Elasticsearch 병렬 테스트를 향한 여정
여정에 앞서서 🧳
안녕하세요! 이번 글에서는 검색팀에 도입되어 2배 이상의 성능 향상을 이룬 병렬 테스트에 대해서 공유하고자 합니다. 특히, Elasticsearch에 의존하는 환경에서 병렬 테스트를 효과적으로 수행하기 위한 격리 전략에 대해 자세히 다룰 예정입니다.
병렬 테스트로 가는 여정에 앞서 저희 검색 시스템에 대해서 간략하게 설명하겠습니다.
저희는 검색엔진으로 Elasticsearch(이하 ES)를 사용합니다. 대부분의 코드가 ES에 의존하고 있으며, 테스트 코드는 주로 통합 테스트 형식으로 작성되었습니다. 작성한 쿼리가 올바르게 동작하는지, 필터링과 정렬이 제대로 수행되는지를 ES의 응답 값을 통해 확인합니다.
검색 시스템은 멀티 모듈로 구성되어 있습니다. 총 20개 이상의 모듈이 있습니다. 상위 모듈은 application - domain - infrastructure 구조로 되어있고, 각각의 상위 모듈 아래 하위 모듈이 존재합니다.
CI/CD 환경에서 전체 테스트 코드를 gradle test로 실행하며, ES나 RDB을 사용한 통합 테스트를 위해 미리 컨테이너로 ES와 MySQL을 띄워놓고 테스트를 진행합니다.
테스트 코드가 약 1,500개가 넘어서자, CI/CD 환경에서 테스트 수행 시간이 무려 10분을 넘기기 시작했습니다. 최적화가 매우 필요했습니다. 앞으로 성장해 나갈 시스템을 위해 빠른 피드백을 받는 게 무엇보다 중요하기 때문이죠. 그래서 저희는 병렬 테스트를 도입하기로 했습니다. 병렬 테스트를 통해 각 CPU 코어가 서로 다른 테스트를 실행하여 처리 성능을 향상할 수 있기 때문입니다.
검색 시스템의 상황을 요약하면 다음과 같습니다.
ES, DB에 대한 공유 의존성을 사용하여 테스트를 진행한다.서비스 특성상 주로 통합 테스트 위주로 테스트를 구성한다.20개 이상의 멀티모듈로 구성되어 있다.
이제 병렬 테스트를 향한 여정을 시작해 보겠습니다.
결국은 격리다
gradle test --parallel
Gradle은 --parallel 옵션을 통해 테스트를 병렬로 처리할 수 있도록 지원합니다. 이 옵션을 추가하면 각 모듈이 병렬로 테스트를 수행해 테스트 성능을 최적화할 수 있습니다.
참고 링크 : https://docs.gradle.org/current/userguide/performance.html#parallel_execution
무작정 -parallel 옵션을 포함해 테스트를 실행해 보았지만, 테스트는 실패했습니다.

병렬 테스트가 실패하는 가장 큰 원인은 무엇일까요? 대부분의 경우 공유 의존성에 대한 격리가 제대로 이루어지지 않기 때문입니다. 병렬로 테스트를 실행하는 동안 격리가 이루어지지 않은 자원(ES, DB)에 접근하게 되어 동시성 문제가 발생하게 됩니다. 따라서 병렬 처리를 위해서는 공유 의존성에 대한 격리가 필수적입니다.
이제 코드를 보면서 어떤 문제가 있었고 어떻게 해결했는지 살펴보겠습니다.
ES 격리 진행하기
@ExtendWith(ElasticsearchContainerExtension.class)
class ExampleTest {
// test code...
}저희는 ES를 이용한 통합 테스트를 진행할 때 위와 같은 형식으로 테스트 코드를 작성합니다. ElasticsearchContainerExtension를 확장하여 ES 통합 테스트 환경을 구성합니다.
public class ElasticsearchContainerExtension implements BeforeAllCallback {
@Override
public void beforeAll(ExtensionContext context) {
createContainerIfNotStarted();
createIndex();
}
}ElasticsearchContainerExtension 객체는 beforAll 을 구현합니다. beforeAll에서 수행하는 해당 객체의 역할을 아래와 같습니다.
- ES가 시작되지 않았다면 Testcontainers를 이용해 ES를 시작합니다.
- 테스트에 필요한 모든 인덱스를 생성합니다.
CI/CD 환경 혹은 로컬 개발 환경에서는 주로 Docker로 ES를 미리 시작해 놓고 테스트를 수행합니다. 따라서 createContainerIfNotStarted()는 넘어가고 createIndex() 코드를 자세히 살펴보겠습니다.
통합 테스트 환경을 구성할 때 createIndex()로 인덱스를 미리 생성하는 이유는, 원하는 mapping, setting으로 구성된 인덱스로 테스트를 진행하기 위함입니다. 미리 인덱스를 생성하지 않으면 테스트 코드 중 색인 요청으로 동적으로 인덱스가 생성되어 원하는 테스트를 수행하지 못할 수 있습니다.
예를 들어, RDB에서 생성되지 않은 테이블에 Insert 하면 입력한 row에 맞는 테이블이 자동으로 생성되는 기능이 ES에서는 제공됩니다. 이는 타입 설정이 자동으로 이루어져 테스트가 실패할 수 있습니다.
