쿠버네티스를 이용해 테스팅 환경 구현해보기
실제로 서비스에 도입해보기 전에 쿠버네티스를 유용하게 사용해 볼 수 있는 방법 중에 하나가 아닐까.
시작하며
이 글은 앞으로 우리가 관리하는 서비스(배민찬)의 아키텍처가 컨테이너 기반의 마이크로 서비스를 지향할 것으로 결정한 후 이를 위해 우선 아키텍처를 테스팅 환경으로 구현하여 실제로 서비스에 도입하기 전에 충분한 기간을 가지고 사용경험을 쌓는 것을 목적으로 쿠버네티스로 테스팅 환경을 구축하면서 겪었던 여러 상황들을 정리해본 글이다. 쿠버네티스의 구조와 그 리소스(Pod, Service, Deployment, ETC…)등은 그것만으로도 책 한 권은 가벼운 주제라 생각되니 그에 대한 설명을 할 수는 없지만 전체적인 테스팅 환경의 구조와 작업을 진행하면서 막혔던 부분, 주의해야 했던 부분을 짤막하게 언급하는 식으로 작성하였다.
테스팅 환경을 클러스터에 구현하기
AWS 환경에 쿠버네티스 클러스터(이하 클러스터) 올리기
일단 쿠버네티스 리소스를 올리려면 클러스터를 만들어야 한다. AWS에서 클러스터를 구축을 하는 데에는 kops를 사용하였다. 공식 사이트의 가이드에도 AWS에서 클러스터를 올리는 방법 중 하나로 설명이 되어있으며 비교적 손쉽게 클러스터를 생성할 수 있기 때문이다. kops가 요구하는 AWS 권한을 가진 계정으로 awscli를 사용할 수 있는 상황이라면 가이드를 따라서 손쉽게 클러스터를 만들어낼 수 있다. 생성할 클러스터의 구조는 다음과 같다.
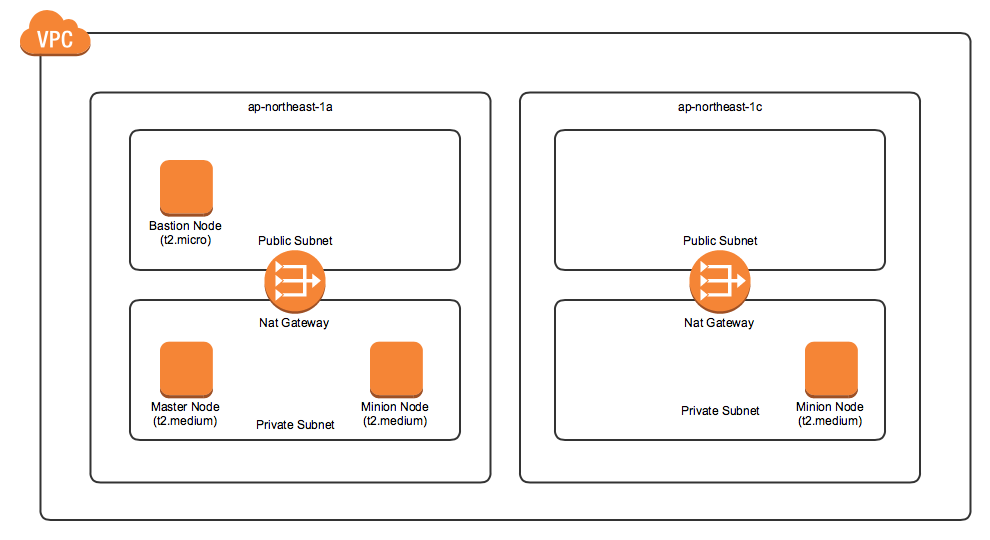
시작은 작은 규모로 t2.medium 마스터 1대, 미니언 2대로 구성하도록 하였다. 마스터 노드의 수는 Raft 알고리즘의 특성상 홀수로 유지하는 것이 좋은데 두 개의 마스터노드는 한 개만 못한 결과를 초래할 수 있기 때문이다(둘 중 하나만 다운돼도 둘 다 다운되는 효과가 나오는 기적). 마스터, 미니언 노드는 private 서브넷에 생성되며 private 서브넷에 있는 노드(EC2 인스턴스)에 접속하려면 Bastion 노드를 통해야 한다. 위의 구조를 가지는 클러스터를 생성하는 명령어는 다음과 같다. 자세한 파라미터 목록은 kops create cluster 문서를 참조하자.
kops create cluster
--cloud aws
--name
--state s3
--topology private
--zones ap-northeast-2a,ap-northeast-2c
--master-zones ap-northeast-2a
--networking calico
--bastion
--ssh-public-key
--node-count=2
--node-size=t2.medium
--master-size=t2.medium
--master-count=1
- 참고로 kops 가이드를 그대로 따라 할 경우 노드 사이즈에 대한 파라미터를 정의하지 않으므로 t2.large 타입과 같은 유료 인스턴스로 노드가 생성되어 요금이 부과될 것이다. 생성되는 인스턴스의 타입은 파라미터로 지정할 수 있으니
kops update cluster --yes명령어를 실행하기 전에 꼭 확인하기 바란다. 그리고 클러스터를 생성했다면 AWS에 생성된 인스턴스를 확인하여 회사든 개인이든 예산에 차질이 없도록 하는 게 좋을 것이다.- Public Subnet 에 바스티온 노드만 올라간다고 CIDR 범위를 좁게 잡으면 안 된다. 나중에 쿠버네티스의 로드밸런서 서비스(이하 로드밸런서, AWS의 ELB 는 ELB라고 표기하겠다.)를 만들때 Utility 타입의 서브넷(하단의 코드 블록에 있음)에서 사용 가능한 아이피의 수가 8개 이상이어야 ELB가 생성되어 로드밸런서가 올바르게 동작한다.
클러스터를 만드는 것은 가이드대로 하면 간단한 일이지만 클러스터를 생성하면 클러스터에 사용되는 VPC 가 생성되는데, 다른 VPC와의 피어링 등의 이슈가 있어 VPC와 서브넷의 CIDR 값을 수동으로 지정해야 한다면 kops update cluster --yes 명령어를 사용하여 최종적으로 클러스터를 생성하기 전에 kops edit cluster 명령어를 사용하면 에디터가 열리고 VPC와 Subnet 의 CIDR을 수정할 수 있다. 이미 클러스터를 생성했는데 이를 변경해야 한다면 차라리 kops delete cluster 명령어로 클러스터 자체를 삭제하고 새로 만드는 게 더 빠르다.
networkCIDR: 10.xx.xx.xx/16. #VPC 의 CIDR
subnets:
- cidr: 10.xx.xx.xx/24
name: ap-northeast-2a
type: Private #Private 는 Private 서브넷을 의미한다.
zone: ap-northeast-2a
- cidr: 10.xx.xx.xx/24
name: ap-northeast-2c
type: Private
zone: ap-northeast-2c
- cidr: 10.xx.xx.xx/24
name: utility-ap-northeast-2a
type: Utility #Utility 는 Public Subnet 을 의미한다.
zone: ap-northeast-2a
- cidr: 10.xx.xx.xx/24
name: utility-ap-northeast-2c
type: Utility
zone: ap-northeast-2c수정 내역을 저장한 후 kops update cluster --yes 명령어를 사용하여 클러스터를 생성했다면 이제 Pod(이하 팟)에 사용할 도커 이미지를 준비한다.
도커 이미지 만들기
클러스터 환경이 준비되었다면 Pod에 사용될 도커 이미지를 만들어야 한다. 테스팅 환경을 구성하기 위해선 4개의 컨테이너가 필요했는데, 이 컨테이너들은 다음과 같은 관계를 지닌다.
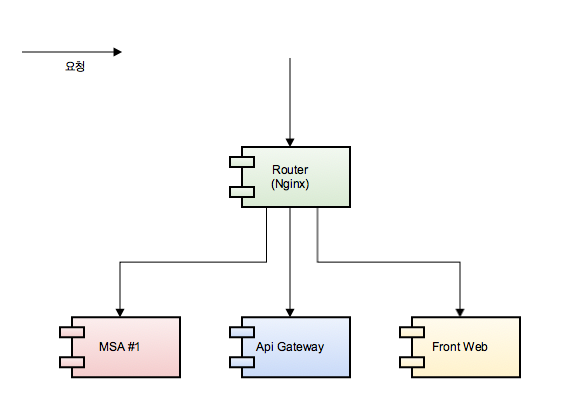
필자는 로컬에서 도커 이미지를 빌드하여 ECR 에 푸쉬한 후 클러스터에서 사용하였다. kops를 통해 AWS상에 클러스터를 만들었다면 동일한 계정의 ECR에 올린 도커 이미지는 별도의 imagePullSecret 이 없어도 가져다 쓸 수 있다.
