습니다.
위 예시로 주어진 이벤트 데이터에서 이벤트 키로 중복을 제거하고 추출된 이벤트 유형 목록은 아래와 같습니다.
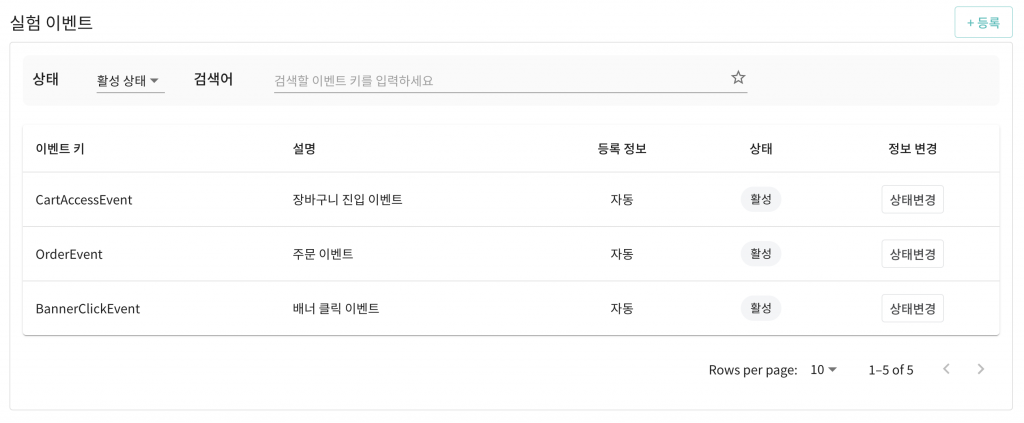
수집된 이벤트 유형을 이용해 실험에서 어떤 데이터를 확인할지에 대한 목표를 설정할 수 있습니다.
실험 목표
실험의 목표는 해당 실험 내에서 확인하고 싶은 데이터를 지정하기 위해 사용됩니다.
장바구니 진입 이후 주문한 사용자의 비율에 대한 지표를 보고 싶은 경우에 어떻게 목표를 설정해야 하는지 예시를 살펴보겠습니다.
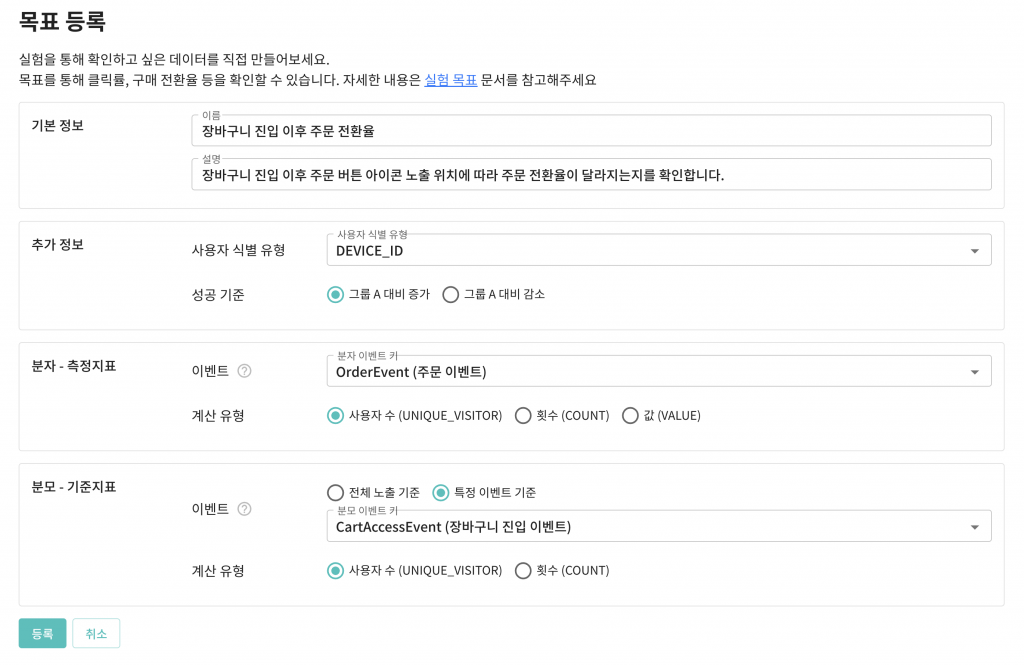
장바구니 진입 이후 주문한 사용자의 비율에 대한 지표를 보고 싶은 경우 아래와 같이 목표를 설정합니다.
- 분자 이벤트: 주문 이벤트(OrderEvent)
- 분모 이벤트: 장바구니 진입 이벤트(CartAccessEvent)
주문 이벤트 발생 건수에 장바구니 진입 이벤트 발생 건수를 나누어 장바구니 진입 이후 주문 이벤트 발생 비율을 구한다고 생각하면 쉽게 이해할 수 있습니다.
사용자 식별 유형과 계산 유형
추가 정보의 사용자 식별 유형이나 이벤트의 계산 유형에 따라 결과값이 크게 달라질 수 있기 때문에 보려는 결과에 따라 식별 유형이나 계산 유형값을 다르게 지정해야 합니다.
실험 플랫폼에서는 회원 번호, 앱의 경우 디바이스 아이디 혹은 기타 값(쿠키 등)에 대해서 사용자 식별 유형을 분리해서 데이터를 저장하고 있습니다. 계산 유형이 사용자 수인 경우 사용자 식별 유형에 따라 중복 제거 기준이 달라집니다.
사용자 식별 유형과 계산 유형에 따라 결과가 어떻게 달라지는지 실험에서 발생한 이벤트 데이터 예시와 표를 살펴보겠습니다.
| 실험 키 | 실험 버전 | 그룹 | 그룹 분배 사유 | 회원 번호 | 디바이스 아이디 | 이벤트 키 | 이벤트 설명 |
|---|---|---|---|---|---|---|---|
| exp-test | 1 | A | ASSIGNMENT | 1111 | 1000 | OrderEvent | 유저가 주문을 했을 때 발생하는 이벤트 |
| exp-test | 1 | A | ASSIGNMENT | 2222 | 1000 | OrderEvent | 유저가 주문을 했을 때 발생하는 이벤트 |
| exp-test | 1 | A | ASSIGNMENT | 3333 | 2000 | OrderEvent | 유저가 주문을 했을 때 발생하는 이벤트 |
| exp-test | 1 | A | ASSIGNMENT | 3333 | 2000 | OrderEvent | 유저가 주문을 했을 때 발생하는 이벤트 |
아래 표를 보면 사용자 식별 유형 및 계산 유형에 따라서 주문 이벤트(OrderEvent)의 발생 건수가 각각 다르게 집계됩니다.
| 사용자 식별 유형 | 계산 유형 | 주문 이벤트 발생 건수 |
|---|---|---|
| 디바이스 아이디 | 사용자 수 | 2건 |
| 회원 번호 | 사용자 수 | 3건 |
| 디바이스 아이디 | 횟수 | 4건 |
| 회원 번호 | 횟수 | 4건 |
계산 유형이 횟수인 경우 사용자 식별 유형은 결과값에 영향을 끼치지 않습니다.
설정된 목표를 이용해 어떻게 결과를 확인할 수 있는지 다음 단락에서 자세히 살펴보겠습니다.
실험 결과
실험 결과 탭에서는 설정된 목표를 기반으로 집계된 결과 데이터와 집계된 결과 데이터가 신뢰할 수 있는지를 확인할 수 있습니다. 실험 결과 화면을 살펴보겠습니다.
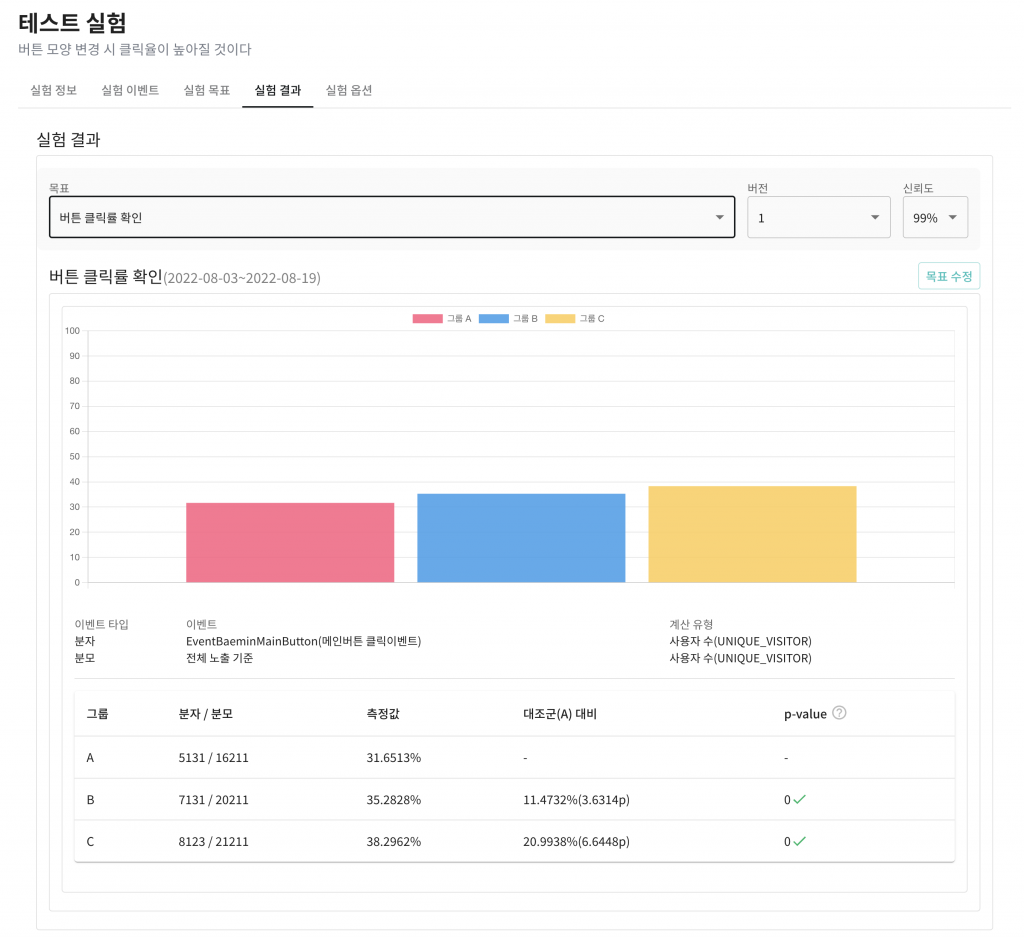
결과 데이터에는 그룹별 전환율과 A 그룹 대비 증감률 등을 확인할 수 있습니다. 또한 p-value를 통해 집계된 실험의 결과를 신뢰할 수 있는지도 확인할 수 있습니다.