참고링크 : https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic-mapping.html
private void createIndex() {
for (RealIndexType index : RealIndexType.values()) {
IndexCreator.createIndex(index.getSearchAlias(), index);
}
}createIndex()는 IndexCreator에 관리하는 모든 인덱스를 생성하라는 명령을 전달합니다. IndexCreator는 인덱스를 생성하는 역할을 수행하며 다음과 같은 동작을 합니다. 현재 관리하는 인덱스는 약 20 개입니다.
public class IndexCreator {
public static boolean createIndex(String indexAlias, IndexType indexType) {
String indexName = createIndexName(indexAlias)
if (esCommandClient.isIndexExist(indexAlias)) {
return true;
}
Map<String, Object> testSchema = indexSchemaSourceBuilder.getSchemaSource(indexType);
return doCreate(indexAlias, indexName, testSchema);
}
}IndexCreator는 다음 순서로 인덱스를 생성합니다. 검색 시에는 alias를 사용하기 때문에 alias를 꼭 지정합니다.
createIndexName(): 인덱스 이름을 생성합니다. 인덱스 이름과 alias는 동일하면 안 되므로 인덱스 이름에 yyyy-MM-dd_hhmmss를 붙입니다.- 인덱스 존재 확인 : 동일한 alias를 가진 인덱스가 이미 생성되었는지 확인합니다. 이미 생성되어 있다면 새 인덱스를 만들지 않습니다.
- 스키마 생성 : 각 인덱스 타입에 맞는 스키마(setting + mapping) 정보를 생성합니다.
doCreate(): 인덱스 이름, alias, 스키마를 이용해 인덱스를 생성합니다.
이제 gradle test --parallel로 실행했을 때 발생했던 오류 중 하나를 살펴보겠습니다.
ElasticsearchStatusException[Elasticsearch exception [type=illegal_argument_exception, reason=no write index is defined for alias [test-main].
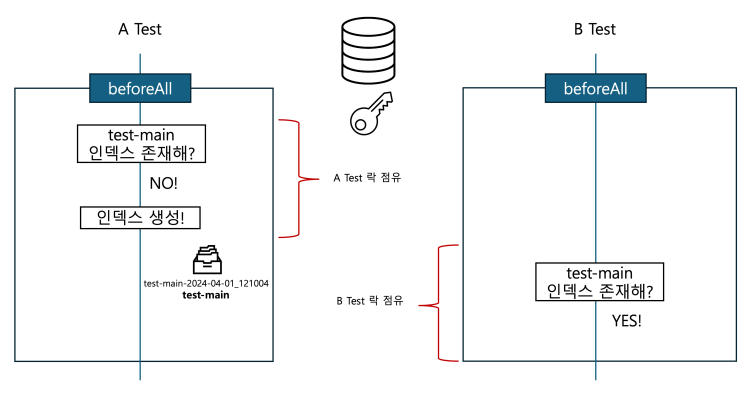
The write index may be explicitly disabled using is_write_index=false or the alias points to multiple indices without one being designated as a write index]위 에러는 순차적으로 수행되던 기존의 ES 통합 테스트 코드가 병렬로 수행되면서 발생한 에러입니다.

에러를 그림으로 표현해 보면 위와 같습니다. 테스트 코드 내에서 test-main 인덱스에 문서를 색인 요청할 때 ES 내에 test-main이라는 여러 인덱스가 생성되어, 어떤 인덱스로 write 요청해야 하는지 알 수 없어 발생한 에러입니다. 그런데 의아하게도 작성된 코드를 살펴보면 동일한 alias는 하나만 가지도록 체크하는 로직이 존재합니다 ( if (esCommandClient.isIndexExist(indexAlias)) ...). 이는 동시성 문제로 볼 수 있습니다. 좀 더 자세히 문제를 파헤쳐 봅시다.
문제를 예제로 구성해 봅시다. A Test, B Test가 존재하고 모두 ElasticsearchContainerExtension 을 사용한다고 가정합니다. 두 테스트를 병렬로 처리하면 다음과 같은 문제가 발생할 수 있습니다.

- A Test와 B Test에서 각각 beforeAll을 수행해 인덱스 생성합니다.
- A Test에서 인덱스 유무를 확인합니다.
- A Test는 인덱스 유무 확인을 마치고 인덱스를 생성합니다.
- B Test도 인덱스 유무를 확인합니다. 그 시점에 A Test에서 아직 인덱스를 만들지 않았기 때문에 인덱스가 없다는 응답을 받습니다.
- B Test에서 인덱스를 생성합니다.
이런 상황에서 동시성 문제가 발생하여 test-main이라는 alias를 가진 인덱스가 두 개 이상 생성될 수 있습니다. 이를 해결하기 위해 몇 가지 방안을 생각해 보았습니다.
아이디어 1 : 🚫 스레드 락을 이용하기
병렬 처리 상황에서 락을 통해 제어하는 것은 보편적인 방법입니다. 그래서 간단하게 락을 걸어 동시성 문제를 해결해 보려 했습니다. synchronized, ReetrantLock 등을 이용해 코드를 동기화할 수 있을 것으로 생각했죠. 하지만 락을 걸어도 문제가 해결되지 않았고 이슈는 계속되었습니다.
문제는 꽤 간단했습니다. gradle test --parallel 옵션을 사용하면 테스트가 모듈 단위로 테스트 프로세스가 분리되어 병렬 처리된다는 점입니다.
학습 테스트: gradle test –parallel
학습 테스트를 통해 gradle test --parallel 이 프로세스 단위로 동작되는 것을 확인해 보겠습니다. 먼저 테스트를 위해 parallel-a, parallel-b, core 모듈을 각각 준비했습니다.
public class TestExtension implements BeforeAllCallback {
private static final AtomicInteger atomic = new AtomicInteger(0);
@Override
public void beforeAll(ExtensionContext context) throws Exception {
Thread.sleep(1000);
int i = atomic.incrementAndGet();
System.out.println("atomic : " + i);
}
}검색 시스템의 ElasticsearchContainerExtension처럼 위와 같이 core 모듈에 TestExtension 객체를 작성했습니다. 여기서는 단순히 카운트만 올리고 이를 출력합니다.