- imagePullSecret 은 쿠버네티스에서 private docker registry 에 있는 도커 이미지를 사용하기 위한 토큰 같은 것이라고 생각하면 될 것 같다. 만약 AWS에 있는 클러스터에 올리기 전에 로컬에서 minikube 등을 이용하여 ECR 에 있는 이미지를 테스트하려면 imagePullSecret 을 설정하지 않고는 해당 이미지를 가져와 사용할 수 없다. ImagePullSecret 의 생성과 사용법은 이곳에서 확인할 수 있다.
- minikube 에서 테스트를 할 때는 minikube 에서 이미지를 빌드해버리면 된다. 본인은 minikube의 도커 이미지를 사용하려면 어딘가 접속 가능한 docker registry 에 이미지가 올라가 있어야 한다고 착각하였는데
minikube ssh명령어를 사용하면 minikube 머신에 접속할 수 있고, 접속하면 docker-machine 에 접속한 것과 유사함을 알 수 있다(실제로 별다른 설정 없이 설치하면 docker-machine 처럼 VirtualBox 에 minikube 머신이 추가된 것을 볼 수 있다.). Mac이라면 minikube에서/Users경로를 통해 로컬 파일 시스템에 접근할 수 있다.
쿠버네티스 리소스 만들기
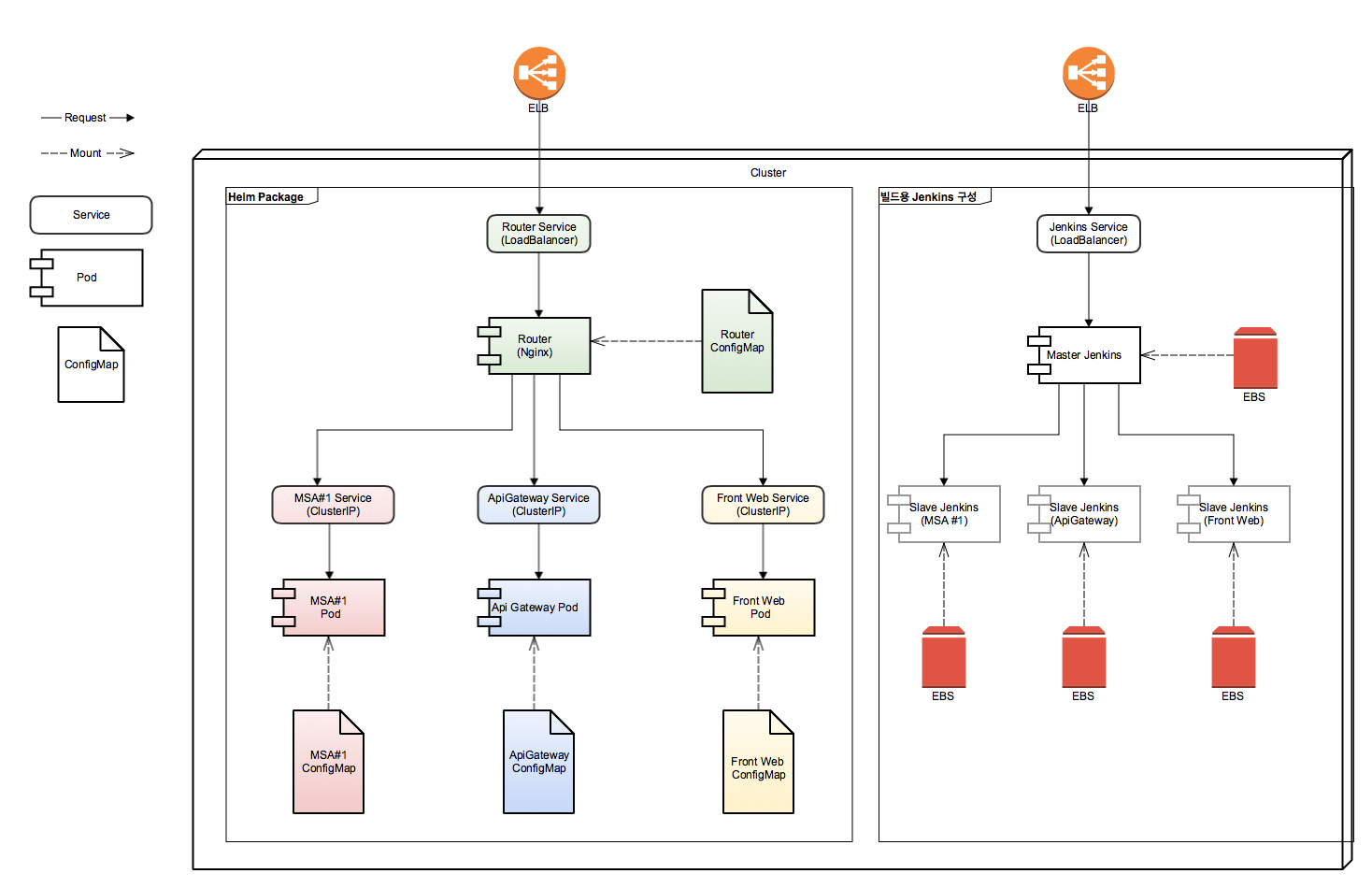
이미지가 준비되었다면 이제 쿠버네티스 리소스를 만든다. 다음과 같은 구조로 구현하였다. 참고로 그림에 있는 팟들은 전부 Deployment 리소스가 관리하고 있다고 생각하면 된다.
nginx 라우터 팟이 로드밸런서와 연결되어 있으며 ELB로부터 요청을 받아 각 서비스로 요청을 전달하도록 되어있는 테스팅 환경의 구조.
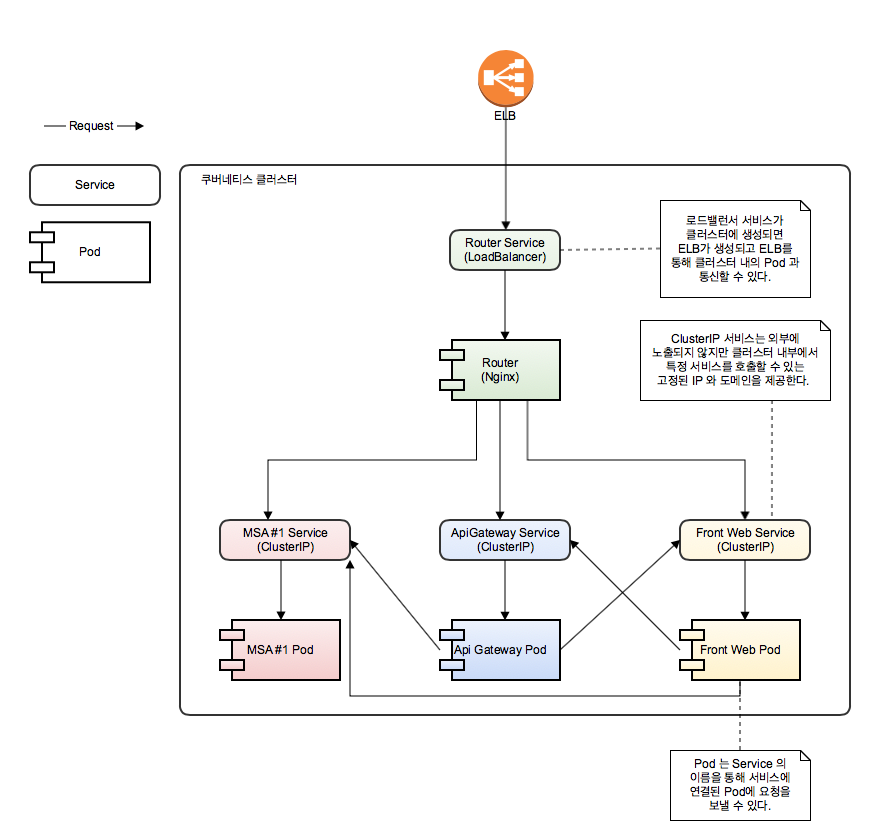
테스트를 구성하는 팟에는 한 개의 컨테이너만 배포되어있지만 팟에는 여러 개의 컨테이너를 한 번에 배포하여 사용할 수 있다. 나중에 젠킨스를 통한 빌드 작업에서 하나의 팟에 여러 컨테이너를 실행하여 사용하는 것을 볼 수 있을 것이다.
필자가 구현할 테스팅 환경은 https 프로토콜을 사용하기 위해 로드밸런서가 생성하는 ELB가 AWS ACM 인증서를 사용하도록 해야 했는데, 이것은 로드밸런서 설정에 다음 어노테이션을 추가하여 해결하였다. 해당 어노테이션을 추가하면 AWS 콘솔에서 ACM이 ELB에 사용되는 것을 확인할 수 있을 것이다.
...
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-ssl-cert: ACM의 ARN
service.beta.kubernetes.io/aws-load-balancer-ssl-ports: "443"테스팅 환경을 구성할 쿠버네티스 리소스의 yaml 설정 파일들이 파일이 준비되었다면 kubectrl create -f 명령어를 통해 쿠버네티스 리소스들을 클러스터에 모두 생성하고 테스트를 해 본다. 감사하게도 QA 팀 분들이 테스트를 해주셔서 테스팅 환경이 구현되었음을 확인할 수 있었다.
