JPA에서 아이디를 자동증가 값으로 사용 시 하이버네이트의 @NaturalId 사용해 보기
DB에서 기본키를 자동증가 값으로 설정하여 사용 시 운영 환경과 베타 환경의 아이디값이 일치하지 않을 때,
@Id를 선언하지 않은 필드를@Id를 선언한 필드와 유사하게 동작하게 하는 하이버네이트의@NaturalId를 사용해 해결할 수 있는 방법을 공유해 보려 합니다.
신규 테이블 생성 시 기본키 생성은 어떻게 하고 계시나요?
저희팀에서는 기본 RDBMS 로 MySQL을 사용하고 있습니다.
MySQL의 경우 기본키를 Clustered Index 로 사용하고 있습니다.
Clustered Index란 데이터베이스 테이블에서 데이터를 저장하는 물리적인 순서를 인덱스 순서로 사용하는 것을 말합니다.
그래서 데이터 삽입 시 기본키 기준으로 데이터가 정렬되기 때문에 자동증가값 사용 시 삽입 성능이 좋습니다.
그리고 배치와 같이 대량의 데이터를 청크 단위로 조회할 때 offset-limit 쿼리로 조회했을 때보다는 아래처럼 기본키를 기준으로 조회했을 때 훨씬 빠르게 조회할 수 있습니다.
이러한 이유로 주로 기본키에는 auto_increment를 사용해 왔습니다.
- offset-limit 쿼리 예
select * from table where date = '2024-04-30' order by id asc limit 1, 500 - pk 기준 조회 쿼리 예
select * from table where date = '2024-04-30' and id > 100 order by id asc limit 500
운영환경과 테스트환경의 아이디값 불일치로 인한 문제
저희팀에서는 테스트환경과 운영환경을 함께 운영하고 있는데요, 테스트 환경의 경우에는 테스트용도로 데이터를 생성하다보니 운영환경과는 다른 데이터를 종종 생성하고는 합니다.
그래서 자동증가 값을 기본키로 사용하는 엔티티 대부분이 운영환경과 테스트환경의 아이디값이 다르게 되어 있습니다.
운영환경과 테스트환경의 아이디값이 달라서 문제가 됐던 경험이 있지 않으신가요?
운영환경과 테스트환경의 아이디값 불일치 문제를 설명해보기 위해 특정한 요구사항이 들어온 상황을 가정해 보겠습니다.
특정 상품의 판매 촉진을 위해 특정한 기간동안 특정 상품 몇개에 대해서만 80% 할인을 해야 한다는 요구사항이 들어왔습니다.
현재 상품 테이블 구조는 아래와 같습니다.
CREATE TABLE `product` (
`id` bigint NOT NULL AUTO_INCREMENT PRIMARY KEY,
`name` varchar(255) NOT NULL,
`price` int NOT NULL
);엔티티는 다음과 같습니다.
@Getter
@Entity
@Table(name = "product")
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Product {
@Id
@Column(name = "id")
@EqualsAndHashCode.Include
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name", nullable = false)
private String name;
@Column(name = "price", nullable = false)
private int price;
public Product(String name, int price) {
this.name = name;
this.price = price;
}
}현재는 할인 기능이 없습니다. 개발기간이 충분하다면 할인 기능을 개발하여 적용하고 싶지만, 안타깝게도 내일 모레부터 바로 운영환경에 적용되어야 하는 상황입니다.
운영 배포전 테스트도 필요하기 때문에 내일 오전까지 개발완료 후 내일 오후부터는 테스트환경에 배포하여 테스트 이후에 모레 오전에 운영환경에 배포하기로 하였습니다.
운영환경과 테스트환경의 상품이 모두 동일하면 좋았겠지만, 아쉽게도 테스트환경에는 테스트용으로 생성했던 상품들이 따로 존재합니다. 따라서 아래와 같이 동일한 상품이라도 아이디가 각각 다르게 등록되어 있습니다.
- 운영환경 상품 데이터

- 테스트환경 상품 데이터

하루 만에 모든 기능 개발을 끝마쳐야 하기 때문에 일단은 할인대상 상품 아이디 목록을 하드코딩하기로 하였습니다. 상품 아이디가 운영환경과 테스트환경에 각각 다르게 생성되어 있어서, 해당하는 상품들의 아이디를 운영환경과 베타환경에서 각각 찾아서 아래와 같이 사용하는 형태로 일단락지었습니다.