-
core 모듈
@ExtendWith(TestExtension.class) public class TestInnerA { @Test void test() throws Exception { System.out.println("testInnerA!"); } }@ExtendWith(TestExtension.class) public class TestInnerB { @Test void test() throws Exception { System.out.println("testInnerB!"); } }@ExtendWith(TestExtension.class) public class TestInnerC { @Test void test() throws Exception { System.out.println("testInnerC!"); } } -
parallel-a 모듈
@ExtendWith(TestExtension.class) public class TestA { @Test void test() throws Exception { System.out.println("testA!"); } } -
parallel-b 모듈
@ExtendWith(TestExtension.class) public class TestB { @Test void test() throws Exception { System.out.println("testB!"); } }
위와 같이 core 모듈에는 세 가지 테스트를 작성했고 parallel-a, parallel-b 모듈에는 각각 하나의 테스트를 작성했습니다. 모두 TestExtension을 확장하는 형태죠. 이 상황에서 ./gradlew test --parallel --info를 통해 테스트의 결과를 살펴보면 다음과 같습니다.
> Task :parallel-a:test
Starting process 'Gradle Test Executor 80'. Working directory:...
Successfully started process 'Gradle Test Executor 80'
TestA STANDARD_OUT
atomic : 1
> Task :parallel-b:test
Starting process 'Gradle Test Executor 79'. Working directory:...
Successfully started process 'Gradle Test Executor 79'
TestB STANDARD_OUT
atomic : 1
> Task :core:test
Starting process 'Gradle Test Executor 78'. Working directory:...
Successfully started process 'Gradle Test Executor 78'
TestInnerA STANDARD_OUT
atomic : 1
TestInnerB STANDARD_OUT
atomic : 2
TestInnerC STANDARD_OUT
atomic : 3실행된 로그에서 유효한 정보만 추출해 보면, 각각 다른 모듈에서 수행되는 테스트는 저마다 Gradle Test Executor를 사용한다는 것을 알 수 있습니다. 이는 다른 Gradle Test Executor에서 수행되면 프로세스로 분리되어 실행되므로, static으로 선언한 AtmoicInteger의 값도 따로 관리된다는 것을 의미합니다.
따라서 처음 사용하려 했던 스레드 락은 현재 상황에서 사용할 수 없습니다.
아이디어 2: 🚫 분산락 활용하기
여러 프로세스에서 테스트가 수행된다는 것을 확인한 후, 분산락을 이용해 문제를 해결할 수 있을지 고민했습니다. 여러 프로세스에서 공유하는 값을 RDB를 이용해 제어하면 스레드 락과 비슷한 아이디어를 구현할 수 있기 때문입니다.
위와 같이 분산락을 구현하면, 처음 인덱스를 생성할 때 A Test에서 필요한 모든 인덱스를 생성하고, B Test에서는 인덱스 유무만 확인하면 됩니다. 이를 통해 병렬로 수행했을 때 alias가 중복되는 문제를 방지할 수 있습니다.
그러나 분산락을 이용해 문제를 해결하면 다음과 같은 난관에 직면하게 됩니다.
ElasticsearchContainerExtension에 DB 관련 의존성이 추가됩니다.- 인덱스 유무를 확인하는 과정에서 락을 얻고 반납하는 과정이 추가되어 동시 처리 성능이 저하됩니다.
- 여러 모듈에서 하나의 인덱스에 동시에 테스트를 진행할 때 인덱스 내 문서에 대해서도 격리가 필요합니다.
이처럼 분산락을 이용하면 인덱스 생성 단계의 문제는 해결할 수 있지만, 결국 하나의 인덱스를 여러 테스트가 공유하게 되어 테스트 수행 중 문서를 인덱스에 색인하거나 삭제하는 과정에서 동시성 문제가 발생할 수 있습니다. 따라서 분산락을 사용하는 것은 근시안적인 해결 방법이었습니다.
아이디어 3 : ✅ 네임스페이스 전략 이용하기
락을 통해 문제를 해결하는 방식은 많은 난관이 남아있습니다. 그래서 아예 테스트 프로세스마다 사용하는 인덱스를 따로 가지게 하는 방법을 생각했습니다. 한 번만 인덱스를 생성하고 여러 프로세스가 같은 인덱스를 공유하는 대신, 각각의 프로세스가 사용할 인덱스를 따로 생성하는 것입니다.

위 그림처럼 프로세스마다 고유한 인덱스를 생성하여 사용하게 하고, 다른 프로세스가 생성한 인덱스에는 접근하지 못하게 한다면 인덱스 간의 격리 문제를 해결할 수 있습니다. 네임스페이스 전략은 락을 사용하는 방법에 비해 다음과 같은 장점이 있습니다.
- ES 만으로 문제를 해결할 수 있습니다. (분산락을 위한 공유 의존성이 필요 없음)
- 락을 점유하고 반납하는 오버헤드가 없습니다.
- 각 네임스페이스로 격리되어 인덱스에 대한 동시성 문제가 발생하지 않습니다.
이러한 장점으로 인해 네임스페이스 전략이 저희 시스템에 가장 적합해 보였고, 이를 적용하기로 결정했습니다.
