Spring 웹 애플리케이션에서 사용하지 않는 API를 찾아보자

안녕하세요. 배민주문서버개발팀 송정훈입니다.
이 글에서는 스프링 웹 애플리케이션에서 사용자 요청에 대한 로그를 수집하고, 사용되고 있지 않는 API를 쉽게 확인하는 방법에 대해서 설명하고자 합니다.
이 많은 API 들을 다 사용하는 걸까?
저희 팀은 배달의민족 서비스의 주문시스템을 만들고 있습니다.
주문시스템은 크게 2개의 API 애플리케이션에서 150여 개의 API를 제공하고 있습니다.
이 중에선 이전에 협업부서의 요청으로 만들었지만, 현재는 사용되고 있지 않은 API도 다수 포함이 되어 있습니다.
사용하지 않는 API가 많다는 건 애플리케이션을 유지보수하는 저희 팀의 입장에선, 현재 가지고 있는 부채 중 하나입니다.
우선 오랫동안 사용되고 있지 않았기 때문에 정상적인 동작은 보장하기가 어렵다는 문제가 있습니다.
그리고 애플리케이션에 변경사항이 생겼을 때 영향도를 파악해야 하는 범위가 늘어난다는 단점도 있습니다.
이러한 불필요한 API 들은 정리해두는 것이 시스템의 중요한 변경사항에 대한 영향도를 줄이고, 개발 및 운영비용을 줄일 수 있습니다.
(요즘 미니멀 라이프가 유행이지 않습니까? API 서버도 쓸모 없는 건 버리고 미니멀하게 가자구요.)
access log 로는 뭔가 좀 부족하다
특정한 API를 사용하고 있는지 확인해보기 위해 가장 먼저 떠올랐던 방법은 access log를 사용하는 방법입니다.
저희는 이미 Elasticsearch를 통해 수집된 access log를 확인할 수 있는 상태였으므로, kibana에 url 만 딱 치면 바로 결과를 확인할 수 있을 것으로 생각하였습니다.
하지만 그렇게 쉽게 해결이 되지 않았는데, 아래와 같은 문제가 발생하게 되었습니다.
@Controller
public class OrderController {
@GetMapping("/v1/orders/")
public OrderInfo getOrderInfo(@PathVariable("id") String id) {
// 블라블라
}
}저희는 알고 싶던건 위에 정의된 GET /v1/orders/라는 API가 실제로 사용여부였지만, access log에는 아래와 같이 기록이 되고 있습니다.
127.0.0.1 - - [12/Feb/2019:16:48:50 +0900] "GET /v1/orders/A0000001 HTTP/1.1" 200 50 "-" "-" "127.0.0.1"
127.0.0.1 - - [12/Feb/2019:16:49:00 +0900] "GET /v1/orders/A0000002 HTTP/1.1" 200 50 "-" "-" "127.0.0.1"
127.0.0.1 - - [12/Feb/2019:16:49:10 +0900] "GET /v1/orders/A0000003 HTTP/1.1" 200 50 "-" "-" "127.0.0.1"위 3건의 로그는 서로 다른 url 이지만, 실제로는 모두 같은 API를 호출하고 있습니다.
access log를 통해서 사용자가 실제 요청한 url은 알 수 있었지만, 컨트롤러에 정의된 특정 API (url 패턴)이 호출되었는지는 알기가 어려웠습니다.
그래서 다른 방법을 찾아보게 되었습니다. 좀 더 저희가 가진 목적에 부합하는 적합한 로그를 남기기로 말이죠.
정답은 HandlerMapping 이 알고 있다
스프링 웹 애플리케이션은 사용자의 요청을 처리하기 위한 Handler를 결정하는 과정에서 HandlerMapping 이라는 녀석을 사용하게 됩니다.
저희가 사용하는 애플리케이션은 RequestMappingHandlerMapping라는 구현이, 사용자 요청을 특정한 컨트롤러 메소드와 연결해주는 역할을 하고 있습니다.