---
spring:
config:
activate.on-profile: beta
natural-id-sample:
discount:
start-date: 2024-04-30
end-date: 2024-04-30
ids:
- 1
- 5
- 7
---
spring:
config:
activate.on-profile: prod
natural-id-sample:
discount:
start-date: 2024-05-01
end-date: 2024-05-10
ids:
- 1
- 3
- 5@Service
public class ProductService {
private static final double DISCOUNT_RATE = 0.8;
private final ProductRepository productRepository;
private final DiscountProperties discountProperties;
public ProductService(ProductRepository productRepository, DiscountProperties discountProperties) {
this.productRepository = productRepository;
this.discountProperties = discountProperties;
}
@Transactional(readOnly = true)
public List<ProductDto> findAll() {
final LocalDate now = LocalDate.now();
return productRepository.findAll().stream()
.map(product -> convertToDto(product, now))
.toList();
}
private ProductDto convertToDto(Product product, LocalDate now) {
return ProductDto.builder()
.id(product.getId())
.name(product.getName())
.price(getPrice(product, now))
.build();
}
private int getPrice(Product product, LocalDate now) {
final int price = product.getPrice();
if (!discountProperties.isDiscountTarget(product.getId(), now)) {
return price;
}
return price - (int) (price * DISCOUNT_RATE);
}
}@ToString
@ConfigurationProperties("natural-id-sample.discount")
public class DiscountProperties {
private final LocalDate startDate;
private final LocalDate endDate;
private final Set<Long> ids;
public DiscountProperties(LocalDate startDate, LocalDate endDate, Set<Long> ids) {
this.startDate = Objects.requireNonNullElse(startDate, LocalDate.MAX);
this.endDate = Objects.requireNonNullElse(endDate, LocalDate.MIN);
this.ids = Objects.requireNonNullElse(ids, Set.of());
}
public boolean isDiscountTarget(Long id, LocalDate now) {
if (now.isBefore(startDate)) {
return false;
}
if (now.isAfter(endDate)) {
return false;
}
return ids.contains(id);
}
}열심히 개발하여 테스트환경에 배포하려는 순간 추가 요구사항이 발생하였습니다.
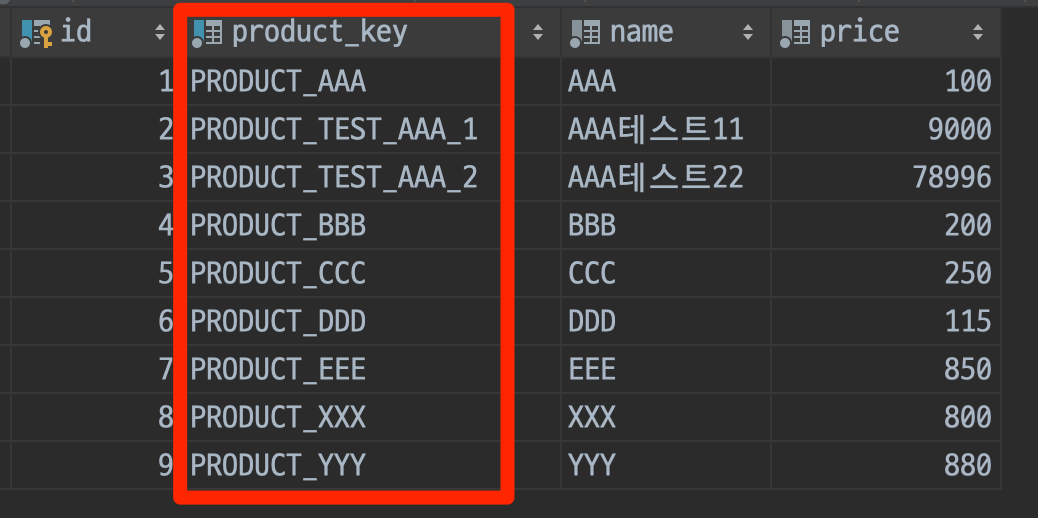
운영배포일 오전에 운영환경에 XXX와 YYY라는 상품이 신규로 생성되게 되는데, 신규로 생성되는 2개의 상품중 XXX 상품에도 동일하게 할인을 적용해 달라는 요구사항이였습니다.
베타환경의 경우 새로운 상품을 추가 후 바로 해당 상품의 아이디를 yml 파일에 추가하였지만, 운영환경은 내일 상품이 새로 생성 되어야만 아이디 값을 알 수 있어서 운영환경에 추가된 상품의 아이디 값을 어떻게 yml 파일에 추가할지 고민이 생겼습니다.
