주니어 개발자의 클린 아키텍처 맛보기
안녕하세요 딜리버리플랫폼팀 송인태입니다.
우아한테크캠프를 마치고 팀에서 들어온 지 1년 정도 되면서 개발을 할 때 어떻게 하면 유지 보수하기 쉽게 개발할지 고민을 하던 도중 Robert C. Martin이 블로그에 기재한 Clean Architecture라는 글을 읽게 되었습니다. 이 글을 저 나름대로 이해해 보고 이러한 내용이 실제 프로젝트에 어떻게 적용되며, 더 나아가 고민할 점이 무엇인지 생각하게 되었습니다.
지금부터 아래에서 언급하는 내용은 제가 이해한 내용과 업무를 진행하면서 생각한 내용이기 때문에 틀린 부분이 있을 수 있습니다. 혹시 다른 생각이 있으면 댓글을 통해 서로 의견을 공유할 수 있으면 좋을 것 같습니다.
의존성 규칙
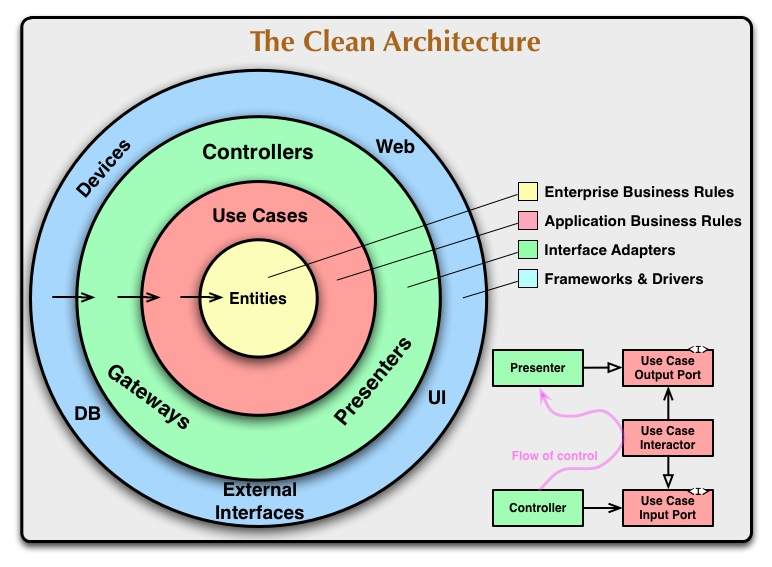
출처 : http://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
Robert C Martin 블로그의 글에서는 대부분의 아키텍처는 세부적인 차이는 있어도 공통적인 목표는 계층을 분리하여 관심사의 분리하는 것이라고 말하는데, 이런 아키텍처가 동작하기 위해서는 의존성 규칙을 지켜야 한다고 합니다.
의존성 규칙은 모든 소스코드 의존성은 반드시 외부에서 내부로, 고수준 정책을 향해야 한다고 말합니다. 즉 업무의 업무 로직을 담당하는 코드들이 DB 또는 Web 같이 구체적인 세부 사항에 의존하지 않아야 합니다. 이를 통해 업무 로직(고수준 정책)은 세부 사항들(저수준 정책)의 변경에 영향을 받지 않도록 할 수 있습니다.
이러한 의존성 규칙을 지키기 위해서 글에서는 "What data crosses the boundaries", "Crossing boundaries"와 같은 상황에 대해 설명하는데 이를 실제 프로젝트에서 어떻게 적용되고 무엇을 주의해야 하는지 알아보겠습니다.
아래의 글을 읽다보면 고수준, 저수준이라는 단어가 자주 등장하는데 대략적으로 다음과 같다고 생각합니다.