결과 화면에 표시되는 p-value나 신뢰도 등의 용어가 생소할 수 있는데 용어에 대해 간략히 살펴보겠습니다.
신뢰도(신뢰 구간)와 유의 수준
결과 화면에서 신뢰도를 99%로 설정하면 유의 수준은 0.01(1 – 0.99)가 됩니다. 일반적으로 5%(신뢰도 95%)의 유의 수준(0.05)을 가장 많이 사용하며 결과 데이터의 정확도가 중요한 실험은 유의 수준을 낮게 설정해야 합니다.p-value
계산된 p-value는 0~1 사이의 값을 가집니다. 유의 수준보다 p-value가 낮으면 극단적 통계치가 관측될 확률이 낮다고 판단하여 도출된 실험의 결과를 신뢰할 수 있다고 판단할 수 있습니다.
대부분의 실험이 기존안(A) 대비 더 나은 조건이 있는지를 확인하는 방법으로 설계되기 때문에 실험 플랫폼에서는 Z 검정을 통해 p-value를 계산하고 있습니다. 검정에 대한 부분은 이후 데이터 검정과 관련된 부분에서 간단하게 다루겠습니다.
그룹 분배 서버
그룹 분배 서버는 사용자 정보(식별자 및 태그 정보 등)와 실험 키를 넘겨주면 사용자가 어떤 그룹에 분배되었는지 결과를 내려주는 역할을 수행하고 있습니다. 그룹 분배 요청과 응답에 어떤 값들이 포함되는지 살펴보겠습니다.
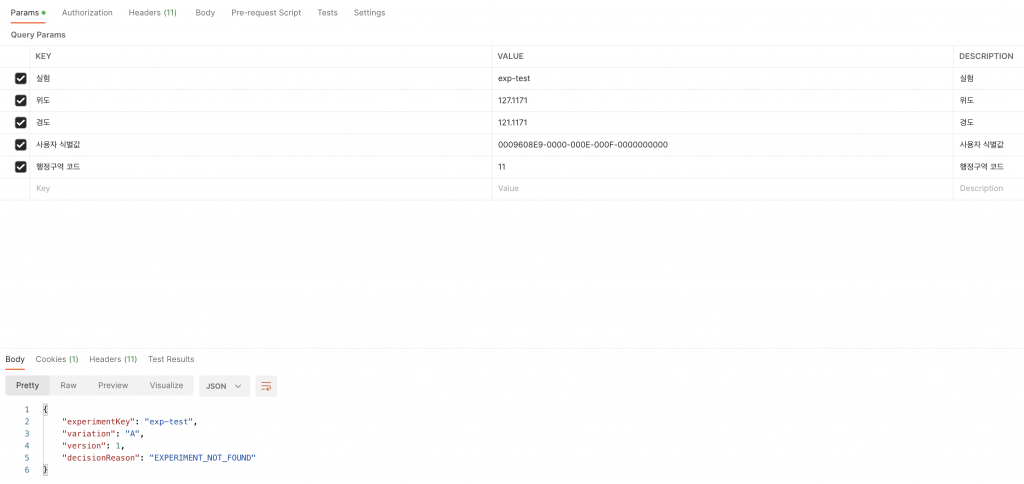
실험 키와 사용자 식별값은 필숫값입니다. 사용자와 관련된 위, 경도 등의 값은 필수값은 아니지만 실험 대상 규칙에 사용자의 정보(지역, 나이, 성별 등)와 관련된 규칙을 정의했다면 해당 값을 넣어 그룹 분배를 요청해야 원하는 그룹 분배 결과를 얻을 수 있습니다.
응답에는 실험 키, 분배 결과 그룹, 버전 정보 및 그룹 분배가 결정된 사유가 포함됩니다. 위의 예시는 실험을 찾을 수 없어 기본 그룹(A)이 반환되었으며 그룹 분배 사유도 실험을 찾을 수 없다고(EXPERIMENT_NOT_FOUND) 응답하고 있습니다.
그룹 분배 처리 과정
그룹 분배가 어떤 흐름으로 처리되는지 플로우 차트와 코드를 살펴보겠습니다.
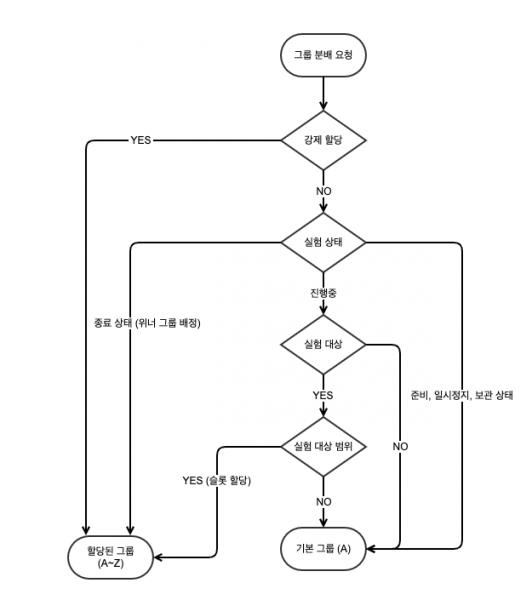
위 플로우 차트에 있는 마름모 모양의 요소들(강제 할당, 실험 상태, 실험 대상, 실험 대상 범위)은 그룹 분배와 관련된 정책을 의미하며 모두 인터페이스를 구현합니다. 해당 인터페이스의 variation 메소드는 해당 정책 내에서 그룹분배 결과를 반환할 수 있는 경우 결과를 반환하고 그룹분배 결과를 도출할 수 없는 경우 null을 반환합니다.
interface VariantAssignmentPolicy {
suspend fun variation(info: VariantAssignmentInfo): VariantAssignmentResult?
}각각의 그룹분배 정책들은 순서대로 처리되며 null을 반환하는 경우 다음 정책으로 처리를 넘깁니다.
해당 인터페이스의 구현체 목록과 순서는 아래와 같습니다.
- ForceAssignmentPolicy (실험 강제 할당이 설정된 경우 처리 정책)
- StatusPolicy (실험 상태에 따른 처리 정책)
- TargetPolicy (실험 대상이 설정된 경우 처리 정책)
- SlotAssignmentPolicy (실험 대상 범위와 사용자의 슬롯과 실험에 설정된 그룹 비율에 따른 처리 정책)
정책들의 처리 순서는 스프링 프레임워크의 Order 어노테이션(annotation)을 통해 관리되고 있습니다.
@Order(1)
@Component
class ForceAssignmentPolicy : VariantAssignmentPolicy {
suspend fun variation(info: VariantAssignmentInfo): VariantAssignmentResult?
}
@Order(2)
@Component
class StatusPolicy : VariantAssignmentPolicy {
suspend fun variation(info: VariantAssignmentInfo): VariantAssignmentResult?
}
@Order(3)
@Component
class TargetPolicy : VariantAssignmentPolicy {
suspend fun variation(info: VariantAssignmentInfo): VariantAssignmentResult?
}
@Order(4)
@Component
class SlotAssignmentPolicy : VariantAssignmentPolicy {
suspend fun variation(info: VariantAssignmentInfo): VariantAssignmentResult?
}스프링 프레임워크의 의존성 주입을 통해 List를 주입받아 그룹분배를 처리하고 있습니다. 해당 부분의 코드를 살펴보겠습니다.
suspend fun List<VariantAssignmentPolicy>.variationProcess(info: VariantAssignmentInfo): VariantAssignmentResult =
runCatching {
this.asFlow()
.mapNotNull { it.variation(info) }
.take(1)
.first()
}.getOrElse { VariantAssignmentResult.serverError(info.key, info.version) }실험 플랫폼에서는 코루틴을 사용하고 있습니다. take를 이용해 첫번째 그룹 분배 결과가 반환되는 경우 실행을 취소하고 해당 값을 즉시 그룹분배 결과를 반환하도록 구현되어 있습니다.
에러가 발생하는 경우는 분배 사유가 서버 에러(SERVER_ERROR)로 기록된 기본 그룹(A)을 반환합니다.
부록 A. Webflux와 Blocking Call
그룹 분배 서버에서 제공하는 API들은 Blocking Call이 필요하지 않습니다. 따라서 적은 스레드로 최대한 효율을 낼 수 있는 Webflux를 사용하고 있습니다.
