SRE 팀에서 장애의 root cause를 찾고 재발방지 하는 방법
안녕하세요. 우아한형제들 시스템신뢰성개발팀에서 근무하고 있는 천명호라고 합니다.
SRE팀은 우아한형제들이 제공하는 서비스가 안정적으로 운영될 수 있도록 다양한 관점에서 지원하는 역할을 합니다
최근 경험한 장애를 통해 SRE 팀이 어떻게 문제를 찾고, 재발 방지를 위한 활동을 하는지 소개해 드리려 합니다.
장애 상황 대응
AWS 내 구축된 시스템과 on premise 환경에 구축된 시스템의 API 요청에 5xx error가 증가, 사용자의 요청이 실패하는 현상이 발생했습니다.
편의상 AWS 내 서비스를 A, on premise 환경에 구축된 서비스를 B라고 하겠습니다. 요약을 하면 다음과 같습니다.
- A 서비스의 5xx error 증가 및 B 서비스의 L4 세션 카운트 증가 ⇒ A 서비스 인스턴스 증설
- 인스턴스 증설 이후 A 서비스의 5xx 와 B 서비스의 L4 세션 카운트 감소 확인
- A 서비스 레이턴시 & 5xx error와 B 서비스의 L4 세션 카운트 감소하였으나 평소 수치로 원복되지 않아
⇒ A 서비스 인스턴스 교체 - A 서비스 인스턴스 교체 이후 5xx error와 B 서비스의 L4 세션 카운트 평소 수치로 원복
현상은 해소되었지만 원인이 불명확 했습니다.
장애는 트래픽이 많이 발생하는 주말마다 반복되었으며,