1. 고수준 : 상위 수준의 개념, 추상화된 개념
- 예시: 데이터를 저장한다, 구역 배달료를 구한다
2. 저수준 : 추상화된 개념을 실제 어떻게 구현할지에 대한 세부적인 개념
- 예시: RDB에 데이터를 저장한다, 폴리곤 구역에 속한 배달건에 대해 배달료를 구한다What data crosses the boundaries
첫 번째로는 경계 간의 데이터를 전달할 때 무엇을 전달해야 하는가에 대한 이야기입니다. 의존성 규칙을 지키기 위해서는 우리가 사용하는 단순하고, 고립된 형태의 데이터 구조를 사용하는 것을 추천합니다. 만약 DB의 형식의 데이터 구조 또는 Framework에 종속적인 데이터 구조가 사용되게 된다면, 이러한 저수준의 데이터 형식을 고수준에서 알아야 하기 때문에 의존성 규칙을 위반하게 됩니다.
저희 팀에서도 이러한 경계 간의 데이터를 전달할 때 간단한 구조의 Data Transfer Objects(DTO)를 이용하고 있는데, 이를 만들면서 몇 가지 생각이 들게 되었습니다.
DTO 간의 중복 코드
업무 로직을 구현하다 보면 클라이언트로부터 전달되는 데이터를 DTO를 통해 받아서 처리합니다. 일반적으로 요청은 크게 등록, 수정, 조회, 삭제의 형태로 오게 되는데, 저는 요청에 따라 DTO를 어떻게 만들어야 할지에 대한 고민을 많이 했습니다. 초반에 로직을 구현하다 보면 생성과 수정 요청은 거의 비슷한 형식의 데이터, 검증 로직을 필요로 하게 됩니다. 때문에 이를 통합하여 중복 코드를 제거할지, 기능에 따라 분리할지에 대한 고민을 많이 했습니다.
public class CreateRequest {
private String name;
private LocalDate startDate;
private LocalDate endDate;
...
}
public class UpdateRequest {
private String name;
private LocalDate startDate;
private LocalDate endDate;
...
}<클린 아키텍처> 책에서 이에 대한 좋은 내용을 언급하는데, 그 내용은 중복에도 종류가 있다는 것이다.
- 진짜 중복
- 한 인스턴스가 변경되면, 동일한 변경을 그 인스턴스의 모든 복사본에 반드시 적용해야한다.
- 우발적 중복(거짓된 중복)
- 중복으로 보이는 두 코드의 영역이 각자의 경로로 발전한다면, 즉 서로 다른 속도와 다른 이유로 변경된다면 이 두 코드는 진짜 중복이 아니다.
저는 저장과 수정 사이의 DTO의 중복은 우발적 중복에 속한다고 생각합니다. 초반에는 코드가 비슷할지 모르지만 각 기능은 서로 다른 이유와 속도로 변경될 가능성이 높기 때문입니다.
간단한 예로 스케줄을 저장해야 하는 기능을 개발한다고 생각해봅시다. 스케줄을 처음 저장할 때는 시작 일자가 과거 시간이 될 필요가 없기 때문에 이에 대한 유효성 검사를 진행합니다.
public class CreateRequest {
public void assertValidation() {
if(startDate.isBefore(LocalDate.now())) {
throw new IllegalArgumentException();
}
}
}하지만 수정을 하는 경우에는 이미 해당 데이터가 과거 날짜일 수 있기 때문에 StartDate에 대한 유효성 검사가 필요 없습니다.
public class UpdateRequest {
public void assertValidation() {
if(startDate.isBefore(LocalDate.now())) { ---> 불필요한 체크
throw new IllegalArgumentException();
}
}
}즉 이렇게 서로 다른 이유와 속도로 변경이 될 수 있는 상황에서는 DTO를 분리하는 것이 좋다고 생각합니다.
Entity가 DTO를 직접 참조하는 문제
가끔씩 코드를 보면 Entity를 생성할 때 Controller로 부터 생성된 Request(DTO) 객체를 이용하는 경우를 보았습니다.
public class Entity {
...
public static Entity of(Request request) {
...