이 과정에서 RequestMappingHandlerMapping는 가장 적합하다고 판단된 패턴을 HttpServletRequest 의 .bestMatchingPattern 이라는 이름의 속성으로 추가하게 됩니다.
이 속성을 사용한다면 쉽게 특정 API에 대한 호출을 확인하기 위한 로그를 남길 수 있을 것 같습니다.
저희는 이것을 ControllerLog라고 정의하고 아래와 같은 클래스를 생성하였습니다.
@ToString
@Getter
public class ControllerLog {
private String httpMethod;
private String urlPattern;
private ZonedDateTime requestedAt;
public ControllerLog(String method, String urlPattern, ZonedDateTime requestedAt) {
this.httpMethod = httpMethod;
this.urlPattern = urlPattern;
this.requestedAt = requestedAt;
}
}그래서 아래와 같은 HandlerInterceptor 코드를 작성해 보았습니다.
@Slf4j
@Component
public class ControllerLogInterceptor extends HandlerInterceptorAdapter {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
ControllerLog controllerLog = new ControllerLog(
request.getMethod(),
(String) request.getAttribute(HandlerMapping.BEST_MATCHING_PATTERN_ATTRIBUTE), // .bestMatchingPattern
ZonedDateTime.now()
);
log.info(contollerLog.toString());
return super.preHandle(request, response, handler);
}
}2019-02-12 16, requestedAt=2019-02-12T16:48:50.000+09:00[Asia/Seoul])
2019-02-12 16, requestedAt=2019-02-12T16:49:00.000+09:00[Asia/Seoul])
2019-02-12 16, requestedAt=2019-02-12T16:49:10.000+09:00[Asia/Seoul])이제 3건 모두 같은 API 요청이라는 게 한눈에 들어오고 있습니다.
어떤 API인지도 알기 쉽고요.
Elasticsearch 로 로그를 모아보자
이제 며칠 또는 몇 주 동안 모아온 로그를 가지고 특정한 API에 대한 요청이 있었는지를 확인해보려고 합니다.
저희는 Elasticsearch를 사용하기로 하였습니다.
특히 AWS에서 제공하는 Elasticsearch Service를 이용하면 쉽게 로그를 저장하고 탐색할 수 있는 환경이 갖춰집니다.
(AWS를 사용하지 않는다면 직접 Elasticsearch Cluster를 구축하셔도 됩니다.)
로그를 수집하는 방법은 여러 가지가 있겠지만 저희는 스프링 애플리케이션에서 Http Client를 사용하여 Elasticsearch Service로 로그를 전송하는 방법을 선택하였습니다.
애플리케이션에서 발생한 로그 데이터들은 메모리상에 모아놓고 있다가 30초마다 한 번씩 Elasticsearch Service로 전송되게 됩니다.
이 작업은 요청 스레드가 아닌 별도의 스레드에서 격리하여 처리하도록 하여 서비스에 영향이 없도록 해야 하며, 만약 Elasticsearch Service에 지연이 발생하더라도 메모리를 무한정으로 잡아먹지 않도록 구성해야 합니다. (로그 데이터를 버리더라도 말이죠.)
이런 작업은 Reactor (또는 RxJava)를 사용하면 쉽게 처리할 수 있습니다!
저희는 Reactor를 사용하기로 하였습니다.
@Configuration
public class ControllerLogConfig {
@Bean
public EmitterProcessor<ControllerLog> controllerLogEmitterProcessor() {
return EmitterProcessor.create();
}
@Bean
public FluxSink<ControllerLog> controllerLogSink(EmitterProcessor<ControllerLog> controllerLogEmitterProcessor) {
return emitterProcessor.sink(FluxSink.OverflowStrategy.DROP);
}
@Bean
public Flux<ControllerLog> controllerLogFlux(EmitterProcessor<ControllerLog> controllerLogEmitterProcessor) {
return emitterProcessor.publishOn(Schedulers.elastic());
}
}로그는 FluxSink<ControllerLog>를 사용하여 발행하면 되고 Flux<ControllerLog>를 사용하여 적당히 가공하여 사용하면 됩니다.