Webflux에서는 스레드가 중단되지 않는다는 전제 하에 작은 스레드 풀(이벤트 루프 워커)을 이용해 요청을 처리합니다. 따라서 Blocking Call로 인해 스레드의 중단이 발생하는 경우 MVC보다 성능이 더 나오지 않을 가능성이 높습니다. Webflux를 사용할 때 의도하지 않게 Blocking Call이 발생할 수 있는 몇가지 부분을 살펴보겠습니다.
logging과 Blocking I/O
실험 플랫폼에서는 logback을 사용하고 있습니다. logback을 사용하는 경우 일반적으로 사용하는 Appender들은 Blocking 형태로 동작합니다. Webflux의 메인 스레드가 차단되는 것을 막으려면 AsyncAppender로 기존에 사용하던 Appender를 감싸주고 neverBlock 옵션을 true로 주어야 합니다.
<appender name="APP_ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="APP"/>
<includeCallerData>false</includeCallerData> <!-- 로그 호출 정보 포함여부 true면 성능 저하가 있다. -->
<neverBlock>true</neverBlock>
</appender>AsyncAppender의 코드를 한번 살펴보겠습니다.
public class AsyncAppenderBase<E> extends UnsynchronizedAppenderBase<E> implements AppenderAttachable<E> {
BlockingQueue<E> blockingQueue;
// ...
private void put(E eventObject) {
if (neverBlock) {
blockingQueue.offer(eventObject);
} else {
putUninterruptibly(eventObject);
}
}
private void putUninterruptibly(E eventObject) {
boolean interrupted = false;
try {
while (true) {
try {
blockingQueue.put(eventObject);
break;
} catch (InterruptedException e) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}
// ...
}코드를 살펴보면 큐에 넣는 부분까지는 메인 스레드가 수행하는 부분을 확인할 수 있습니다. 여기서 neverBlock 옵션을 true로 주지 않으면 offer가 아니라 putUninterruptibly을 사용하면서 blockingQueue에 공간이 날 때 까지 스레드가 대기하면서 메인 스레드가 차단됩니다.
neverBlock 옵션을 사용할 때 주의할 점이 있습니다. 큐가 가득 찬 경우 로그가 유실됩니다. 이 점에 유의해서 로그의 중요도에 따라 queue 사이즈를 늘리거나 neverBlock 옵션을 끄고 사용해야 합니다.
코드를 이어서 살펴보면 로그를 남기는 작업을 AsyncAppender-Worker-스레드가 수행하는 것을 확인할 수 있습니다.
public class AsyncAppenderBase<E> extends UnsynchronizedAppenderBase<E> implements AppenderAttachable<E> {
// ...
BlockingQueue<E> blockingQueue;
Worker worker = new Worker();
@Override
public void start() {
// ...
worker.setDaemon(true);
worker.setName("AsyncAppender-Worker-" + getName());
// make sure this instance is marked as "started" before staring the worker Thread
super.start();
worker.start();
}
class Worker extends Thread {
public void run() {
// ...
}
}
}blockingQueue에 넣는 eventObject에 이벤트 루프 스레드(reactor-http-nio)의 정보가 기록되기 때문에 로그에는 AsyncAppender-Worker 스레드가 아닌 이벤트 루프 스레드의 이름이 출력됩니다.
[reactor-http-nio-2] : asyncAppender logging test [reactor-http-nio-3] : asyncAppender logging test
코루틴과 runBlocking
코루틴을 사용해보신 경우 예제 코드 등에서 runBlocking이 사용되는 것을 볼 수 있습니다. runBlocking을 사용하는 경우 해당 메소드를 실행하는 스레드가 차단되기 때문에 일반적인 경우에는 사용하면 안됩니다.
fun main() = runBlocking {
launch {
delay(1000L)
println("World!")
}
println("Hello")
}이미 코루틴이 익숙하신 분들은 당연하게 생각되는 내용이지만 처음 Webflux나 코루틴 등의 기술을 사용하는 경우 위와 같은 부분을 인지하지 못하는 경우가 많습니다.
Blocking Call이 발생할 수 있는 간단한 몇가지 사례를 살펴보았습니다. Webflux에서 Blocking Call은 성능에 치명적이므로 BlockHound 등을 활용해 Blocking Call 발생 여부를 체크하면서 개발을 진행해야 합니다.
부록 B. 그룹 분배 서버 성능 개선
그룹 분배 서버는 우아한형제들 내 전체 서비스의 그룹 분배 요청을 처리합니다. 따라서 그룹 분배 서버에서 지연이 발생하면 우아한형제들 내부에서 실험을 진행하거나 기능 플래그를 사용하는 모든 클라이언트에 영향을 줄 수 있습니다.
이 때문에 그룹 분배 API 서버는 높은 처리량과 빠른 처리 속도를 보장해야 합니다. 실험 플랫폼을 개발하면서 성능을 개선하기 위해 했던 몇가지 작업들을 살펴보겠습니다.
캐싱 적용
그룹 분배 결과를 얻기 위해서는 실험이나 기능 플래그의 데이터(그룹 비율이나 강제 할당 정보 등)가 필요합니다. 해당 데이터는 Redis에 저장되어 있어 그룹 분배를 호출할 때 매번 Redis에 요청을 보내게 됩니다. 이 때 Redis의 부하를 줄이고 그룹 분배 API의 성능을 향상시키기 위해서 로컬 캐싱을 적용했습니다.
<?xml version="1.0" encoding="UTF-8"?>
<config xmlns='http://www.ehcache.org/v3'>
<cache alias="experiment">
<value-type>domain.Experiment</value-type>
<expiry>
<ttl>30</ttl>
</expiry>
<resources>
<heap unit="entries">100</heap>
</resources>
</cache>
<cache alias="experiments">
<value-type>java.util.List</value-type>
<expiry>
<ttl>30</ttl>
</expiry>
<resources>
<heap unit="entries">50</heap>
</resources>
</cache>
<cache alias="featureFlag">
<value-type>domain.FeatureFlag</value-type>
<expiry>
<ttl>30</ttl>
</expiry>
<resources>
<heap unit="entries">100</heap>
</resources>
</cache>
</config>실험이나 기능 플래그의 조건을 변경했을 때 바로 반영이 되어야 하기 때문에 캐시의 만료 시간(30초)을 짧게 설정했습니다.
Coroutine과
@Cacheable
Spring 환경에서 캐싱을 적용할 때 보통@Cacheable어노테이션을 주로 활용합니다. 하지만 Coroutine을 사용하는 경우에 해당 어노테이션을 사용할 수 없습니다. spring-kotlin-coroutine 라이브러리를 활용하면@Cacheable을 사용할 수 있으나 프로젝트가 잘 관리되고 있지 않아 번거롭지만 아래와 같이 CacheManager를 사용해 캐싱을 적용했습니다.@Component class ExperimentLoadCacheAdapter( @Qualifier("experimentLoadAdapter") private val loadExperimentPort: LoadExperimentPort, cacheManager: CacheManager, ) : LoadExperimentPort { private val experimentCache: Cache = checkNotNull(cacheManager.getCache("experiment")) override suspend fun findByKey(key: String): Experiment? = experimentCache.getOrPut(key) { loadExperimentPort.findByKey(key) } inline fun Cache.getOrPut(key: String, callback: () -> T?): T? { /** **/ } }
그룹분배 서버는 특성상 실험이나 기능 플래그의 조건이 변경되기 전에는 동일한 파라미터에 대해서 응답이 변경되지 않습니다. 이런 특성을 활용해 Cache-Control 등의 헤더를 응답하고 Nginx나 CloudFront를 활용해 서버의 부하를 줄이는 방안도 검토하고 있습니다.
WebClient와 reactor.netty Metric 이슈
WebFlux 환경에서는 대부분 HTTP 통신을 위해 WebClient를 사용하며 실험 플랫폼에서도 아래와 같이 WebClient를 사용해 HTTP 요청을 처리하고 있습니다.
class Class(
webClientBuilder: WebClient.Builder,
clientHttpConnector: ClientHttpConnector,
) {
private val webClient =
webClientBuilder.uriBuilderFactory(DefaultUriBuilderFactory("http://localhost:8080"))
.clientConnector(clientHttpConnector)
.build()
fun test() {
webClient
.get()
.uri("/그룹 분배 API 경로?파라미터1=1&파라미터2=2")
// ...
}
}위와 같이 path와 queryParam을 넣고 요청하는 경우 대시보드에서 아래와 같이 수 없이 많은 메트릭이 노출되는 것을 확인할 수 있습니다.
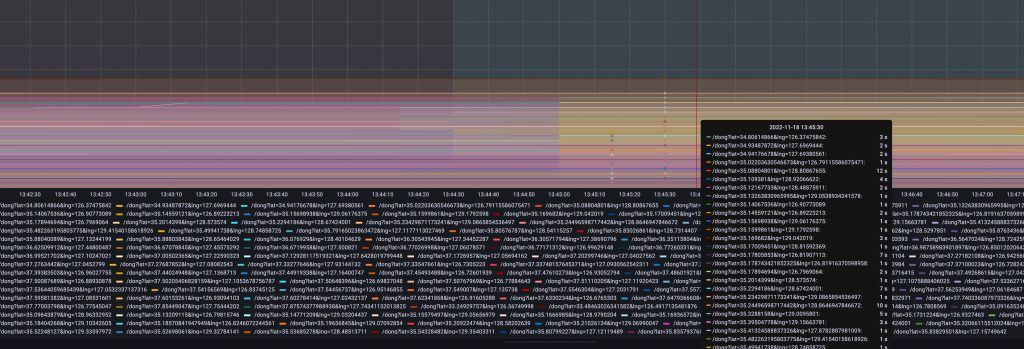
이는 WebClient.Builder를 이용해 클라이언트를 생성할 때 지정하는 clientConnector와 연관이 있습니다. Webflux 환경에서는 위와 같이 선언하면 아래 구현체를 사용하게 됩니다.
public class ReactorClientHttpConnector implements ClientHttpConnector {
private final HttpClient httpClient;
}
그리고 해당 구현체의 내부에서는 HttpClient 인터페이스가 존재하며 사용하는 HttpClient의 구현체는 reactor netty의 HttpClientConnector입니다.
package reactor.netty.http.client;
class HttpClientConnect extends HttpClient {}이 HttpClient와 관련해서 Reactor Netty HTTP Client 6.12. Metrics 문서의 내용을 살펴보면 템플릿 형태로 변환하지 않고 URI를 사용하면 각각 고유한 태그를 생성하고 이로 인해 메트릭에 대해 많은 메모리를 사용하거나 CPU 오버헤드를 유발할 수 있다는 내용이 포함되어 있습니다.