}
}이러한 코드를 보고 Web으로 오는 데이터를 직접 참조하지 않고 DTO를 통해 다른 경계로 전달하기 때문에 규칙을 지켰다고 생각할 수 있습니다. 하지만 제가 생각하기에 의존성 규칙의 목적은 저수준의 개념이 고수준의 개념에 영향을 주지 않게 하기 위함이라고 생각합니다.
위의 코드와 같이 Entity가 직접 DTO를 참조하게 된다면 DTO의 변경에 의해 Entity도 변경될 수 있다는것을 알려줍니다. 따라서 Entity를 생성하는 UseCase 계층에서 DTO의 데이터를 꺼내서 Entity를 생성하는것이 DTO의 변경에 의해 Entity가 변경할 가능성을 낮출수 있다고 생각합니다.
Crossing boundaries
두 번째로는 Crossing boundaries 입니다. 이는 제어의 흐름은 원의 내부에서 외부로 향할 수 있는데 소스코드의 의존성은 이렇게 될 경우 의존성 규칙을 위배하게 되므로, 의존성 역전의 원칙을 이용하여 이를 해결해야 한다는 이야기입니다. 이는 조금더 풀어서 이야기하면 고수준의 정책은 저수준의 정책에 의존해서는 안된다는 이야기입니다.
간단한 예를 통해 알아보겠습니다. 일반적으로 조회 요청이 일어나면 이를 처리하기 위해 제어의 흐름과 소스코드의 의존성은 아래와 같습니다.
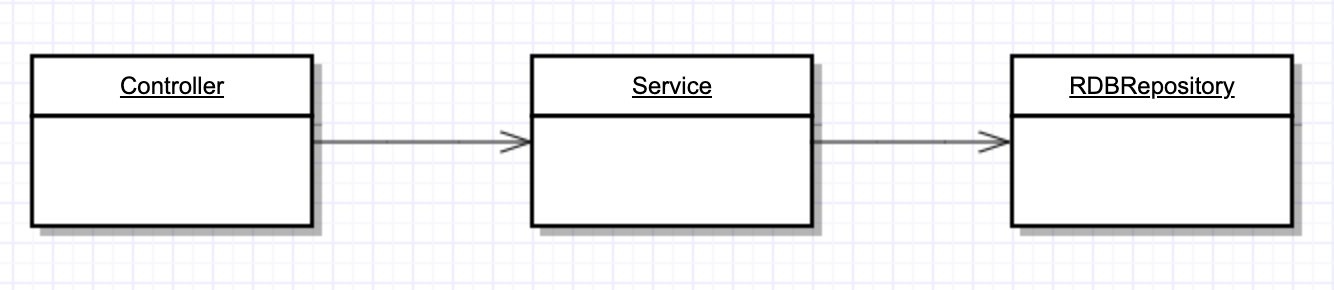
이러한 제어의 흐름과 같이 소스코드 의존성을 가지게 된다면 Service가 구체적인 RDBMS를 구현한 구현체(저수준의 정책)를 직접 참조하게 되는데 이는 의존성 규칙을 위반하게 됩니다. 이러한 문제의 가장 간단한 해결책은 DIP(의존성 역전의 원칙)을 적용하는 것입니다.

추상화된 Repository 인터페이스를 두어서 Service가 이를 참조하고, 구체적인RDRepository가 이러한 인터페이스를 구현하게 된다면 소스코드의 의존성을 역전시킬 수 있습니다. 이러한 DIP를 통해 우리는 Service는 DB의 구체적인 세부사항을 알 필요도 없고, DB의 변경에도 영향을 받지 않게 됩니다.
지금까지 저는 Crossing boundaries의 개념을 DB 또는 Framework & Drivers 계층에 대해서만 생각했습니다. 하지만 이번 프로젝트를 진행하면서 업무들 사이에서도 Crossing boundaries 개념을 적용할 수 있다는 것을 생각하게 되었습니다.