네임스페이스 전략 적용하기
인덱스 생성 시 네임스페이스 적용
네임스페이스 전략을 적용하기 위해 가장 먼저 해야 하는 작업은 프로세스마다 고유한 식별자를 가지도록 하는 것입니다. 저는 static 변수를 활용해 고유한 값을 갖도록 했습니다. 테스트 프로세스들은 각각의 고유한 JVM 메모리 공간에서 동작하기 때문에 서로 static 변수를 공유하지 않으므로 동시성 문제도 발생하지 않습니다.
public class TestIndexNameFactory {
public static final String RANDOM_UUID = UUID.randomUUID().toString();
public static String attachIndexPrefix(String indexName) {
if (indexName.startsWith(RANDOM_UUID)) {
return "index-" + indexName;
}
return "index-" + RANDOM_UUID + indexName;
}
public static String attachAliasPrefix(String aliasName) {
if (aliasName.startsWith(RANDOM_UUID)) {
return aliasName;
}
return RANDOM_UUID + "-" + aliasName;
}
}TestIndexNameFactory는 정적 변수로 RANDOM_UUID를 가지고 있습니다. 이는 프로세스마다 고유한 식별자가 됩니다. 이 팩토리는 indexName, aliasName에 prefix를 붙여주는 역할을 하고, 이렇게 생성된 indexName과 aliasName은 프로세스마다 고유한 이름을 가지게 됩니다. 이제 이 팩토리를 활용해서 인덱스를 생성하도록 하겠습니다.
public class IndexCreator {
public static boolean createIndex(String indexAlias, IndexType indexType) {
String indexNameWithPrefix = TestIndexNameFactory.attachIndexPrefix(indexAlias);
String aliasNameWithPrefix = TestIndexNameFactory.attachAliasPrefix(indexAlias);
if (esCommandClient.isIndexExist(aliasNameWithPrefix)) {
return true;
}
Map<String, Object> testSchema = indexSchemaSourceBuilder.getSchemaSource(indexType);
return doCreate(aliasNameWithPrefix, indexNameWithPrefix, testSchema);
}
}기존의 IndexCreator가 프로세스 고유의 이름과 별칭을 가지는 인덱스를 생성하도록 변경되었습니다. 이제 테스트가 실행될 때마다 테스트 프로세스들은 저마다의 네임스페이스를 가지는 인덱스를 생성하게 될 것입니다. 하지만 아직도 문제가 남아있습니다.
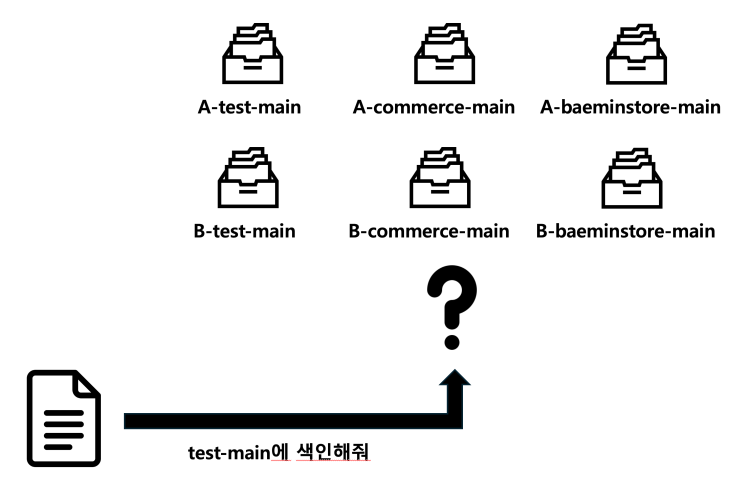
현재 상황은 위와 같습니다. 인덱스의 생성 자체는 분리되었지만, 실제 인덱스에 접근하는 로직은 수정되지 않았기 때문에 테스트 코드는 기존처럼 test-main 인덱스에 접근하려 합니다. 하지만 해당 인덱스는 이제 존재하지 않습니다. 다만 네임스페이스로 분리된 A-test-main, B-test-main만 존재할 뿐입니다. 이제 남아 있는 문제는 인덱스에 접근할 때에도 특정 네임스페이스의 인덱스에 요청을 보내도록 수정하는 것입니다.
인덱스 접근 시 네임스페이스 적용
접근 문제를 해결하는 과정을 살펴보기 전에, 저희 코드에서 어떻게 인덱스에 접근하고 있는지 살펴보겠습니다.
public interface IndexType {
TenantType getTenantType();
String getSchemaName();
default String getSearchAlias() {
return getSchemaName() + "-main";
}
default String getAutocompleteAlias() {
return getSchemaName() + "-autocomplete";
}
default String getAdminAlias() {
return getSchemaName() + "-admin";
}
... // 위와 비슷한 Alias 들이 몇 개 더 존재한다.
}@Getter
public enum RealIndexType implements IndexType {
BAEMIN_MART(
TenantType.BAEMIN_MART
),
COMMERCE(
TenantType.COMMERCE
),
...
;
private final TenantType tenantType;
private final String schemaName;
RealIndexType(TenantType tenantType) {
this.tenantType = tenantType;
this.schemaName = tenantType.name().toLowerCase().replaceAll("_", "-");
}
}현재 저희 코드에서는 IndexType 인터페이스의 getSearchAlias(), getAutocompleteAlias() 등의 메서드를 통해 인덱스 alias를 얻고 해당 alias로 ES 요청을 합니다.
public abstract class ElasticsearchRepository {
protected Mono<ElasticResult<DocumentHit>> internalSearch(SearchSourceBuilder searchSourceBuilder, IndexType indexType) {
String indexName = indexType.getSearchAlias(); // <<< IndexType에 맞는 alias 이름을 가져와서 사용한다.
return EsSearchClient.inquire(indexName, searchSourceBuilder)
.map(searchResponse -> ElasticResult.fromResponse(searchResponse))
.onErrorResume(e -> {
log.error("[ElasticsearchRepository][internalSearch] failed to search; indexType={}", indexType, e);
return Mono.just();
});
}
}위 코드는 IndexType을 전달하여 EsClient에 요청을 보내는 과정입니다. 메서드의 첫 번째 라인을 보면 indexType.getSearchAlias() 메서드를 통해 alias 이름을 꺼내와 검색 요청에 사용하는 것을 확인할 수 있습니다. 이런 식으로 인덱스에 접근하는 로직이 구성됩니다. 테스트에서는 어떻게 네임스페이스를 분리하여 접근하도록 할 수 있을까요?