사용하는 쪽에선 Reactor에서 제공하는 엘라스틱 스레드를 사용하게 되므로 요청 스레드를 블로킹하는 일도 없습니다.
아까 만들었던 ControllerLogInterceptor를 수정합니다.
@Component
public class ControllerLogInterceptor extends HandlerInterceptorAdapter {
private final FluxSink<ControllerLog> controllerLogSink;
public ControllerLogInterceptor(FluxSink<ControllerLog> controllerLogSink) {
this.controllerLogSink = controllerLogSink;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
ControllerLog controllerLog = new ControllerLog(
request.getMethod(),
(String) request.getAttribute(HandlerMapping.BEST_MATCHING_PATTERN_ATTRIBUTE),
ZonedDateTime.now()
);
controllerLogSink.next(controllerLog);
return super.preHandle(request, response, handler);
}
}이제는 ControllerLogInterceptor에서는 slf4j를 사용하여 로그를 남기는 대신에 FluxSink<ControllerLog>를 사용하여 로그를 발행하게 됩니다.
기존과 동일하게 slf4j로도 로그를 남기기 위해서 아래와 같은 컴포넌트를 추가합니다.
@Slf4j
@Component
public class Slf4jControllerLogProcessor {
private final Flux<ControllerLog> controllerLogFlux;
private Disposable disposable;
public Slf4jControllerLogProcessor(Flux<ControllerLog> controllerLogFlux) {
this.controllerLogFlux = controllerLogFlux;
}
@PostConstruct
public void init() {
disposable = controllerLogFlux.subscribe(it -> log.info(it.toString()));
}
@PreDestroy
public void destroy() {
if (disposable != null) {
disposable.dispose();
}
}
}다음으로 Elasticsearch Service에 로그 데이터를 전송하기 위한 컴포넌트를 추가합니다.
@Slf4j
@Component
public class EsControllerLogProcessor {
private final Flux<ControllerLog> controllerLogFlux;
private final EsLogSender esLogSender;
private Disposable disposable;
public EsControllerLogProcessor(Flux<ControllerLog> EsLogSender esLogSender) {
this.controllerLogFlux = controllerLogFlux;
this.esLogSender = esLogSender;
}
@PostConstruct
public void init() {
disposable = logFlux.bufferTimeout(1000, Duration.ofSeconds(30), Schedulers.elastic())
.filter(it -> !CollectionUtils.isEmpty(it))
.subscribe(esLogSender::send);
}
@PreDestroy
public void destroy() {
if (disposable != null) {
disposable.dispose();
}
}
}발행된 로그를 Elasticsearch Service로 전송하는 것은 비용이 큰 작업입니다.
그래서 한 건씩 전송한다기보다는 여러 건의 로그를 묶어서 전송하는 게 효율적입니다.
