주소검색서버(woowahan-juso) 개발기(上)

부제: SpringBoot Batch를 이용하여 주소DB 구축하기
안녕하세요 라이더스개발팀 정세빈 입니다 🙂
BROS(Baemin Riders Operating System)에 주소검색을 위한 주소검색서버 개발 및 배포 경험을 공유 드리려고 합니다.
BROS는 배민라이더스의 주문 건을 배달하기 위한 라이더 운영 시스템입니다.
라이더 분들이 배달할 때 픽업지 혹은 배달지의 위치가 굉장히 중요합니다.
해당 위치의 변경 및 확인을 위한 주소 검색서버가 필요했고, 여러 솔루션 중 직접 DB에 데이터를 쌓고 서버를 배포하는 것을 택하게 되었습니다.
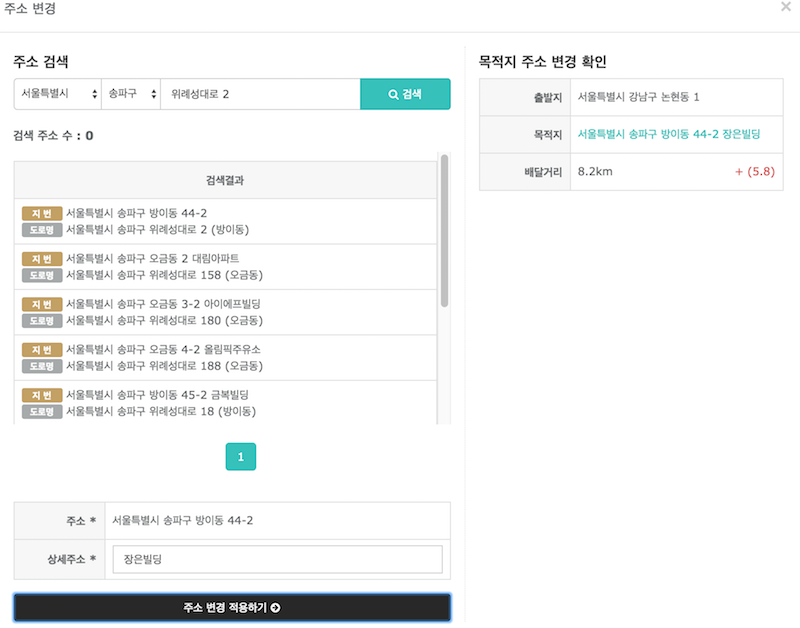
[주소 검색 및 변경 화면]
위 화면처럼 주소 검색을 위한 서버가 (여러가지 이유로) 필요했었습니다. 그래서 저희는 SpringBoot Batch, Amazon CloudSearch, JPA등을 이용하여 woowahan-juso라는 주소검색 서버를 배포하였습니다.
사내에도 잘 모르시는 분들을 위해 공유 겸, 해당 서버를 구성하는 것들에 대한 개발 경험을 나눠 볼려고 합니다.
음… 서버 구성 전체에 대한 얘기?
는 아닙니다.
주소 검색서버(woowahan-juso) 개발에 쓰인 서버 스펙 중, 이번 글에서는 SpringBoot Batch를 이용하여 주소DB를 재구축한 부분에 대해서 포스팅하려고 합니다.
그리고 SpringBoot Batch의 설정 및 사용방법 등 기술적 부분보다는 주소 데이터를 어떤식으로 다뤘는지, 왜 그렇게 했는지 등 경험을 중점적으로 다뤄 볼 예정입니다.
(기술적인 부분은 역시 Reference Doc이죠)
유심히(?) 보신 분들은 봤겠지만, 이번 글의 타이틀에 (上)을 붙였습니다. (下)에서는 재구축한 주소 DB를 이용하여 Amazon CloudSearch 서비스를 사용한 부분을 포스팅할 예정입니다. (Feat. 빅픽쳐)
시작에 앞서
왜 이미 있는 주소 서비스를 사용하지 않고 DB를 새로 작업한건지, 왜 일반적인 batch 프로세스를 개발하지 않고 spring batch를 이용했는지에 대한 자체 Q&A를 진행해봤습니다.
왜 주소DB를 따로 구축했나요
www.juso.go.kr 에 가면 주소검색 솔루션과 주소검색 API 그리고 txt형식의 주소 데이터를 제공해줍니다. 그중에서 몇 가지 이유로 txt형식의 주소데이터를 택해 새로운 주소DB를 구축했습니다.
-
최신 주소 데이터 자동동기화의 불필요
주소검색 API는 데이터를 정부에서 관리하고, 주소검색 솔루션은 주소 업데이트를 일정 기간 이상 하지 않으면 서비스가 중단되는 특징이 있습니다.
