실시간 반응형 추천 개발 일지 1부: 프로젝트 소개
배민 앱에서 "OOO 님을 위한 맞춤 맛집", "OOO 님에게 추천하는 상품"과 같은 추천 영역을 마주친 적 있으신가요?
추천프로덕트팀은 배민, B마트, 배민스토어 등 우아한형제들의 다양한 서비스에 추천 서비스를 제공하는 팀으로, 사용자들이 원하는 가게, 메뉴, 상품, 셀러 등을 쉽고 빠르게 찾을 수 있도록 돕고 있습니다.
2023년 12월, 추천프로덕트팀은 사용자의 실시간 행동 이력을 활용하여 가게를 추천하는 실시간 반응형 추천 시스템을 도입했습니다. 그리고 A/B 테스트 결과, 노출 대비 주문 전환율이 기존 추천 방식 대비 약 40% 상승했습니다.
이번 글에서는 실시간 반응형 추천 시스템의 개발 배경 및 설계, 시스템 구성 등을 개괄적으로 소개하겠습니다. 이 시스템을 위해 새롭게 도입한 실시간 데이터 스트리밍 파이프라인, 벡터 유사도 검색, 컨텐츠 기반 인코더 모델과 같은 개별 컴포넌트에 대한 내용은 후속 글을 통해 더 자세하게 다룰 예정이니 기대해주세요.
기존 추천 방식 소개
실시간 반응형 추천 시스템을 소개하기에 앞서 기존 추천 방식을 먼저 알아보겠습니다.
배민 앱에서 검색 버튼을 누르면 검색 홈 화면으로 이동하는데요, 이 곳에 "검색 홈 큐레이션" 영역이 위치하고 있습니다. "OOO님을 위한 맞춤 맛집" 이라는 제목을 가진 이 영역은 사용자가 좋아할만한 가게를 추천해줍니다.

검색 홈 화면에 위치한 검색 홈 큐레이션 영역
기존 "검색 홈 큐레이션" 영역은 Two Tower 모델(사용자와 아이템 각각을 표현하는 임베딩 타워를 구성한 후 임베딩간의 유사도를 구하는 모델)을 기반으로 개인화 추천을 제공했습니다. 이 모델은 사용자의 주문 이력을 학습 데이터로 사용하여 사용자와 가게 간의 유사도를 파악합니다.

Two Tower Model 구조. (hackernoon)
전체적인 파이프라인은 다음과 같은 순서로 동작합니다:
- 사용자의 주문 이력을 학습 데이터로 사용하여 Two Tower 모델을 학습시킵니다.
- 사용자 정보와 추천 후보 가게 목록을 모델에 입력하면 모델은 사용자와 각 가게 간의 유사도 스코어를 응답합니다. 이 스코어를 활용하여 추천 후보 가게 목록을 정렬합니다.
- 하루에 한 번 오프라인 배치 방식으로 사용자별 추천 가게 목록을 추출하여 MongoDB에 저장합니다.
- 추천 API 서버가 MongoDB를 조회하여 추천 가게 목록을 응답합니다.

전체 파이프라인 구성. ([우아콘 2023] 추천시스템 성장 일지: 데이터 엔지니어 편)
기존 방식의 한계
Two Tower 모델 기반의 오프라인 배치 방식은 사용자의 전반적인 음식 취향을 잘 파악하여 추천을 제공합니다. 실제로 이 방식은 추천 도입 이전과 비교했을 때 60% 이상 높은 노출 대비 주문전환율(100명의 사용자에게 추천을 제공했는데 그 중 10명의 사용자가 추천 가게를 클릭한 후 음식을 주문했다면 노출 대비 주문전환율은 10%)을 보여주고 있습니다.
하지만 사람의 마음은 하루에도 몇 번씩 바뀝니다. 평소 햄버거를 즐겨 먹는 사람도 가끔 샐러드를 먹고 싶을 때가 있고, 다이어트를 하는 사람도 가끔 피자를 시켜 먹습니다.
오프라인 배치 형태로 미리 추천 가게를 추출하는 기존 방식은 이런 마음의 변화를 즉각적으로 추천에 반영하는 것이 불가능했습니다.
문제 상황 예시
- 비 오는 날에 갑자기 파전을 먹고 싶어진 사용자
- 식사 주문 후 디저트를 추가로 주문하고 싶은 사용자
- 패스트푸드만 먹다가 갑자기 다이어트를 시작한 사용자
실시간 반응형 추천 시스템
어떻게 하면 짜장면을 먹고 싶은 사용자에게 중식 가게를, 아이스 아메리카노가 갑자기 당기는 사용자에게 카페를 추천해 줄 수 있을까요?
우리는 사용자의 관심사를 실시간으로 파악하고, 이 관심사에 맞춰 추천을 제공하는 시스템을 만들어보기로 했습니다. 그리고 이를 위해 세 가지 새로운 컴포넌트를 개발했습니다.
- 컴포넌트 1. 실시간 행동 이력 스트리밍
- 사용자의 관심사, 의도를 파악하기 위해 행동 이력을 실시간으로 스트리밍하는 파이프라인을 구축했습니다.