먼저 떠오른 생각은 상품을 먼저 생성하고서 생성된 상품의 아이디를 확인하여 코드상에 추가한 뒤 배포하는 방법이었습니다.
하지만 배포를 위해 아침 일찍 일어나 코딩까지 하기에는 너무나 억울한 마음이 들었던 저는 아이디 값이 어차피 자동증가 값이니 현재까지의 상품등록 추이를 보았을 때 알파벳순으로 상품이 등록되었으니 이번에도 XXX, YYY순으로 상품이 등록될 것으로 예상하여 현재 운영환경에 등록된 가장 큰 아이디값에 +1만 해주면 될 것이라는 생각을 하게 되었습니다.
그래서 현재 운영환경에 등록된 상품 중 가장 큰 아이디값인 5에다가 +1 해준 값인 6을 아래처럼 yml 파일에 추가하였고 운영환경에 그대로 배포하였습니다.
spring:
config:
activate.on-profile: prod
natural-id-sample:
discount:
start-date: 2024-05-01
end-date: 2024-05-10
ids:
- 1
- 3
- 5
- 6오전에 운영환경에 배포 이후 즐겁게 일하고 있던 저에게 갑자기 문의가 들어왔습니다.
오늘 운영환경에 추가한 상품 중 XXX 상품이 할인되어야 하지만, 실제로는 YYY 상품이 할인되고 있다는 문의였습니다.
원인은 상품의 순서가 예상과는 달리 XXX, YYY 순서로 등록되지 않고 반대 순서인 YYY, XXX 순서로 상품이 등록되는 바람에 YYY 상품이 할인되고 있었습니다.
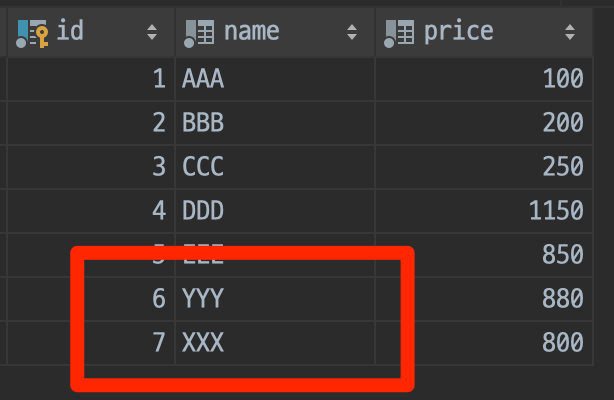
급하게 운영환경에 하드코딩된 아이디 값을 고쳐서 재배포 이후에는 정상적으로 XXX 상품이 할인될 수 있었습니다.
변경되지 않는 유니크 키가 설정된 컬럼을 사용해 보자
위의 사례와 같이 운영환경과 테스트환경의 자동증가하는 아이디값이 불일치하여 발생하는 일을 방지하기 위해서는 어떻게 해야 할까요?
여러 가지 방법이 있겠지만 한 가지 방법으로는 아래와 같이 자동 증가하는 아이디값 외에 유니크 키가 적용된 컬럼을 하나 더 추가하여 코드에서 자동증가값 대신에 유니크 키 컬럼을 사용해 보는 방법이 있습니다.
CREATE TABLE `product` (
`id` bigint NOT NULL AUTO_INCREMENT PRIMARY KEY,
`product_key` varchar(255) NOT NULL, # 유니크 키 컬럼 추가
`name` varchar(255) NOT NULL,
`price` int NOT NULL,
UNIQUE KEY `product_key` (`product_key`)
);product_key 컬럼의 경우 아이디 값 대신에 사용되어야 합니다. 즉 생성만 가능하고 변경이 되면 안 됩니다. 이에 아래와 같이 생성자에서만 전달받도록 엔티티를 수정하였습니다.