진정한 고난의 시작, 배포 자동화
이제 쿠버네티스 클러스터에 테스팅 환경이 올라갔다. 이제 이 테스팅 환경에서 테스트를 진행할 수 있을 것 같은데, 현재는 하나의 테스팅 환경을 올렸을 뿐이다. 그리고 현재는 테스팅 환경을 하나 만드는 것만 해도 다음과 같은 절차가 필요하다.
- 테스트를 하고자 하는 소스를 Git에서 체크아웃
- 빌드 (Java의 gradle, PHP의 Composer, node 이 npm 등등)
- 도커 이미지 빌드, 푸쉬
- 쿠버네티스 리소스 생성
만약 이것을 자동화하지 않으면 클러스터에 테스팅 환경을 매번 배포하는 것부터가 큰일이니 젠킨스를 사용하여 자동화를 해야 할 것 같다. 이 과정을 젠킨스에서 처리하면 다음과 같은 절차를 거치게 될 것이다.
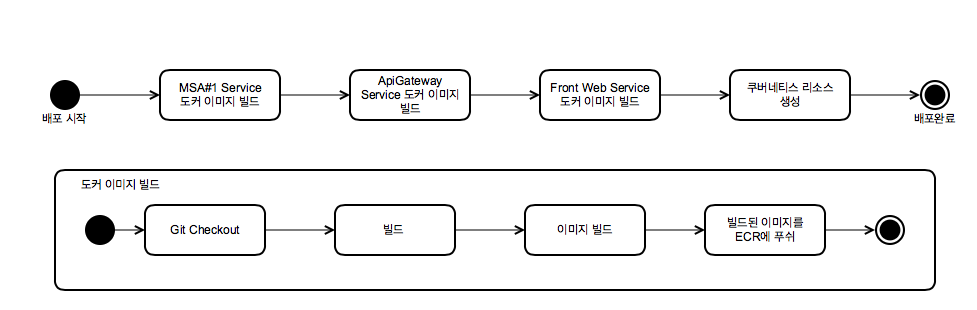
그런데 막상 배포 자동화를 하려고 하니 문제가 있었다. 여러 명이 각자의 테스팅 환경을 사용할 수 있도록 각 테스팅 환경은 alpha-cluster01~05-www.testdomain.com와 같은 서로 다른 도메인을 사용해야 했는데, 이를 위해서는 쿠버네티스 리소스와 함께 nginx 의 설정 파일, Java의 환경변수, PHP 설정 파일을 변경해야 했고 이를 젠킨스에서 처리하도록 하는 것은 매우 비효율적이었기 때문이다.
Helm 패키지 매니저
Helm은 쿠버네티스 패키지 매니저인데, helm 사용하면 클러스터에 Tiller라는 팟이 설치되고, 이 팟을 통해 Helm 패키지(이하 차트) 내부에 정의한 쿠버네티스 리소스들을 클러스터에 올릴 수 있다. 흥미로운 점은 Helm에서 템플릿 기능을 지원한다는 것이다. 이 템플릿 기능을 사용하여 도메인에 따라 설정을 변경해 줘야 하는 작업을 해결할 수 있었다.
Helm 템플릿 예시 – front web 서비스의 configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name}
data:
configuration.ini: |
pc_www = "https}-www.testdomain.com" # release의 값이 alpha-cluster01 일 경우 배포될 때 이 값은 https://alpha-cluster01-www.testdomain.com 로 치환된다.
mobile_www = "https}-m.testdomain.com"
cdn = "https://cdn-abc.co.kr"
login_action = "https}-www.testdomain.com/member/login.exe.php"
mobile_login_action = "https}-m.testdomain.com/member/login.exe.php"
rest_api = "https}-api.testdomain.com"
api_gateway = "https}-api.testdomain.com"
config.php: |
} # 이런식으로 패키지에 포함된 파일을 읽어서 컨피그 맵에 넣을 수도 있다.
} 은 helm을 사용하여 차트를 배포할 때 --name 파라미터로 지정한 값으로 치환되어 들어갈 것이다. (지정하지 않으면 도커 컨테이너처럼 임의의 자동으로 생성된 이름이 할당된다.) 그럼 이제 도메인의 변경이 필요한 파일들을 도커 이미지에 넣지 않고 ConfigMap(이하 컨피그맵)에 넣은 후에, 차트 배포 시 치환된 컨피그맵을 팟의 컨테이너에 파일로 마운트 하거나 환경변수로 설정한다
이때
--name으로 넘기는 파라미터는 생성된 테스팅 환경에 접속할 때 사용할 도메인의 접두사 (ex: alpha-cluster01~05)를 사용하는데 이는 alpha-cluster01-www.testdomain.com와 같은 도메인 설정을 동적으로 하고 차트를 통해 배포된 테스팅 환경에서 생성된 ClusterIP 서비스를 각 테스팅 환경끼리 구분하기 위해서 사용된다.
front web 서비스의 deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name}
spec:
replicas: 1
template:
metadata:
name}
labels:
app}
spec:
containers:
- image}}"
imagePullPolicy: Always
name: front-web
volumeMounts:
- name}
mountPath: /home/abc/def/configuration.ini
subPath: configuration.ini
readOnly: true
- name}
mountPath: /home/abc/def/config.php
subPath: config.php
readOnly: true
volumes:
- name}
configMap:
name}
그리고 helm에서는 차트의 의존성을 관리할 수 있는데, 이 기능을 사용하면 테스팅 환경에 필요한 각 서비스별로 차트를 일일이 배포하지 않고, 이들을 포함하는 하나의 임의의 패키지를 만들어 한번에 배포할 수 있다(사실 차트를 동일한 이름으로 중복해서 배포할 수 없으므로 테스팅 환경을 구성하는 서비스들의 차트들이 동일한 도메인을 사용하려면 하나의 차트로써 배포될 필요도 있었다). helm 차트로 구성한 테스팅 환경의 구조는 다음과 같다.
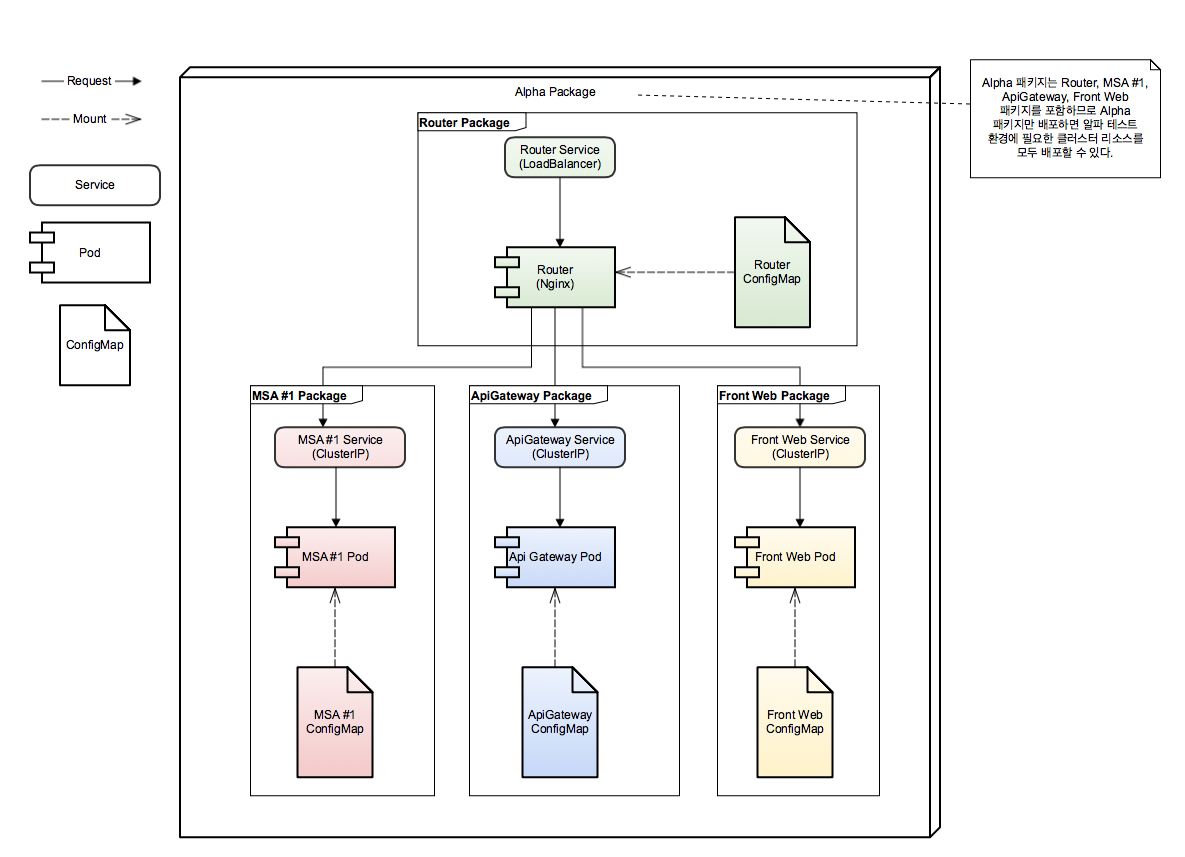
이제 helm install 명령어로 alpha 차트를 배포할 때 --name 에 설정한 도메인 접두사가 각 서비스의 컨피그맵에 치환되어 들어갈 것이다. 차트가 준비되었으면 helm install 명령어를 통해 클러스터에 차트를 배포하는 것이 가능하다. helm install 명령어에서는 템플릿에서 사용할 값을 파라미터로 넘겨줄 수도 있는데, 이 기능은 잠시 후에 jenkins 파이프라인 예시에서 helm 차트를 배포할 때 파이프라인을 통해 빌드된 도커 이미지의 태그를 제공하는 용도로 사용하였다.
helm 차트를 만듦으로써 테스팅 환경의 배포는 helm install 명령어 하나로 처리할 수 있게 되었고 도메인 변경에 따른 문제도 해결되었다. 그럼 이제 배포 자동화를 위해 젠킨스 파이프 라인을 구성해보도록 하겠다.