SRE팀과 개발팀들은 주말마다 동일한 대처를 통해 장애를 해소했습니다.
편안한 주말을 위해 SRE팀, 클라우드인프라개발팀, 도메인팀, 정보보안팀 등은 근본 원인을 찾기 시작했습니다.
장애 원인 분석
장애가 발생한 환경
명확한 root cause를 찾기 위해서 장애가 난 환경에 대해 분석했고 환경은 아래와 같습니다.
AWS 환경의 EC2(web application) 와 on premise 환경의 Server(web application) 가 rest api 통신을 하는 시스템 구성입니다.
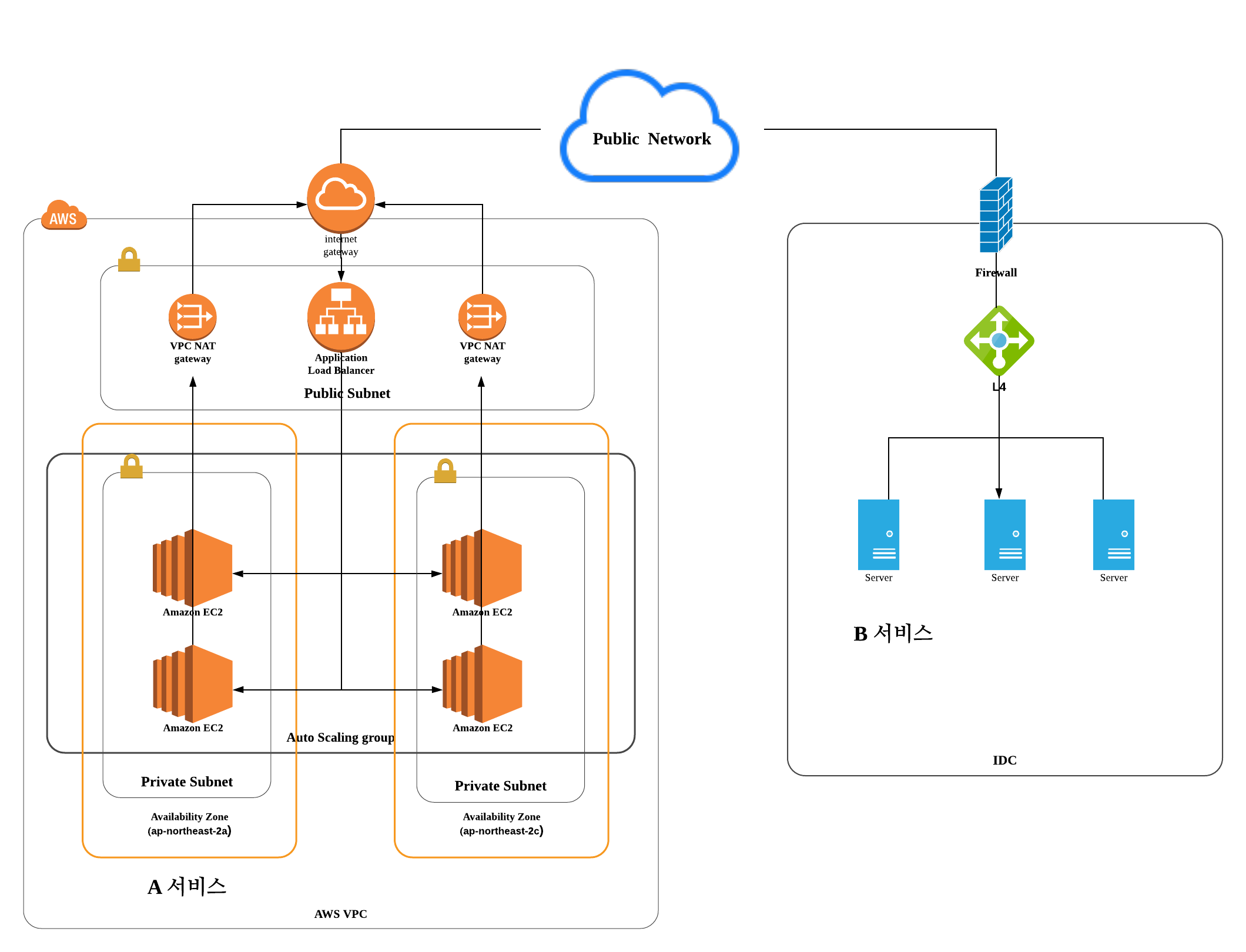
[장애 환경의 구성]
원인 분석을 위한 증거 수집
A 서비스, B 서비스의 application error log, system log, packet dump 등에 대해서 살펴봤습니다.
그중 B 서비스의 packet dump에서 이상한 점을 발견했습니다.
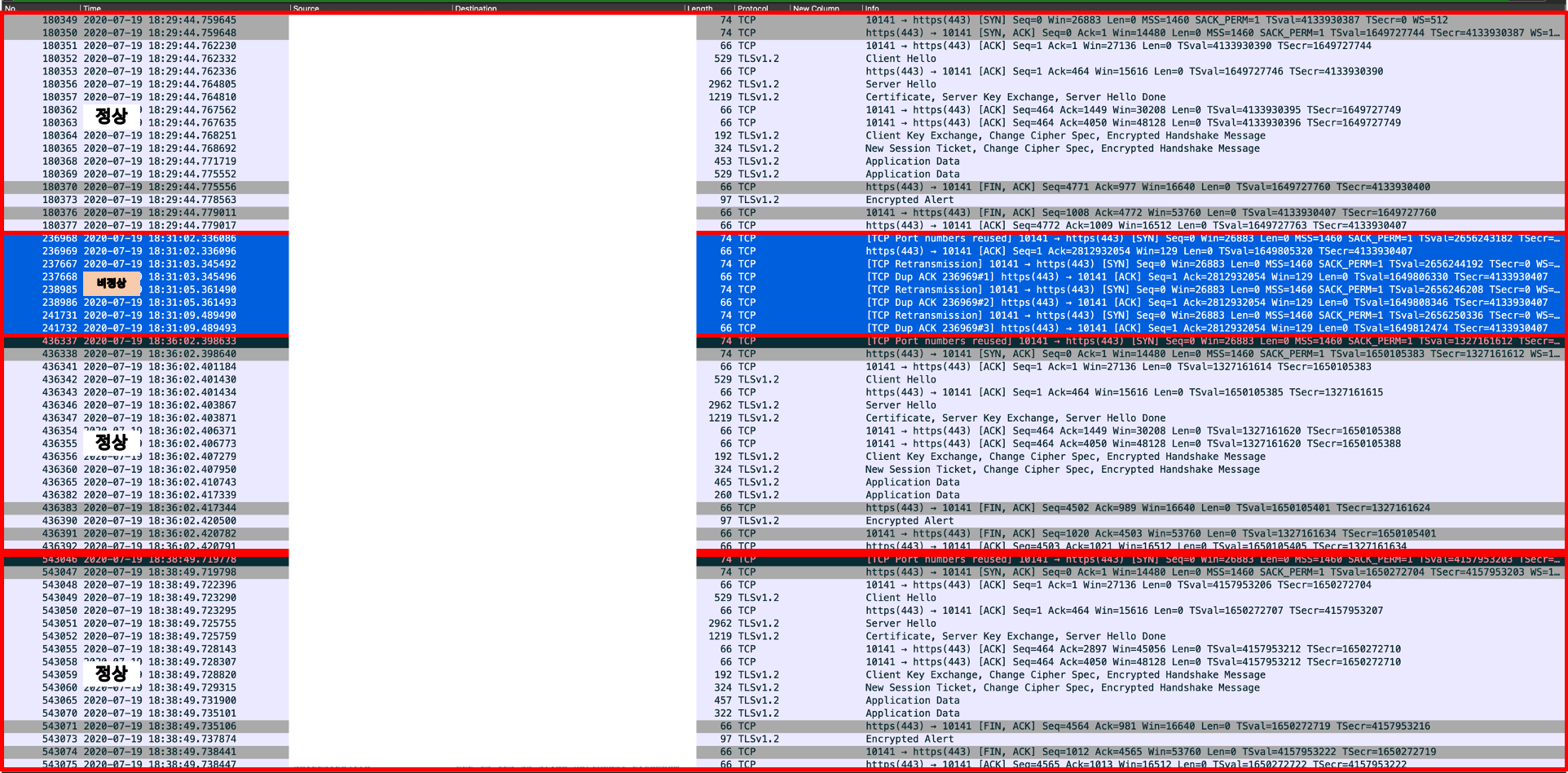
[B Service 의 tcp dump]
-
정상
- 출발지 : 13.125.xx.xx (AWS NAT Gateway) // Src Port : 10141
- 목적지 : 58.229.xxx.xx (B서비스 서버) // Dst Port : 443