해당 내용을 확인한 이후 아래와 같은 형태로 코드를 변경해 메트릭이 정상적으로 노출되도록 변경했습니다.
webClient
.get()
.uri("/그룹 분배 API 경로") {
it
.queryParam("파라미터 1", listOf("1"))
.queryParam("파라미터 2", "2")
.build()
}아래와 같이 path를 사용하면 내부 메소드의 구현 차이로 동일하게 메트릭 문제가 발생합니다.
webClient .get() .uri { it.path("/그룹 분배 API 경로") .queryParam("파라미터 1", listOf("1")) .queryParam("파라미터 2", "2") .build() }
파라미터 템플릿이 적용되지 않은 노란색 API의 latency가 메트릭 이슈가 없는 초록색 API의 latency에 비해 튀는 걸 확인할 수 있습니다.
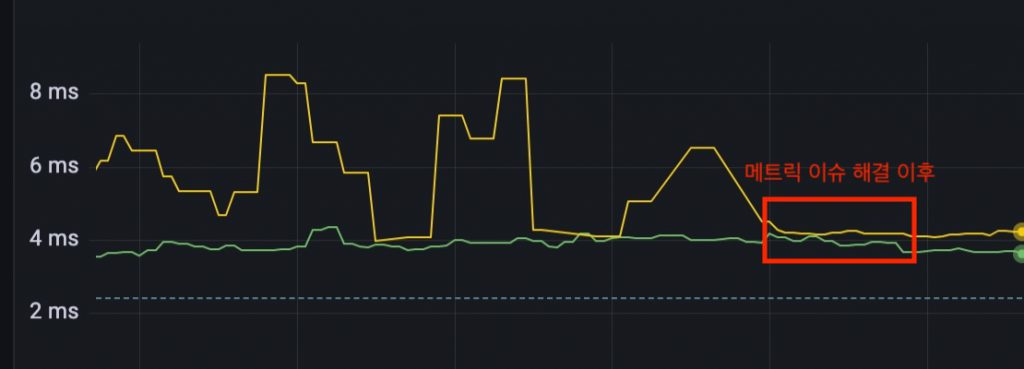
이후 메트릭 문제를 수정하고 배포한 이후에 안정적으로 latency가 유지되는 모습을 확인할 수 있습니다.
위 내용은 Spring Boot 2.6.3 버전 기준이며 Spring Boot 2.4 이상 버전에서 발생합니다.
JVM Warm Up 자동화
그룹 분배 서버는 Kotlin과 Spring을 사용하며 JVM의 JIT Compiler 특성상 애플리케이션이 시작된 직후에 트래픽을 받게되면 API의 지연이 발생하는 문제가 있습니다.
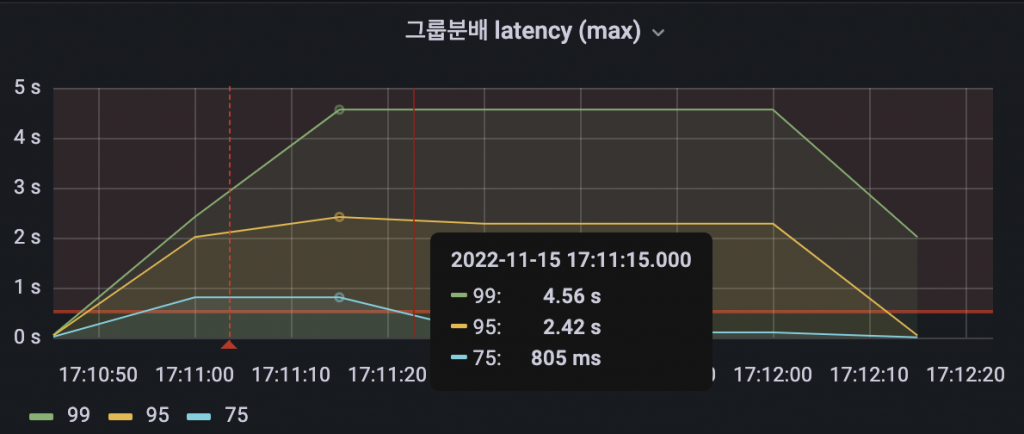
배포 직후에 그룹 분배 요청의 처리가 지연되는 경우가 생겨 기본 그룹(A)을 반환받거나 클라이언트쪽에 지연이 전파되는 경우가 일부 발생했습니다. 문제를 해소하기 위해서 헬스체크가 완료되어 트래픽을 받기 이전에 웜업을 완료해야 했습니다.
ApplicationReadyEvent 이벤트를 받은 이후 실험과 기능 플래그에 대한 그룹분배 호출을 수행합니다. 수행이 완료된 이후에는 WarmUpCompleteEvent 이벤트를 발행합니다.
@EventListener
override fun onApplicationEvent(event: ApplicationReadyEvent) {
val warmUpExperimentJob = warmUpCoroutineScope.launch { repeat(1000) { variationByGroups() } }
val warmUpFeatureFlagJob = warmUpCoroutineScope.launch { repeat(1000) { variationFeatureFlag() } }
runBlocking {
warmUpExperimentJob.join()
warmUpFeatureFlagJob.join()
eventPublisher.publishEvent(WarmUpCompleteEvent())
}
}여기서는 실험과 기능 플래그에 대한 그룹 분배 요청을 천번씩 호출하도록 단순하게 구성해두었지만 서비스의 특성이나 Compilation Level을 고려해 웜업 시 호출할 메서드나 횟수를 구성해야 합니다.
그리고 커스텀 헬스체크 인디케이터를 추가했습니다. 해당 인디케이터는 WarmUpCompleteEvent 이벤트를 수신한 이후에 헬스체크가 성공하도록 구성되어 있습니다.
@Component
@ConditionalOnEnabledHealthIndicator("warm-up")
class JvmWarmUpHealthIndicator : ReactiveHealthIndicator {
private var isWarmUpCompleted = false
@EventListener
fun onWarmUpEvent(event: WarmUpCompleteEvent) {
this.isWarmUpCompleted = true
}
override fun health(): Mono<Health> {
return if (isWarmUpCompleted) {
Mono.just(Health.up().build())
} else {
Mono.just(Health.down().build())
}
}
}이후 프로퍼티에 기본 헬스체크 이외에 웜업 인디케이터를 바라보는 설정을 추가하면 웜업이 완료된 이후에 헬스체크가 성공하게 됩니다.
management:
health:
warm-up:
enabled: true이후에는 웜업이 완료되고 일정 시간이 지난 후 트래픽을 받기 때문에 지연 없이 안정적으로 트래픽을 처리할 수 있었습니다.
이벤트 적재 서버
실험 플랫폼에서는 기본적으로 우아한형제들 내부의 로그를 활용해 실험에 필요한 데이터를 추출하는 구조를 가지고 있습니다. 이 때문에 데이터서비스실을 통해 로그를 수집하고 있지 않은 서비스의 경우 실험 플랫폼을 통해 데이터를 수집하거나 집계할 수 없는 문제가 존재합니다.
실험 플랫폼에서는 로그를 수집하지 않는 팀들에서도 실험 플랫폼을 사용할 수 있도록 API를 통해 이벤트 데이터를 적재하는 기능을 제공하고 있습니다.
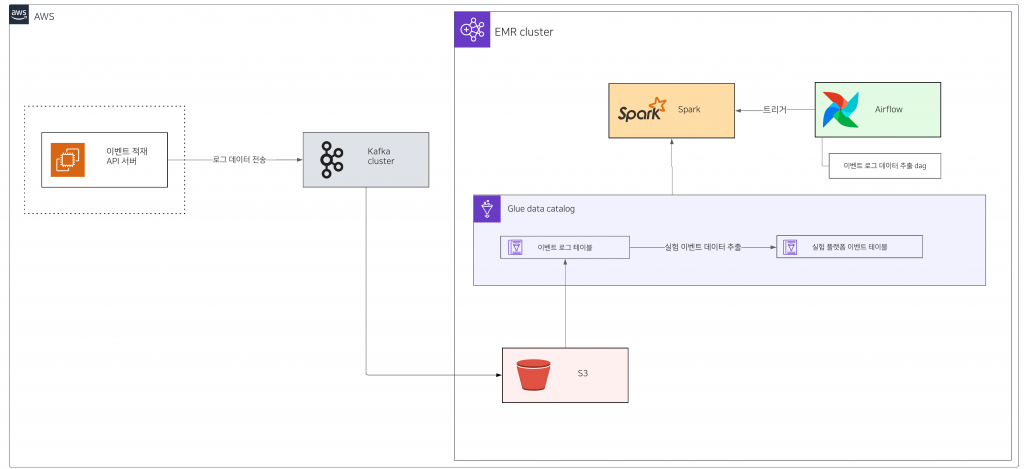
이벤트 데이터 적재 데이터를 받아 로그로 남기고 데이터서비스실에서 제공하는 내부의 파이프라인을 통해 최종적으로 이벤트 로그 테이블에 적재됩니다.