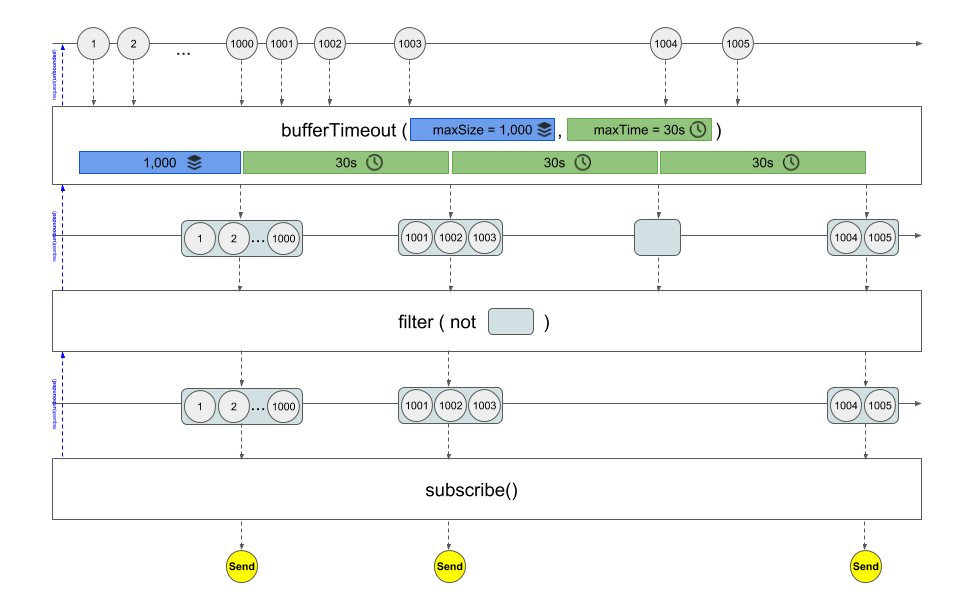
가장 먼저 보이는 bufferTimeout()은 30초마다 또는 1,000개의 로그가 모일 때마다 로그를 하나의 리스트로 묶어서 발행하는 Flux를 반환하여 줍니다.
30초 동안 발행되는 로그가 한 건도 없다면 빈 리스트가 반환될 텐데 이것은 filter()를 통해서 걸러줍니다.
마블 다이어그램으로 그린다면 아래와 같습니다.
@Slf4j
@Component
public class EsLogSender {
public static final DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("yyyyMMdd");
private final RestHighLevelClient client;
private final ObjectMapper mapper;
public EsLogSender(RestHighLevelClient client, ObjectMapper mapper) {
this.client = client;
this.mapper = mapper;
}
public void send(List<ControllerLog> list) {
try {
String indexName = "controller-log-" + LocalDate.now().format(FORMATTER);
BulkRequest request = new BulkRequest();
for (ControllerLog each : list) {
request.add(new IndexRequest(indexName, "doc").source(mapper.writeValueAsBytes(each), XContentType.JSON));
}
client.bulkAsync(request, RequestOptions.DEFAULT, new ActionListener<BulkResponse>() {
@Override
public void onResponse(BulkResponse response) {
log.debug("Send to logs to ES.");
}
@Override
public void onFailure(Exception e) {
log.warn("Exception in send to logs to ES.", e);
}
});
} catch (Exception e) {
log.warn("Exception in send to logs to ES.", e);
}
}
}이 부분은 payload를 생성하고 Elasticsearch Service에 전송하는 부분입니다.
활용하기 편리한 RestHighLevelClient를 사용해서 구현해봤습니다.
이제 스프링 애플리케이션이 수행되는 동안에 발생하는 ControllerLog들은 Elasticsearch Service로 전송되게 되고, Kibana 에서 결과를 확인해보실 수 있습니다.