팀에서 배달과 배달료에 관한 업무를 진행하면서, 배달과 배달료에 대해 Crossing boundaries 개념을 적용할 수 있도록 노력했습니다.
배달과 배달료의 관계
배달료를 구할 때 크게 두 가지 정책이 있습니다. 첫 번째는 배달을 수행하는 라이더의 거리 기반 요금제에 따른 요금, 두 번째는 구역 할증에 따른 추가 요금입니다. 따라서 배달료를 구하기 위해서는 아래와 같은 제어의 흐름이 발생합니다.
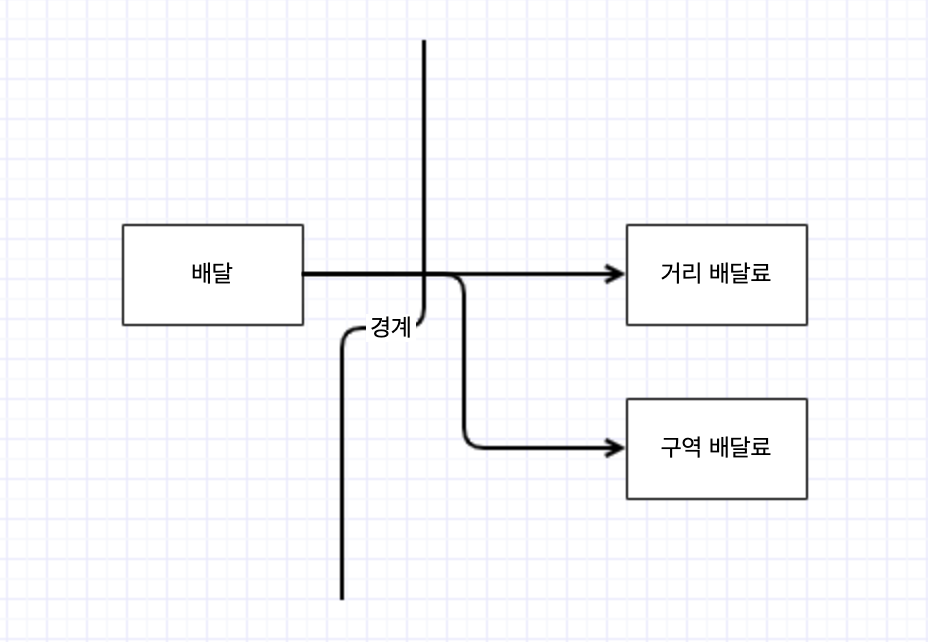
이러한 제어의 흐름 데로 소스코드 의존성을 주게 된다면 배달에 관한 정책에서 구체적인 거리 배달료 정책과, 구역 배달료 정책에 강하게 의존하게 됩니다. 즉 각각의 배달료 정책이 변경될 때마다 배달에 관한 부분도 변경될 여지가 생기게 됩니다.
