가게노출 파트의 조금은 색다른 파일럿 프로젝트, 그리고 첫 업무까지의 이야기

안녕하세요, 프론트검색서비스팀 신입 개발자 김덕수입니다.
입사한지 어느덧 네 달 가까이 시간이 흘렀는데요..!
조금 시간이 지나기는 하였지만, 파일럿 프로젝트를 진행하면서 배웠던 것들과 더불어
신입 개발자가 팀에서 적응해 나가는 과정을 공유드려보고 싶어서 포스팅을 작성하게 되었습니다.
가게 노출 파트에서는 어떻게 온보딩이 진행되는지, 파일럿 프로젝트에서부터 첫 업무를 마치기까지 과정을 간단하게 소개드립니다.

때는 지난 1월, 신입으로 입사한지 딱 3일째 되던 날, 랩탑 세팅을 마치자마자 어명같은 파일럿 프로젝트 구현령이 떨어집니다 ㅎㅎ
파일럿 프로젝트 구현 요구 조건을 간단히 요약하자면 다음과 같습니다.
미니 가게 노출 시스템을 한 번 만들어 보세요
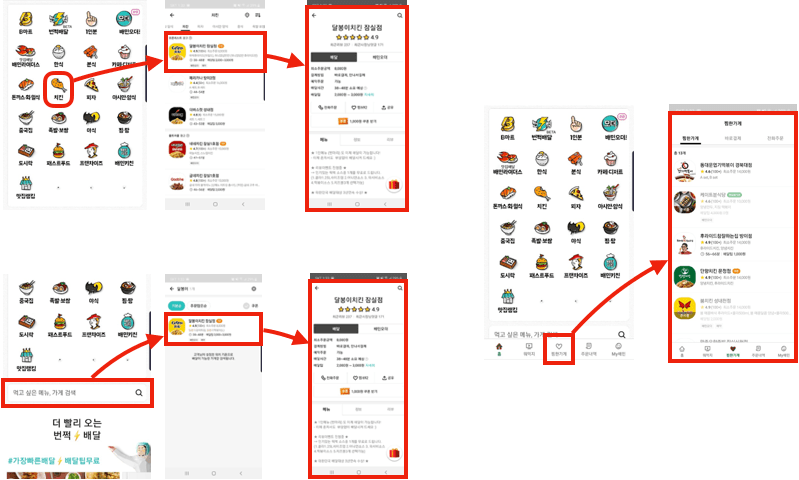
- 위와 같이 음식 카테고리 → 카테고리에 따른 가게 목록 노출 → 가게 클릭 시 가게 상세 페이지 까지 연결되도록 구현
- 검색 → 검색 결과 가게 목록 노출 → 가게 클릭시 가게 상세 페이지까지 연결되도록 구현
- 찜한 가게 → 찜한 가게 목록 노출 → 가게 클릭시 가게 상세 페이지까지 연결되도록 구현
- 필요한 데이터를 요청할 때 현재 가게노출 시스템에서 사용중인 api client 모듈들을 사용해서 구현
- API구현 + 페이지 뷰 + 사내 테스트망에 배포
요는, 가게 노출 시스템 일부를 간단히 구현해 보는 것이 과제였습니다.
구현 대상을 조금 더 명료하게 보기 위해 가게 노출 시스템 일부를 간단히 그려 보자면 아래와 같습니다.
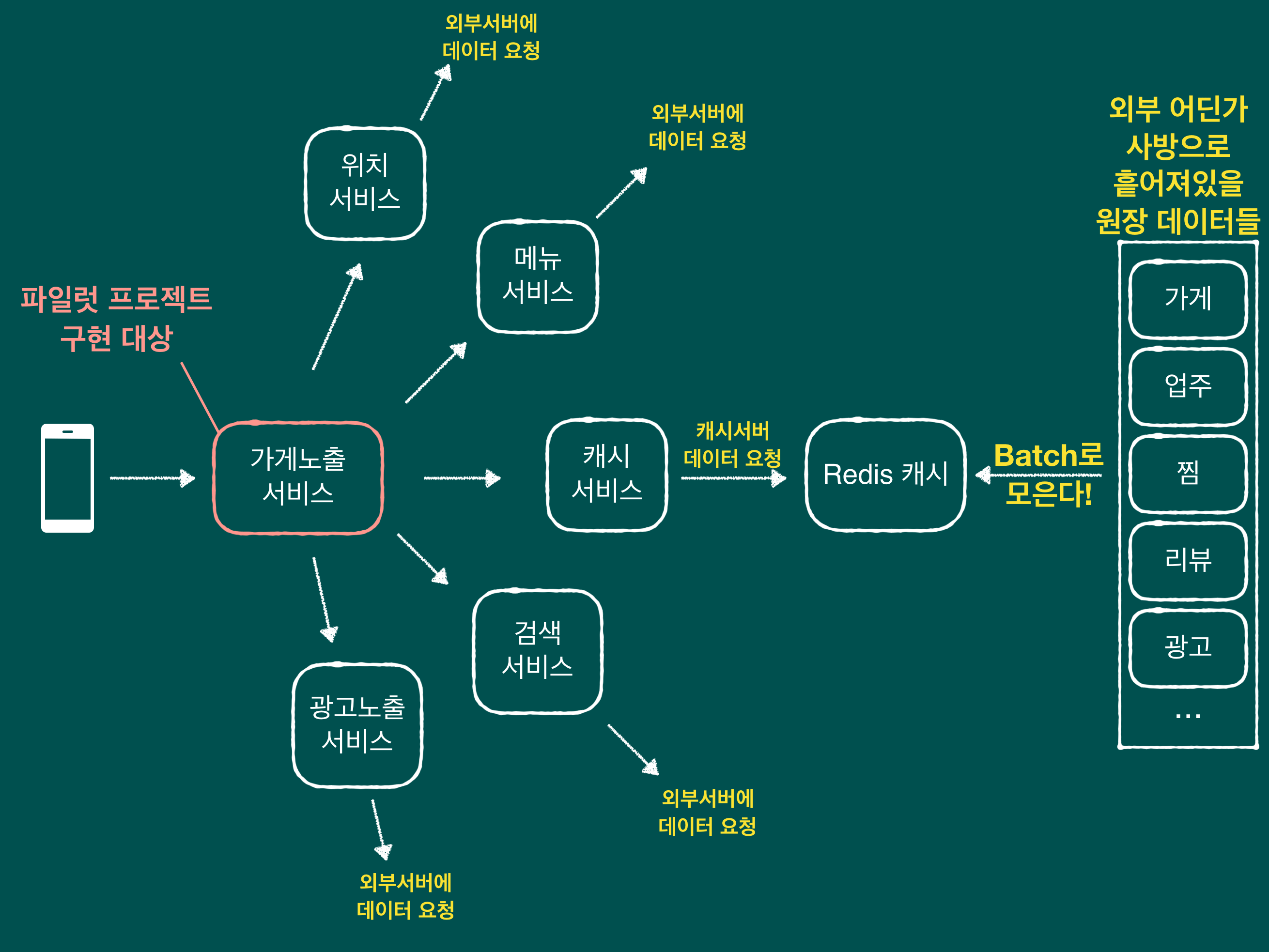
이 중에서 외부에 데이터를 요청하는 부분(위치 서비스, 메뉴 서비스 등등)은 저희 팀에서 실제로 외부 api 요청시에 사용하고 있는 모듈을 이용했습니다.