BROS의 주소 현황과 배민의 주소 현황의 싱크를 유지해야하기 때문에, 늘 최신데이터를 업데이트 해야 하는 주소 서비스를 이용할 수 없었습니다.
-
테스트용 주소에 대한 처리
상시 운영상황에서의 테스트를 위한 주소가 존재하는데, 해당 주소를 DB차원에서 관리하려면 불가피하게 DB를 재구축해야 했습니다.
-
SLA(Service Level Agreement) 미보장
만약 서비스의 운영환경에서 주소검색이 안되면 서비스의 에러상황으로 이어지게 됩니다. 하지만 www.juso.go.kr 에서 제공하는 서비스는 SLA에 대해서 보장해주지 않습니다. 이벤트 트래픽 혹은 갑작스런 장애상황 등에 SLA가 보장되지 않는 서비스가 껴있는건 서버 운영측면에서 리스크를 안고 가게 됩니다.
그래서 트래픽 대응, 장애대응 등 직접적으로 운영, 관리할 수 있는 주소 서버가 필요했습니다.
왜 Spring Batch를 사용했나요
Spring Batch의 특징은 굉장히 많지만 그 중에서도 주소 데이터를 넣는 Batch Job을 실행할 때 얻을 수 있던 장점에 대해 써보겠습니다.
-
실패 시점부터 재시작 가능
주소 txt파일을 읽어 주소데이터를 넣을 때 예상치 못한 에러로 Batch Job이 중 될 수도 있습니다.
파일 라인중 특정 컬럼이 비어있어서 NPE가 날 수도 있으며, 예상과 달리 Unique특성이 깨지는 데이터가 있어서 SQL예외가 발생할 수도 있습니다.
여러 데이터가 들어있는 주소txt파일은 전체로 보면 2천만이 넘는 row를 가지고 있습니다. 이런 많은 데이터를 전체적으로 valid체크하는 것도 어려움이 있고 valid하지 않다고 해서 필요없는 데이터라고 판단할 수도 없습니다. 또 실패했다고 처음부터 다시 job을 실행하기엔 데이터양이 많아 비효율적인 작업이 됩니다.
Spring Batch를 통해 Application을 실행하면 BATCH_JOB_EXECUTION_CONTEXT, BATCH_STEP_EXECUTION_CONTEXT 라는 테이블이 생성되고, 이 테이블에는 특정 Job or Step의 실행을 지속할 수 있게하는 데이터가 업데이트 됩니다. 이를 통해 중간에 batch job이 중단되더라도 문제파악 후 실패시점부터 다시 실행할 수 있었고, 더불어 위의 문제점들을 해결 할 수 있었습니다.
-
기본적인 ItemReader, ItemWriter interface 및 구현체 제공
Spring Batch에서는 여러 형태의 데이터들(DB, 플랫파일)을 하나의 인터페이스(ItemReader, ItemWriter)로 Step을 구현할 수 있게 제공해줍니다. 그럼으로서 여러 형태의 데이터에 대한 직접적인 대응을 줄일 수 있었고, 교육 비용도 줄일 수 있었습니다.
이 외에도 Batch Process를 처리할 때 Spring Batch의 기능, 특징으로 얻을 수 있는 장점이 많기 때문에 선택했습니다.
이제 주소 Batch Job을 만들어 보…기 전에
Spring Batch에 대해서 모르시는 분들께 해당 글 이해를 위한 작업 실행구조를 간단히 설명하고 시작하겠습니다
(이미 아시는 분들은 넘어가셔도 좋지만, 피드백은 언제나 감사합니다 🙂

-
JobRepository: 현재 실행 중인 프로세스의 meta data를 저장합니다.
-
JobLauncher: Client로부터 요청을 받아 Job을 실행하는 객체입니다.
-
Job: Step들의 컨테이너, Step들의 단계 혹은 재시작 가능성과 같은 모든 단계에 대한 전역 속성을 구성합니다.
-
Step: 실제 batch처리를 정의, 제어하는 정보가 들어있는 도메인 객체입니다.
-
ItemReader: 한 Step안에서 FlatFile, XML, DB 등 여러 input에서 Item을 읽어 들입니다.
-
ItemProcessor: ItemReader로부터 읽어들인 Item을 DB에 Write하기 전에 필요한 로직을 처리를합니다.
-
ItemWriter: ItemReader로부터 읽어 들인 Item을 Insert, Update 처리합니다.