Helm 젠킨스 패키지
helm을 이용하면 helm 차트 저장소에 등록되어 있는 차트들을 내려받아 사용할 수 있는데 이중에는 젠킨스 차트도 있으며 이 차트는 이미 쿠버네티스 클러스터 관련 설정이 이미 되어있어 매우 유용하다. (쿠버네티스 젠킨스 플러그인이 이미 설치되어있고 해당 젠킨스 차트가 올라가있는 클러스터에 관한 설정이 이미 되어있는 상태), 그리고 설치되면서 자동으로 PersistentVolume(이하 PV) 리소스를 생성하여 젠킨스 관련 데이터를 영속적으로 저장하기 때문에 노드 자체가 날아가는 상황에서도 별도의 설정 없이 젠킨스의 데이터를 유지할 수 있는 장점이 있다.
젠킨스 차트를 클러스터에 배포했을 때의 구조
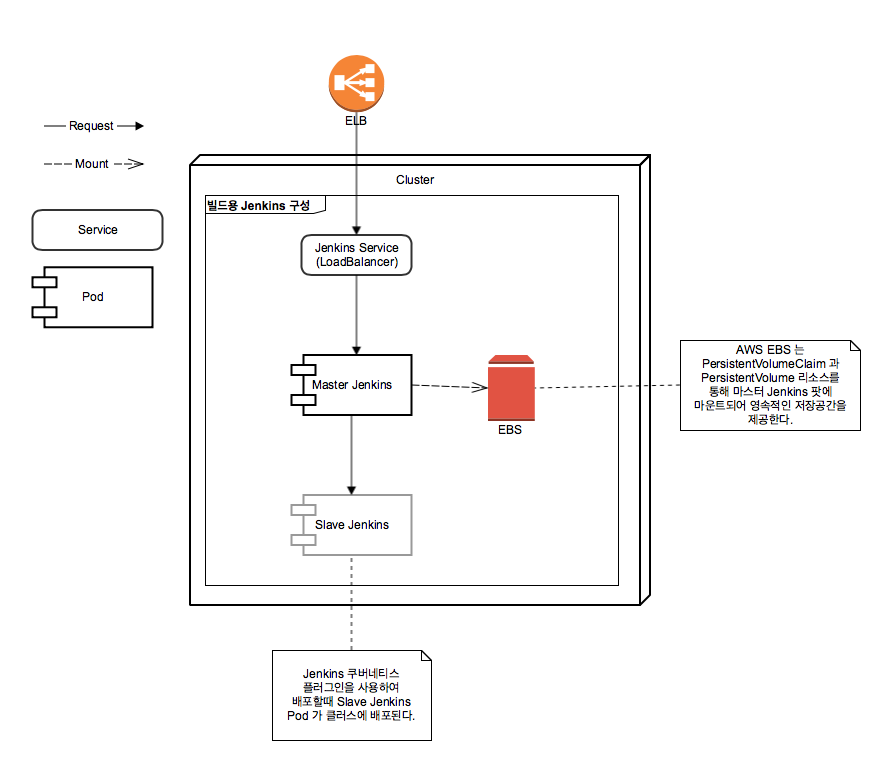
참고로 본인은 이 패키지의 존재를 모르고 오피셜 젠킨스 이미지를 사용하던 중 노드가 다운되는 일이 벌어졌는데 PV을 사용하지 않아 거의 다 완성한 파이프라인을 날려먹는 참사를 당하게 되었다. 별도로 PV를 마운트 하거나 hostPath를 마운트 한 경로에 데이터를 저장하지 않으면 팟의 삭제와 함께 모든 데이터가 날아가니 팟에서 만들어지는 소중한 데이터는 꼭 영속적인 저장소에 저장하도록 하자.
그리고 젠킨스의 쿠버네티스 플러그인은 젠킨스 슬레이브 팟을 클러스터에 배포하여 빌드를 지원하는데, 흥미롭게도 이 슬레이브 팟에는 여러 컨테이너를 추가할 수 있어 이를 빌드 과정에서 사용할 수 있다. 그렇다면 굳이 마스터 젠킨스에 빌드를 위한 기능을 설치하지 않고 빌드 전용 컨테이너를 만들어 빌드 작업 자체의 휴대성을 높일 수도 있을 것이다. 이는 php, composer, npm 등 빌드에 필요한 게 많았던 레거시 웹 서비스 빌드에 특히 유용했다.
프론트 웹 빌드용 젠킨스 슬레이브 팟
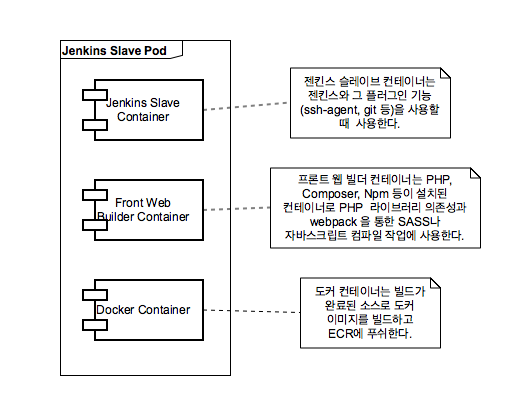
그리고 젠킨스 슬레이브 팟에서 kubectl, helm 컨테이너를 사용 시에는 별도의 설정 없이 클러스터를 사용할 수 있어 kubectl의 config 파일을 설정할 필요도 없어진다. 이제 이를 사용하는 파이프라인을 작성해보자.
프론트 웹을 빌드하는 파이프라인
def frontWebImage = "이미지 레포지토리"
def frontWebImageTag
node {
stage('Build And Push Front') {
if (frontWebImageTag == null) {
podTemplate(label: 'build-front-web'
containers: [
containerTemplate(name', ttyEnabled: true, command: 'cat', resourceLimitMemory: '768Mi'),
containerTemplate(name: 'docker', image: 'docker:17.11', ttyEnabled: true, command: 'cat', resourceLimitMemory: '64Mi'),
],
volumes: [
hostPathVolume(hostPath: '/var/run/docker.sock', mountPath: '/var/run/docker.sock')
]) {
node('build-frontWeb') {
stage('Build Front Image') {
sshagent (credentials: ['eng-fresh']) {
// 별도로 container 문을 사용하지 않으면 Jenkins 슬레이브 컨테이너에서 명령어가 실행된다.
git branch", credentialsId', url"
gitCommit = sh(returnStdout: true, script: 'git rev-parse HEAD').trim().take(8)
frontWebImageTag = "$-$"
ARTIFACT_ID = sh(returnStdout").trim()
PACKAGE = sh(returnStdout.tar.gz").trim()
container('front-web-builder') { // 레거시 웹 컨테이너에서 쉘을 실행한다.
sh "build/build.sh package $" //build.sh. 는 composer 와 nom 을 사용한다.
}
container('docker') { // 도커 컨테이너에서 쉘을 실행한다.
sh "docker build -t $ --build-arg PACKAGE=$ --build-arg ARTIFACT_ID=$ ."
}
}
}
stage("Push Front Image") {
container('docker') {
docker.withRegistry('', '') {
docker.image("$").push()
}
}
}
}
}
}
}
.
.
.
}다른 자바 서비스들도 마찬가지로 빌드 → 도커이미지 빌드 → 도커 이미지 푸쉬의 동일한 과정을 거친다. 필요한 도커 이미지를 모두 빌드하고 푸쉬했다면 helm 커맨드를 실행하며 helm 차트를 배포한다.
node {
.