운영 서버에서 돌아가고 있는 코드를 최대한 일찍 보는 것이 시스템을 파악하고 업무에 적응하는 데에 있어서,
그리고 배움에 있어서도 좋을 것 같다는 뜻에서 이렇게 프로젝트를 구성해 주셨는데요,
안정적으로 가게들을 노출하기 위해 만들어진 기존의 거대한 시스템을 먼저 파악하는 것이 첫 번째 도전 과제였습니다.
그 다음으로는 마이크로 서비스 아키텍쳐가 갖는 복잡도를 다루는 것이 관건이었습니다.
배달의 민족 서비스는 서비스를 구성하는 수많은 하위 서비스들로 나누어져 있고,
가게 노출에 필요한 데이터가 사방에 흩어져 있습니다.
이 데이터들을 잘 모아서 사용자들에게 정리된 가게 정보들을 보여주기 까지 수많은 api 호출이 필요합니다.
외부 api 호출시 주의해야 할 점들이 많은데, 시스템의 파악과 더불어 이 부분을 잘 처리하는 것이 이번 파일럿 프로젝트의 핵심이었습니다.
프로젝트 진행 과정
전체적인 과정은 ‘아키텍쳐 설계 → 백엔드 API 구현 → 페이지 View 구현 & 테스트 서버 배포’ 순으로 진행되었습니다.
각각의 과정 사이사이에 끊임없이 피드백을 받으며 부족한 부분을 개선시켜 나갑니다.
클래스 연관 관계도
코드를 작성하기 전에 아키텍쳐 설계부터 시작하였는데요, 본 파일럿 프로젝트는 가게 노출 시스템의 데이터의 흐름을 파악하는 것이 주 목적이었고, DB를 사용할 일이 없었기 때문에 테이블 설계나 ERD 대신 클래스 의존 관계를 중심으로 프로젝트 구조를 잡아 보았습니다.
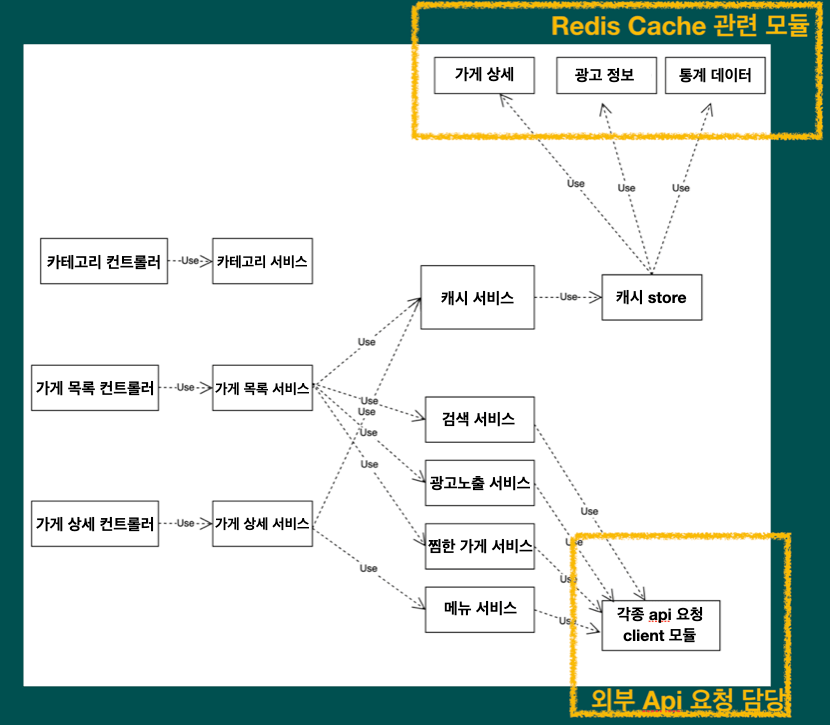
아키텍쳐 설계를 마친 이후에 약 3주간 백엔드 api를 먼저 구현하게 되고, 구현을 마치면 대망의 코드리뷰가 기다리고 있습니다.
팀 코드 리뷰
파일럿 프로젝트를 진행하면서 오프라인 코드 리뷰를 많이 받을 수 있었다는 점이 너무 좋았습니다.
특히 팀 전체 개발자 분들께서 모두 참여하셔서 오프라인 리뷰를 해 주시는 자리가 있었는데,
덕분에 실무에서 겪어보지 않으면 알기 어려운 부분들에 대해 정말 많이 배울 수 있었습니다.
받았던 피드백 중 공유드리면 좋을 것 같은 피드백 몇 가지만 공유해 보도록 하겠습니다.
핵심 구현 로직
특정 위치에서 배달 가능한 가게 목록을 조회하여 노출하는 서비스 로직을 간단히 예로 들어 보겠습니다.
대략적인 흐름은 아래와 같습니다.