Spring Batch는 크게 위의 구조를 통해 동작합니다. 더 자세하게는 위 구조를 동작하기 위한 여러가지 설정과 DB, Object 등이 있지만, 이번 포스팅에서 다루기엔 너무 많고 어렵기 때문에 링크만 공유드립니다.(회피)
이 구조를 주소 Batch Job에 적용해보면
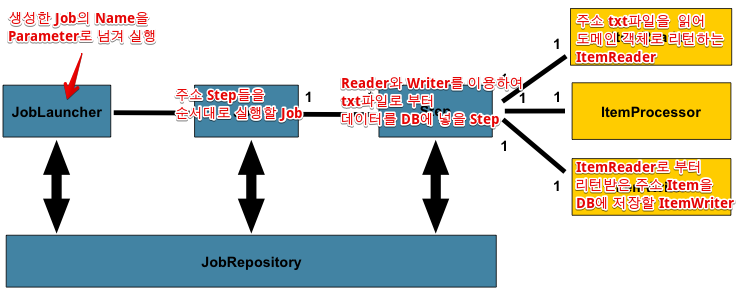
-
각 데이터 별(주소, 지번, 부가, 도로명) 주소데이터 txt파일을 읽는 ItemReader, 주소DB에서 시도, 시군구 등 데이터를 읽는 ItemReader 구현합니다.
-
ItemReader로 읽은 Item(도메인객체)들을 새로운 주소DB에 Insert할 ItemWriter를 구현합니다.
-
ItemReader와 ItemWriter, 필요에 따라서는 ItemProcessor를 추가하여 데이터별 Step을 구현합니다.
-
각 Step들을 플로우에 맞게 실행할 Job을 생성하고
-
해당 Job name을 parameter로 JobLauncher에게 실행요청을 합니다.
그래서 주소 Batch Job은 이렇게 만들었습니다.
위에서 간단하게 설명한 실행 구조들을 실제로 어떻게 구현했고 사용했는지에 대해 코드와 함께 설명드리려고 합니다.
코드는 Java이고 실제 프로젝트의 코드가 아닌 포스팅용으로 수정한 코드임을 알려드립니다.
1. 주소 txt파일을 라인단위로 읽는 ItemReader 구현
우선 txt파일을 read해서 도메인 객체를 리턴할 ItemReader를 구현해야 합니다.
@Bean
public FlatFileItemReader<Juso> jusoItemReader() {
FlatFileItemReader<Juso> reader = new FlatFileItemReader<>();
reader.setEncoding(CP949); // 주소 txt파일 한글인코딩
reader.setLineMapper(new DefaultLineMapper<Juso>() {{
setLineTokenizer(new DelimitedLineTokenizer("|") {{
setNames(new String[]{
"id",
"jusoName",
"jusoCol1",
"jusoCol2"
});
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper<Juso>() {{
setTargetType(Juso.class);
}});
}});
return reader;
}우선 FlatFileItemReader를 이용하여 FlatFile(.txt)을 읽는 ItemReader Bean을 생성했습니다.
플랫파일을 라인단위로 읽은 후, LineTokenizer와 FileSetMapper를 이용하여 read한 각 라인을 도메인객체로 리턴받게 구현하였습니다.
2. read한 Item(도메인객체)을 DB에 저장할 ItemWriter 구현
앞 단계에서 ItemReader를 이용해 txt파일로부터 Item을 읽은 후, 원하는 DB Table에 저장할 ItemWriter를 구현해야 합니다.
@Bean
public JdbcBatchItemWriter<Juso> jusoItemWriter() {
JdbcBatchItemWriter<Juso> writer = new JdbcBatchItemWriter<>();
writer.setAssertUpdates(false);
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
writer.setJdbcTemplate(new NamedParameterJdbcTemplate(dataSource));
writer.setSql("INSERT INTO `juso_info`n" +
"(`id`,n" +
"`juso_name`,n" +
"`juso_col1`,n" +
"`juso_col2`)n" +
"VALUESn" +
"(:id,n" +
":jusoName,n" +
":jusoCol1,n" +
":jusoCol2)"); // Item을 read할 때 mapping해준 named paramter로 set value
return writer;
}JdbcBatchItemWriter를 이용하여 Jdbc모듈 형식으로 mysql에 접근하였습니다. 그 중 NamedParameterJdbcTemplate을 이용하여 read한 Item (도메인객체)을 namedParameter로 가져와 insert할 value를 셋팅했습니다.
3. ItemReader와 ItemWriter를 이용하여 여러 데이터의 Step 구현
앞서 구현한 ItemReader와 ItemWriter를 통해 원하는 데이터를 read, write할 Step을 구현해야 합니다.