. //도커 이미지 빌드 & 푸쉬
.
stage ("Helm Deploy") {
podTemplate(label: 'helm'
containers: [
containerTemplate(name: 'helm', image: 'lachlanevenson/k8s-helm:latest', ttyEnabled: true, command: 'cat')
]) {
node('helm') {
stage("Deploy Alpha") {
git branch', url'
container('helm') {
sh "helm init" //helm init 명령어는 클러스터에 Tiller 를 배포하면서 로컬환경에서 사용하는 차트 저장소를 만든다.
sh "helm package helm/alpha/router" # 패키징 된 차트는 로컬 차트 저장소에 저장된다.
sh "helm package helm/alpha/front-web"
sh "helm package helm/alpha/msa1"
sh "helm package helm/alpha/api-gateway"
sh "helm dependency update helm/alpha/alpha" #의존하는 모든 패키지를 가져와 알파 패키지에 추가한다. 위에서 패키징한 차트는 로컬 저장소에 저장되어 있어 가져올 수 있다.
sh "helm install --debug --name $ --namespace default --set front-web.frontWebTag=$ --set msa1.msa1ImageTag=$ --set api-gateway.apiGatewayImageTag=$ helm/alpha/alpha"
// 도커 이미지의 태그 값은 중복되지 않도록 git commit ID 와 Jenkins 빌드 넘버의 조합이다. 이 값은 helm install 명령에 파라미터로써 제공되어 젠킨스 파이프라인에서 빌드한 이미지를 팟에서 사용하는것이 가능하게 해준다.
// $ 깂은 빌드할 때 설정하는 값으로 alpha-cluster01~05 의 값중에 하나를 사용한다.
}
}
}
}
}
}빌드를 실행했는데 빌드가 계속 대기 중이고 시작되지 않는다면 젠킨스 설정에서 Executor 설정을 확인하자. 필자의 경우 젠킨스 차트를 통해 설치 했을 때 기본값이 0으로 저장되어 있어 영문도 모르고 한동안 기약 없는 대기를 타야 했다.
차트 배포 결과
$ helm ls
NAME REVISION UPDATED STATUS CHART NAMESPACE
alpha-cluster01 1 Sat DEC 9 14:36:53 2017 DEPLOYED alpha-1.0.0 default
jenkins 1 Thu Dec 14 15:29:29 2017 DEPLOYED jenkins-0.10.1 jenkins
$ kubectl get po
NAME READY STATUS RESTARTS AGE
alpha-cluster01-api-gateway-4117715186-f23mv 1/1 Running 0 1m
alpha-cluster01-front-web-1457034248-qvnsr 1/1 Running 0 1m
alpha-cluster01-msa1-3928334195-11092 1/1 Running 0 1m
alpha-cluster01-router-1217976428-8xp7g 1/1 Running 0 1m
//--name alpha-cluster01 값으로 설치된 차트의 서비스들은 alpha-cluster01 접두사를 가지게 되어 다른 테스팅 환경의 서비스와 간편하게 구분되고 사용될 수 있다.
$ kubectl get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alpha-cluster01-api-gateway 100.68.48.102 <none> 80/TCP 1m
alpha-cluster01-api-proxy 100.64.121.224 <none> 80/TCP,443/TCP 1m
alpha-cluster01-front-web 100.66.0.18 <none> 80/TCP,443/TCP 1m
alpha-cluster01-msa1 100.68.79.194 <none> 80/TCP 1m
alpha-cluster01-router 100.66.130.177 <none> 80/TCP,443/TCP 1m이것으로 배포 과정이 자동화되었다. 이제 차트가 배포되었을 때 생성된 Router 로드밸런서의 ELB에 Route53을 통해 도메인을 연결해주기만 하면 테스팅 환경을 사용할 수 있게 되었다. 그럼 이제 클러스터가 기존의 5개의 테스팅 환경(기존에 테스팅 환경을 5개까지 사용했으므로)을 감당해낼 수 있는지 확인해보자.
노드의 리소스 사용량 관리
안타깝게도 다수의 테스팅 환경을 배포하는 과정에서 미니언 노드 하나가 다운되었는데, 원인을 알아본 결과 팟의 리소스 사용량에 제한을 두지 않아서 이런 문제가 발생한 것으로 보인다. 특히 CPU 보다 메모리 사용량을 제한하지 않을 경우 치명적인데 최악의 경우 OOM(Out of Memory) 이 발생하여 노드가 재시작될 수도 있다. 팟의 리소스 제한을 설정하면 노드에 충분한 리소스가 남아있지 않을 경우 팟이 아예 배포되지 않으므로 노드의 OOM을 방지할 수 있을 것이다. 일단 팟의 리소스 제한을 설정하기 위해 어떤 팟이 얼마나 리소스를 사용하는지 모니터링을 해보자
Heapster addon 설치
Heapster를 설치하면 kubectl top (node|pod) 명령어를 사용하여 각 노드와 팟의 CPU, 메모리 사용량을 모니터링할 수 있다. Heapster만 설치해서는 명령어를 친 순간의 리소스 사용량만 모니터링할 수 있지만 지금은 이걸로 충분한 것 같다(influxDB, Grafana 플러그인을 사용하면 좀 더 상세한 모니터링이 가능하다). 그럼 명령어를 한번 실행해 보자.
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ip-10-xx-xx-xx.ap-northeast-2.compute.internal 97m 4% 2642Mi 68%
ip-10-xx-xx-xx.ap-northeast-2.compute.internal 68m 3% 3678Mi 46%
ip-10-xx-xx-xx.ap-northeast-2.compute.internal 54m 2% 3339Mi 42%
$ kubectl top po
NAME CPU(cores) MEMORY(bytes)
alpha-cluster01-router-1217976428-8xp7g 0m 10Mi
alpha-cluster01-front-web-3938765134-hvxwr 0m 124Mi
alpha-cluster01-api-gateway-4117715186-f23mv 0m 630Mi
alpha-cluster01-msa1-3928334195-11092 0m 726Mi
$ kubectl top po -n jenkins //젠킨스와 젠킨스 슬레이브 팟은 jenkins 네임스페이스를 가진다.
NAME CPU(cores) MEMORY(bytes)
jenkins-jenkins-322528892-n58cn 0m 1143Mi
jenkins-slave-3928334195-12824 0m 938Mi // 배포중일때 kubectl top 명령어를 사용해 보았다.kubectl top pod 명령어로 팟의 리소스를 모니터 할 때는 팟이 클러스터에 올라가고 시간이 좀 지나야 한다. 금방 올린 팟의 리소스 사용량이 안 뜬다면 잠시 후에 명령어를 다시 실행해 보자.
모니터링 결과 java로 만든 msa1과 Api-gateway 팟의 메모리 사용량이 상당함을 알 수 있었다. t2.medium 타입의 EC2 인스턴스를 두 미니언 노드의 가용 메모리는 8Gi인데 자바를 사용하는 팟 두 개 만으로도 1Gi가 넘는 메모리를 사용하는 셈이다. 배포에 사용되는 젠킨스 팟은 한술 더 뜨는데, 두개의 팟이 거의 2Gi 의 메모리를 사용하고 있는 상황이다. 이런 상황에서 메모리 사용량을 제한하지 않았으니 팟은 약간의 노드에 약간의 리소스만 사용 가능해도 배포되었을 것이며 시간이 지남에 따라 제한 없이 사용 메모리를 계속 늘려감으로써 노드의 OOM을 초래하게 되는 것도 무리가 아니었다. 안정적으로 다수의 테스팅 환경을 위해 팟에 리소스 제한을 설정하자.
팟의 리소스 제한
쿠버네티스에선 팟에서는 사용할 리소스를 제한할 수 있는데, 만약 제한하지 않으면 팟은 메모리를 제한 없이 사용하게 된다. 팟이 사용할 리소스 설정에는 request, limit 두 가지가 있는데 request는 해당 팟이 실행되기 위해 요구하는 리소스 사용량으로 쿠버네티스는 노드에 request 에 설정한 값 이상의 리소스가 남아있을 경우에만 팟을 노드에 배포한다. limit는 팟이 최대로 사용할 수 있는 리소스의 값이다.