@Service
@RequiredArgsConstructor
@Slf4j
public class ShopListService {
private final ShopSearchingService shopSearchingService;
// 위치 기반 가게 목록 검색 서비스
private final CacheService CacheService;
// 레디스 캐시 서비스
public Mono<List<BaeminShopSummary>> getBaeminShops(SearchCategoryRequest searchCategoryRequest) {
return ShopSearchingService.getBaeminShopNumbers(searchCategoryRequest)
// 특정 위치에서 주문 가능한 가게 id만 가져와서
.flatMap(CacheService::getBaeminShopSummaries);
// 가게 노출시 필요한 실제 데이터를 레디스 캐시에서 조회
}
}가게 검색 서비스에 사용자 위치, 음식 카테고리 등을 포함한 정보들(SearchCategoryReqeust)을 넘겨주면 해당 가게들의 가게 번호들을 되돌려 줍니다. 돌려받은 가게 번호들로 레디스 캐시에 저장된 상세 데이터들을 조회해서 가게 목록 데이터로 조합하여 되돌려 주면 끝!
….이 아니라 중간중간 상당히 복잡한 과정이 숨어 있습니다. 일단 아래와 같이 간단하게만 정리해 보겠습니다.
@Service
@RequiredArgsConstructor
public class ShopSearchingService {
private final GeoApiCircuitClient geoApiCircuitClient;
// 위경도 -> 행정동 코드로 변환하는 api 요청 client
private final ShopSearchApiCircuitClient shopSearchApiCircuitClient;
// 가게 목록 검색을 위한 api 요청 client
public Mono<List<Long>> getBaeminShopNumbers(SearchCategoryRequest searchCategoryRequest) {
return getRegionCode(searchCategoryRequest.getLongitude(),
searchCategoryRequest.getLatitude())
.map(searchCategoryRequest::toShopSearchApiRequest)
// 가게 검색 서비스에 검색 요청하기 위해 request 변환
.flatMap(ShopSearchApiCircuitClient::getBaeminList)
// 가게 검색 서비스에 비동기로 가게 목록 검색 요청
.map(ShopSearchResponse::toShopNumbers);
// 결과를 받아 가게 id만 추출
}
private Mono<String> getRegionCode(Longitude longitude, Latitude latitude) {
return geoApiCircuitClient.getRegionCode(longitude.getValue(), latitude.getValue())
}
}@Service
@RequiredArgsConstructor
@Slf4j
public class CacheService {
private final ImageHosts imageHosts;
private final ShopDetailCacheService shopDetailCacheService;
// 가게 관련 데이터 레디스 캐시 조회
private final ShopAdvertisementCacheService shopAdvertisementCacheService;
// 광고 관련 데이터 레디스 캐시 조회
private final ShopStatisticsCacheService shopStatisticsCacheService;
// 리뷰수, 별점 등 통계 데이터 레디스 캐시 조회
public Mono<List<BaeminShopSummary>> getBaeminShopSummaries(List<Long> shopIds) {
return Mono.zip(shopDetailCacheService.get(shopIds),
shopAdvertisementCacheService.get(shopIds),
shopStatisticsCacheService.get(shopIds)) // api 호출 병렬처리
.map(responses -> BaeminShopSummaryBuilder.builder(imageHosts)
// api 호출 응답을 조합해서 가게 목록 응답으로 변환
.shopDetails(responses.getT1())
.ShopAdvertisements(responses.getT2())
.shopStatistics(responses.getT3())
.buildBaeminShopSummaries());
}
}의존하고 있는 다른 서비스 코드를 다 보여 드릴 수가 없어서 위 코드만으로는 파악하기 좀 어렵지만, 코드 리뷰 중 받았던 피드백과 함께 조금 더 살펴보겠습니다.
네트워크 요청 예외 처리, Timeout
위 코드에 대해 가장 먼저 받았던 피드백은 Timeout과 관련된 피드백 이었습니다. 코드에 네트워크 요청에 대한 예외 처리가 하나도 안 되어 있는 것을 보시고, Timeout에 대해서 고려해 보았는지 물어 보셨습니다. 가게 노출 서비스는 외부 api 요청이 굉장히 많은데, api 응답이 제대로 돌아오지 않는 경우를 제대로 처리하지 못하면 클라이언트 요청이 계속 쌓이게 되어 장애가 날 수 있다고 하셨습니다. 외부 api 요청에 대한 응답이 늦어지는 경우에는 요청한 서버에 문제가 있음을 빠르게 인지하고 처리하는 것이 중요한데, 우리 서비스에서 문제 상황인 것을 어떻게 판단하고 있는지 먼저 파악해 보라고 하셨습니다.
사실 Timeout과 관련된 부분도 이미 저희 client 모듈에 다 구현이 되어 있어서 주의 깊게 살펴 보았다면 알 수 있는 부분이었는데요, Api 요청을 하는 ApiClient를 다음과 같이 소켓 관련 Timeout을 설정해 사용하고 있었습니다.
public class ApiClient {
protected final WebClient webClient;
...
private static WebClient create(...) {
...
return WebClient.Builder
.clientConnector(new ReactorClientHttpConnector(createHttpClient(hostProperties)))
.build();
}
private static HttpClient createHttpClient(HostProperties hostProperties) {
return HttpClient.create()
.tcpConfiguration(client ->
client.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, hostProperties.getConnectTimeout())
// ConnectionTimout 설정
.doOnConnected(connection -> connection
.addHandlerLast(new ReadTimeoutHandler(hostProperties.getSocketTimeout(), TimeUnit.MILLISECONDS))
.addHandlerLast(new WriteTimeoutHandler(hostProperties.getSocketTimeout(), TimeUnit.MILLISECONDS))
// SocketTimeout 시간을 정해놓고
// Read, Write시에 패킷 응답 지연이 SocketTimeout보다 길어지면
// 타임아웃 처리!
));
}
...