- 패킷 흐름 : 3way-handshake(세션시작) -> 데이터전송 -> 4way-handshake(세션종료)
-
비정상
- 출발지 : 13.125.xx.xx (AWS NAT Gateway) // Src Port : 10141
- 목적지 : 58.229.xxx.xx (B 서비스 서버) // Dst Port : 443
- 패킷 흐름 : 요청자 SYN -> 서버 ACK(2812932054) -> 요청자 SYN 재전송 3회 반복
정상이라면 요청자 SYN에 대하여 B 서비스 서버에서 SYN,ACK로 응답하여 TCP세션을 생성해야 합니다.
하지만 비정상일 경우는 요청자 SYN을 B 서비스 서버에서 받은 후 잘못된
sequence number로 ACK만 응답하는 이상 현상을 확인했습니다.
즉, Port 재사용이 반복되다가 B 서비스 서버 쪽에서 TCP Socket이 정상적으로 close 되지않아 발생되는 증상으로 의심을 하고 가설을 세워 테스트를 진행했습니다.
증거에 따른 가설 수립 및 검증
앞서 증거 수집에서 확인한 tcp port 재사용 하지 못하는 로그를 기반으로 다음과 같은 가설을 세웠습니다.
검증을 위한 가설
-
출발지에서 정상적으로 TCP 소켓을 종료하지 않았다.
- 검증 내용
- 출발지 인스턴스 수량 조정
- 출발지 타임아웃 조정
- AWS A, C Zone 이슈
- 검증 내용
-
목적지에서 정상적으로 TCP 소켓을 종료하지 않았다.