- 사용자가 클릭한 가게나 검색한 검색어 등의 행동 이력을 실시간으로 스트리밍하여 MongoDB에 적재합니다.
- 실시간 행동 이력 조회 API를 통해 MongoDB에 적재된 사용자의 행동 이력을 조회합니다.
- 컴포넌트 2. 인코더 모델 학습 및 임베딩 추출
- 가게와 검색어를 동일한 벡터 공간에 임베딩 형태로 표현하는 인코더 모델을 개발했습니다.
- 가게의 메타 정보와 검색 로그 등을 활용하여 가게와 검색어가 유사할수록 더 가까운 벡터 공간에 위치하도록 인코더 모델을 학습시켰습니다.
- 학습된 인코더 모델로 가게 및 검색어의 임베딩을 추출하고, 이를 ‘벡터 유사도 검색 컴포넌트’가 사용하는 VectorDB에 업로드했습니다.
- 컴포넌트 3. 벡터 유사도 검색
- 사용자의 행동 이력과 추천 후보 가게 간의 유사도를 계산합니다.
- 사용자의 행동 이력과 추천 후보 가게 목록이 주어졌을 때 VectorDB에서 각각의 임베딩 값을 조회한 후, 이들 사이의 코사인 유사도를 계산하여 응답하는 컴포넌트를 개발했습니다.
이 시스템은 사용자의 현재 관심사와 의도에 실시간으로 반응하여 추천을 제공하기 때문에 우리는 이를 ‘실시간 반응형 추천 시스템’이라고 이름 붙였습니다.
시스템 구조
실시간 반응형 추천 시스템의 구조는 아래와 같습니다. 각 컴포넌트는 서로 다른 기술 스택과 인프라 위에 구성되어 있습니다.
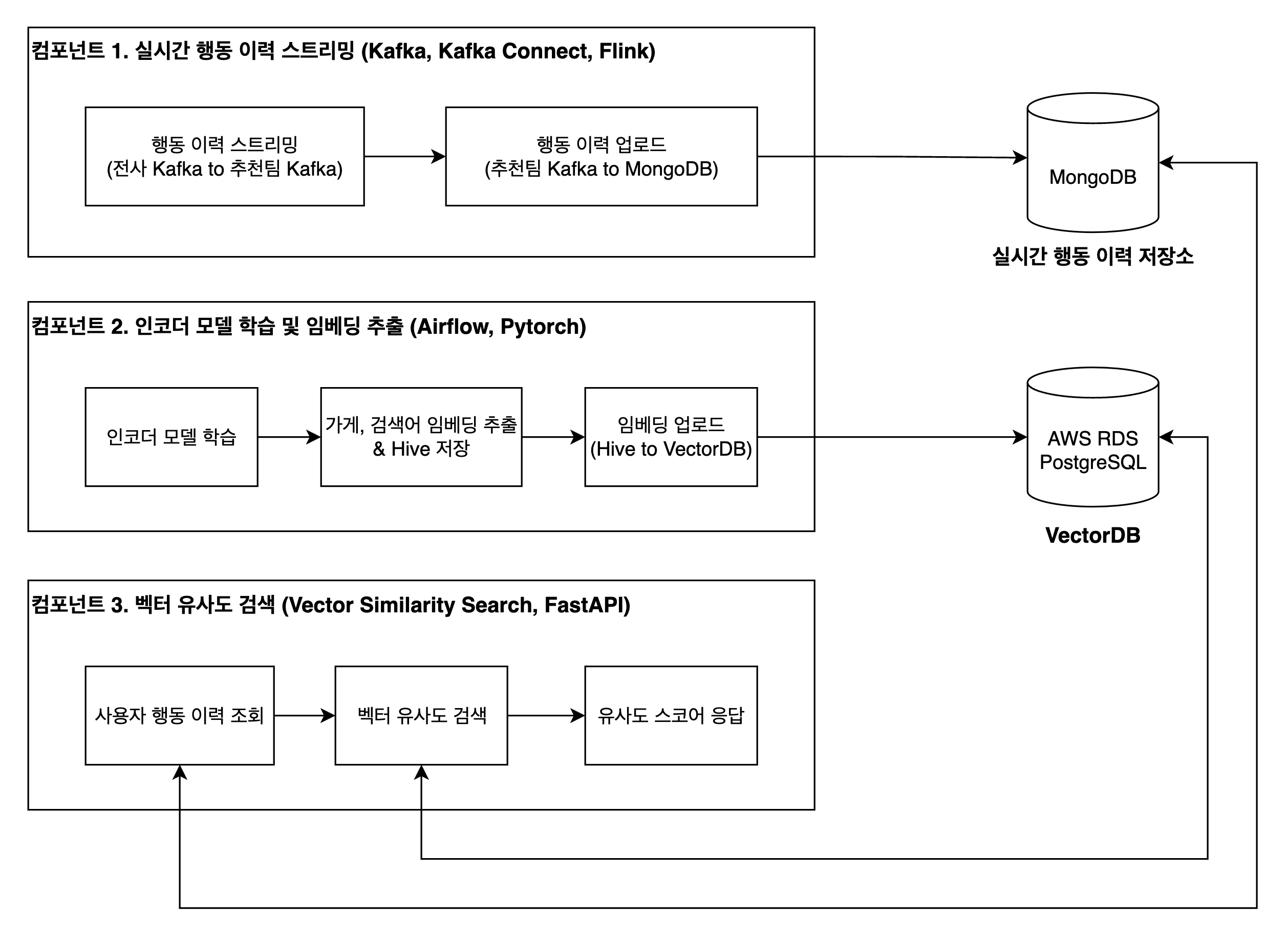
실시간 반응형 추천 시스템 구조
서비스 관점에서는 전체 시스템을 두 단계로 구분할 수 있습니다.