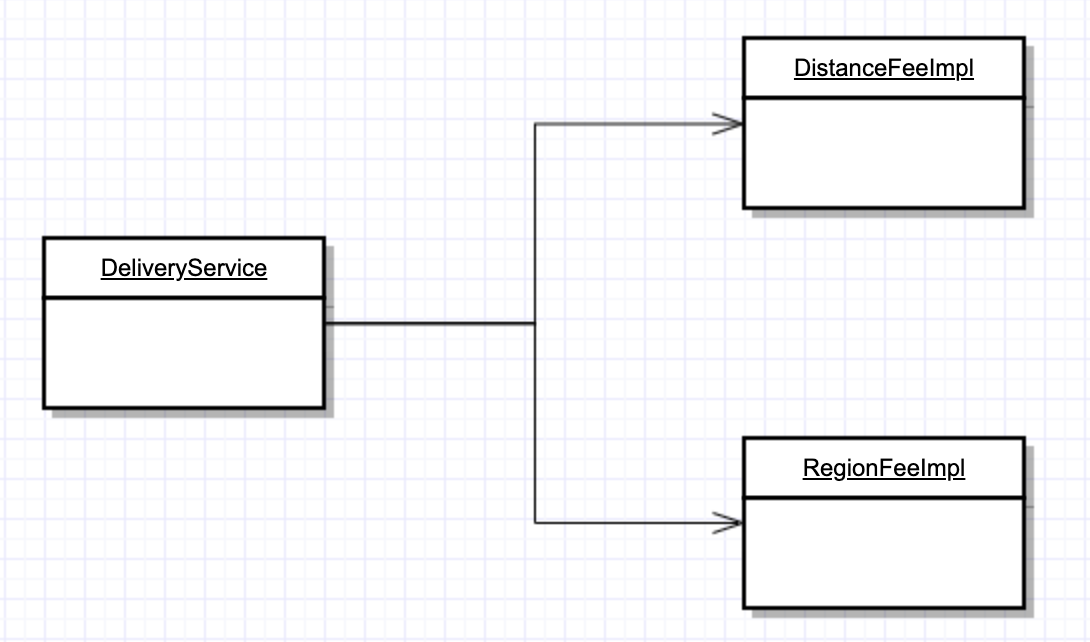
따라서 이 경우에도 DIP를 적용해서 배달에 관한 정책에서 구체적인 배달료 구하는 정책을 분리시킬 수 있습니다. 이를 통해 거리 배달료나, 구역 배달료 정책이 변경되도 배달 도메인에서는 변경에 대한 영향을 받지 않게됩니다.
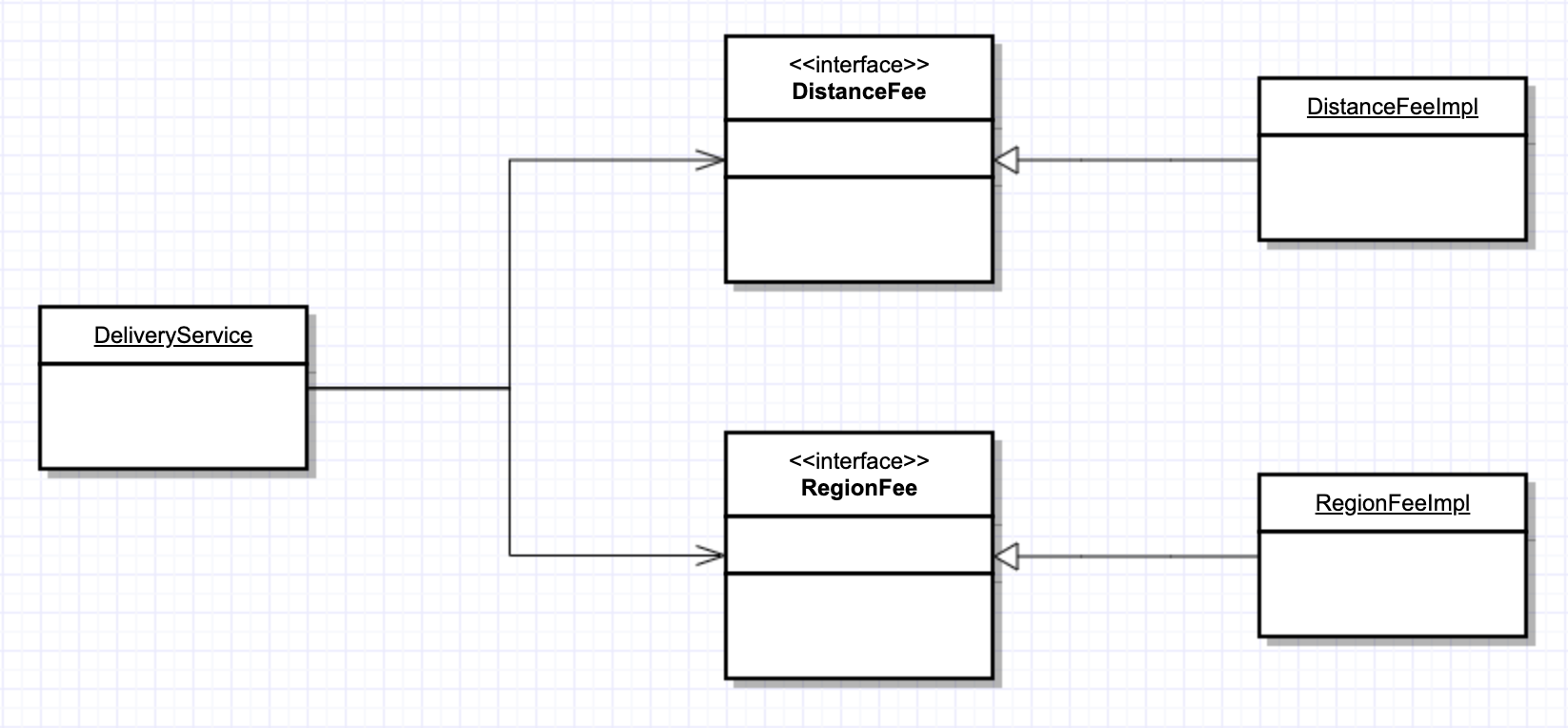
DIP를 적용하고 한 가지 더 고민한 점은 배달료 정보를 얻기 위해서는 