}그리고 해당 ApiClient를 사용하는 곳에서는 method timeout을 설정하여 webClient 응답이 timeout 설정 시간보다 늦을 경우 해당 ApiClient를 사용하는 곳으로 TimeoutException이 던져지도록 하고 있습니다.
class ShopSearchApiClient extends ApiClient {
...
public Mono<ShopSearchResponse> getBaeminList(SearchRequest searchRequest) {
return webClient.get()
.uri(uriBuilder -> uribuilder.path("/baemin/shops")
.queryParam(...)
.build())
.retrieve()
.bodyToMono(SearchResponse.class)
.timeout(timeout); // Method timeout
}위의 두 코드를 살펴보면 Timeout 설정이 여러 군데에 있는데요, Connection timeout, Read(Write) timeout,
그리고 Method timeout까지 세 군데나 timeout 설정을 하고 있습니다. 왜 timeout 설정을 이렇게 여러 군데 하는 것일까요? 각 Timeout이 없는 상황을 가정하여 타임아웃 설정을 세 군데나 해주어야 하는 이유를 생각해 보겠습니다.
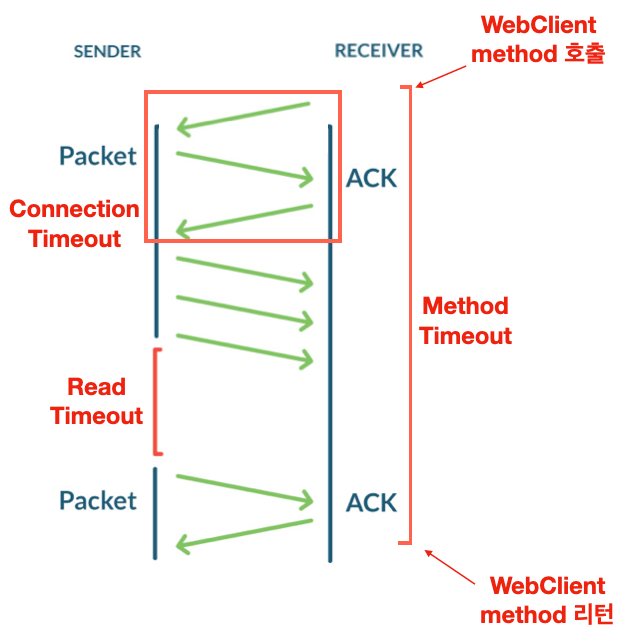
- Connection timeout, Read timeout만 설정하고 method timeout을 설정하지 않는 경우:
Connection timeout은 처음 소켓 connection을 맺기까지, 그리고 Read timeout은 패킷이 도착하고 다음 패킷이 도착하기까지
걸리는 시간과 관련된 timeout입니다. 만약 Method timeout을 설정하지 않으면 응답 응답 지연이 최대
Connection Timeout + Read Timeout * (총 패킷 개수 – 1) 까지 길어지게 될 수 있습니다.
WebClient method 호출시에 예상했던 timeout보다 지연 시간이 길어지게 될 수 있는 것이죠.
그러니 메서드 timeout을 반드시 설정해 주어야 합니다. - method timeout만 설정하고 Connection timeout, Read timeout은 설정하지 않는 경우:
method timeout으로 설정한 시간보다 메서드 응답 지연이 길어지면 TimeoutException이 발생하고 메서드가 종료되지만,
Socket에 할당된 자원은 제대로 반환되지 않을 수 있습니다. 예를 들어 api 요청한 서버에 문제가 생겨 소켓 Connection
시도에 대한 응답이 돌아오지 않는 경우, method timeout으로 인해 해당 api 호출 메서드는 종료 되겠지만 해당 소켓은
기약없는 대기상태에 빠질 수 있습니다. 그러면 file descriptor도 fd 테이블에서 지워지지 않으며,
open file 개수(프로세스가 가질 수 있는 소켓 포함 파일 개수)도 줄어들지 않습니다.
이렇게 반환되지 않는 자원이 누적되면 메모리나 open file 관련 IOException이 발생할 수 있습니다.
이와 같은 이유에서 Connection timeout, Read timeout, Method timeout 세 가지를 모두 다 설정해 주어야 합니다.
이렇게 설정해둔 Timeout등으로 예외 상황을 탐지하고, 예외가 지정 횟수를 초과해서 발생하면 api 요청을 하는 대상 서버가 장애 상황이라고 판단합니다.
장애가 해결될 때까지 해당 서버로 요청이 흘러 들어가지 않도록 CircuitBreaker를 사용하고 있습니다.
class ShopSearchApiCircuitClient {
private final CircuitBreaker circuitBreaker;
private final ShopSearchApiClient shopSearchApiClient;
...
public Mono<ShopSearchResponse> getBaeminList(SearchCategoryRequest SearchCategoryRequest) {
return ShopSearchApiClient.getBaeminList(SearchCategoryRequest)
.transform(CircuitBreakerOperator.of(circuitBreaker))
.doOnError(throwable -> log.error("apiClient에서 전파한 TimeoutException 등 예외 상황 원인 로깅"));
}예외 상황을 서비스에서 어떻게 해석하고 처리할 것인가
예외 상황인 것을 포착하고 서비스에 TimeoutException을 던져 알렸으면 반드시 예외 상황을 처리해 주어야 합니다. 이 때, 데이터의 성격에 따라 어떤 예외들은 각 서비스 내부에서 처리하고, 바깥으로 전달되지 않도록 하는 것이 좋다고 하셨습니다. 서비스 사용처에서 해당 서비스를 호출할 때 에러 상황에 대한 처리를 보장해주는 것이죠.
위 코드에서 외부 api 요청이 있는 부분은 ShopSearchingService 클래스인데요,
예외 상황이 생겨도 서비스 내부에서 모두 처리되도록 예외처리를 추가해 보겠습니다.
처리를 할 때에는 데이터의 중요도에 따라서 예외 처리 해야하는 데이터가 있고, 기본값으로 처리하여 되돌려주는 것이 나은 데이터가 있다고 하셨습니다.
비교적 중요하지 않은 데이터들을 기본값으로 처리하더라도 일단 사용자에게 최대한 빠르게 피드백을 주도록 하는 것이 나을 때가 있다는 말씀이셨습니다.