리소스 사용량을 설정한 팟이 노드에 배포될 때
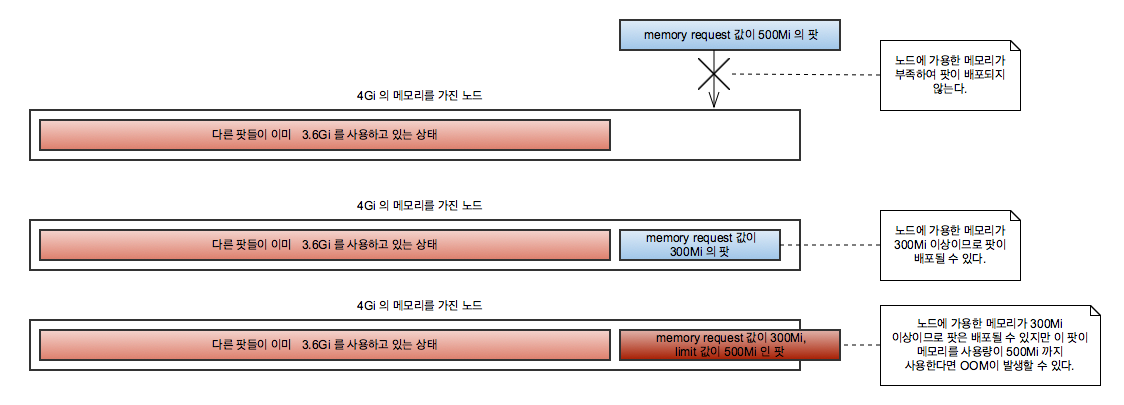
- 노드에 해당 팟이 배포될 수 있는지는 request로 판단함에 주의해야 한다. 1Gi의 메모리를 가진 노드에 request 100Mi, limit 1Gi로 설정되어 있는 팟을 두 개 배포할 경우 두 팟 모두 배포되지만 각 팟이 1Gi 의 메모리를 사용하려고 하며 이는 노드에 OOM을 발생시킬 가능성이 있다.
- Docker에서도 발생하는 문제지만 컨테이너에서 java를 사용할 때 JVM 의 힙 메모리를 설정하지 않으면 JVM 은 컨테이너에서 사용 가능한 메모리가 아닌 노드가 사용할 수 있는 총 메모리를 기준으로 힙 메모리를 사용할 것이다. java 컨테이너를 실행할 때는 힙메모리 설정을 하는 것이 안전할 것이다.
Deployment에서 팟 리소스 제한 걸기
...
spec:
template:
spec:
containers:
- args:
-Dfile.encoding=utf-8
command:
- java
- -server
- -Xmx256m
- -Xms256m
- -jar
- /home/java/app.jar
image: msa1-image-repo:msa1-image-tag
imagePullPolicy: IfNotPresent
name: msa1
ports:
- containerPort: 8080
protocol: TCP
resources:
limits:
memory: 448Mi
requests:
memory: 448Mi
...Deployment에서 관리하는 팟의 리소스 제한을 걸어준다. 리소스 사용량을 모니터링을 하면서 서비스가 유지되는 한도 내에서 최대한 줄여보았다. 다른 팟들의 리소스 사용량도 설정했다면. 이제 배포에 사용되는 젠킨스 슬레이브 팟의 리소스도 제한해야 하는데 마찬가지로 다음과 같이 컨테이너별로 리소스 사용량을 제한할 수 있다.
podTemplate(label: 'build-msa1',
containers: [
//젠킨스 슬레이브 컨테이너는 선언하지 않아도 자동으로 포함되지만 리소스 제한을 설정하기 위해서는 직접 선언해줘야 한다.
containerTemplate(name $', resourceLimitMemory: '384Mi',
envVars: [
envVar(key: 'JVM_HEAP_MIN', value: '-Xmx192m'),
envVar(key: 'JVM_HEAP_MAX', value: '-Xmx192m')
]
),
containerTemplate(name: 'java', image: 'java:8-jdk', ttyEnabled: true, command: 'cat', resourceLimitMemory: '768Mi',
envVars: [
envVar(key: 'JVM_HEAP_MIN', value: '-Xmx256m'),
envVar(key: 'JVM_HEAP_MAX', value: '-Xmx256m')
]
),
containerTemplate(name: 'docker', image: 'docker:17.11', ttyEnabled: true, command: 'cat', resourceLimitMemory: '64Mi'),
]
);이제 노드가 OOM으로 다운되는 문제가 방지되는지 다시 테스팅 환경을 5개 이상 배포해보니 클러스터가 매우 느려지고 마지막에 배포하려는 테스팅 환경이 배포되지 않는 상황이 발생하긴 하지만 노드 자체가 다운되는 현상은 발생하지 않았다. 이제 나름 안정을 찾게 된 듯하다. 그런데 리소스 사용량을 설정하다 보니 젠킨스 슬레이브 팟의 메모리 사용량 워낙 많음(1Gi 정도를 제공하지 않으면 제대로 동작하지 않았다)을 알게 되었는데, 만약 두 개의 노드에 테스팅 환경을 위한 팟이 골고루 배포된다면 어느 노드에도 젠킨스 슬레이브 팟이 배포되지 않을 가능성이 있지 않을까?
리소스는 남는데 왜 배포를 하질 못하니…
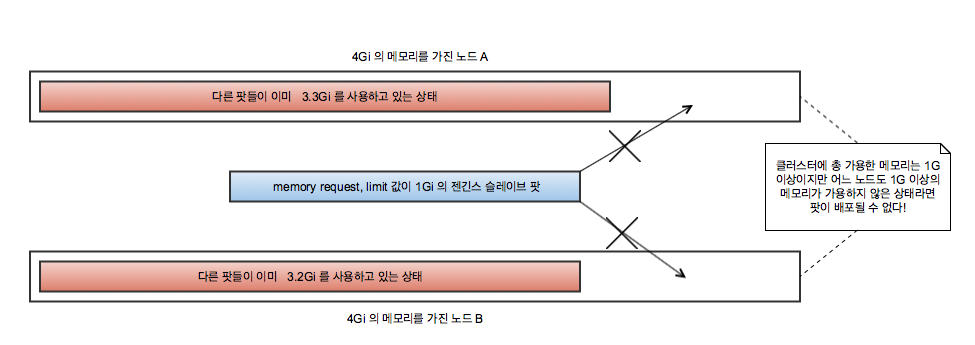
사용할 수 있는 총 자원은 충분하지만 팟이 어떻게 배포되느냐에 따라 자원 소모가 큰 팟이 배포가 되지 못할 수 있다. 그렇다면 배포를 할 때 젠킨스 슬레이브 팟의 배포를 위한 자원을 확보하려면 두 개의 노드에 어떤 식으로 팟이 배포될지 제어를 할 필요가 있다.
NodeAffinity & NodeSelector
팟에 NodeAffinity를 설정하면 팟이 배포될 때 어떤 노드를 선호할지 노드에 붙은 라벨을 사용하여 설정할 수 있는데, 노드에 라벨을 붙이는 방법은 다음과 같다.
kubectl label nodes <node-name> <label-key>=<label-value>
이미 붙은 라벨을 수정하려면 –overwrite 옵션을 사용해야 한다.
노드에 라벨이 붙은 상태
$ kubectl get node --show-labels
NAME STATUS AGE VERSION LABELS
ip-10-xx-xx-xx.ap-northeast-2.compute.internal Ready 11d v1.7.11 alpha-pod-affinity=deploy ....
ip-10-yy-yy-yy.ap-northeast-2.compute.internal Ready 11d v1.7.11 alpha-pod-affinity=service ....Deployment 에서 관리하는 팟에 NodeAffinity 설정
spec:
template:
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: alpha-pod-affinity
operator: In
values:
- service
weight: 99 # 좀 극단적이지만 alpha-pod-affinity 라벨의 값이 service 인 노드를 편애하게 만들도록 하자.
- preference:
matchExpressions:
- key: alpha-pod-affinity
operator: In
values:
- deploy # alpha-pod-affinity 라벨의 값이 deploy 라면 service 노드에 배포 불가능한 상황일 경우에나 deploy 노드에 배포될 것이다.
weight: 1배포를 위한 젠킨스 슬레이브 팟에도 NodeAffinity를 적용하고 싶었으나 안타깝게도 지금은 nodeAffinity 설정을 지원하지 않는 것 같다. 하지만 다행스럽게도 nodeSelector는 지원하는데, nodeSelector 역시 노드에 붙은 라벨을 이용하여 팟의 배포를 제어할 수 있지만 nodeAffinity 처럼 선호하는 노드를 지정하는 것이 아니라 해당 라벨을 가진 노드에만 팟의 배포가 가능하도록 하는 방식이다. 즉 nodeSelector에 지정한 라벨을 가진 노드가 없을 때는 팟이 배포되지 못하니 주의하자.
파이프라인에 nodeSelector 설정을 추가 예시
podTemplate(label: 'build-msa1', nodeSelector: 'alpha-pod-affinity=deploy', // 노드셀렉터 설정을 추가하였다.
containers: [
containerTemplate(name $', resourceLimitMemory: '384Mi',
envVars: [
envVar(key: 'JVM_HEAP_MIN', value: '-Xmx192m'),
envVar(key: 'JVM_HEAP_MAX', value: '-Xmx192m')
]
),
containerTemplate(name: 'java', image: 'java:8-jdk', ttyEnabled: true, command: 'cat', resourceLimitMemory: '768Mi',
envVars: [
envVar(key: 'JVM_HEAP_MIN', value: '-Xmx256m'),
envVar(key: 'JVM_HEAP_MAX', value: '-Xmx256m')
]
),
containerTemplate(name: 'docker', image: 'docker:17.11', ttyEnabled: true, command: 'cat', resourceLimitMemory: '64Mi'),
]
volumes: [
hostPathVolume(hostPath: '/var/run/docker.sock', mountPath: '/var/run/docker.sock')
]
);이제 테스팅 환경용 팟은 alpha-pod-affinity=service 라벨이 붙은 노드에 우선적으로 배포된 후 더 이상 배포하기 힘들 때에나 라벨이 alpha-pod-affinity=deploy 인 노드에 팟을 배포할 것이다. 그리고 젠킨스 슬레이브 팟은 alpha-pod-affinity=deploy 라벨이 붙은 노드에만 배포될 것이다.