DistanceFee와 RegionFee를 의존성 주입을 받아서 사용해야 한다는 점입니다. 사실 클라이언트 입장에서는 이런 배달료를 구하기 위해서는 어떤 인터페이스들을 의존해야하는 가에 대한 구체적인 정보를 모르고 사용하는 것이 좋은데 이는 Facade를 제공하여 해결할 수 있습니다.
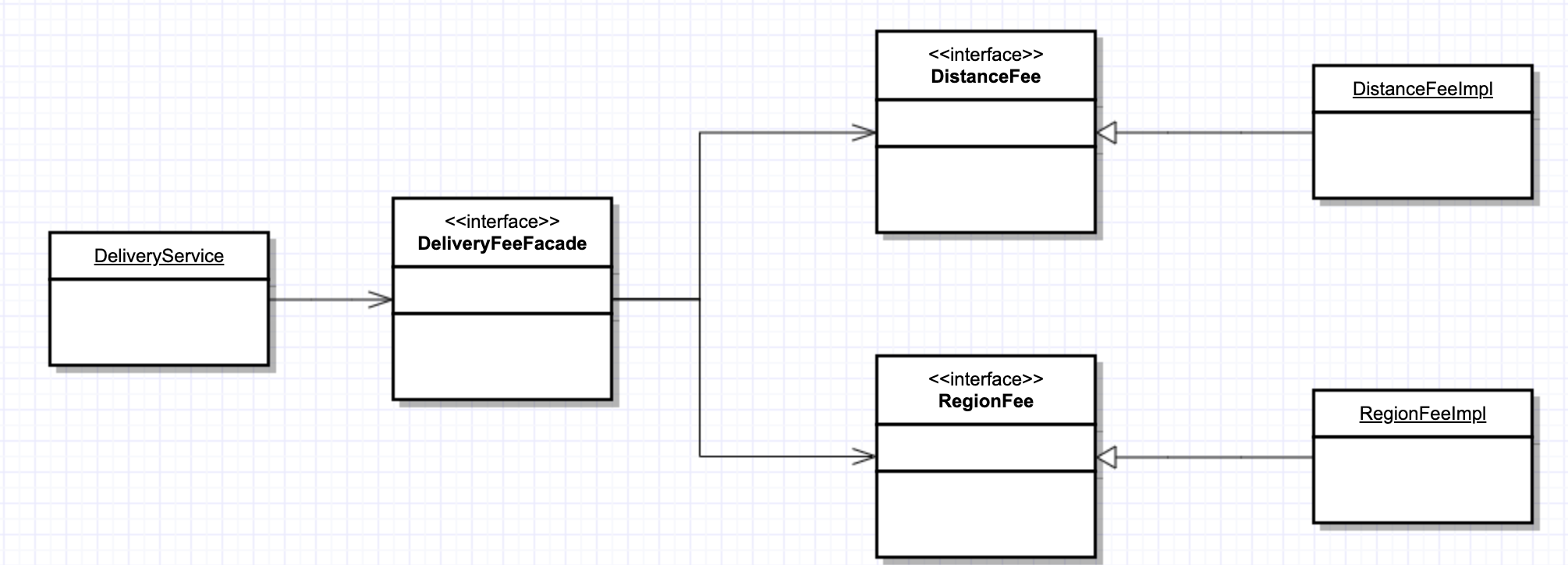
Facade를 제공하면 클라이언트는 배달료 정보를 얻기 위해 Facade 인터페이스에만 의존하면 됩니다.