1. 실시간 데이터 파이프라인
- 사용자가 배민 앱에서 검색어를 입력하거나 가게를 클릭하면 로그가 생성되고, 이 로그를 실시간으로 스트리밍하여 MongoDB까지 전달합니다.
2. 추천 서빙
- 사용자가 배민 앱에서 "검색 홈 화면"에 진입했을 때 "검색 홈 추천 API"로의 요청이 발생합니다.
- "검색 홈 추천 API"는 "행동 이력 조회 API"로부터 사용자의 실시간 행동 이력을 조회합니다.
- 이후, 오프라인 배치 방식으로 미리 만들어둔 Two Tower 모델 추천 가게 목록을 조회합니다.
- 마지막으로 "벡터 유사도 검색 API"에 유사도 스코어 계산을 요청합니다.
- 추천 가게 목록을 유사도 스코어 순으로 정렬하여 응답합니다.
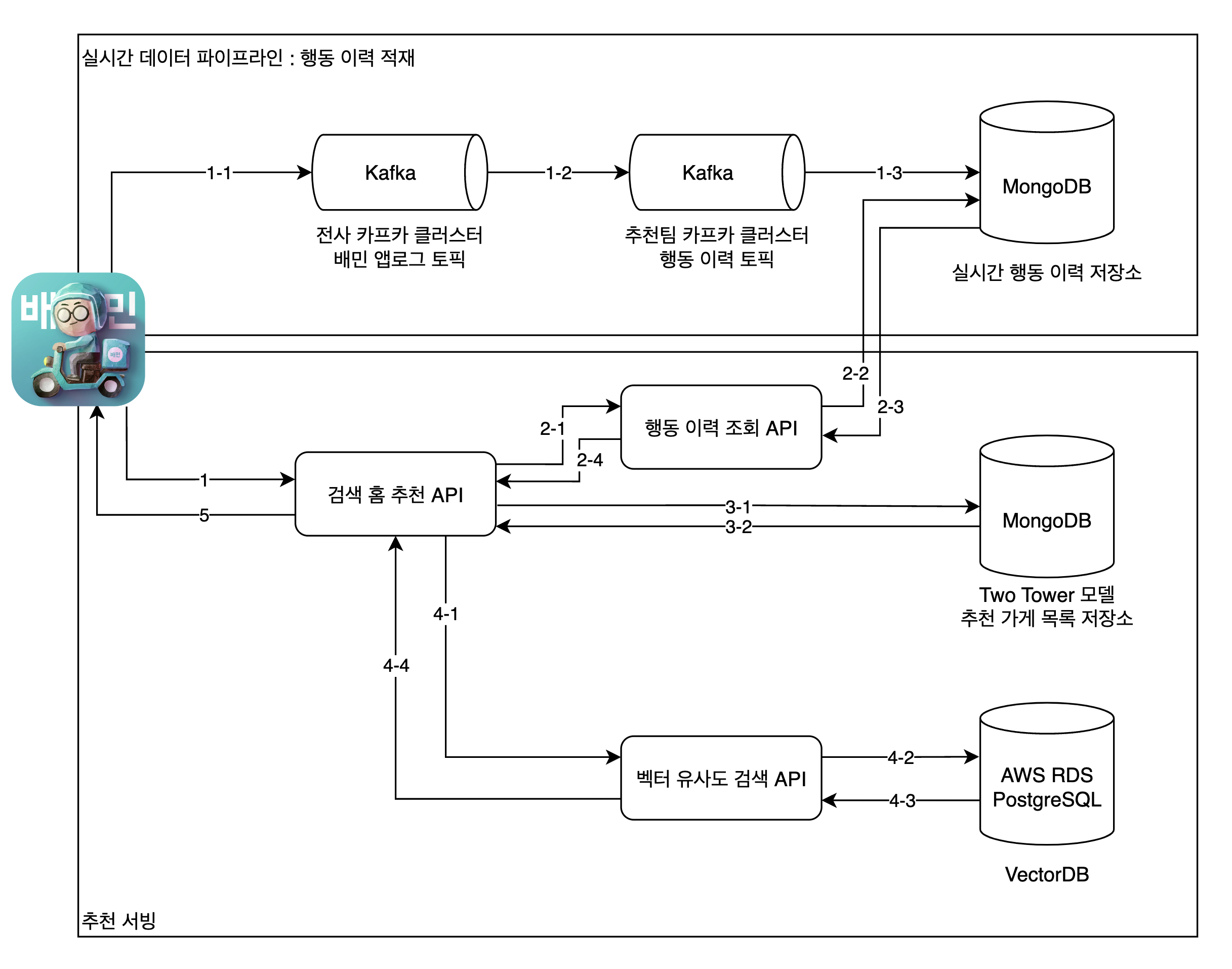
개별 컴포넌트 소개
이제 실시간 반응형 추천 시스템을 구성하는 개별 컴포넌트들이 어떤 기능을 제공하는지, 어떤 방식으로 동작하는지를 살펴보겠습니다.