아이디어 1 : 🚫 Fake 객체로 오버라이딩
처음 생각한 방법은 테스트에서 Fake 객체를 사용해 구현을 오버라이딩하는 것이었습니다.
public class ElasticsearchRepository {
protected Mono<ElasticResult<DocumentHit>> internalSearch(SearchSourceBuilder searchSourceBuilder, IndexType indexType) {
String indexName = getIndexName(indexType) // <<< 여기 부분이 메서드 추출되었다.
return EsSearchClient.inquire(indexName, searchSourceBuilder)
.map(searchResponse -> ElasticResult.fromResponse(searchResponse))
.onErrorResume(e -> {
log.error("[ElasticsearchRepository][internalSearch] failed to search; indexType={}", indexType, e);
return Mono.just();
});
}
protected String getIndexName(IndexType indexType) {
return indexType.getSearchAlias();
}
}운영 코드를 위와 같이 수정했습니다. getIndexName()으로 alias를 얻는 메서드를 추출했습니다. 오버라이딩이 가능한 구조로 바꿔주기 위함인데요. 이제 테스트 코드 내에서 Fake 객체를 다음과 같이 구현해 주면 됩니다.
public class TestMainElasticsearchRepository extends ElasticsearchRepository {
@Override
public String getIndexName(IndexType indexType) {
return TestIndexNameFactory.attachAliasPrefix(indexType.getSearchAlias()); // <<< 인덱스 고유 네임스페이스를 이용한다.
}
}이렇게 TestMainElaisticsearchRepository라는 Fake 객체를 만들어 ElasticsearchRepository를 상속받아 네임스페이스 접근하도록 구현했습니다. 이제 테스트 코드 내에서는 ElasticsearchRepository 대신 TestMainElasticsaerchRepository를 사용하면 됩니다. 그러나 이 방법을 사용하다 보니 몇 가지 문제점이 있었습니다.
문제점 1 : ESClient에 직접 호출하는 테스트에서는 prefix를 직접 붙여야 한다.
@Test
@DisplayName("주어진 아이디 중 삭제된 문서의 아이디를 찾아내는 기능 테스트")
void findDeletedIds() {
// given
SearchDocument document = SearchDocument.builder()
.content(testContent())
.build();
String str = objectMapper.writeValueAsString(document);
IndexRequest indexRequest = new IndexRequest()
.index(TestIndexNameFactory.attachAliasPrefix(TEST_SHOP.getSearchAlias())) // <<< 네임스페이스 명시가 필요하다
.source(str, XContentType.JSON)
.id("123");
ES_CLIENT.indexDocument(indexRequest).block();
ES_CLIENT.refresh(new RefreshRequest(TestIndexNameFactory.attachAliasPrefix(TEST_SHOP.getSearchAlias()))).block(); // <<< 네임스페이스 명시가 필요하다
// when
Set<String> deletedIds = elasticsearchRepository.findDeletedIds(TestIndexNameFactory.attachAliasPrefix(TEST_SHOP.getSearchAlias()), Set.of("123", "456", "789")).block(); // <<< 네임스페이스 명시가 필요하다
// then
assertThat(deletedIds).containsExactlyInAnyOrder("456", "789");
}위 테스트에서는 ElasticsearchRepository를 통해 ES 작업을 수행하는 것이 아닌 ES_CLIENT에 직접 호출합니다. 이런 테스트에서 네임스페이스를 명시하려면 attachAliasPrefix()로 감싸야 합니다. 만일 개발자가 attachAliasPrefix()를 빼먹는다면 테스트가 실패할 가능성이 있습니다.
문제점 2 : 운영 코드는 생각보다 복잡하다.
실제 운영 코드는 복잡합니다. ElasticsearchRepository 같은 클래스가 여러 개 있으며, 각 클래스는 저마다 다른 alias에 접근하도록 로직이 작성되어 있습니다. 따라서 Fake 오버라이딩 방법을 사용하면 모든 클래스에 대해 이와 같은 수정을 해야 합니다.
public class TestCommerceElasticsearchCommander extends CommerceElasticsearchCommander {
// 다양한 alias에 접근하는 메서드들을 모두 override 해야 한다.
@Override
protected String getAnalyzeAlias(IndexType indexType) {
return attachAliasPrefix(super.getAnalyzeAlias(indexType));
}
@Override
protected String getIndexNamePrefix(IndexType indexType) {
return attachIndexPrefix(super.getIndexNamePrefix(indexType));
}
@Override
protected String getAnalyzeComparisonAlias(IndexType index) {
return attachAliasPrefix(super.getAnalyzeComparisonAlias(index));
}
// ... 다른 메서드들도 동일하게 처리
}
위 코드처럼 여러 alias에 접근하는 CommerceElasitcsearchCommander의 경우 테스트 코드를 위한 메서드 추출로 인해 운영 코드의 복잡도도 매우 높아지고, 새로운 alias 접근이 생길 때마다 Fake 객체에서의 수정이 잦아질 것입니다.
public class ElasticsearchRepository {
protected Mono<ElasticResult<DocumentHit>> internalSearch(SearchSourceBuilder searchSourceBuilder, IndexType indexType) {
String indexName = indexType.getSearchAlias(); // <<<< 이렇게 getIndexName() 이 구현되어있음에도 직접 넣는 경우가 생긴다면??
return EsSearchClient.inquire(indexName, searchSourceBuilder)
.map(searchResponse -> ElasticResult.fromResponse(searchResponse))
.onErrorResume(e -> {
log.error("[ElasticsearchRepository][internalSearch] failed to search; indexType={}", indexType, e);
return Mono.just();
});
}
protected String getIndexName(IndexType indexType) {
return indexType.getSearchAlias();
}
}위 코드처럼 개발자가 실수로 메서드 추출했음에도 기존 방식대로 IndexType.getSearchAlias()로 접근하면 테스트는 격리된 네임스페이스에 접근하지 못해 실패할 것입니다.