- <클린 소프트웨어>라는 책에서는 Facade는 정책 적용이 크고 가시적이어야 하는 경우 사용해야 한다고 얘기합니다
사실 현제처럼 2개 정도의 인터페이스만 바라본다면 Facade 인터페이스는 과할 수 있지만, 이는 팀원들과 협의를 통해 맞춰가면 된다고 생각합니다.
인터페이스 선언 시 주의할 점
DIP를 적용해서 인터페이스를 분리하면 구체적인 세부사항을 분리시킬 수 있다는 장점을 얻었습니다. 하지만 이런 인터페이스를 선언할 때도 주의할 점이 몇가지 있다고 생각합니다.
1. 인터페이스 분리
인터페이스를 작성할 때는 클라이언트가 필요로 하는 메서드를 기반으로 분리되어야 한다고 생각합니다. 이전까지는 인터페이스를 구현체 클래스에 의존하여 작성했기 때문에 클라이언트가 필요하지 않는 메서드까지 노출하게 되었습니다.
예를 들어 특정 도메인 객체가 배달료, 배달팁, 배달시간의 할증에 관한 정보를 가지고 있다고 하면 클라이언트가 사용할 인터페이스를 다음과 같이 구현체에 의존하여 작성했습니다.
public interface ExtraService {
long calculateExtraDeliveryFee(...);
long calculateExtraDeliveryTip(...);
long calculateExtraDeliveryTime(...);
}사실 각각의 메서드를 소비하는 클라이언트들은 모두 달랐지만 같은 인터페이스를 바라보았기 때문에 각각의 변경에 따라 영향을 받을 수 있는 클라이언트가 많아지게 되었습니다. 결국 이러한 변경의 영향을 줄이기 위해 각각의 클라이언트를 기반으로 인터페이스를 분리했습니다.
public interface ExtraFeeService {
long calculateExtraDeliveryFee(...);
}
public interface ExtraTipServie {
long calculateExtraDeliveryTip(...);
}
public interface ExtraTimeService {
long calculateExtraDeliveryTime(...);
}2. 인터페이스 명
인터페이스를 생성할 때 제가 하는 실수는 인터페이스와 메서드 명에 구현체 클래스를 나타내곤 했습니다. 이는 직접적인 의존성은 없다고 하지만 결국 클라이언트가 세부적 사항을 알게 한다고 생각합니다. 따라서 인터페이스의 이름, 메서드 이름을 정할 때도 구체적인 클래스의 이름을 드러내지 않는 것이 중요하다 생각합니다.
3. 인터페이스 메서드 파라미터
인터페이스의 파라미터를 어떻게 넘길까 고민할 때 저는 Entity, DTO, 필요한 데이터를 각각 넘기는 방법을 3가지를 고민했습니다. 이 또한 변경의 측면에서 고민해 볼 수 있습니다.