이벤트 로그 테이블에 적재된 데이터는 Airflow의 dag를 통해 1시간마다 실험 플랫폼 이벤트 테이블로 추출되고 있습니다.
데이터 추출/집계 파트
실험 플랫폼에서는 사내에서 제공하는 데이터플랫폼을 활용해 다양한 서비스들의 로그 데이터를 실험 플랫폼 이벤트 테이블(Glue Data Catalog Table)로 추출하거나 필요한 데이터를 실험 플랫폼 데이터베이스(RDS)로 전달하는 작업을 처리하고 있습니다.
데이터플랫폼에서 제공하는 Airflow에는 실험 플랫폼에서 아래 목적을 수행하기 위한 dag들이 정의되어 있습니다.
실험 플랫폼 이벤트 데이터 추출
- 사내 다양한 서비스(배달의민족, B마트)와 이벤트 적재 API를 통해 쌓인 로그 정보를 기반으로 실험에 필요한 이벤트 데이터를 추출하고 실험 플랫폼 이벤트 테이블(Hive 테이블)에 적재합니다.
실험 이벤트 유형 추출
- 실험 플랫폼 이벤트 테이블에 적재된 데이터를 기반으로 중복이 제거된 실험 별 이벤트 유형(장바구니 진입, 주문 전환 등)을 실험 플랫폼 데이터베이스(실험 플랫폼 RDB)에 적재합니다.
실험 결과 데이터 집계
- 실험 플랫폼 어드민에 설정된 실험 목표와 실험 플랫폼 이벤트 테이블 데이터를 기반으로 결과를 집계하고 실험 플랫폼 데이터베이스(실험 플랫폼 RDB)에 적재합니다.
각각의 dag들 내부에 어떤 task들이 존재하는지 살펴보겠습니다.
실험 플랫폼 이벤트 데이터 추출과 적재
실험 플랫폼에서는 우아한형제들 내부의 여러 서비스들(배달의민족, B마트, 상회 등)과 실험 플랫폼 이벤트 적재 API의 결과로 기록된 로그에서 실험에 필요한 데이터들을 추출하고 적재하는 작업을 수행하고 있습니다.
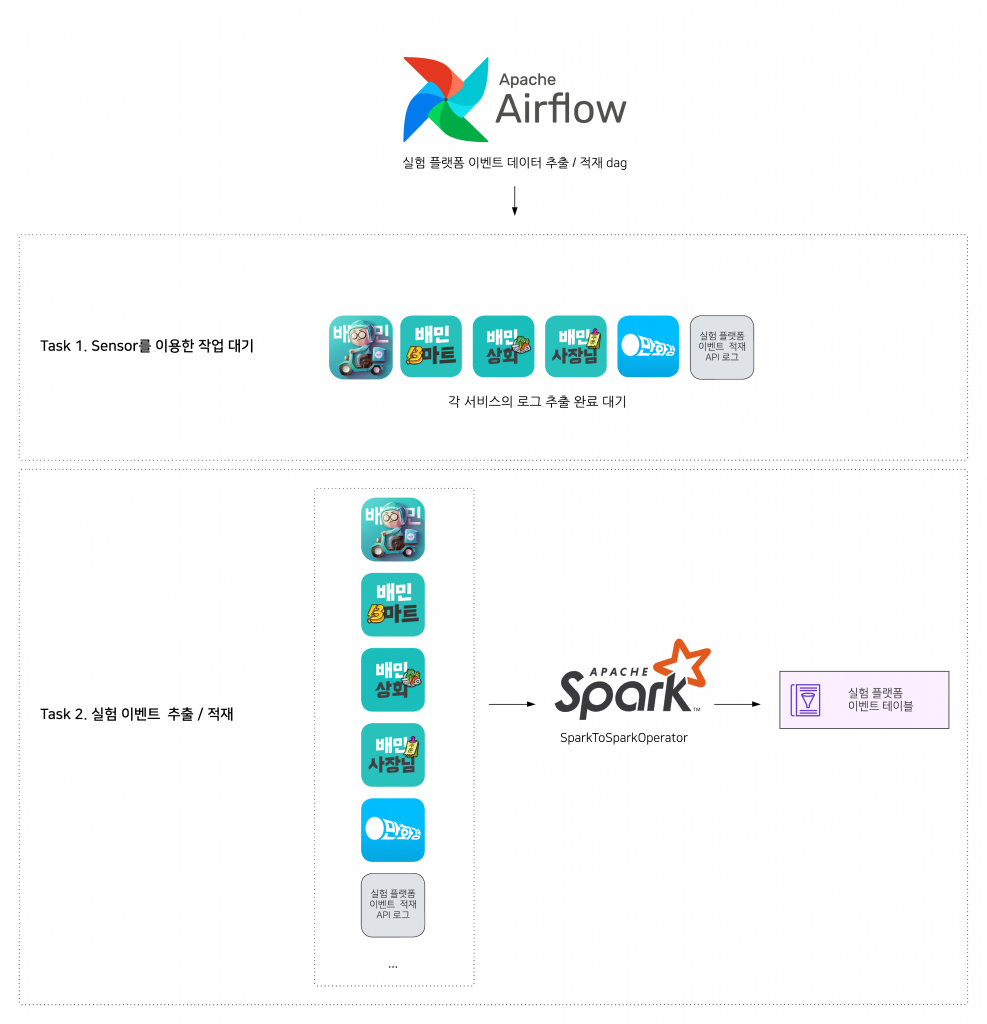
- 서비스별 로그 적재를 위한 dag의 task가 완료되었는지 Sensor를 통해 체크하고 대기합니다.
- 서비스별 로그 테이블에서 실험을 위한 데이터를 추출하는 작업을 진행하고 추출된 결과 데이터를 실험 플랫폼 이벤트 Hive 테이블로 적재합니다.
이제 실험 플랫폼 이벤트 테이블을 통해 실험에서 발생한 이벤트 유형을 추출하거나 결과를 집계할 수 있습니다.
SparkToSparkOperator는 데이터플랫폼에서 제공하는 Hive 테이블의 데이터를 읽어 Hive 테이블에 쓸 수 있는 기능을 제공하는 Operator입니다.
실험 이벤트 유형 추출과 적재
실험에서 어떤 지표(주문 전환율 등)를 볼 것인지 목표를 설정하기 위해서는 실험 내에서 어떤 이벤트가 발생했는지를 식별할 수 있어야 합니다.
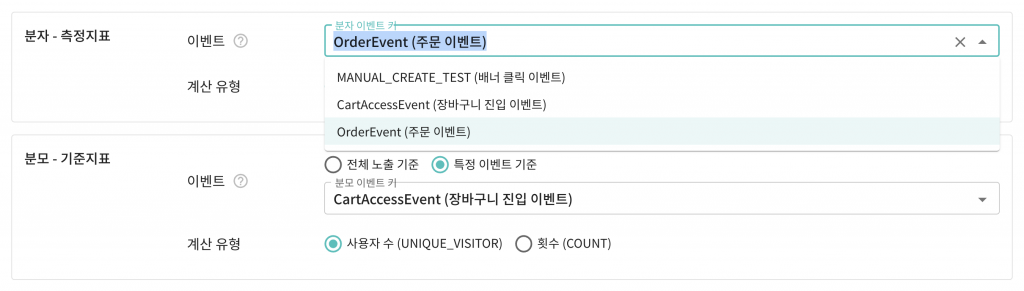
실험 플랫폼 어드민에서는 목표를 설정할 때 실험에서 발생한 이벤트 유형을 확인하고 선택할 수 있습니다.
이는 실험 플랫폼 이벤트 테이블의 데이터를 기준으로 발생한 이벤트 유형을 추출하고 실험 플랫폼 RDB로 적재하는 작업을 주기적으로 수행하고 있기 때문입니다. 해당 dag가 어떻게 동작하고 있는지 살펴보겠습니다.
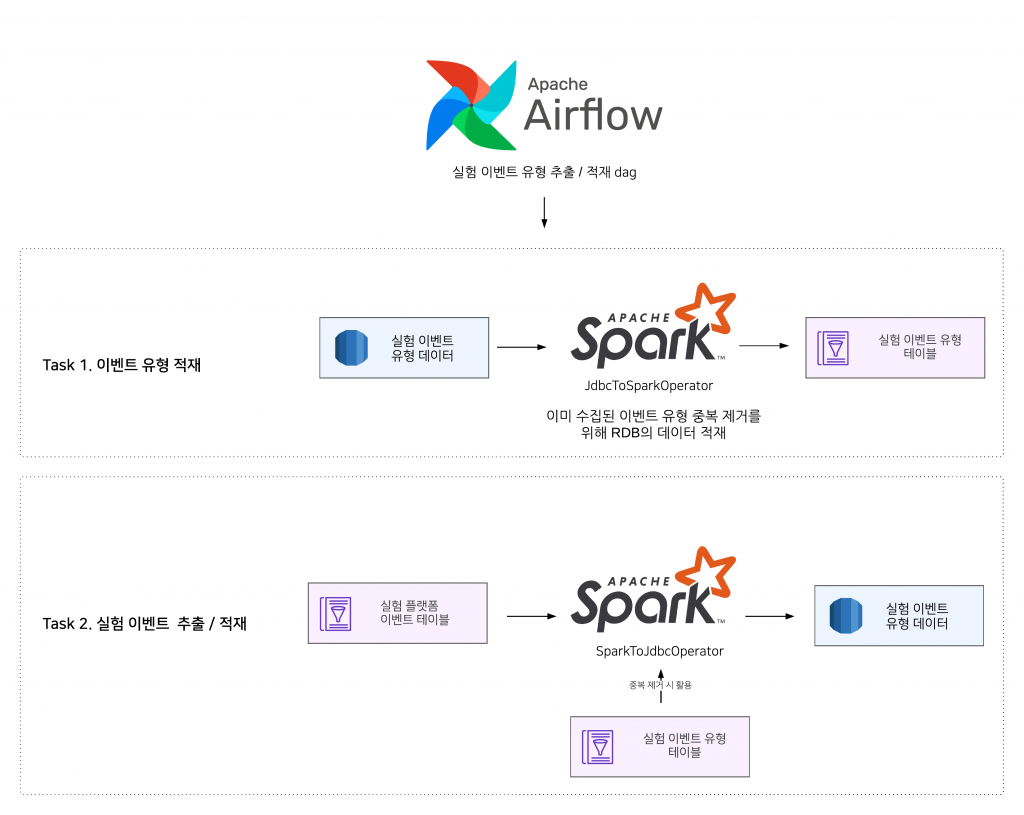
- 실험 플랫폼 RDB에 이미 저장되어 있는 RDB의 데이터를 Hive 테이블로 적재합니다. 이 데이터는 이벤트 유형 데이터의 중복 제거에 활용합니다.