컴포넌트 1. 실시간 행동 이력 스트리밍
실시간 행동 이력 조회 스트리밍 컴포넌트는 사용자의 행동 이력을 실시간으로 적재 및 조회합니다. 실시간 데이터 스트리밍 파이프라인과 API 서버로 구성되어 있습니다.
이 컴포넌트는 다음과 같은 기능을 제공합니다.
- 특정 사용자가 최근 1시간 이내에 검색한 검색어를 조회
- 특정 사용자가 최근 1시간 이내에 클릭한 가게 목록을 조회
- 특정 세션이 최근 1시간 이내에 검색한 검색어와 클릭한 가게 목록을 조회
실시간 행동 이력 조회 컴포넌트는 아래와 같은 방식으로 동작합니다.
Step 1. 실시간 행동 이력 수집 및 적재
- Flink 애플리케이션을 통해 전사 카프카 클러스터 내 로그 토픽을 실시간으로 컨슈밍하여 추천프로덕트팀 카프카 클러스터 내 사용자 행동 이력 토픽으로 가져옵니다.
- 가져오는 과정에서 우리에게 필요 없는 메시지는 제거하고(필터링) 메시지 내용을 우리에게 필요한 포맷으로 변경합니다(트랜스포밍).
- Kafka Connect를 통해 추천프로덕트팀 카프카 클러스터 내 사용자 행동 이력 토픽을 실시간으로 컨슈밍하여 사용자 행동 이력 데이터를 MongoDB에 업로드합니다.
- MongoDB에 timestamp 필드를 기준으로 TTL(time to live)을 적용하여 일정 시간이 지난 행동 이력은 자동으로 삭제합니다.
Step 2. 실시간 행동 이력 조회
- 회원 번호 또는 세션 아이디를 입력받아 MongoDB에 저장된 행동 이력을 조회하여 응답합니다.

실시간 행동 이력 수집 및 적재 파이프라인 구조
컴포넌트 2. 인코더 모델 학습 및 임베딩 추출