- Entity, DTO를 전달하는 방법
- 저는 일반적으로 업무와 관련된 인터페이스를 사용하면 Entity 자체를 넘기거나 DTO를 파라미터로 사용합니다. 이러한 이유는 업무 로직의 세부사항은 언제든지 변경될 수 있기 때문입니다. Entity나 DTO를 사용하면 이러한 변경이 클라이언트에 영향을 미치는 것을 줄일 수 있습니다.
//DTO를 사용할 때 팩토리 메서드를 사용하여 Entity를 받게 구현한다면, //필요한 데이터가 추가되더라도 클라이언트의 변경을 줄일 수 있습니다. public class DTO { public static ofEntity(Entity entity) { ... } } - 보통 Enitity보다 DTO를 사용하는 경우는 인터페이스가 특정 도메인에 종속되는 것이 아니라 범용적일 때 사용하고 있습니다.
- 저는 일반적으로 업무와 관련된 인터페이스를 사용하면 Entity 자체를 넘기거나 DTO를 파라미터로 사용합니다. 이러한 이유는 업무 로직의 세부사항은 언제든지 변경될 수 있기 때문입니다. Entity나 DTO를 사용하면 이러한 변경이 클라이언트에 영향을 미치는 것을 줄일 수 있습니다.
- 필요한 데이터를 각각 넘기는 방법
- 모든 인터페이스에 Entity나 DTO를 넘기는 것은 과할 수 있습니다. 제가 생각하기에 불변에 가까운 유틸성 인터페이스는 필요한 인자를 파라미터로 받으면 오히려 명확할 수 있다고 생각합니다.
public interface DateUtil { long between(Date from, Date to); }
- 모든 인터페이스에 Entity나 DTO를 넘기는 것은 과할 수 있습니다. 제가 생각하기에 불변에 가까운 유틸성 인터페이스는 필요한 인자를 파라미터로 받으면 오히려 명확할 수 있다고 생각합니다.
프로젝트를 진행하며 고민한 점
사실 이렇게 적용하면서 두 가지 생각을 하게 되었습니다.
첫 번째는 "이런 배달료 정책 같은 경우는 자주 변경되는 경우가 많이 없는데 이렇게 인터페이스를 통해 과하게 구현하는 게 맞는가?"에 대한 고민이었습니다. 하지만 지금의 생각은 업무 정책은 적던 많던 항상 변경될 수 있는 포인트라고 생각합니다. 따라서 변경할 수 있는 여지를 두어서 추후에 변경이 생기더라도 큰 영향 없이 변경할 수 있도록 구현해야 한다고 생각합니다. (사실 이번 프로젝트도 구역 할증에 대한 정책이 완전히 변경되어서 진행하게 되었습니다.)
두 번째는 "이렇게 업무 간의 경계를 클래스부터 시작하여, 패키지, 모듈까지 분리해 나가면 더 유연하고 확장 가능한 서비스를 운영할 수 있지 않을까?"라는 생각입니다. 아직은 많이 경험해보지 못했지만 앞으로는 이런 점도 생각해보면서 업무를 진행해보려고 합니다.
글을 마무리하며
이번 글은 제가 프로젝트를 하면서 느꼈던 것 중 그나마 정리하기 편한 코드 레벨의 글을 작성했습니다. 사실 프로젝트를 진행하는 동안 팀원들과 페어 프로그래밍, 코드 리뷰를 통해 수많은 이점을 얻을 수 있다는 것을 깨달았습니다. 글에서 얘기한 거와 같이 생각하고 코드를 작성할 수 있었던 것도 페어 프로그래밍과, 코드 리뷰를 통해 가능했습니다. 다음에 기회가 된다면 페어 프로그래밍과, 코드 리뷰 방법에 대해서도 머릿속에서 조금 더 구체화 시키고 정리하여 글을 통해 공유하도록 하겠습니다.