@Getter
@Entity
@Table(name = "product")
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Product {
@Id
@Column(name = "id")
@EqualsAndHashCode.Include
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "product_key", nullable = false, updatable = false, unique = true)
private String key;
@Column(name = "name", nullable = false)
private String name;
@Column(name = "price", nullable = false)
private int price;
public Product(String key, String name, int price) {
this.key = key;
this.name = name;
this.price = price;
}
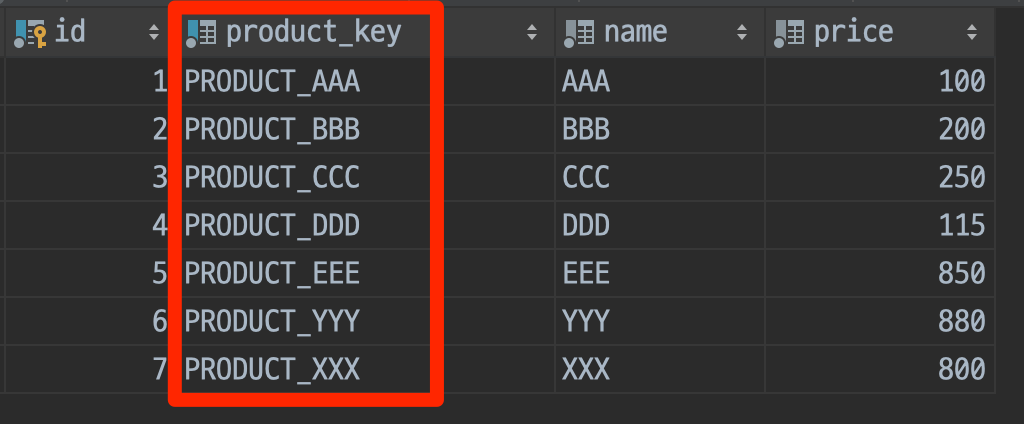
}추가된 유니크키 컬럼값을 통해 운영환경과 테스트환경에서 동일한 식별값으로 데이터를 생성할 수 있게 되어 아이디가 불일치하여 생기는 문제는 예방할 수 있게 되었습니다.
- DB 데이터
- application.yml
---
spring:
config:
activate.on-profile: beta
natural-id-sample:
discount:
start-date: 2024-04-30
end-date: 2024-04-30
keys:
- PRODUCT_AAA
- PRODUCT_CCC
- PRODUCT_EEE
- PRODUCT_XXX
---
spring:
config:
activate.on-profile: prod
natural-id-sample:
discount:
start-date: 2024-05-01
end-date: 2024-05-10
keys:
- PRODUCT_AAA
- PRODUCT_CCC
- PRODUCT_EEE
- PRODUCT_XXX그래서 이제부터는 아이디 대신 유니크키 컬럼 값으로 조회하여 사용하기로 마음먹고 아래와 같이 findByKey() 메서드를 ProductRepository에 추가 후 기존 findById() 메서드를 사용하는 부분들을 모두 findByKey() 메서드를 사용하도록 수정하기로 하였습니다.
Optional<Product> findByKey(String key);findByKey() 사용시 모든 기능은 정상동작하지만, 한 가지 마음에 걸리는 게 생겼습니다.
동일한 트랜잭션에서 동일한 엔티티를 여러 번 조회하는 경우, findById() 를 사용하면 한 번만 쿼리가 발생하지만 findByKey()를 호출하면 매번 쿼리가 발생한다는 점입니다.
ProductRepositoryTest.java
@Test
void findByKey() throws Exception {
productRepository.findByKey(PRODUCT_KEY).get();
productRepository.findByKey(PRODUCT_KEY).get();
productRepository.findByKey(PRODUCT_KEY).get();
}쿼리 로그
INFO [Test worker] MySQL : [QUERY] select p1_0.id,p1_0.product_key,p1_0.name,p1_0.price from product p1_0 where p1_0.product_key='KEY!!!'
INFO [Test worker] MySQL : [QUERY] select p1_0.id,p1_0.product_key,p1_0.name,p1_0.price from product p1_0 where p1_0.product_key='KEY!!!'