- 검증 내용
- 서버 수량 조정
- 커널튜닝
- in bound queue 크기
net.core.netdev_max_backlog=30000
net.ipv4.tcp_max_syn_backlog=65536
net.core.somaxconn=16384 - timeout 관련
net.ipv4.tcp_fin_timeout=5 - TIME_WAIT 상태 소켓 갯수 => gracefully shutdown 을 위해서 많이 잡음
net.ipv4.tcp_max_tw_buckets=“1800000”
- in bound queue 크기
- 검증 내용
-
출발지-목적지 사이 네트워크 구간에서 이슈가 있었다.
- 검증 내용
- AWS NAT gateway Performance Issues
- NAT 증설
- IDC F/W
- 공격성 패킷으로 인지하였는지 아닌지
- 출발지와 목적지 IP+Port 잘 넘겨주었는지
- IDC L4
- 출발지와 목적지 IP+Port 잘 넘겨주었는지
- AWS NAT gateway Performance Issues
- 검증 내용
1, 2 번 가설에 대해서 동일한 환경을 구성 후 테스트해 본 결과 커널튜닝, server 증설 등으로는 동일한 증상이 발생 하였습니다.
흥미로운 사실은 3번을 테스트하던 도중
AWS NAT Gateway 환경일 경우 요청하는 A 서비스에서 connection pool 을 사용하지 않을 경우만 동일 현상 발생 하는 것 발견했습니다.
이를 조금 더 명확하게 확인 하기위해 3번의 구간별 가설을 다시 작성했습니다. 현재의 구성의 network 관점으로 정리하면 다음과 같습니다.
A Service → NAT gateway → Public → IDC → F/W → L4 → B Service-
connection pool 사용 시 동일 현상 재현 확인
- 구성: A Service → NAT gateway → Public → IDC → F/W → L4 → B Service