- 실험 플랫폼 이벤트 테이블에서 발생한 이벤트 유형을 추출합니다. 그리고 실험 이벤트 유형 테이블의 데이터를 이용해 중복을 제거하고 실험 플랫폼 RDB로 적재합니다.
위 작업을 통해 실험 설계자들은 어드민에서 실험에서 발생한 이벤트의 유형 목록을 확인하고 목표를 설정할 수 있습니다.
실험 결과 데이터 집계와 적재
이제 마지막으로 실험의 결과를 집계하고 실험 플랫폼 RDB의 실험 결과 테이블에 적재하는 부분을 살펴보겠습니다.
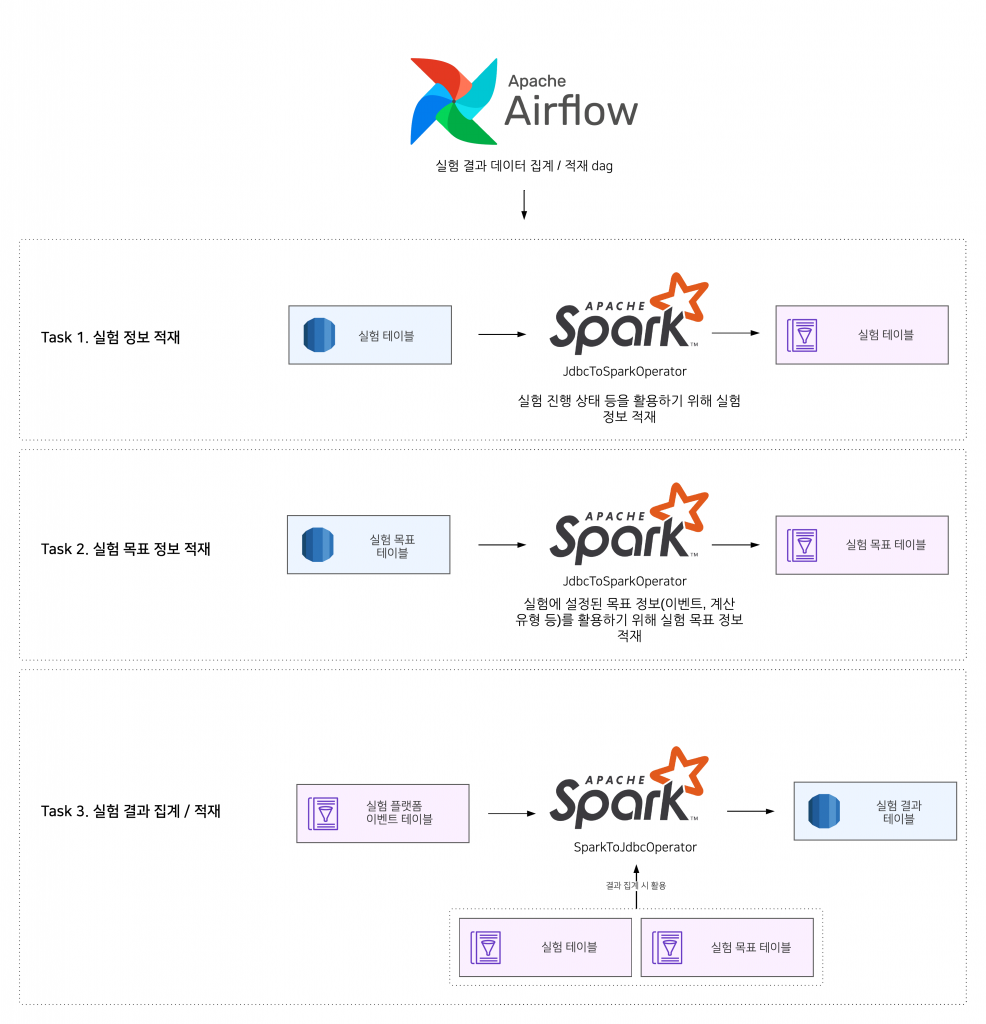
- 실험 플랫폼 RDB에 저장된 실험 데이터를 Hive 테이블로 적재합니다. 실험 결과 집계 단계에서 실험의 상태를 확인할 때 사용합니다.
- 실험 플랫폼 RDB에 저장된 실험 목표 데이터를 Hive 테이블로 적재합니다. 실험 결과 집계 단계에서 목표에 설정된 분모, 분자 이벤트와 계산 유형을 확인하는데 사용합니다.
- 목표에 설정된 분자와 분모 이벤트, 계산 유형 등을 기반으로 실험의 결과를 집계하고 실험 결과 테이블 RDB에 결과 데이터를 적재합니다.
위 dag를 통해 RDB에 저장된 결과를 이용해 실험 플랫폼 어드민에서 결과를 확인할 수 있습니다.
위의 결과 집계에서는 설정된 목표에 따라 분자, 분모 값을 집계합니다. 측정값(전환율), 대조군 대비 증가율, p-value 값들은 실험 플랫폼 어드민 API 서버에서 계산해 응답하고 있습니다. 다음 단계에서 데이터 검정을 위한 p-value를 어떻게 계산하는지 과정을 간략하게 살펴보겠습니다.
부록 A. 실험 결과 데이터의 검정
실험을 설계할 때 A안과 B안 중 어떤 것이 뛰어난지를 검증한다고 가정해보겠습니다. 보통은 B안이 더 뛰어나다는 사실을 증명하기 위한 데이터를 제시하려고 생각합니다.
하지만 통계와 관련해서 가설을 검증하는 방식은 우리가 생각하는 과정과는 조금 다릅니다. 내가 검증하려는 가설과 반대되는 가설을 세우고 이 가설을 기각함으로써 검증하려는 가설이 참이라는 것을 검증합니다.
여기서 내가 검증하려는 가설을 대립가설이라고 하고 반대되는 가설을 귀무가설이라고 합니다. A와 B안 두가지 안 중 B안의 효과가 더 뛰어난지를 실험을 통해 검증하려는 경우에 아래와 같은 귀무가설과 대립가설을 세울 수 있습니다.
- 귀무 가설 : 대조군(A)의 효과는 실험군(B)보다 크거나 같다.
- 대립 가설 : 대조군(A)의 효과는 실험군(B)보다 작다.
위의 대립가설에서는 B안이 더 뛰어난지에 대해 다루고 있습니다. 따라서 B안의 전환율이 A안보다 더 낮은 경우를 검정할 필요가 없습니다. 이 경우 단측 검정을 수행하고 그 중에서도 좌측 검정을 수행합니다.
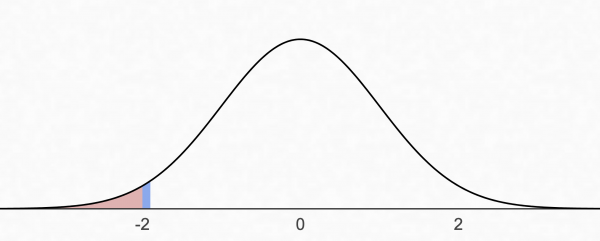
이제 검정을 통해 위 정규분포 그래프의 빨간색 영역에 해당하는 p-value를 구해야 합니다. 가설 검정을 위한 방법은 베이지안, 빈도주의 여러가지 방법이 있지만 여기서는 빈도주의를 이용한 가설 검정, 그 중에서도 Z 검정을 사용한 통계 검정 방법을 간략히 소개하겠습니다.
실험에서 수치형 지표(횟수, 금액, 시간) 등을 보는 경우 Z 검정이 적합하지 않을 수 있습니다. 이 부분은 추후에 개선할 예정이며 현재는 Z 검정만을 제공하고 있습니다.
검정통계량(Z-Score)과 p-value 계산
Z 검정은 아래와 같은 순서로 이루어집니다.
- 검정 통계량(Z-Score)을 계산한다.
- 검정 통계량으로 얻어진 결과를 표준정규분포표에 대입해 면적을 통해 p-value를 구한다.
- 설정한 유의 수준에 따라 실험의 결과가 유의한지 판단한다.
검정통계량을 구하기 위해서는 아래와 같은 계산식을 사용할 수 있습니다.