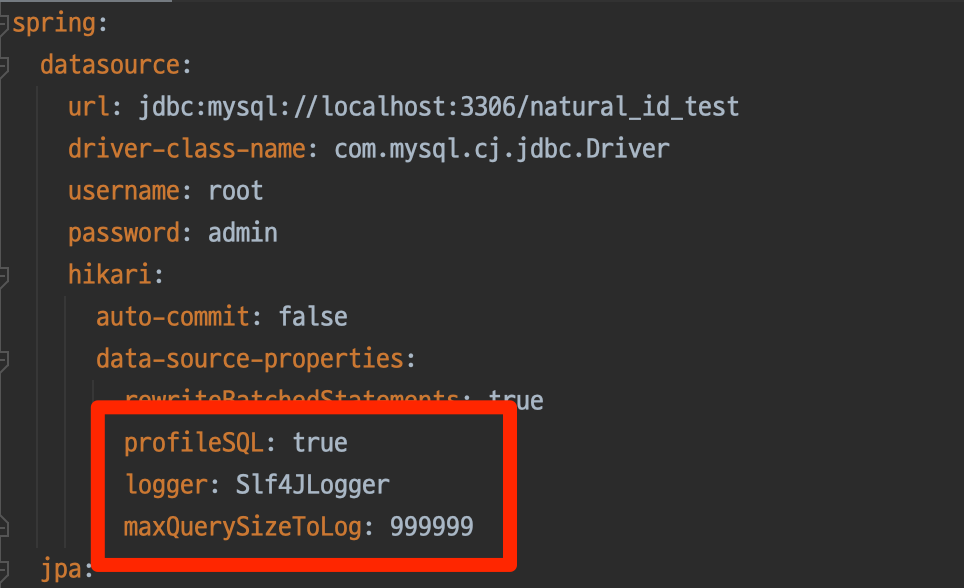
INFO [Test worker] MySQL : [QUERY] select p1_0.id,p1_0.product_key,p1_0.name,p1_0.price from product p1_0 where p1_0.product_key='KEY!!!'[참고] MySQL 이나 MariaDB 드라이버를 사용하는 경우 아래와 같은 설정으로 쿼리 로그를 남길 수 있습니다.
하이버네이트의 @NaturalId를 사용해 보자
찜찜함을 해결하기 위해 열심히 이곳저곳을 찾아보다가 하이버네이트에는 @Id가 붙은 필드가 아닌 필드에 선언하여, @Id가 붙은 필드와 유사하게 동작하게 해주는 @NaturalId라는 것이 있다는 것을 발견하게 되었습니다.
NaturalId API 문서를 보면 아래와 같은 문구가 있는데 지금의 상황에 사용하기에 적절해 보입니다.
This annotation is very useful when the primary key of an entity class is a surrogate key, that is, a system-generated synthetic identifier, with no domain-model semanticsDeepL 번역기의 도움을 받아보면 아래와 같이 해석이 됩니다.
이 어노테이션은 엔티티 클래스의 기본 키가 도메인 모델 의미가 없는 시스템 생성 합성 식별자, 즉 대리 키일 때 매우 유용합니다.그래서 바로 Product 엔티티의 key 필드에 @NaturalId를 아래와 같이 추가하기로 했습니다.
@NaturalId 추가 전/후를 비교하기 위해 기존 Product 엔티티에 추가하기보다는 ProductWithNaturalId 라는 엔티티를 새로 만들어 key 필드에 @NaturalId를 추가해 보도록 하겠습니다.
@Getter
@Entity
@Table(name = "product_with_natural_id", indexes = {
@Index(name = "product_key", columnList = "product_key", unique = true)
})
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class ProductWithNaturalId {
@Id
@Column(name = "id")
@EqualsAndHashCode.Include
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NaturalId
@Column(name = "product_key", nullable = false, updatable = false, unique = true)
private String key;
@Column(name = "name", nullable = false)
private String name;
@Column(name = "price", nullable = false)
private int price;
public ProductWithNaturalId(String key, String name, int price) {
this.key = key;
this.name = name;
this.price = price;
}
}
@NaturalId를 추가한 후 찜찜함이 해결되는지를 확인해 보기 위해 동일 트랜잭션에서 동일 키로 findByKey()를 여러 번 호출해 보겠습니다.
ProductWithNaturalIdRepositoryTest.java
@Test
void findByKey() throws Exception {
productWithNaturalIdRepository.findByKey(PRODUCT_KEY1).get();
productWithNaturalIdRepository.findByKey(PRODUCT_KEY1).get();
productWithNaturalIdRepository.findByKey(PRODUCT_KEY1).get();
}쿼리 로그
INFO [Test worker] MySQL : [QUERY] select pwni1_0.id,pwni1_0.product_key,pwni1_0.name,pwni1_0.price from product_with_natural_id pwni1_0 where pwni1_0.product_key='KEY111'
INFO [Test worker] MySQL : [QUERY] select pwni1_0.id,pwni1_0.product_key,pwni1_0.name,pwni1_0.price from product_with_natural_id pwni1_0 where pwni1_0.product_key='KEY111'
INFO [Test worker] MySQL : [QUERY] select pwni1_0.id,pwni1_0.product_key,pwni1_0.name,pwni1_0.price from product_with_natural_id pwni1_0 where pwni1_0.product_key='KEY111'@NaturalId를 엔티티의 key 컬럼에 추가하였지만 쿼리가 여전히 여러 번 실행되는 것은 변하지 않았습니다.