- 결과: 현상 재현 발생 안함
-
AWS와 IDC간 VPN 구성하여 NAT & Public 제외하여 동일 현상 재현 확인
- 구성: A Service → VPN → IDC → 방화벽 → L4 → B Service
- 결과: 현상 재현 발생 안함
-
특정 존에서 동일 현상 재현 확인
- 구성: A Service(A Zone) → NAT gateway → Public → IDC → 방화벽 → L4 → B Service
- 결과: 현상 재현 발생
-
L4 제외하여 동일 현상 재현 확인
- 구성: A Service → NAT → Public → IDC → 방화벽 → B Service
- 결과: 현상 재현 발생 안함
4 가지 경우에 대한 테스트 진행 하였고 그에 따른 분석결과는 다음과 같습니다.
- L4가 있는 상태에서 출발지에서 connection pool을 사용하니 재현이 안 된다!
- 출발지에서 connection pool을 사용하지 않는 상태에서 L4를 제외하니 재현이 안 된다
위 테스트의 결과를 통해서 IDC 에 존재하는 L4 구간에서의 이상동작으로 한계를 지을 수 있었습니다.
- DAM(Direct access mode)활성화 상태에서 Client Port 변환이 발생하지만 알고있었던
Port 범위(2000 ~ 65000)와 실제 동작 상태가 다르게 나타남
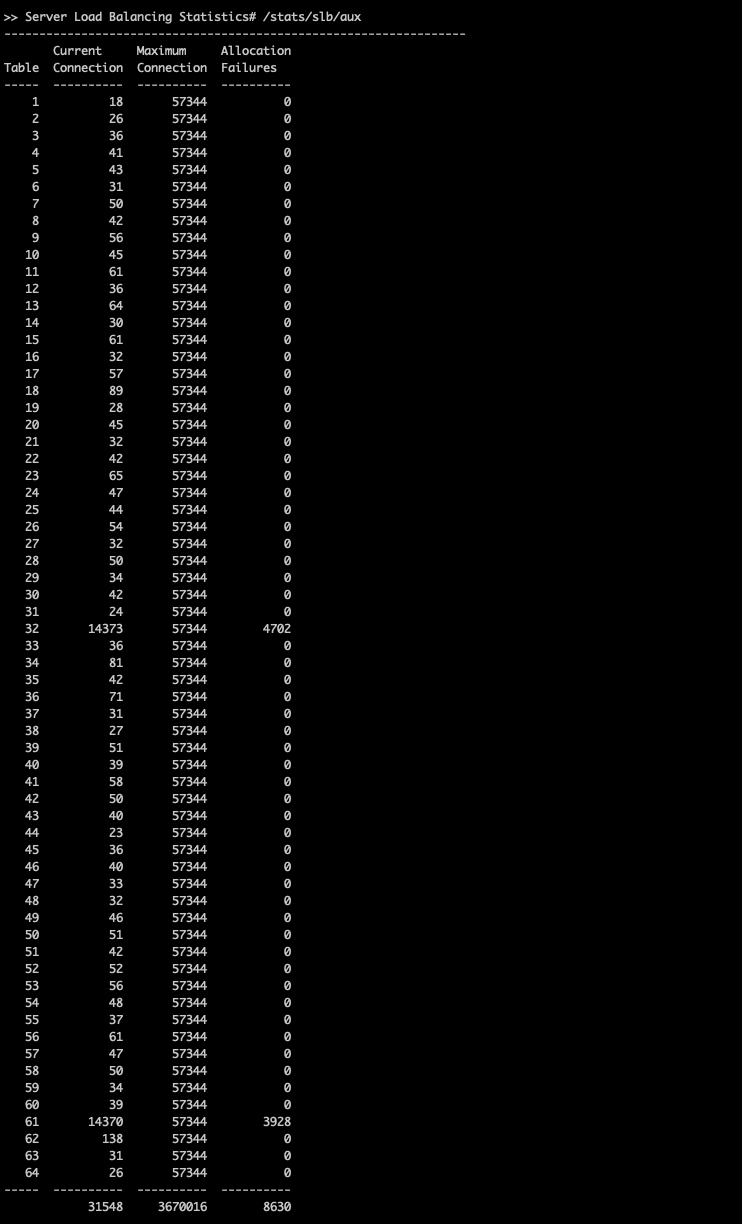
[L4 부하 테스트 시 발생 현상]
- /i/slb/sess/du 명령어로 Session table 확인시 Service port 15000 이상 확인 불가 (2048~16383 만 확인 됨)
- Client 요청 과부하로 TEST VIP Session 이 약 28000을 초과 하는 경우 AUX Table에 Allocation fail 수치 증가

[source port range]