그래서 가게 검색 api요청에 실패하는 경우 기본값을(통계 데이터 등이 0으로 초기화된 empty 객체) 정해놓고 되돌려 주도록 수정해보았습니다.
As-is
@Service
@RequiredArgsConstructor
public class ShopSearchingService {
private final GeoApiCircuitClient geoApiCircuitClient;
private final ShopSearchApiCircuitClient shopSearchApiCircuitClient;
public Mono<List<Long>> getBaeminShopNumbers(SearchCategoryRequest searchCategoryRequest) {
return getRegionCode(searchCategoryRequest.getLongitude(),
searchCategoryRequest.getLatitude())
.map(searchCategoryRequest::toShopSearchApiRequest)
.flatMap(ShopSearchApiCircuitClient::getBaeminList)
.map(ShopSearchResponse::toShopNumbers);
}
private Mono<String> getRegionCode(Longitude longitude, Latitude latitude) {
return geoApiCircuitClient.getRegionCode(longitude.getValue(), latitude.getValue());
}
}To-be
@Service
@RequiredArgsConstructor
public class ShopSearchingService {
private final GeoApiCircuitClient geoApiCircuitClient;
private final ShopSearchApiCircuitClient shopSearchApiCircuitClient;
public Mono<List<Long>> getBaeminShopNumbers(SearchCategoryRequest searchCategoryRequest) {
return getRegionCode(searchCategoryRequest.getLongitude(),
searchCategoryRequest.getLatitude())
.map(searchCategoryRequest::toShopSearchApiRequest)
.flatMap(ShopSearchApiCircuitClient::getBaeminList)
.switchIfEmpty(Mono.just(ShopSearchResponse.empty()))
.onErrorResume(error -> Mono.just(ShopSearchResponse.empty()))
.map(ShopSearchResponse::toShopNumbers);
}
private Mono<String> getRegionCode(Longitude longitude, Latitude latitude) {
return geoApiCircuitClient.getRegionCode(longitude.getValue(), latitude.getValue())
.switchIfEmpty(Mono.error(FailedToGetRegionCodeException::new));
}
}map과 flatMap의 차이를 잘 알고 있는가?
가게 노출 시스템에서는 non-blocking, 비동기로 요청을 처리하기 위해 WebFlux와 reactor를 사용합니다.
위의 예시 코드에서처럼, 하나의 요청을 처리하는 과정에서 외부 api 요청에 대한 응답을 받아서 flatmap으로 처리하는 경우가 많았습니다.
처음에는 flatmap을 단순히 Mono<Mono
reactor의 flatmap은 단순히 Mono의 depth를 펼쳐 주는 역할만 하는 것이 아닙니다.
reactor에서 map과 flatmap은 큰 차이가 있는데, 그 중 하나는 flatmap에서 context switching이 일어날 수 있다는 점입니다.
잘못 사용하면 시스템의 성능이 떨어질 수 있으니 주의해서 사용해야 합니다.
지금 코드에서는 별다른 문제가 없을지도 모르지만 차이점에 대해서는 조금 더 알아보는 것이 좋겠습니다.
context…switching…이 일어날 수 있다구요…???? 저는 정말 아무것도 모르고 flatmap을 사용하고 있었습니다.
나중에 문서를 살펴보니 두 메서드는 아래와 같이 분명하게 차이가 있었습니다.
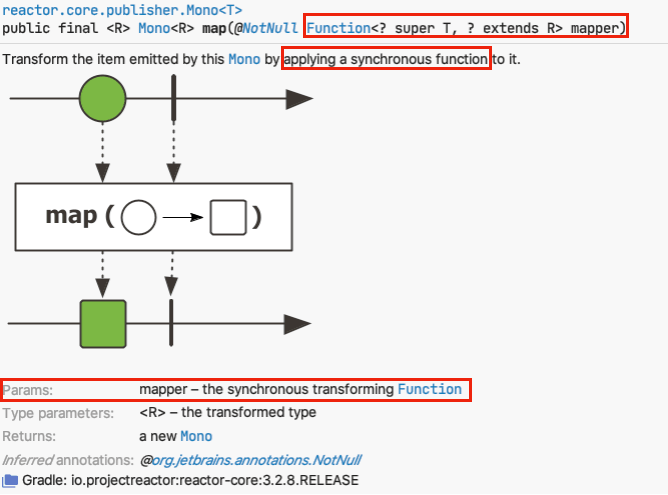
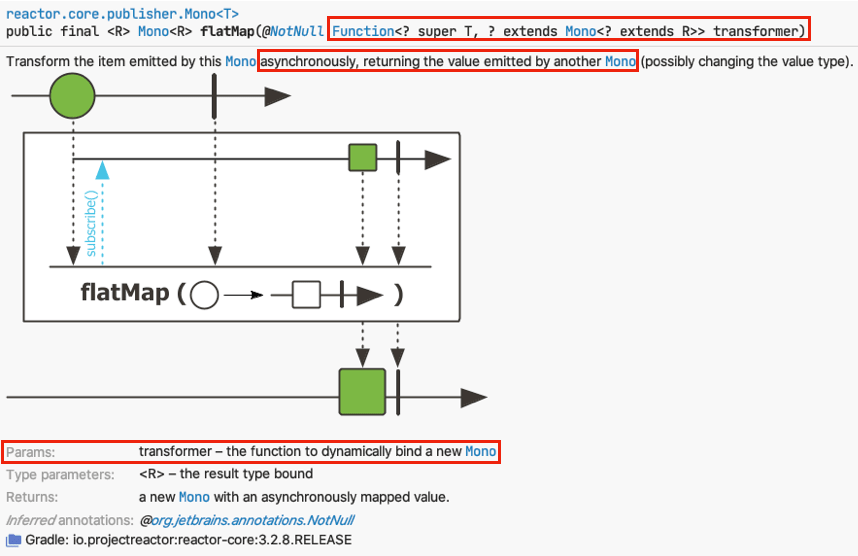
사실 메서드 parameter만 봐도 알 수 있듯이, Mono의 flatmap은
‘별도의 stream에서 Mono를 방출하는 Function 타입 transformer’를 인자로 받습니다.
간단히 말해, 비동기 function를 transformer로 적용할 수 있다는 뜻이죠.