A, B 안에 대한 분자 분모 값과 전환율이 아래와 같다고 가정하겠습니다.
| 그룹 | 분자 | 분모 | 측정값(전환율) |
|---|---|---|---|
| A | 1003 | 121 | 12.06% |
| B | 1004 | 151 | 15.04% |
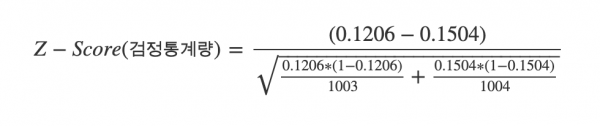
위 계산을 통해 -1.95라는 검정통계량을 얻을 수 있습니다. 검정통계랑은 정규분포를 기준으로 어디에 위치해 있는가를 나타내는 값입니다. 우리는 표준정규분포표를 통해서 면적을 구하고 그를 이용해 p-value를 구할 수 있습니다.
표준정규분포표
z − 0.00 − 0.01 − 0.02 − 0.03 − 0.04 − 0.05 -1.9 0.02872 0.02807 0.02743 0.02680 0.02619 0.02559
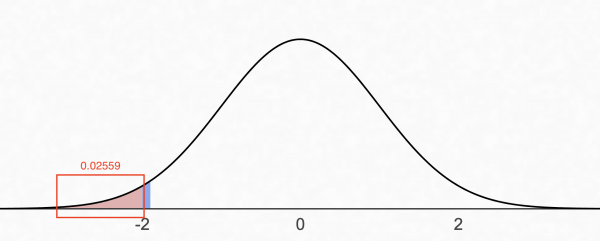
표준정규분포표를 통해 얻어낸 결과값인 0.02559가 p-value이며 위 그래프의 빨간색 영역에 해당합니다.
이제 p-value를 통해 우리가 이전에 세웠던 귀무가설을 기각하고 대립가설을 채택해 “대조군(A)의 효과는 실험군(B)보다 작다”를 검증할 수 있습니다.
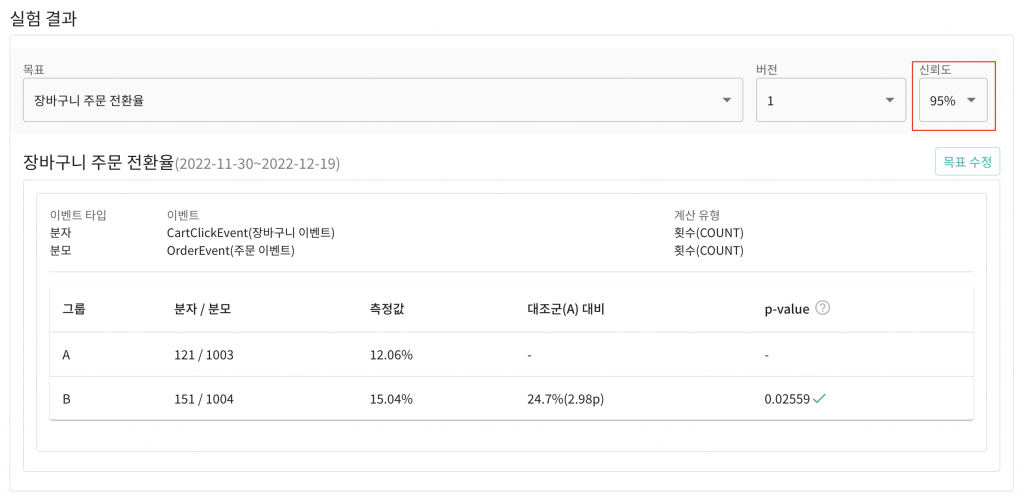
실험 플랫폼 어드민에서는 95%와 99% 신뢰도를 정할 수 있도록 제공하고 있습니다. 우리가 계산한 p-value는 0.02559로 신뢰도 95%에서 유의수준인 0.05를 초과하지 않기 때문에 귀무가설을 기각하고 대립가설을 채택할 수 있습니다.
기능 플래그
기능 플래그는 글의 서론에서 잠시 다루었지만 코드의 수정, 배포 없이 서비스의 동작을 변경할 수 있는 기능입니다.
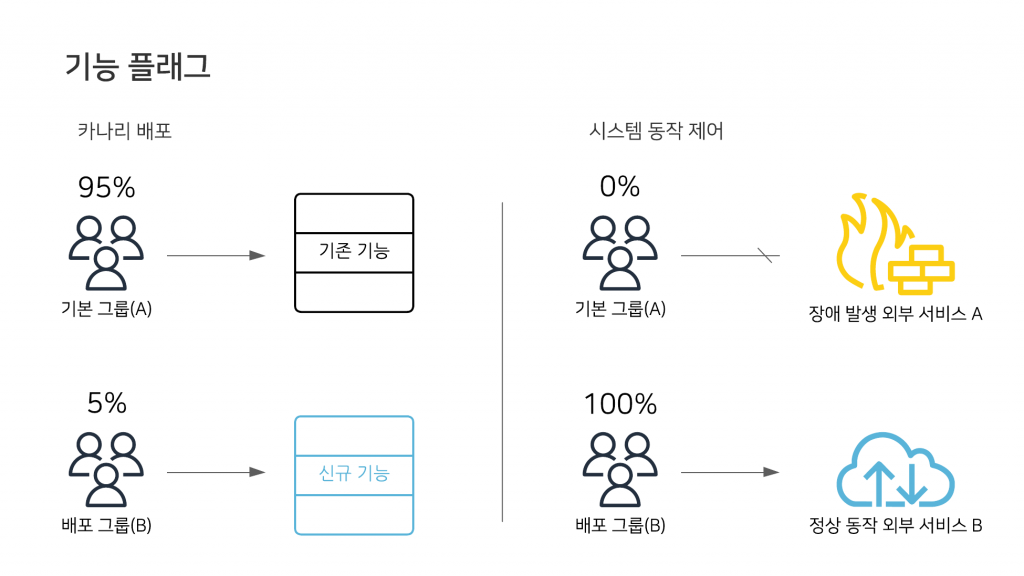
그룹 분배나 동작 방식은 위에서 설명한 실험과 동일하기 때문에 자세한 설명은 생략하고 기능 플래그의 종류와 사용 사례를 몇가지 살펴보겠습니다.
기능 플래그의 종류와 사용 사례
기능 플래그는 다양한 곳에 활용될 수 있습니다. 마틴 파울러의 블로그 글에서는 기능 플래그를 아래 4가지로 분류해서 소개하고 있습니다.
- 릴리스를 위한 기능 플래그(Release Toggles)
- 운영을 위한 기능 플래그(Ops Toggles)
- 권한 관리를 위한 기능 플래그(Permission Toggles)
- 실험을 위한 기능 플래그(Experiment Toggles)
각각의 기능 플래그들이 어떤 특징을 가지고 있는지 살펴보겠습니다.
실험을 위한 기능 플래그(Experiment Toggles)는 실험 플랫폼에서 기능 플래그가 아닌 실험이라는 기능으로 별도로 제공하고 있어 다루지 않습니다.
릴리스를 위한 기능 플래그(Release Toggles)
해당 기능을 활용하면 완벽하게 테스트가 되지 않았거나 불완전한 기능을 숨겨진 상태로 운영 환경에 배포할 수 있습니다. 숨겨진 기능의 노출 비율을 설정하거나 특정 조건을 가진 사용자에게만 노출하는 형태로 카나리 배포를 수행할 수 있습니다.
일반적으로 배포 직후 안정성이 확인되면 바로 신규 기능으로 대체하고 제거되므로 수명이 짧고 새로운 기능을 배포하기 위해 설정을 변경하는 경우만 그룹이 변경되므로 상대적으로 정적인 기능 플래그의 유형으로 볼 수 있습니다.
비율 기반 카나리 배포
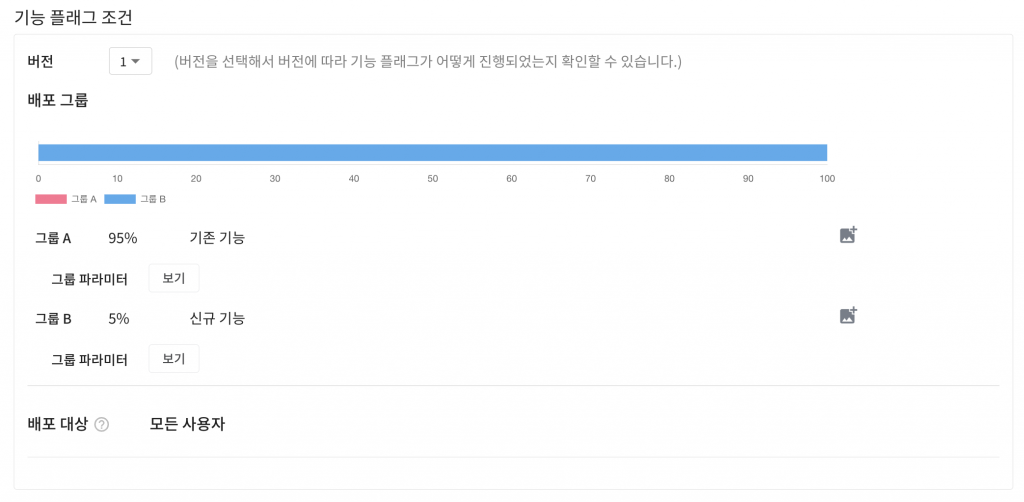
조건 기반 카나리 배포
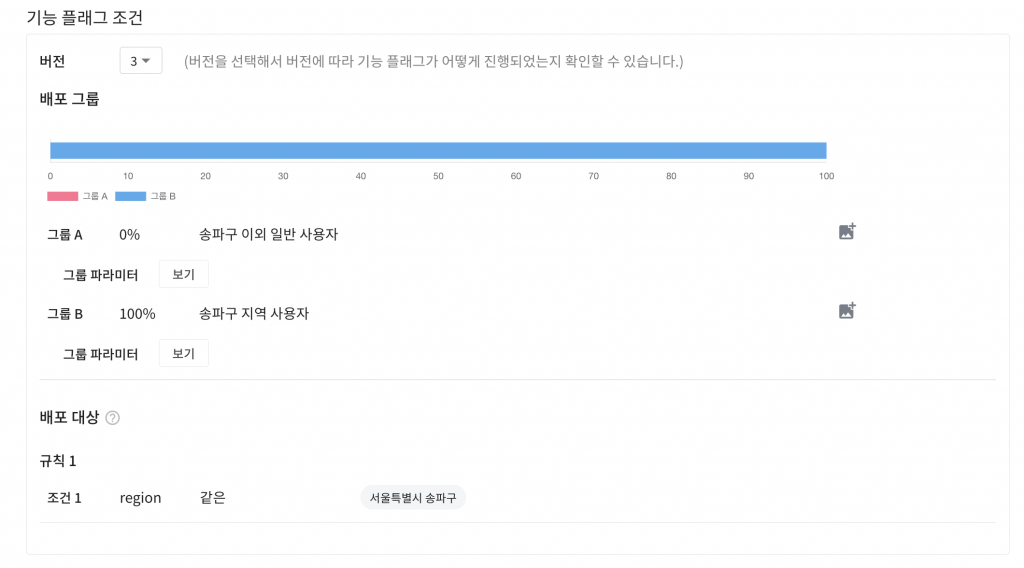
운영을 위한 기능 플래그(Ops Toggles)
해당 기능 플래그를 활용하면 배포를 하지 않고도 시스템의 동작을 제어할 수 있습니다. 시스템의 운영자가 성능 저하 혹은 문제가 될 수 있는 기능의 비율을 낮추거나 비활성화하는 데 사용할 수 있습니다.