Fake 객체로 접근 로직을 오버라이딩하는 방법은 운영 코드의 복잡도를 높이고 실수의 가능성을 증가시키므로 적합하지 않습니다.
아이디어 2 : ✅ Setter 활용
Fake 객체를 사용하는 아이디어는 확실하지만 코드의 복잡도, 실수의 여지 때문에 매우 사용하기 어려웠습니다. 팀원들과 논의한 끝에 IndexType 구현체가 enum이라는 특징을 활용하기로 했습니다. enum은 객체를 딱 한 번 생성하고 사용하는 싱글톤 인스턴스입니다. 싱글톤이므로 같은 JVM 프로세스라면 동일한 인스턴스를 호출합니다. 다음과 같이 구현을 변경해 보겠습니다.
public interface IndexType {
TenantType getTenantType();
String getSchemaName();
String getPrefix(); // <<<< 새로 추가됨!
default String getSearchAlias() {
return getPrefix() + "-main";
}
// ...
}@Getter
public enum RealIndexType implements IndexType {
BAEMIN_MART( TenantType.BAEMIN_MART),
COMMERCE(TenantType.COMMERCE),
// ... 더 많은 인덱스 타입들
;
private final TenantType tenantType;
private final String schemaName;
@Setter
private String prefix; // <<<< 새로 추가됨!
RealIndexType(TenantType tenantType) {
this.tenantType = tenantType;
this.schemaName = getTenantType().name().toLowerCase().replaceAll("_", "-");
this.prefix = schemaName; // 운영 코드에서는 schemaName과 동일하도록 설정
}
}prefix라는 새 변수를 추가하고 이에 @Setter를 붙여 세터 메서드를 가지도록 설정했습니다. 운영에서는 prefix 변수에 schemaName을 그대로 설정해 기존과 동일하게 동작하도록 했습니다.
public class ElasticsearchContainerExtension implements BeforeAllCallback{
@Override
public void beforeAll(ExtensionContext context) throws Exception {
setAliasPrefixForTest(); // <<< 추가!
createContainerIfNotStarted();
createIndex();
}
private void setAliasPrefixForTest() {
Arrays.stream(RealIndexType.values())
.forEach(index -> index.setPrefix(TestIndexNameFactory.attachAliasPrefix(index.getPrefix())));
}
}테스트 코드에서는 ElasticsearchContainerExtension에서 setAliasPrefixForTest()를 통해 prefix를 네임스페이스가 붙은 prefix로 변경합니다. 이렇게 하면 Fake 객체를 오버라이딩하지 않아도 원하는 네임스페이스의 인덱스에 접근할 수 있습니다.
위와 같이 enum에서 setter를 사용하는 방법은 운영 코드에서 enum의 불변성을 깨뜨릴 우려가 있지만, 팀 내 합의가 이루어졌고, setter를 사용함으로써 얻는 이점이 더 크기 때문에 적용하기로 했습니다.
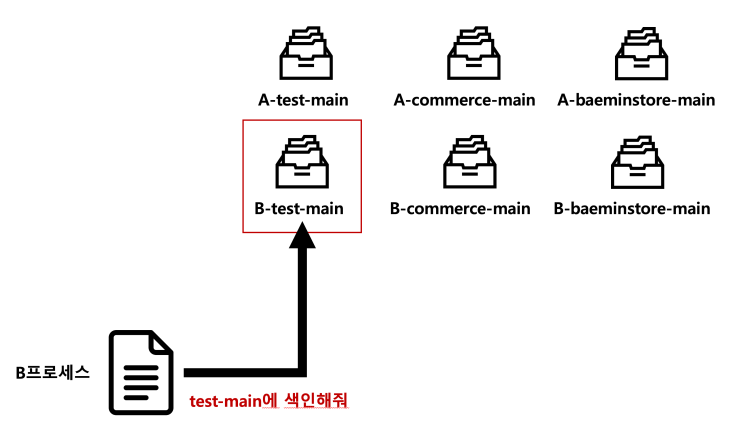
이제 setter를 활용해 적절한 네임스페이스의 인덱스로 접근을 할 수 있습니다. 위 그림처럼 B 프로세스에서는 test-main에 문서를 색인해달라는 요청이 들어올 경우 B-test-main에 문서를 색인할 수 있습니다. 이제 ES에 대한 격리가 이루어져 병렬 테스트가 가능합니다.
남아 있는 문제점들 🦖
저희는 ES의 인덱스 생성 문제를 네임스페이스 전략을 통해 해결하고, 인덱스 접근의 문제를 Setter 도입으로 해결했습니다. 공유 의존성에 대한 격리를 이루어냈으니 병렬로 테스트가 가능하겠죠. 하지만 병렬 테스트를 실행해 보니 생각과는 달리 실패하는 모습을 보였습니다. 무슨 문제였을까요?
SQL Connection 이슈
문제는 ES가 아닌 RDB에서 발생했습니다. 바로 Too Many Connections 오류가 발생했습니다. 순차적으로 돌렸을 때는 발생하지 않았으나 병렬로 테스트를 돌렸을 땐 해당 오류가 나타났습니다.