그러면 해당 transformer를 별도의 thread에서 비동기적으로 수행하는 과정에서 context switching이 일어날 수 있겠죠.
저희 시스템에서는 어떤 상황에서 context switching이 일어날 수 있는지,
그래서 map을 사용할 때보다 flatmap을 사용한 경우에 오히려 성능이 떨어지게 되는지
아래와 같이 간단하게만 테스트를 한 번 작성해 보았습니다. 우선 map과 flatmap이 크게 성능 차이를 보이지 않는 경우입니다.
class MapVsFlatMap {
private static BlockingQueue<Mono<Integer>> eventQueue = new LinkedBlockingQueue<>();
// 처리해야할 가상의 event를 담는 queue
private static final String MAPPER_STRING = "transformed";
// map의 mapper 결과물로 사용할 String
private static final Mono<String> TRANSFORMER_STRING = Mono.just("transformed");
// flatmap의 transformer 결과물로 사용할 Mono String
static {
int trial = 100; // 100, 1000, 10000, 100000, 1000000 으로 변화를 주며 성능 측정
for (int number = 0; number < trial; number++) {
eventQueue.add(Mono.just(number)); // 가상의 event 생성
}
}
@Test
void map() throws InterruptedException {
while(!eventQueue.isEmpty()) {
eventQueue.take()
.map(number -> MAPPER_STRING)
.subscribe();
}
}
@Test // 위 테스트와 동시에 진행하면 lock이 걸려 테스트가 수행되지 않을 수 있습니다. 각 테스트는 별도로 수행해줍니다.
void flatMap() throws InterruptedException {
while(!eventQueue.isEmpty()) {
eventQueue.take()
.flatMap(number -> TRANSFORMER_STRING)
.subscribe();
}
}
}가게노출 시스템에서는 주로 다량의 Mono 데이터를 처리하는 일이 많기 때문에 위와 같이 Mono 이벤트들이 담긴 queue를 만들고,
map과 flatmap이 각각 queue의 event를 소비하는 상황을 가정하였습니다.
그리고MAPPER_STRING과 TRANSFORMER_STRING은 map과 flatmap의 메서드 수행 시간을 보다 정확히 비교하기 위해
미리 static으로 만들어 두도록 하였습니다. 각 테스트가 잘 작동하는지 확인하기 위해 로그와 함께 수행해보겠습니다.
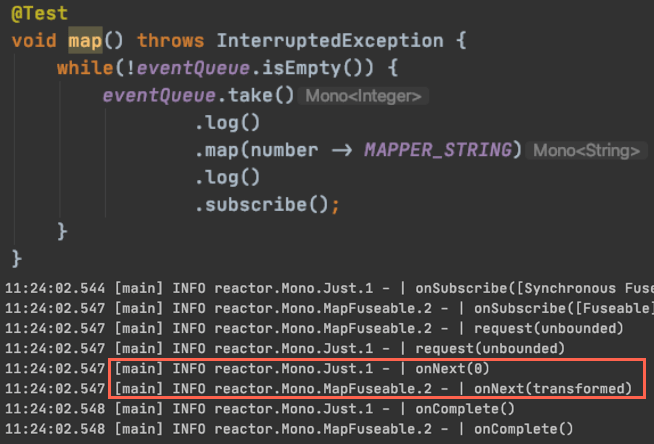
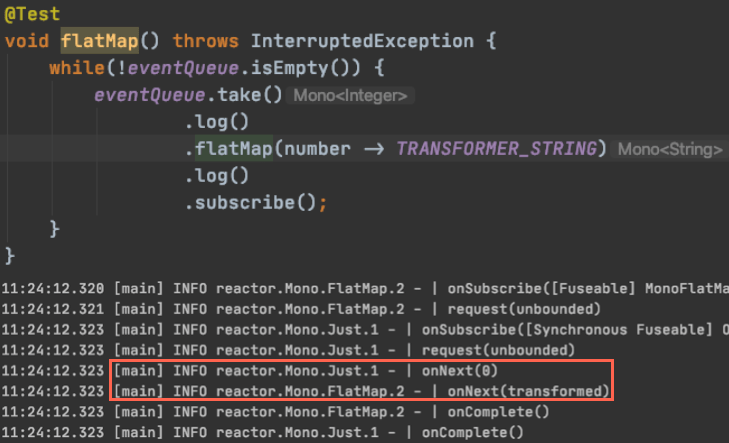
두 테스트 모두 Mono
그리고 로그에서 보이듯, flatMap의 인자로 들어오는 transformer에 별다른 처리를 해주지 않으면 context switching이 일어나지 않습니다.
모두 같은 thread에서 작업이 이루어집니다. 이번에는 다음과 같이 flatmap의 인자로 들어갈 transformer를 별도의 thread에서 수행하도록 아래와 같이 코드를 수정해 보겠습니다.
As-is
private static final String MAPPER_STRING = "transformed";
private static final Mono<String> TRANSFORMER_STRING = Mono.just("transformed"); // flatmap의 인자로 들어갈 transformerTo-be
private static final String MAPPER_STRING = "transformed";
private static final Mono<String> TRANSFORMER_STRING = Mono.just("transformed")
.subscribeOn(Schedulers.elastic());이렇게 flatmap의 transformer를 ThreadPool 내의 별도 thread에서 수행하도록 하고, flatmap test를 다시 수행하면
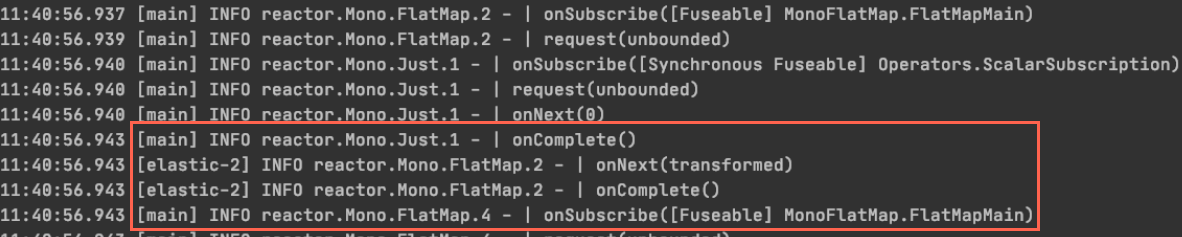
로그를 통해 context switching이 일어나는 것을 관찰할 수 있습니다.