대부분 금방 제거되지만 외부 시스템의 이중화와 같은 시스템 제어 목적의 기능 플래그는 시스템 운영자를 위해 거의 무기한으로 남아있을 수 있어 긴 수명 주기를 가질 수 있습니다.
외부 시스템 호출에 대한 이중화
동일한 기능을 제공하지만 대체될 수 있는 서비스의 이중화 목적으로 해당 기능 플래그를 활용할 수 있습니다.
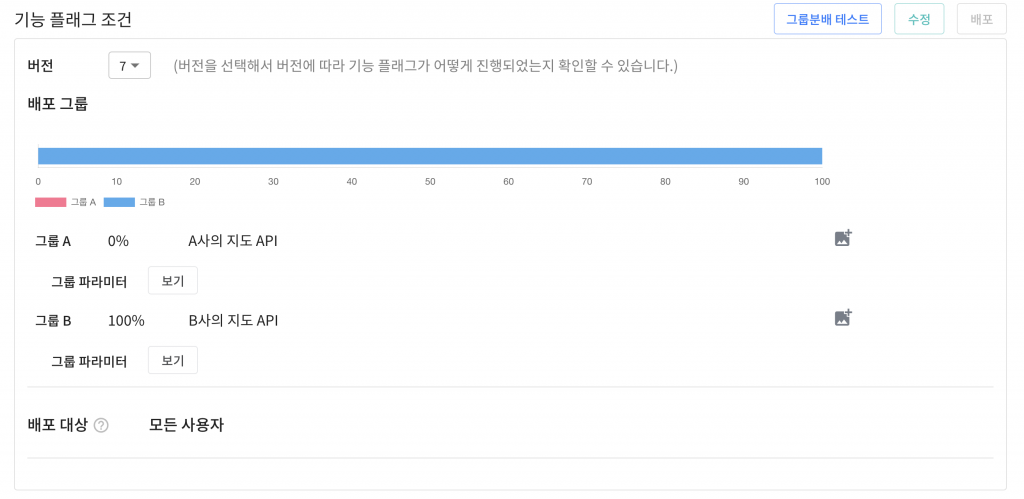
지도와 관련된 서비스의 구현을 위해 외부 서비스를 활용할 때 A사와 B사의 지도 API를 기능 플래그로 구현할 수 있습니다. 기능 플래그를 활용하면 둘 중 하나의 서비스에 장애가 발생했을 때 트래픽 전환을 통해 영향을 받지 않을 수 있습니다.
권한 관리를 위한 기능 플래그(Permission Toggles)
유료 고객 혹은 내부 사용자만 사용할 수 있는 기능을 관리하기 위한 목적으로 기능 플래그를 활용할 수 있습니다. 권한 관리 목적의 기능 플래그는 특성상 긴 수명 주기를 가질 수 있습니다.
서비스 운영 팀에게만 기능 노출
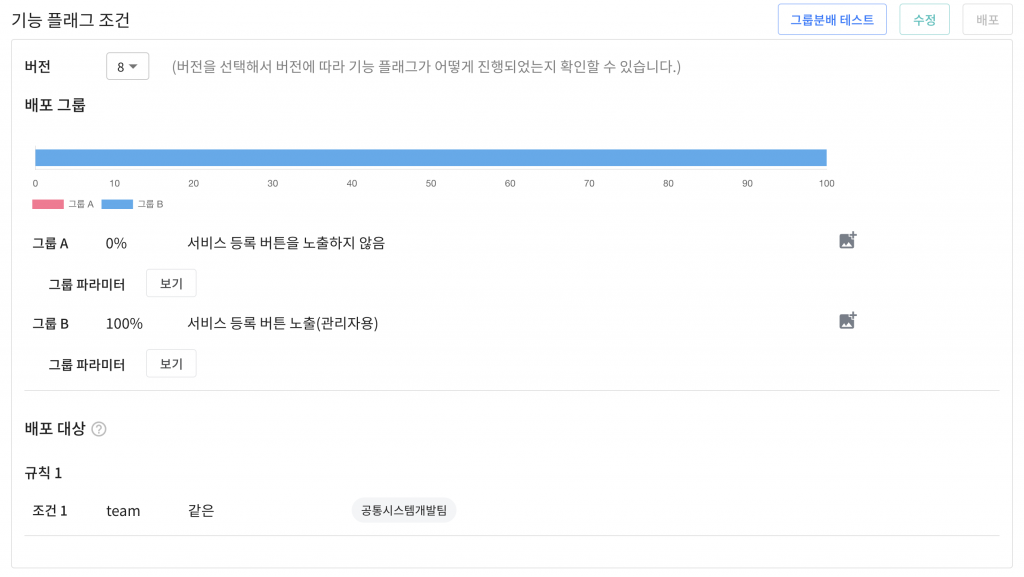
기능 플래그를 통해 공통시스템개발팀의 인원들에게만 서비스 등록 버튼을 노출할 수 있습니다.
여러 종류의 기능 플래그와 활용 사례를 살펴보았습니다.
기능 플래그의 단점
위와 같은 좋은 사례들만 보면 기능 플래그를 사용하지 않을 이유가 없어보이지만 기능 플래그를 사용하기 위해서는 배포할 기능을 두벌로 만들어 유지해야 하는 단점이 있습니다.
그리고 기능 플래그의 사용이 종료된 이후 기능 플래그와 관련된 코드를 제거하는 작업도 개발자에게 부담스러운 작업일 수 있습니다. 종료 이후 기능 플래그를 잘 관리하지 않으면 기능 플래그의 분기 처리가 계속 쌓이면서 이해하기 어렵고 복잡한 코드가 되어 큰 장애를 유발할 수도 있습니다.
마무리
실험 플랫폼에서 제공하는 실험과 기능 플래그 두가지 기능과 실험 플랫폼의 아키텍처에 대해 살펴보았습니다.
아직 실험 플랫폼에는 아래와 같이 해결해야할 과제들이 많이 남아있습니다.
- 그룹분배 서버 부하 감소
- 로컬 캐싱을 통해 데이터 스토어의 부하를 줄였지만, 그룹 분배 서버가 받는 부하는 여전히 많습니다.
- 다양한 통계 분석 방법과 퍼널 분석 기능 제공
- 현재 빈도주의 방식만을 제공하며, 퍼널 분석 등의 기능도 제공하지 않고 있습니다. 이후에는 베이지안 방식이나 퍼널 분석 기능을 제공하려고 합니다.
- 세그먼트 생성 및 실험 대상에 세그먼트 지정
- 현재 실험 대상에 설정할 수 있는 조건이 한정적입니다. 월 10만원 이상 주문한 회원을 대상으로 실험을 한다거나, 한번도 주문을 하지 않은 회원을 대상으로 실험을 한다거나 하는 등 다양한 세그먼트를 설정하고 실험 대상으로 설정할 수 있어야 합니다.
- 실험 데이터 처리 속도 개선, 데이터 범위 축소
- 진행되는 실험의 개수에 따라 하루에도 수천억 건 이상의 실험 데이터를 처리해야 할 수도 있습니다. 필요한 정보만 수집하도록 데이터의 범위를 축소하거나 튜닝을 통해 속도를 개선해야 합니다.
위와 같은 여러가지 부분을 고민해나가며 계속 실험 플랫폼을 고도화시키고 개선해나가려고 합니다. 그리고 실험과 기능 플래그라는 기능은 특정 비즈니스나 도메인에 종속되지 않는 기능이기도 합니다. 이후에는 우아한형제들뿐만 아니라 딜리버리히어로를 비롯해 더 많은 곳에서도 활용될 수 있길 기대합니다.
참고 자료
- Trustworthy Online Controlled Experiments – 저자 Ron Kohavi
- Feature Toggles (aka Feature Flags) – martinfowler