-
docker-compose.yml
mysql: image: mysql:5.7 environment: - MYSQL_DATABASE=... - MYSQL_ROOT_PASSWORD=... - TZ=Asiz/Seoul ports: - 3366:3306 volumes: - ./db/mysql-configure.cnf:/etc/mysql/conf.d/my.cnf # 이런식으로 my.cnf 내용을 지정해주게 되면 mysql 관련 설정을 변경할 수 있다. -
db/mysql-configure.cnf
[mysqld] max_connections = 500 # default는 151 로 설정되어있음커넥션 수가 한계를 넘어섰다는 오류이기 때문에 위처럼 테스트에서 사용하는 커넥션 수를 늘리면 해결됩니다. 하지만 근본적인 원인은 HikariCP에 있었습니다.
datasource:
hikari:
connection-timeout: 3000 #3s
max-lifetime: 50000 #50s
maximum-pool-size: 10기존에 문제가 발생하던 HikariCP 설정입니다. 프로세스가 시작되면 minimum-idle을 따로 설정해 주지 않아서 default로 maximum-pool-size로 설정되기 때문에 당장 사용하지 않더라도 10개의 커넥션을 잡아버리게 됩니다. 병렬로 실행되면 각 프로세스마다 10개씩 커넥션을 잡아 DB 커넥션 한도를 초과하게 됩니다. 저는 테스트에서 한 프로세스에 대한 동시 요청이 많지 않기 때문에 minimum-idle을 설정하여 idle 상태의 커넥션 수를 조절했습니다.
datasource:
hikari:
connection-timeout: 3000 #3s
max-lifetime: 50000 #50s
maximum-pool-size: 5
minimum-idle: 1 # <- minimum-idle을 설정!위와 같이 설정하면 테스트 실행 시 최소 1개의 커넥션만 잡게 되어 DB 커넥션 한도를 초과하지 않게 됩니다.
ES 서킷브레이커 열리는 문제
기존 테스트용 인덱스를 관리하는 방식은 테스트에 사용될 모든 인덱스를 생성하고 이를 공용으로 사용하는 구조였습니다. 하지만 병렬 테스트 도입으로 인해 각각의 프로세스마다 인덱스를 생성하게 됩니다. 기존 로직에 클린업 메서드가 없었기 때문에 테스트를 돌릴 때마다 클러스터에 많은 인덱스가 남아 있었습니다.
인덱스가 남아있으면 아래와 같은 큰 문제점이 발생하게 되는데요.
- ES 클러스터에 너무 많은 인덱스가 쌓여 처리 성능이 급격하게 떨어짐 = 테스트 성능 하락
- 인덱스가 많아지면 메모리 사용량이 증가해 서킷 브레이커가 열려 클러스터를 사용하지 못함 = 테스트 실패
이 문제를 해결하기 위해 클린업 정책을 추가하고 필요한 인덱스만 생성하도록 수정해야 했습니다.
클린업 정책 추가
클린업 정책을 추가하는 것은 간단합니다. 이미 Extension을 사용하고 있기 때문입니다.
public class ElasticsearchContainerExtension implements BeforeAllCallback, AfterAllCallback {
@Override
public void afterAll(ExtensionContext extensionContext) throws Exception {
IndexCreator.deleteIndices("*" + TestIndexNameFactory.RANDOM_UUID + "*");
}
}위 코드와 같이 AfterAllCallback 을 추가로 상속받아 하나의 테스트 클래스의 모든 테스트가 끝났을 경우 해당 네임스페이스의 모든 인덱스를 삭제하도록 합니다. 이제 모든 테스트가 끝난 후 생성된 인덱스가 모두 지워져 서킷브레이커 문제를 피할 수 있습니다.
필요 인덱스만 생성되도록 수정
하지만 위 클린업 메서드만 추가하면 많은 양의 인덱스를 생성하고 삭제하는 작업을 반복하게 됩니다. 오히려 테스트 성능이 악화될 수 있습니다. 따라서 테스트마다 필요한 인덱스만 생성하도록 제한을 걸어주는 작업이 필요합니다. @Tag 애노테이션을 이용하여 필요 인덱스를 지정해주도록 했습니다.
@ExtendWith(ElasticsearchContainerExtension.class)
@Tag(COMMERCE_TEST)
class TestExample {
...
}public class ElasticsearchContainerExtension implements BeforeAllCallback, AfterAllCallback{
@Override
public void beforeAll(ExtensionContext context) throws Exception {
if (isEmpty(context.getTags())) {
throw new IllegalArgumentException("테스트에 생성해서 사용할 인덱스를 클래스의 태그(@Tag)로 지정해주세요.");
}
setAliasPrefixForTest();
createContainerIfNotStarted();
createIndex(context.getTags()); // 추가!!
}
private void createIndex(Set<String> tags) {
tags.stream()
.map(ElasticsearchIndexCreation::toCreation)
.forEach(ElasticsearchIndexCreation::create);
}
}위처럼 테스트 클래스에 @Tag로 지정한 값을 ElasticsearchContainerExtension에서 beforeAll 메서드의 인자인 context에서는 꺼낼 수 있습니다. 이를 통해 테스트 코드에서 필요한 인덱스를 @Tag로 지정하도록 수정했습니다. 또, ElasticsearchContainerExtension 을 사용하는 테스트에 태그가 지정되지 않으면 테스트가 실패하도록 설정해 실수를 방지했습니다. 이제 테스트마다 필요한 인덱스만 생성하도록 설정할 수 있습니다.
추가로 ElasticsearchIndexCreation의 구현을 살펴보도록 하겠습니다.
public enum ElasticsearchIndexCreation {
NO_CREATION(() -> {}),
COMMERCE_CREATION(() -> IndexCreator.createIndex(COMMERCE)),
BAEMINMART_CREATION(() -> IndexCreator.createIndex(BAEMINMART)),
// ...