Contect switching이 일어나는 것을 확인 하였으니,
Context switching이 일어나지 않는 경우와 일어나는 경우 각각에 대해 event 개수를 늘려 가며 수행 시간을 비교해 보겠습니다.
event 개수를 늘려 가며 각각의 경우에 대해 map과 flatmap의 수행 시간을 간단하게 측정해 보았습니다.

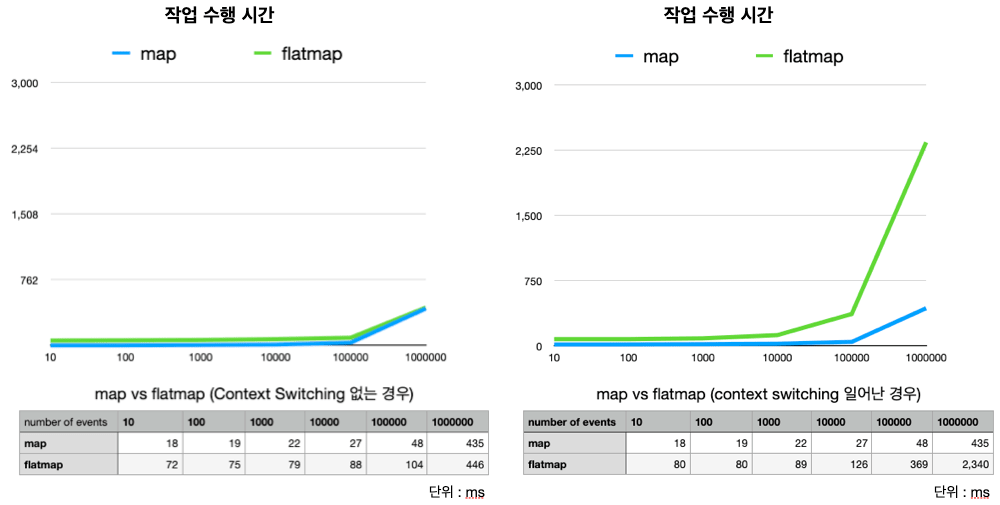
Context switching이 일어나지 않으면 map과 flatMap의 성능에 있어서 거의 차이가 없습니다.
하지만 flatMap에서 Context switching이 일어나는 경우 처리해야 하는 event 개수가 많아질수록 수행 시간이 급격히 길어지는 것을 관찰할 수 있었습니다.
flatmap을 활용하면 병렬 처리를 통해 성능이 대폭 향상되는 경우도 있겠지만, 잘못 사용하면 오히려 성능이 떨어지게 될 수도 있음을 확인하였습니다.
이외에도 코드 스타일, 패키지 구조, 의존성 관리 등 다양한 측면에서 코드 리뷰를 받을 수 있었습니다. 덕분에 짧은 기간 동안 많은 배움이 있었던 것 같습니다.
코드리뷰 마지막에 팀장님께서 우리는 절대로 장애가 나면 안 된다는 말씀을 강조하셨습니다. 우리는 제일 앞단 서버를 담당하고 있기 때문에 장애가 나면 그건 전면 장애고, 정말 잠깐 동안의 장애더라도 회사와 가게 사장님들께 커다란 손실이 생길 수 있다고 하셨습니다. 그래서 우리 팀의 가장 중요한 목표는 무장애라는 말씀과 함께, 사용하는 기술들을 정말 깊게 파악하고 있어야 한다고, 코드 한 줄 작성할 때에도 정말 문제가 없는지 고민하고 신경써서 작성해야 한다고 하셨습니다.
절대로 장애가 나면 안 된다는 말씀이 두고두고 마음에 와 닿았습니다. 코드 한 줄 한 줄에 실리는 책임감이 이전과 달라야겠다는 생각을 많이 했습니다.
서비스 배포
백엔드 구성에 대한 피드백 반영을 마치면 요구사항에 맞춰 화면을 그리고, 사내 테스트용 AWS VPN에 배포하여 동작을 확인합니다.
프로젝트 배포시 요구조건은 아래와 같습니다.
- 트래픽이 많아지면 자동으로 scale out 시킬 수 있도록 구축
- CI/CD가 이루어질 수 있도록 구축
- 배포시 무중단 배포
요구조건에 맞게 배포하기 위해 다음과 같은 배포 전략을 세우고 배포 환경을 구성해 보았습니다.
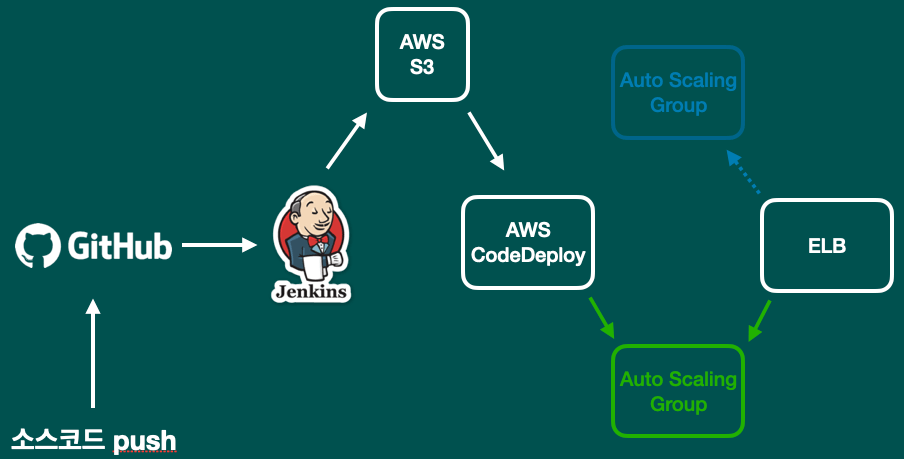
코드리뷰때와 마찬가지로 배포 전략에 대해서도 피드백을 받습니다.