이 컴포넌트는 유사한 가게와 검색어가 근처 벡터 공간에 위치하도록 검색 로그와 가게 메타데이터 등을 사용하여 인코더 모델을 학습시킵니다. 학습된 모델로부터 가게와 검색어에 대한 임베딩을 추출하여 VectorDB에 업로드합니다.
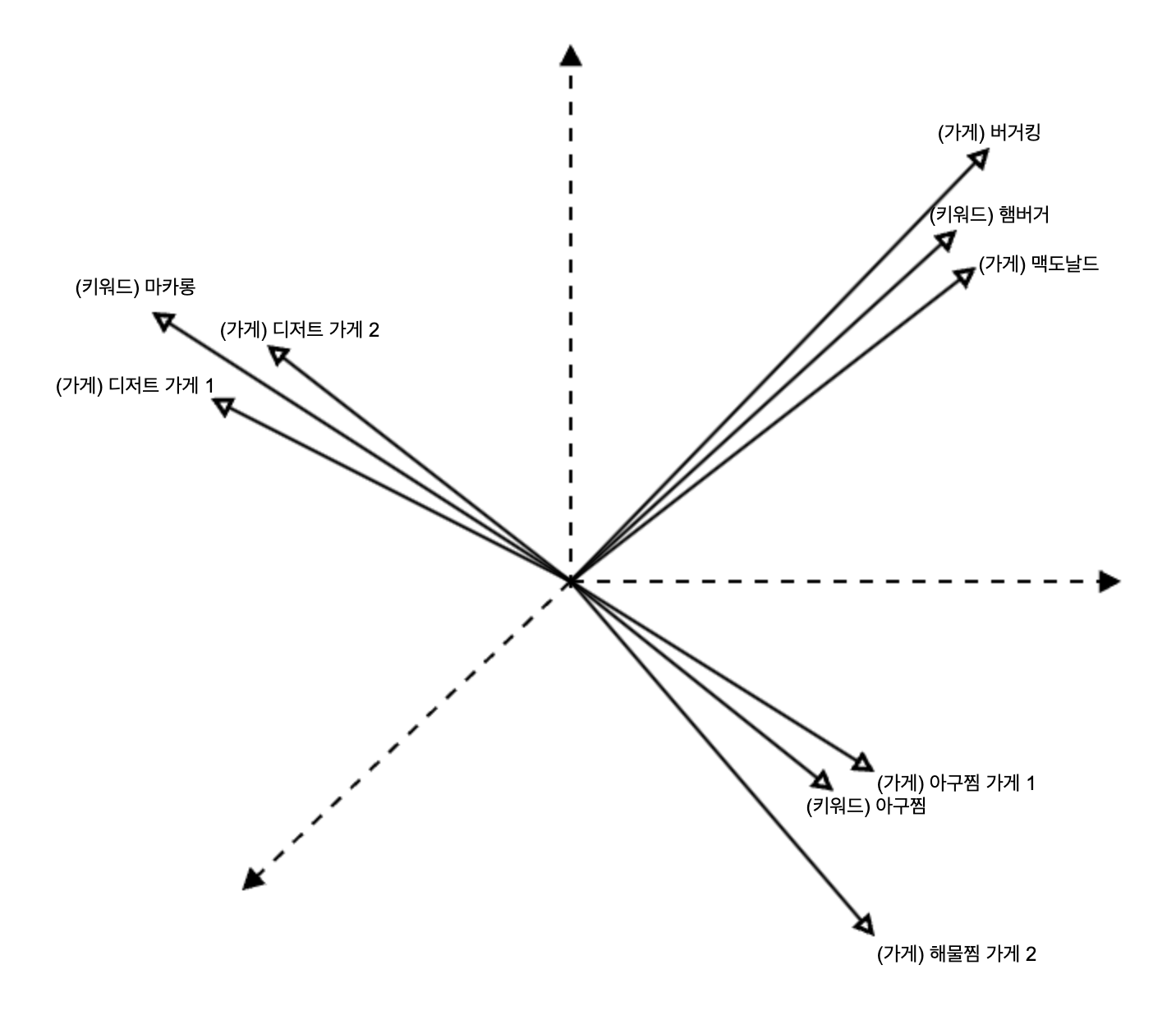
벡터 공간에 표현된 가게 및 키워드 임베딩
전체적인 과정은 아래와 같은 순서로 동작합니다. 모든 과정은 Airflow DAG 형태로 구성되어있으며 하루에 한 번 실행됩니다.
- 모델 학습 : 검색 로그, 가게 메타데이터 등을 사용하여 인코더 모델을 학습시킵니다. 학습 과정은 사내 On-Premise GPU 서버에서 수행됩니다.
- 모델 추론 : 임베딩 값을 생성할 검색어와 가게 목록을 인코더 모델에 입력하여 임베딩을 추출합니다. 이 과정 또한 사내 추출 과정 또한 사내 On-Premise GPU 서버에서 수행됩니다.
- 임베딩 업로드 : 추출한 임베딩 값을 벡터 유사도 검색 컴포넌트가 사용하는 VectorDB (RDS – PostgreSQL) 에 업로드합니다.
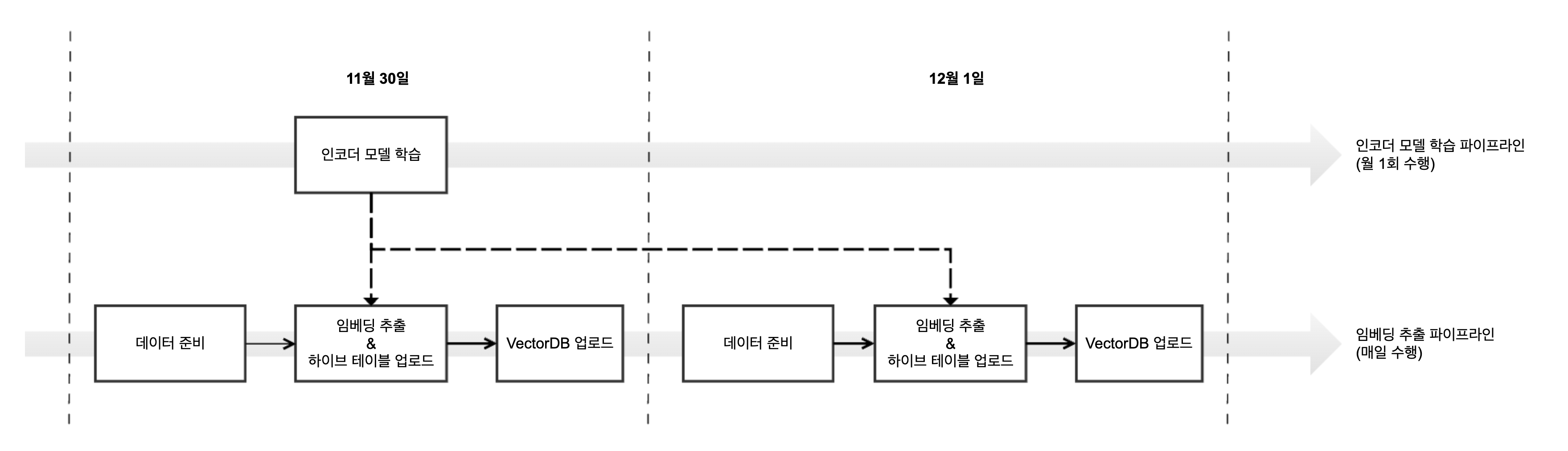
인코더 모델 학습 & 임베딩 추출 파이프라인
컴포넌트 3. 벡터 유사도 검색
사용자 행동 이력 임베딩과 각 추천 후보 가게 임베딩 간의 거리를 계산하여 응답하는 컴포넌트입니다. 임베딩 벡터 간의 거리가 가깝다는 것은 곧 두 임베딩이 유사하다는 것을 의미합니다. 이를 활용하여 사용자의 행동 이력과 추천 후보 가게 간의 유사도를 측정할 수 있습니다.