끝날때 까지 끝난게 아니다.
-
L4 검증 테스트 가설
- AWS availability Zone(A, B, C)과 NAT Gateway를 1:1로 매핑하였고, A Service를 각 Zone에 분배하여 부하테스트를 진행
-
테스트 예상 결과
- L4에서 Source IP(Nat Gateway IP) 당 약 14000개의 port를 할당할 것으로 예상
- B Service 테스트 서버에서 TIME_WAIT 의 갯수가 약 42000개 이상되면 동일 현상 발생
-
테스트 결과
- B Service 테스트 서버에서는 약 42000개의 TIME_WAIT 이 발생하고 A Service에서 5xx error 발생
- 예상했던 Source IP(Nat Gateway IP) 당 약 14000 임계치 확인 => NAT gateway 3개 구성시 14000*3 = 42000
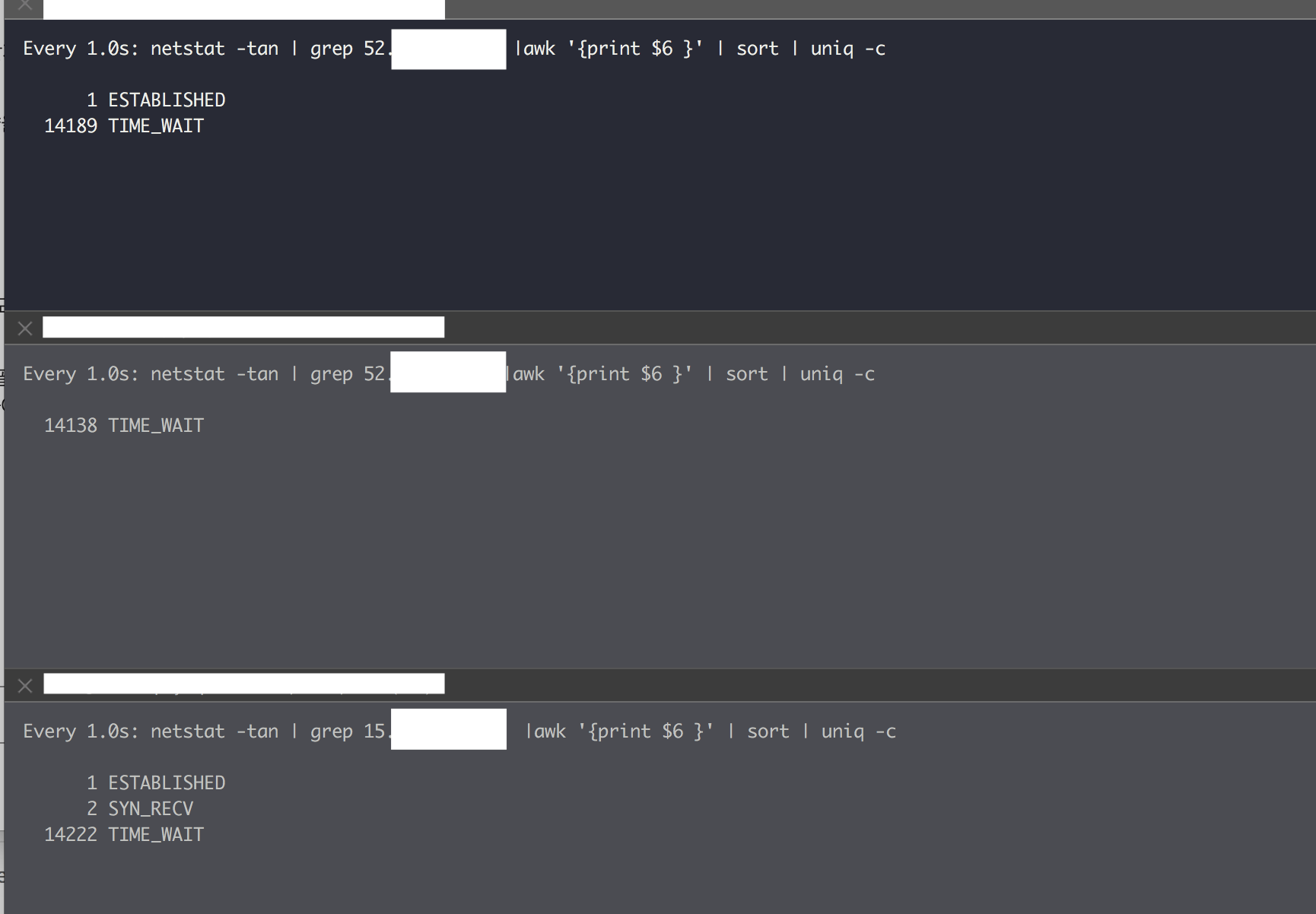
[L4 부하 테스트 결과]
재발 방지를 위한 조치
- 재발 방지를 위해서 A Service 팀과 협업 하여 connection pool 을 사용하도록 전환
- AWS – IDC 사이의 NAT Gateway를 사용 서비스를 조사하여 connection pool 을 사용하도록 전환
정리
일반적으로 장애의 해결법은 원인 분석 과정에서 쉽게 발견할 수 있습니다.
하지만 문제의 원인을 정확히 확인하지 않는다면, 우리는 잠재적 위험을 떠안고 서비스를 운영해야 합니다.
우아한형제들에서는 장애의 해결을 최우선으로 다루지만, 재발방지를 위해 root cause를 찾아내는 과정 또한 중요하게 여기며,
이를 통해 재발 방지를 위한 노력을 꾸준히 하고 있습니다.
우아한형제들의 SRE팀에 대해서 더 알고 싶거나, 함께 우아한형제들의 서비스를 안정적이고 신뢰성있게 운영하시고 싶은 분들은
지원을 부탁드립니다.
긴 글 읽어주셔서 감사합니다.