그리고 서버 배포까지 마무리하면 파일럿 프로젝트가 모두 마무리됩니다.
첫 업무
파일럿 프로젝트가 마무리된 기쁨도 잠시, 프로젝트를 마치자마자 그 다음날 바로 첫 업무에 투입되었습니다. (?!) 무릇 회사란..

처음 받은 업무는 가게 목록 정렬 및 필터링 관련 업무였는데요,
각 가게 목록 노출 지면에서 원하는 조건에 따라 정렬 또는 필터링된 조건으로 가게 목록 조회 요청을 할 수 있도록
정렬 옵션과 필터 옵션들을 만들어 관리하는 일이었습니다.
첫 업무였던 만큼 우여곡절이 많았습니다.
처음 일을 하며 어떤 부분이 어려웠는지, 그리고 팀에서는 어떤 방식으로 일을 하고 있는지 간단하게만 정리하고 마무리하겠습니다.
하위 호환 문제
배달의 민족 서비스는 앱 서비스입니다.
앱이 한번 배포가 나가고 누군가 어플을 다운 받으면 사용자 측에서 업데이트 하기 전까지는 앱 기능을 수정할 수 없습니다.
새로운 버전이 나올 때마다 모든 사용자들이 업데이트를 해주면 좋겠지만, 애석하게도 일부 사용자들은 업데이트를 하지 않고 사용하기도 합니다.
그래서 서버 측에서는 기능이 개편 되더라도 개편되기 이전의 하위 버전에 대한 기능을 유지해야 하는 경우가 많습니다.
기능이 한두 개도 아닌데, 각각의 기능이 계속 발전하면서 버전까지 여러 개가 생기면 정말 코드가 몇 배는 복잡해집니다.
기능 구현을 하면서 버전도 고려하여 하위 호환을 유지하되, 중복 없이 깔끔한 코드를 만드는 것이 처음에 상당히 어려웠습니다.
프로젝트를 진행하며 만났던 문제를 하나 예로 들자면,
하위 버전에서 들어오는 정렬 옵션의 종류와 새로운 버전에서 들어오는 정렬 옵션의 종류가 다른 경우에도
서버에서 모든 정렬 종류들을 지원할 수 있도록 구현해야 하는 경우가 있었습니다.
if문으로 버전 분기를 태울 수도 있지만, 아래와 같이 어댑터를 구현해
하위 버전에서 들어오는 정렬 옵션과 최신 버전에서 들어오는 정렬 옵션을 일관적으로 매핑하여 처리해 주었습니다.
public class ListingSortAdapter {
private static final Map<String, String> sortTypeMappedByCode = Stream<SortType[]>.of(
LegacySortingTypeA.values(), // SortingType들은 모두 Enum으로 관리합니다.
LegacySortingTypeB.values(),
LegacySortingTypeC.values(),
NewSortingType.values())
.flatMap(Arrays.::stream)
.collect(Collectors.toMap(sortType -> sortType.generateCode(),
sortType -> sortType.getValue(),
(o1, o2) -> o1));
public static String resolveListingSortKind(String sortName) {
return sortTypeMappedByCode.getOrDefault(sortName, NewSortingType.DEFAULT.name());
// 값이 없는 경우 에도 null이 아닌 기본값을 반드시 되돌려주도록 합니다
}
}최대한 코드 중복을 줄이면서 서로 다른 버전의 코드들을 효과적으로 관리할 수 있도록 하는 일이
앞으로 계속 만나게 될 과제가 아닐까 싶습니다.
그래도 코드가 보이네..???
당연한 이야기겠지만 파일럿 프로젝트로 미니 가게 노출 시스템을 구현해 본 것이 상당히 큰 도움이 되었습니다.
도메인에 대한 파악도 아직 부족하고, 정책도 모르는 게 많고,
Webflux와 리액티브 프로그래밍을 알게 된 지는 고작 한두 달 남짓 됐을 때였지만,
그래도 파일럿 프로젝트를 진행하면서 운영에서 돌아가는 코드를 봐둔 덕에 전체적인 흐름을 어느정도 파악할 수 있었습니다.
덕분에 요구사항이 주어졌을 때 코드가 어디에 들어가야 할 지 대략적인 그림을 그려볼 수 있었던 것 같습니다.
페어프로그래밍
저희 파트에서는 신입 개발자의 온보딩을 위해, 그리고 서로 코드를 공유하고 버스 펙터(bus factor)를 낮추기 위해 페어 프로그래밍을 하고 있습니다. 필요한 지식을 전달하거나, 핵심적인 로직을 공유해야 하는 경우 페어로 이야기를 나누며 기능을 구현합니다. 첫 업무를 진행하기에 앞서 기존 코드들을 재구성해야 할 필요도 있었고, 핵심 로직을 짜기 위해 알아야 하는 배경 지식도 있어서 용근님과 페어로 초기 설계를 진행했습니다.
코드 리뷰
파트 내에서 업무를 진행하며 작성한 모든 코드에 대해서 반드시 코드 리뷰를 받습니다. 코드 리뷰를 통해 기능 구현 과정에서 놓친 부분을 보완하기도 하고, 더 나은 방향으로 코드를 개선하기도 합니다.
일정의 압박이 있지만 기능이 동작하도록 구현하는 데에서 멈추지 않고, 지속적으로 코드 품질을 개선해 나가고 있습니다.
마무리하며
입사한 뒤로 4개월이 정말 쏜살같이 지나간 것 같습니다. 첫 직장이었던 만큼 모르는 부분도, 미숙한 점도 정말 많았습니다.
그럼에도 잘 적응해 일을 시작할 수 있었던 것은 함께 일하시는 분들께서 많이 알려 주시고, 배려해 주신 덕이 아닐까 싶습니다.
지난 4개월간 배움도 많았지만, 앞으로 배워야 할 것들을 훨씬 많이 보게 된 것 같습니다.
좋은 팀에 합류하게 된 만큼, 잘 익히고 배워서 쓸모 있는 구성원으로 자리매김할 수 있기를 바랍니다.
긴 글 읽어주셔서 감사합니다 🙂