해당 컴포넌트를 사용하면 아래와 같은 시나리오를 지원할 수 있습니다:
- 주어진 N 개의 가게 중 특정 가게와 가장 유사한 가게를 추천
- 주어진 N 개의 가게 중 사용자가 방금 검색한 검색어와 가장 유사한 가게를 추천
- 주어진 N 개의 가게를 가장 잘 표현하는(유사한) 대표 키워드를 추천
추천프로덕트팀은 벡터 유사도 검색을 구현하기 위해 PostgreSQL와 pgVector를 사용했습니다.
벡터 유사도 검색(Vector Similarity Search – VSS)은 최근 LLM과 함께 많은 관심을 받는 기술입니다.
이렇게 벡터를 저장하고 검색, 관리할 수 있는 데이터베이스를 특별히 VectorDB라고 부릅니다. 이 글에서도 AWS RDS PostgreSQL 데이터베이스를 VectorDB라고 부르겠습니다.
가게 목록과 사용자가 검색한 검색어 간의 유사도를 계산하는 예시를 가지고 벡터 유사도 검색 과정을 함께 살펴보겠습니다.
(사전 준비) 임베딩 테이블을 준비합니다.
가게와 검색어에 대한 임베딩 테이블이 준비되어 있고, 각 테이블은 인덱싱되어 있습니다.
embedding칼럼은 pgVector의 vector 타입을 사용합니다.- 임베딩은 매일 업데이트됩니다. 해당 임베딩이 언제 생성되었는지를 나타내는
part_date칼럼을 사용합니다
(예시) 가게 임베딩 테이블
| shop_no | embedding | part_date |
|---|---|---|
| shop_no_1 | [-0.070946805,0.04897019, …] | 2024-06-16 |
| shop_no_2 | [-0.024124546,0.05294727, …] | 2024-06-16 |
| shop_no_3 | [-0.04311671,-0.05463976, …] | 2024-06-16 |
(예시) 검색어 임베딩 테이블
| search_keyword | embedding | part_date |
|---|---|---|
| 치즈볶음밥 | [-0.024124546,0.05294727, …] | 2024-06-16 |
| 아이스바닐라라떼 | [-0.04311671,-0.05463976, …] | 2024-06-16 |
| 크림찜닭 | [-0.070946805,0.04897019, …] | 2024-06-16 |
1. 벡터 유사도 검색 API에 벡터 유사도 검색 요청이 들어옵니다.
# 4개의 가게에 대해 "마라탕" 검색어와의 유사도 스코어를 계산
curl -X 'POST' \
'https://vector-similarity-search.host/v1/similarity/shops/keyword/cosine' \
-H 'Content-Type: application/json' \
-d '{
"keyword": "마라탕",
"candidates": [
"shop_no_1",
"shop_no_2",
"shop_no_3",
"shop_no_4"
]
}'2. 벡터 유사도 검색 API는 벡터 유사도 검색 쿼리를 생성하여 VectorDB에 전달합니다.
-- 코사인 유사도를 구하는 쿼리
SELECT
shop_no
, 1 - (embedding <=> '[0.1904833,0.22328706,-0.0675203, ...]') AS similarity
FROM baemin_feature_content_based_shop_embedding
WHERE shop_no IN('shop_no_1', 'shop_no_2', 'shop_no_3', 'shop_no_4')
ORDER BY similarity DESC
LIMIT 100위 쿼리를 보면 HNSW(그래프 기반 근사 최근접 검색 기술)이나 IVFFlat(Inverted File Flat) 같은 ANN(approximate nearest neighbor, 근사 최근접 이웃) 방식을 사용하지 않는 것을 알 수 있습니다.
ANN 방식을 사용하지 않고 Exact search 방식을 사용하는 이유는 사용자 주변에 위치한 N 개의 가게에 대해서만 벡터 유사도 검색을 수행해야 하기 때문입니다.
이와 관련된 성능 비교 실험 결과 등의 내용은 후속 글을 통해 공유해 드리겠습니다.
3. 벡터 유사도 검색 API가 쿼리 수행 결과를 후처리하여 응답합니다.
{
"shops": [
{
"shopNo": "shop_no_3",
"score": 0.575612 // shop_no_3 가게가 "마라탕" 키워드와 가장 높은 유사도를 보임
},
{
"shopNo": "shop_no_4",
"score": -0.023846
},
{
"shopNo": "shop_no_2",
"score": -0.088934
},
{
"shopNo": "shop_no_1",
"score": -0.149144
}
],
// ...