@Bean
public Step jusoStep() {
return stepBuilderFactory.get("jusoStep")
.<Juso, Juso>chunk(CHUNK_SIZE)
.reader(new MultiResourceItemReader<Juso>() {{
setResources(resources);
setDelegate(jusoItemReader());
}})
.writer(jusoItemWriter())
.build();
}각 데이터에 맞는 도메인 객체와, txt파일을 Resource객체로 변환 후 set했습니다.
step에는 chunk size를 지정해 줄 수 있습니다. chunk size 만큼 ItemReader와 ItemWriter가 동작하여, 원하는 단위로 트랜잭션 커밋을 할 수 있습니다.
4. 주소DB에서 시도, 시군구, 행정동을 뽑아 저장하는 Step 구현
주소 txt파일을 읽어 저장한 주소DB에는 약 800만개의 지번정보와 약 35만개의 도로명정보, 기타 부가정보들이 있습니다.
해당 파일에는 시도, 시군구, 행정동에 대한 정보를 따로 제공해주지 않아 전체 주소 정보로 부터 추출해야 합니다.
앞서 구현한 것들과 달리, 이 Step은 DB로 부터 read와 write를 합니다.
public <T> Step createStep(String stepName, int chunkSize, String readSql, RowMapper<T> readRowMapper) {
return stepBuilderFactory.get(stepName)
.<T, T>chunk(chunkSize)
.reader(new JdbcCursorItemReader<T>() {{
setDataSource(dataSource);
setSql(readSql);
setRowMapper(readRowMapper);
}})
.writer(new JpaItemWriter<T>() {{
setEntityManagerFactory(entityManagerFactory);
}}).build();
}read, write과정이 앞 단계보다 간단해서 generic type을 이용하여 각 Step들을 구현했습니다.
각 데이터에 맞는 read sql, rowMapper를 parameter로 받아 JdbcCursorItemReader를 사용하였고, JPA Entity 객체를 통해 write하는 JpaItemWriter를 사용하였습니다.
5. 각 Step들의 순서를 지정할 Job 생성
이제 구현한 Step들을 Job단위로 묶어 원하는 순서대로 실행할 Job을 만들어야 합니다.
@Bean
public Job initDataJob() throws IOException {
return jobBuilderFactory.get("initDataJob")
.incrementer(new RunIdIncrementer())
.start(batchConfiguration.jusoStep0())
.next(batchConfiguration.jusoStep1())
.next(batchConfiguration.jusoStep2())
.next(batchConfiguration.initSidoStep())
.next(batchConfiguration.initSigunguStep())
.next(batchConfiguration.initDongOfAdminStep())
.build();
}Sido, Sigungu, DongOfAdmin Step들은 4.에서 구현한 createStep method를 통해 만든 Step입니다.
jusoStep을 먼저 실행하여 주소txt 파일로부터 DB에 데이터를 쌓고, 그 후에 시도, 시군구 등의 데이터를 다시 주소DB로 부터 추출해야 합니다.
그래서 Job을 생성하고 start, next로 Step을 실행하였고, Job이 Step의 순서를 보장해 주어서 원하는 동작을 할 수 있었습니다.
6. JobName을 이용하여 Job 실행
Application 실행 시 -Dspring.batch.job.names=jobName 으로 원하는 jobName을 넣어주면 JobLauncher가 parameter를 받아 해당 job을 실행하고, 원하는 주소 데이터들을 주소DB에 쌓을 수 있습니다.
마무리_final
현재 운영중인 서버는 위 구현 과정을 통해 Job을 만들고 실행하여 원하는 주소 DB를 만들고 잘 사용중입니다. (다행이다)
주소 검색서버의 목표는 www.juso.go.kr 메인의 검색 기능을 구현하는 것이었습니다. 해당 기능을 구현하기 위해 Amazon CloudSearch 서비스를 선택하였고, 그 부분을 다음 포스팅에 적어 볼 예정입니다.
마무리_real_final
이렇게 개발했던 경험을 블로그로 포스팅한 건 이번이 처음입니다.
역시 글을 쓰는 건 (정말)힘들고 (너무)어려웠지만 덕분에 다시 Spring Batch에 대해서 더 깊게 공부할 시간을 가져서 좋았습니다.
더불어 이 주소서버 개발을 할 때 처음으로 Spring Batch를 공부하며 진행했었는데, 이렇게 doc문서를 더 자세히 보면서 이전 코드를 보니 코드리뷰도 된 것 같아서 더 좋은 경험이 되었습니다.
글을 마무리 지으려니 어떻게 지어야 할지 잘 모르겠네요.
그래서 급 마무리 인사드립니다.
이렇게 누추한 글에 귀한 분들께서 읽어주셔서 감사합니다
다음 포스팅에서 Amazon CloudSearch와 함께 돌아오겠습니다.
다음 화 예고편

[cause you are my girl~]