;
private final IndexCreateFunction function;
ElasticsearchIndexCreation(IndexCreateFunction function) {
this.function = function;
}
public void create() {
function.doCreate();
}
public static ElasticsearchIndexCreation toCreation(String tag) {
try {
return ElasticsearchIndexCreation.valueOf(tag);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("주어진 태그로 인덱스 생성 정책을 만들 수 없습니다. [tagName: " + tag + "]");
}
}
@FunctionalInterface
private interface IndexCreateFunction {
void doCreate();
}
public static class Tag {
public static final String NO_CREATION_TEST = "NO_CREATION";
public static final String COMMERCE_TEST = "COMMERCE_CREATION";
public static final String BAEMINMART_TEST = "BAEMINMART_CREATION";
// ...
}
}태그에 대한 생성 전략은ElasticsearchIndexCreation의 enum 객체들이 가지고 있습니다. 함수형 인터페이스를 활용해 저마다의 생성 전략을 가지게 했습니다. 하지만 JUnit에서 제공하는 @Tag는 String만 인자로 받기 때문에 이를 전략과 연결해 줄 ElasticsearchIndexCreation.Tag 이너 클래스를 선언하고 상숫값을 담아놓았습니다.
하지만 @Tag의 인자 제약조건 때문에 생성 전략과 상수가 느슨하게 연결되어 실수를 유발할 수 있습니다. 만약 enum이나 상숫값이 변경되면 테스트가 실패할 수 있죠. 이를 방지하기 위해 코드에 대한 제어를 강화하기로 했습니다.
public enum ElasticsearchIndexCreation {
NO_CREATION(() -> {}),
COMMERCE_CREATION(() -> IndexCreator.createIndex(COMMERCE)),
BAEMINMART_CREATION(() -> IndexCreator.createIndex(BAEMINMART)),
// ...
;
private final IndexCreateFunction function;
ElasticsearchIndexCreation(IndexCreateFunction function) {
this.function = function;
Tag.validate(this.name()); // enum 인스턴스 생성 시점에 인스턴스의 이름과 일치하는 상수가 Tag에 정의되어 있는지 확인한다.
}
public static class Tag {
public static final String NO_CREATION_TEST = "NO_CREATION";
public static final String COMMERCE_TEST = "COMMERCE_CREATION";
public static final String BAEMINMART_TEST = "BAEMINMART_CREATION";
// ...
// 아래부터 추가된 코드!
private static void validate(String creationName) {
if (containsTag(creationName)) {
return;
}
throw new IllegalArgumentException("인덱스 생성 정책에 맞는 ElasticsearchIndexCreation.Tag를 정의해야합니다. [creationName: " + creationName + "]");
}
private static boolean containsTag(String name) {
return Arrays.stream(Tag.class.getDeclaredFields())
.map(Tag::convertToString)
.anyMatch(fieldName -> fieldName.equals(name));
}
private static String convertToString(Field field) {
try {
return (String) field.get(null);
} catch (IllegalAccessException e) {
throw new RuntimeException("Failed to access field value", e);
}
}
}
}위 코드에서는 ElasticsearchIndexCreation.Tag에서 validate를 수행하는 코드가 추가되었습니다. 주어진 creationName이 실제 Tag 이너 클래스의 상수로 있는지를 자바 리플렉션을 통해 확인합니다. 전략과 매칭되는 상수가 없을 경우 에러를 발생시킵니다. 이를 통해 코드 수정으로 인한 전략 매칭 실패를 방지할 수 있습니다.
여정의 마무리 🎁

남았던 문제를 해결하다 보니 드디어 파이프라인이 정상적으로 완료되었습니다. 그동안의 여정을 돌아보면 아래와 같습니다.
- 공유 의존성의 격리 문제로 병렬 테스트가 실패했습니다.
- ES 인덱스 생성 시 발생한 동시성 이슈를 네임스페이스 전략으로 해결했습니다.
- 후보 : 스레드 락, 분산락, 네임스페이스 전략 ✅
- 네임스페이스로 지정한 ES 인덱스에 접근하지 못하는 문제를 Setter 도입으로 해결했습니다.
- 후보 : Fake 오버라이딩 전략, Setter 전략 ✅
- 격리 이후 남아있는 문제들을 `HikariCP 설정`, `클린업 정책 도입`, `@Tag`를 통해 해결했습니다.이제 병렬 테스트가 얼마나 성능 향상에 도움을 주었는지 확인해 보겠습니다.
AS-IS ( 병렬 테스트 이전)

- 로컬 기준 4m 5s
- CI/CD 기준 10m 41s
TOBE (병렬 테스트 적용)

- 로컬 기준 1m 48s
- CI/CD 기준 5m 3s
gradle scan을 이용해서 병렬테스트 전후의 결과를 비교해 보았습니다. 결과적으로 로컬과 CI/CD 환경 모두 기존 대비 2배 이상의 테스트 수행 성능 향상을 이루었습니다. 병렬 테스트만 도입했을 뿐인데 성능 향상이 커서 꽤나 달콤한 성과입니다. 아직 수행 시간을 보면 더 최적화해볼 여지가 있어 보입니다. 앞으로도 지속적으로 테스트 환경을 최적화하고 개선해 나갈 것입니다.
이번 프로젝트는 저 혼자의 힘이 아닌 팀원들의 협력과 지원 덕분에 가능했습니다. 함께 고민하고 해결책을 찾아가는 과정에서 많은 것을 배울 수 있었고, 이는 앞으로의 도전에 큰 자산이 될 것입니다. 이 자리를 빌려 함께해 준 모든 팀원들에게 감사의 인사를 전합니다. 앞으로도 성장하며 더 나은 성과를 이루어 나가길 기대합니다.