}A/B 테스트
실시간 반응형 추천 시스템은 결국 주어진 가게 목록을 사용자의 행동 이력과 유사한 순서대로 재정렬하는 시스템입니다.
"어떻게 재정렬할 것인가" 도 중요하지만 "어떤 가게를 재정렬할 것인가, 어떤 가게를 후보로 사용할 것인가"도 중요합니다. 우리는 A/B 테스트를 위해 새로운 가게 후보를 사용하는 것이 아니라, 기존에 만들어놓은 Two Tower 기반 추천 가게 목록을 그대로 후보로 사용하기로 했습니다.
- A 그룹 : Two Tower 기반 추천 가게 목록 제공
- B 그룹 : Two Tower 기반 추천 가게 목록을 실시간 행동 이력 기반으로 재정렬하여 제공
- 행동 이력이 없으면 Two Tower 기반 추천 가게 목록을 제공
A/B 테스트 결과, B 그룹의 CTR(Click-through rate, 노출 수 대비 클릭 수 비율)이 A 그룹 대비 23% 상승하였고, 노출 대비 주문전환율은 40.24% 상승했습니다.
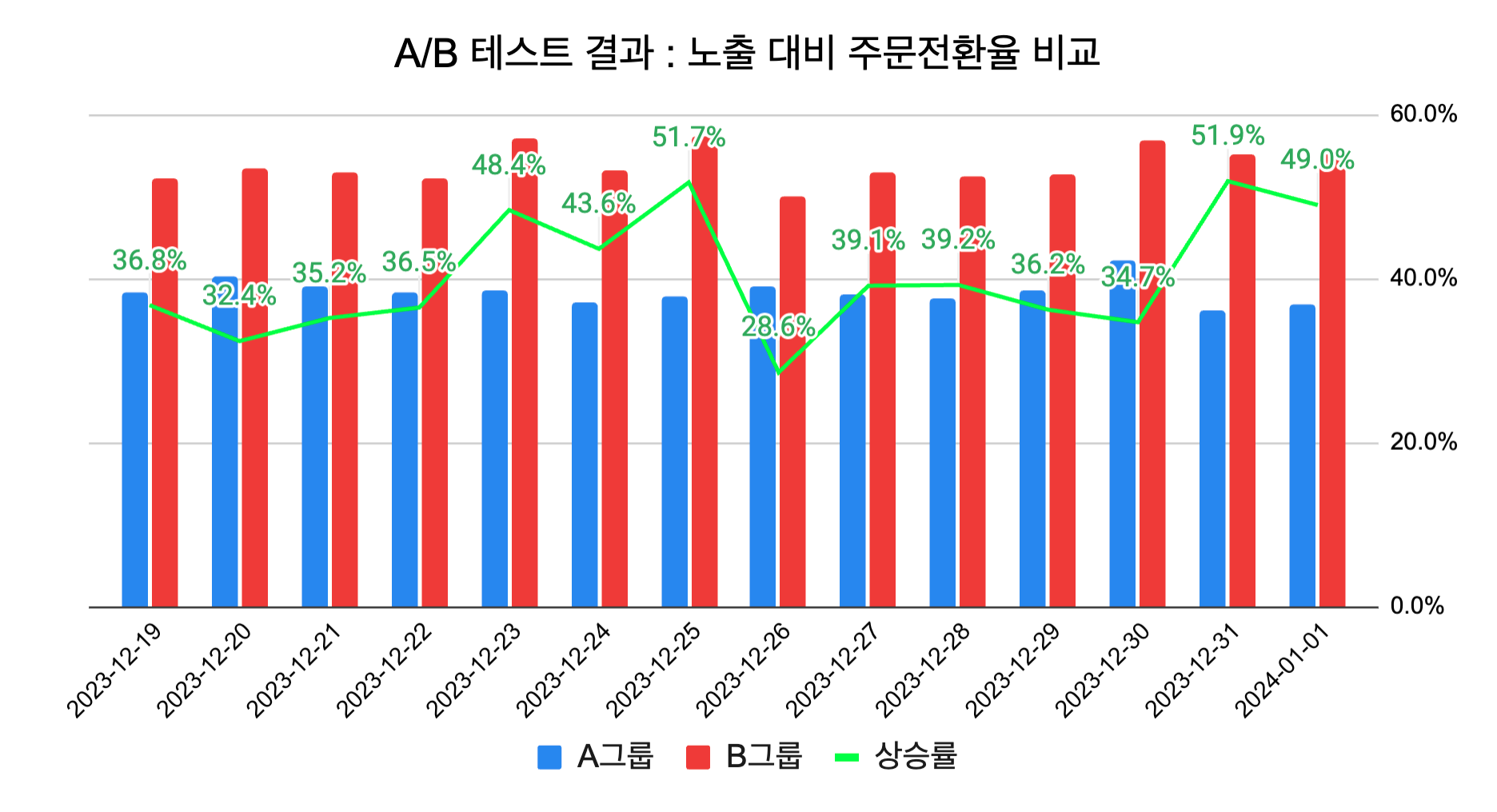
이 결과는 실시간 반응형 추천 시스템의 추천 결과가 사용자의 관심사와 잘 맞아떨어졌음을 보여줍니다. 특히 검색 홈 화면은 지면의 특성상 목적형 사용자가 많이 방문합니다. 이들에게 관심사에 맞는 가게를 추천함으로써 클릭과 주문으로 이어지는 비율이 높아진 것으로 보입니다.