팟이 어떤 노드에 배포되었는지 확인해보자.
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
alpha-cluster01-api-gateway-4117715186-f23mv 1/1 Running 0 1h 100.113.255.189 ip-10-xx-xx-xx.ap-northeast-2.compute.internal
alpha-cluster01-front-web-3938765134-hvxwr 1/1 Running 0 1h 100.113.255.149 ip-10-xx-xx-xx.ap-northeast-2.compute.internal
alpha-cluster01-msa1-3928334195-11092 1/1 Running 0 1h 100.113.255.148 ip-10-xx-xx-xx.ap-northeast-2.compute.internal
alpha-cluster01-router-1217976428-8xp7g 1/1 Running 0 1h 100.113.255.187 ip-10-xx-xx-xx.ap-northeast-2.compute.internal
$ kubectl get po -o wide -n jenkins
NAME READY STATUS RESTARTS AGE IP NODE
jenkins-jenkins-322528892-n58cn 1/1 Running 0 7d 100.111.50.79 ip-10-yy-yy-yy.ap-northeast-2.compute.internal
jenkins-slave-4028334195-12824 4/4 Running 0 2m 100.111.50.82 ip-10-yy-yy-yy.ap-northeast-2.compute.internal배포 속도 개선
클러스터가 안정되니 이번엔 15분을 넘어가는 배포 속도가 거슬리기 시작했다. 만약 이렇게 느린 배포 과정에서 마지막 도커 이미지 빌드에 사용되는 Git 브랜치 명이라도 잘못 입력하여 빌드가 실패한다면 썩 유쾌하진 않을 것이다. 젠킨스 빌드 로그를 보면 빌드에 걸리는 속도의 주범은 gradle, composer, npm 등을 사용하여 라이브러리 의존성을 처리하는 작업인 것으로 보이는데 이런 작업들은 일반적인 상황이라면 실행 시 캐시가 남아 다음 실행 시의 실행시간이 단축되지만 현재 빌드 환경에서는 언제나 새로운 젠킨스 슬레이브 팟이 배포되기 때문에 캐시가 남지 않는 것이 엄청나게 느린 속도 빌드 속도의 주범이다. 그렇다면 helm의 jenkins 패키지처럼 PV를 마운트 하여 캐시를 영속적으로 저장한다면 빌드 속도를 개선시킬 수 있지 않을까? 일단 AWS 에서 사용할 EBS를 만들고 해당 id를 이용하여 클러스터에서 사용할 PV를 만들도록 하자.
젠킨스 슬레이브 팟에 캐시용 EBS를 PV(Persistent Volume), PVC(Persistent Volume Claim) 을 사용하여 마운트한 구조도
PV 와 PVC 리소스를 만들었다면 파이프라인에 persistent volume 을 설정해준다.
podTemplate(label: 'build-msa1', nodeSelector: 'alpha-pod-affinity=deploy',
containers: [
containerTemplate(name $', resourceLimitMemory: '384Mi',
envVars: [
envVar(key: 'JVM_HEAP_MIN', value: '-Xmx192m'),
envVar(key: 'JVM_HEAP_MAX', value: '-Xmx192m')
]
),
containerTemplate(name: 'java', image: 'java:8-jdk', ttyEnabled: true, command: 'cat', resourceLimitMemory: '768Mi',
envVars: [
envVar(key: 'JVM_HEAP_MIN', value: '-Xmx256m'),
envVar(key: 'JVM_HEAP_MAX', value: '-Xmx256m')
]
),
containerTemplate(name: 'docker', image: 'docker:17.11', ttyEnabled: true, command: 'cat', resourceLimitMemory: '64Mi'),
],
volumes: [
hostPathVolume(hostPath: '/var/run/docker.sock', mountPath: '/var/run/docker.sock'),
persistentVolumeClaim(mountPath: '/home/jenkins/.gradle', claimName: 'msa1', readOnly: false) //Gradle 캐시를 저장할 EBS 를 마운트한다.
]
);이미 생성된 EBS의 ID 를 사용할 경우 배포될 팟과 EBS의 availability zone 은 동일해야 한다. 그렇지 않으면 팟이 배포되지 않는다. 빌드에 사용되는 EBS 는 모두 ip-10-yy-yy-yy.ap-northeast-2.compute.internal 노드와 동일한 availability zone 에 생성해두었다.
EBS를 마운트 하여 사용하니 자바 서비스의 빌드 속도가 눈에 띄게 개선되었다(MSA #1 서비스의 경우는 8분 → 2분, ApiGateway 5분 → 2분으로 많이 단축되었지만 Front Web은 8분→5분 정도로 살짝 단축됨). 그리고 클러스터 상에 자원이 많을 경우 파이프라인의 parallel 문을 사용하여 java로 된 MSA #1, ApiGateway 서비스와 Front Web 서비스를 빌드하는 각각의 젠킨스 슬레이브 팟을 클러스터에 동시에 배포하여 빌드를 병렬로 진행하는 파이프라인을 추가하여 배포에 걸리는 시간을 더 단축할 수 있었다.
Ingress
이제 마지막으로 수동으로 해줘야 하는 작업이 남아있는데, 그것은 바로 테스팅 환경이 하나 배포될 때마다 생성된 ELB에 Route53 의 도메인을 연결하는 작업이다. 사실 도메인 연결은 귀찮긴 하지만 별것 아니지만 새로 생성된 ELB의 시큐리티 그룹을 설정해주는 것이 더 문제다. 테스팅 환경이 배포될 때마다 새로 생성된 ELB의 시큐리티 그룹을 다시 설정해주지 않으면 테스팅 환경이 외부에 노출될 수도 있을 것이다. 이제 이 문제만 해결한다면 배포는 완전 자동화를 달성할 수 있을 것이다. 이 문제는 Ingress 리소스를 사용하여 ELB를 한 개만 고정으로 사용하고 Ingress 에서 받은 요청을 호스트 값에 따라 알맞는 테스팅 환경으로 각각 포워딩하면 해결할 수 있을 것이다. Ingress 는 apache 의 virtual host 와 같은 역할을 한다고 생각하면 될 것이다. 그런데 Ingress 리소스는 쿠버네티스에서 기본으로 지원되는 것은 아니라서 사용하려면 우선 ingress addon 을 설치해줘야 한다. Ingress를 addon을 설치하면 kube-ingress 네임스페이스에 ingress-nginx 라는 로드밸런서를 만드는데, 이 로드밸런서 역시 AWS ACM인증서를 사용하기 위해서 ACM 설정을 위한 annotation을 추가해준다. (ACM인증서 사용을 위한 annotation은 이 글의 윗부분에서 찾을 수 있다) 이제 ELB는 이 로드밸런서에서만 사용할 것이다.