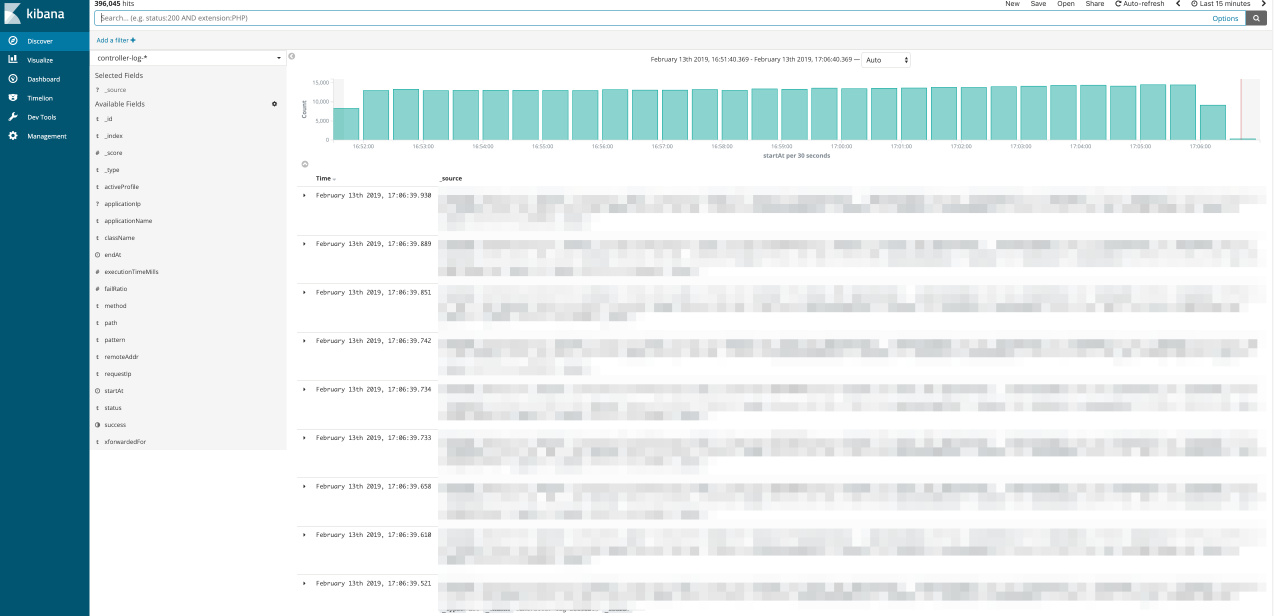
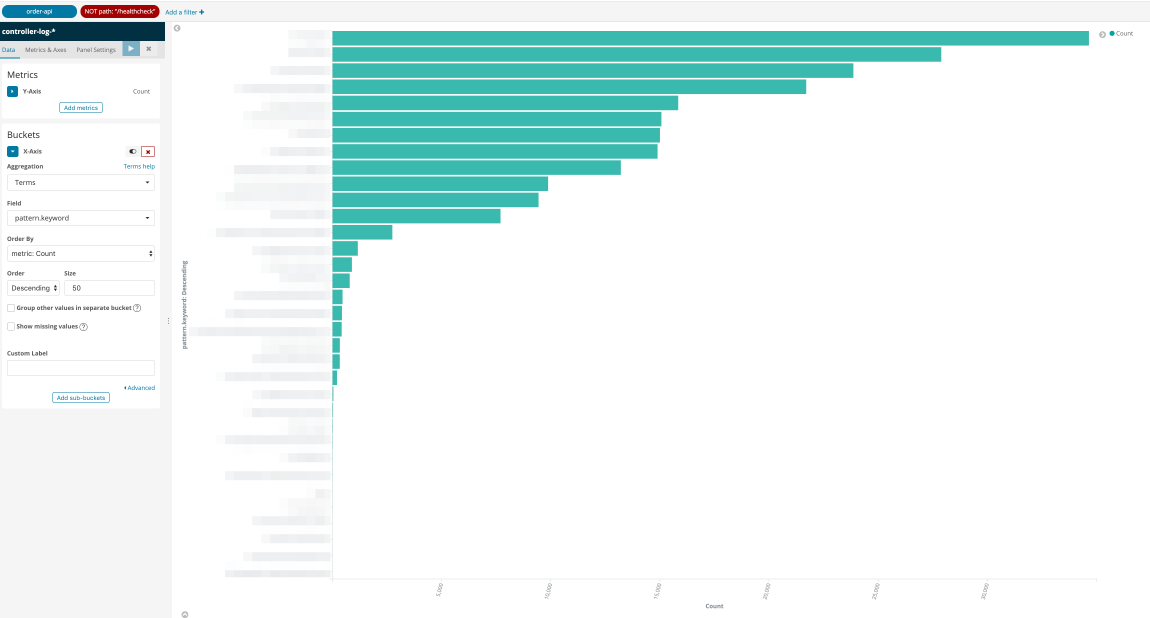
사용하지 않는 API 찾아보기
이제는 Elasticsearch Service를 사용하여 호출이 단 한 번도 발생하지 않는 API를 찾아볼 수 있습니다.