교훈
이번 프로젝트를 진행하면서 몇 가지 중요한 교훈을 얻을 수 있었습니다
- 컴포넌트 기반 설계의 장점 1 – 개발 효율성
- 실시간 반응형 추천 시스템은 여러 컴포넌트로 구성되어 있습니다. 이번 프로젝트에서는 세 명의 엔지니어가 각각 하나의 컴포넌트를 담당하여 병렬로 개발을 진행했습니다. 컴포넌트 간의 인터페이스와 입력/출력 스펙을 명확하게 정의한 덕분에 병렬로 개발할 수 있었고, 2개월 만에 프로젝트를 완성했습니다.
- 컴포넌트 기반 설계의 장점 2 – 확장성
- 프로젝트를 시작할 당시에는 "검색 홈 큐레이션" 하나의 영역만을 위해 3개의 컴포넌트를 설계하고 개발했습니다. 그러나 프로젝트를 진행하면서 각각의 컴포넌트들이 독립적으로 다양한 프로젝트에 적용될 수 있다는 것을 깨달았습니다. 각 컴포넌트는 특정 기능에 집중하여 설계되었기 때문에 다른 서비스에도 쉽게 통합할 수 있었습니다. 현재 추천프로덕트팀의 다양한 서비스에서 이 컴포넌트들을 활용하고 있으며, 이를 통해 새로운 서비스 개발 시 중복 작업을 줄이고, 개발 속도를 높일 수 있었습니다.
- 실시간 데이터의 중요성
- 사용자 관심사는 시시각각 변합니다. 실시간 데이터를 기반으로 한 추천 시스템은 사용자들의 의도를 더 파악할 수 있으며, 이를 통해 더 높은 주문 전환율을 달성할 수 있음을 확인했습니다.
앞으로의 계획
프로젝트를 오픈한 지 벌써 6개월이 지났습니다. 6개월간 우리는 코드를 리팩토링하고 쿼리를 튜닝하는 등 시스템을 고도화했습니다. 또한 가게배달 추천, 검색 결과 등의 영역에 실시간 반응형 추천 시스템을 확대 적용했습니다. 앞으로도 지속적인 개선과 확장을 통해 더욱 정교하고 효율적인 추천 시스템을 구축할 계획입니다.
- 다양한 요소를 고려한 랭킹
- 이번 실험에서는 가게와 행동 이력 간의 유사도만을 활용하여 가게를 재정렬했습니다. 향후 랭킹 시스템에서는 유사도 외에도 다양한 피쳐들을 고려하여 더욱 정교한 추천을 제공할 계획입니다.
- 사용자 의도 파악 방안 모색
- 사용자의 의도를 더 정확하게 파악하기 위한 방법을 고민하고 있습니다. 현재는 사용자가 방금 클릭한 가게나 방금 검색한 검색어만을 사용하고 있지만, 이 외에도 사용자의 의도를 파악할 수 있는 다른 요소를 탐구하고 도입할 계획입니다. 예를 들어, 사용자의 브라우징 패턴, 장바구니 담기 행동, 특정 시간대의 활동 등을 분석하여 사용자를 더 깊게 이해하고자 합니다.
- 컴포넌트 성능 최적화
- 실시간 반응형 추천 시스템의 성능을 더욱 향상시키기 위해 각 컴포넌트의 성능을 모니터링 및 최적화하고 있습니다. 특히 사용량이 많은 벡터 유사도 검색 및 실시간 데이터 스트리밍 파이프라인의 성능 개선에 집중할 계획입니다.
- 컴포넌트 간 통신 방식 개선
- 시스템의 성능과 안정성을 높이기 위해 컴포넌트 간의 통신 방식을 개선할 예정입니다. 현재는 REST 방식으로 HTTP 프로토콜을 통해 통신하고 있지만, gRPC 등의 효율적이고 안정적인 통신 프로토콜을 도입하는 것을 고려하고 있습니다.
마치며
이번 글에서는 실시간 반응형 추천 시스템을 간략하게 소개해 드렸습니다. 세 가지 컴포넌트를 중심으로 시스템의 구성 방식을 소개했고, 노출 대비 주문전환율 40.23% 상승이라는 뛰어난 성과를 확인한 A/B 테스트 관련 내용까지 공유드렸습니다.
개발 과정이나 트러블슈팅 기록 등 기술적인 부분들에 대한 더 자세한 내용은 후속 글을 통해 공유할 예정이니 많은 기대 부탁드립니다.