Ingress 가 적용된 테스팅 환경의 구조
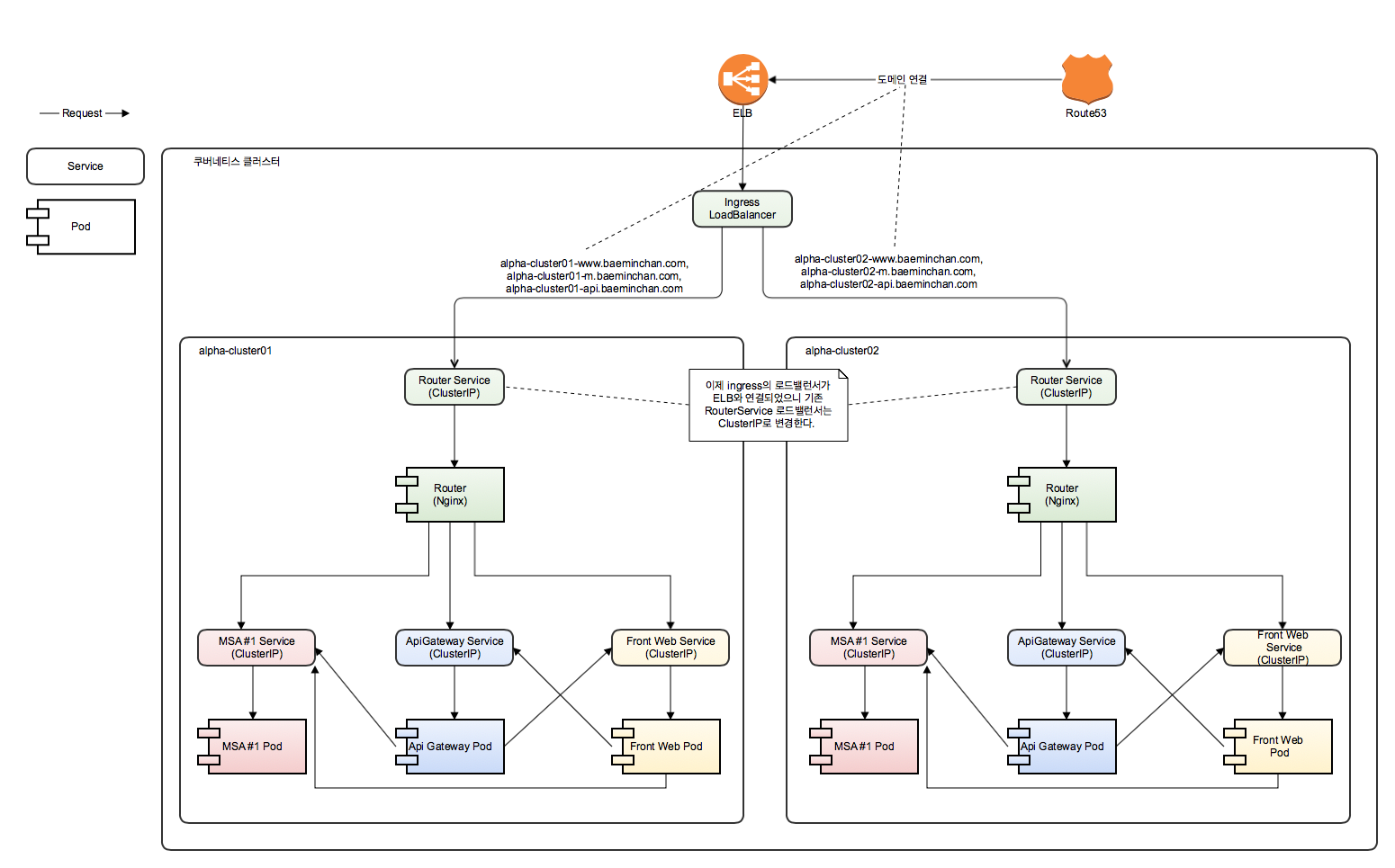
이제 ingress 리소스를 설정하여 클러스터에 추가하자
Ingress 설정 yaml 파일
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: alpha-cluster
spec:
rules:
- host: alpha-cluster01-www.testdomain.com
http:
paths:
- path: /
backend:
serviceName: alpha-cluster01-router
servicePort: 80
- host: alpha-cluster01-api.testdomain.com
http:
paths:
- path: /
backend:
serviceName: alpha-cluster01-router
servicePort: 80
- host: alpha-cluster01-m.testdomain.com
http:
paths:
- path: /
backend:
serviceName: alpha-cluster01-router
servicePort: 80
- host: alpha-cluster02-www.testdomain.com
http:
paths:
- path: /
backend:
serviceName: alpha-cluster02-router
servicePort: 80
- host: alpha-cluster02-api.testdomain.com
http:
paths:
- path: /
backend:
serviceName: alpha-cluster02-router
servicePort: 80
- host: alpha-cluster02-m.testdomain.com
http:
paths:
- path: /
backend:
serviceName: alpha-cluster02-router
servicePort: 80
# 나머지 도메인도 똥일하게 설정해준다.이제 ELB 는 Ingress 에 연결된 1개만 남았고 테스팅 환경을 배포하면 Ingress 를 통해 접속할 수 있어 Route53과 Security Group 을 테스팅 환경을 배포할 때마다 수정할 필요가 없어지게 되었으니 이제 배포가 자동화되었다고 할 수 있을 것 같다.
갱신이 필요한 서비스만 새로 배포하기
이제 테스팅 환경을 배포하는 것은 자동화 하였는데, 만약 수정한 서비스는 한 개인데 테스팅 환경에 필요한 모든 리소스를 재배포해야 한다면 효율적이지 않을 것이다. 원하는 하나의 서비스만 교체하는 파이프라인을 만들어 보자. 테스트를 구성하는 서비스는 Deployment를 통해 팟을 관리하니 kubectl set image 명령어를 사용하면 지정한 Deployment에서 사용하는 팟의 도커 이미지가 수정할 수 있는데, Deployment 리소스는 사용하는 도커 이미지가 변경될 경우 팟을 변경된 이미지를 사용하도록 재배포하므로 이를 이용하여 원하는 서비스만 갱신하는 파이프라인을 만들 수 있다.
MSA #1 서비스 하나만 갱신하는 파이프라인 예, helm이 아닌. kubectl 컨테이너를 사용한다.
def msa1Image = ""
def msa1ImageTag
node {
stage('Partial Deploy Msa1') {
if (msa1ImageTag == null) {
podTemplate(label: 'build-msa1', nodeSelector: 'alpha-pod-affinity=deploy',
containers: [
containerTemplate(name $', resourceLimitMemory: '384Mi',
envVars: [
envVar(key: 'JVM_HEAP_MIN', value: '-Xmx192m'),
envVar(key: 'JVM_HEAP_MAX', value: '-Xmx192m')
]
),
containerTemplate(name: 'java', image: 'java:8-jdk', ttyEnabled: true, command: 'cat', resourceLimitMemory: '768Mi',
envVars: [
envVar(key: 'GRADLE_OPTS', value: '-Xmx384m'),
envVar(key: 'JVM_HEAP_MIN', value: '-Xmx256m'),
envVar(key: 'JVM_HEAP_MAX', value: '-Xmx256m')
]
),
containerTemplate(name: 'docker', image: 'docker:17.11', ttyEnabled: true, command: 'cat', resourceLimitMemory: '64Mi'),
containerTemplate(name: 'kubectl', image: 'lachlanevenson/k8s-kubectl:latest', ttyEnabled: true, command: 'cat', resourceLimitMemory: '64Mi')
],
volumes: [
hostPathVolume(hostPath: '/var/run/docker.sock', mountPath: '/var/run/docker.sock'),
persistentVolumeClaim(mountPath: '/home/jenkins/.gradle', claimName: 'msa1', readOnly: false)
]
) {
node('build-msa1') {
stage("Build Msa1") {
git branch", credentialsId', url"
gitCommit = sh(returnStdout: true, script: 'git rev-parse HEAD').trim().take(8)
msa1ImageTag = "partial-$-$"
container('java') {
sh './gradlew --gradle-user-home=/home/jenkins/.gradle --no-daemon --stacktrace -x test -x findBugsMain -x findBugsTest clean build'
}
container('docker') {
sh "docker build -t $ ."
}
}
stage ('Push Msa1') {
container('docker') {
docker.withRegistry('', '') {
docker.image("$").push()
}
}
}
stage('Update Deployment Image') {
container('kubectl') {
sh "kubectl set image deployment/$-msa1 msa1=$ -n default"
}
}
}
}
}
}
}이제 원하는 서비스만 빌드하여 배포하는 것이 가능해졌으니 좀 더 효율적으로 테스팅 환경을 사용하는 것이 가능할 것이다.
마치며
쿠버네티스를 사용하며 경험을 쌓아보자는 생각으로 시작한 작업이었지만 실제로 테스팅 환경을 구축하면서 느낀 점은 테스팅 환경을 구성하는 데에 있어서도 편리하고 유용했다는 점이다. 쿠버네티스의 리소스들은 클러스터가 AWS든 GCE 든 상관없이 클러스터 환경이 구성되어 있다면 얼마든지 올려서 사용할 수 있으며 AWS를 다루는데 익숙하지 않은 본인의 입장에서 도커 이미지를 빌드하고 쿠버네티스 리소스를 생성하는 것으로 손쉽게 다른 서비스들을 테스팅 환경에 추가할 수 있다는 점에서 상당히 매력적이었다. 그리고 정말 잘 구성한다면 테스팅 환경을 유지하는데 드는 예산도 절약할 수 있는 가능성을 보여준다. 사용하는 AWS 인스턴스 수가 줄어드는 건 소소한 덤이라고 볼 수 있겠다.
정리를 해놓고 보니 쿠버네티스 자체보다는 배포 자동화에 대한 내용이 더 많아진 것 같다. 필자는 젠킨스의 쿠버네티스 플러그인을 사용하여 파이프라인을 작성하였지만 굳이 이 플러스인 사용 없이도 얼마든지 배포를 자동화시킬 수는 있을 것이다. 하지만 젠킨스 슬레이브 팟을 클러스터에 배포하고 팟에 포함된 컨테이너를 통해 빌드를 하는 것은 나름 신선한 경험이었고 빌드를 위한 컨테이너를 별도로 만들어서 빌드 작업에 사용하는 것도 의외의 편리함을 제공하여 한번 사용해 볼 만한 가치는 있다는 느낌이 들었다. 만약 쿠버네티스에 관심이 있고 사용해보고 싶지만 실제로 적용하는데 부담이 된다면 테스팅 환경과 그 배포 환경을 쿠버네티스를 이용하여 구성해보는 것부터 비교적 가볍게 시작해보는 건 어떨까?