간단하게 아래와 같은 테스트코드를 사용하여 사용하지 않는 API 들을 찾아낼 수 있었습니다.
@Slf4j
public class ApiCountTest extends SpringTestContext {
@Autowired
List<RequestMappingHandlerMapping> handlerMappings;
@Autowired
RestHighLevelClient client;
@Test
public void test() {
handlerMappings.stream()
.flatMap(it -> it.getHandlerMethods().keySet().stream())
.forEach(this::print);
}
private void print(RequestMappingInfo requestMappingInfo) {
for (RequestMethod method : requestMappingInfo.getMethodsCondition().getMethods()) {
for (String pattern : requestMappingInfo.getPatternsCondition().getPatterns()) {
long count = getCount(method.name(), pattern);
if (count > 0) {
log.info("method=, pattern=, count=", method, pattern, count);
} else {
log.warn("method=, pattern= is not occurred.", method, pattern);
}
}
}
}
private long getCount(String method, String pattern) {
CountRequest countRequest = new CountRequest();
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder bool = QueryBuilders.boolQuery();
List<QueryBuilder> must = bool.must();
must.add(QueryBuilders.matchQuery("httpMethod.keyword", method));
must.add(QueryBuilders.matchQuery("urlPattern.keyword", pattern));
searchSourceBuilder.query(bool);
countRequest.source(searchSourceBuilder);
countRequest.indices("controller-log-*");
try {
return client.count(countRequest, RequestOptions.DEFAULT).getCount();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}RequestMappingHandlerMapping에 정의된 모든 RequestMappingInfo 정보를 뽑아내어 Elasticsearch Service에서 질의하여 호출 수를 뽑아내 보았습니다.
2019-02-13 17 is not occurred. // 이것이 한번도 호출되지 않은 API
2019-02-13 17:25:41 INFO [main] ApiCountTest : method=POST, pattern=/v1/orders, count=13234
2019-02-13 17, count=249912
2019-02-13 17, count=8872115
...Warning으로 표시된 API가 한번도 호출되지 않은 API입니다.
결론
저희 팀에서 사용하지 않는 API를 찾아내기 위하여 진행했던 내용을 다시 한번 정리해보겠습니다.
먼저 API 호출 여부를 판단할 수 있는 커스텀한 정보가 필요하였고, 스프링의 HandlerMapping 에서 제공한 속성정보를 사용하여 로그 데이터를 생성하였습니다.
이렇게 생성된 로그 데이터들은 Elasticsearch Service에 전송되어, 쿼리질의를 통해 쉽게 사용하지 않는 API 데이터를 찾아낼 수 있었습니다.
그리고 Elasticsearch Service와 연동하는 부분에서 Reactor를 사용하여 여러 건의 로그 데이터를 모아서 효율적으로 전송하도록 하였습니다.
어떻게 보면 사용하지 않는 API를 찾는다는 목적에 비해서 매우 많은 번거로운 작업이 들어가게 되었는데요.
사실은 저희는 위에서 이야기한 거보다 좀 더 상세하고 많은 정보를 ControllerLog에 담아서 다양한 용도로 활용을 할 계획입니다.
(API 별 평균 수행 시간을 측정한다거나, 오류수를 측정할 수 있겠네요.)
여기까지 읽어주셔서 진심으로 감사드립니다.
150여 개의 API 중 몇 개가 삭제 대상인지는 비밀입니다. 부끄부끄 ㅎㅎ
끗~
참고자료
- RequestMappingHandlerMapping
- HandlerMapping.BEST_MATCHING_PATTERN_ATTRIBUTE
- HandlerInterceptorAdapter
- Elasticsearch Java High Level REST Client
- Flux
- EmitterProcessor