열심히 다시 이곳저곳을 찾아다녀본 결과 하이버네이트에서 제공하는 기능이기 때문에 @NaturalId 가 붙은 컬럼으로 조회 시에 아래와 같은 형태로 사용해야 한다는 것을 발견할 수 있었습니다.
entityManager.unwrap(Session.class)
.bySimpleNaturalId(Entity.class)
.loadOptional(naturalId);위의 기능을 활용하기 위해 Custom Repository를 만들고 구현체를 생성하도록 하겠습니다.
쿼리 비교를 위해 findByKey() 가 아닌 findByNaturalId() 라는 이름으로 메서드 하나를 새로 만들도록 하겠습니다.
ProductWithNaturalIdRepositoryCustom.java
public interface ProductWithNaturalIdRepositoryCustom {
Optional<ProductWithNaturalId> findByNaturalId(String key);
}ProductWithNaturalIdRepositoryImpl.java
public class ProductWithNaturalIdRepositoryImpl implements ProductWithNaturalIdRepositoryCustom {
private final EntityManager entityManager;
public ProductWithNaturalIdRepositoryImpl(EntityManager entityManager) {
this.entityManager = entityManager;
}
@Override
public Optional<ProductWithNaturalId> findByNaturalId(String key) {
return entityManager.unwrap(Session.class)
.bySimpleNaturalId(ProductWithNaturalId.class)
.loadOptional(key);
}
}추가한 findByNaturalId()를 동일트랜잭션에서 여러 번 호출해보니 findByKey()를 여러 번 호출 했을 때와는 달리 select 쿼리가 최초 한번만 실행됩니다.
ProductWithNaturalIdRepositoryTest.java
@Test
void findByNaturalId() throws Exception {
productWithNaturalIdRepository.findByNaturalId(PRODUCT_KEY1).get();
productWithNaturalIdRepository.findByNaturalId(PRODUCT_KEY1).get();
productWithNaturalIdRepository.findByNaturalId(PRODUCT_KEY1).get();
}쿼리로그
INFO [Test worker] MySQL : [QUERY] select pwni1_0.id,pwni1_0.product_key,pwni1_0.name,pwni1_0.price from product_with_natural_id pwni1_0 where pwni1_0.product_key='KEY111'이제는 findById()를 사용하는 대신에 엔티티에 @NaturalId를 선언한 필드로 마음 놓고 조회할 수 있게 되었습니다.
그런데 갑자기 궁금증이 생겼습니다.
동일 트랜잭션에서 위에서 정의한 findByNaturalId()로 조회한 엔티티의 아이디 값으로 findById() 메서드를 통해 다시 엔티티를 조회하게 된다면 어떻게 될까요?
아래와 같이 동일 트랜잭션에서 findByNaturalId() 로 조회한 엔티티의 아이디 값으로 findById()를 다시 조회해보니 findById()를 호출했을 때는 select 쿼리가 실행되지 않았습니다.
ProductWithNaturalIdRepositoryTest.java
@Test
void findById() throws Exception {
final ProductWithNaturalId productWithNaturalId = productWithNaturalIdRepository.findByNaturalId(PRODUCT_KEY1).get();
productWithNaturalIdRepository.findById(productWithNaturalId.getId()).get();
}쿼리 로그
INFO [Test worker] MySQL : [QUERY] select pwni1_0.id,pwni1_0.product_key,pwni1_0.name,pwni1_0.price from product_with_natural_id pwni1_0 where pwni1_0.product_key='KEY111'이번에는 동일트랜잭션 안에서 findAll()을 통해 저장된 전체 데이터를 조회한 후에 findByNaturalId()를 호출하게 된다면 어떻게 될까요?
아래와 같이 findAll() 조회 시에 발생한 select 쿼리 외에는 추가 쿼리가 발생하지 않았습니다.
ProductWithNaturalIdRepositoryTest.java
@Test
void findAll() throws Exception {
productWithNaturalIdRepository.findAll();
productWithNaturalIdRepository.findByNaturalId(PRODUCT_KEY1).get();
productWithNaturalIdRepository.findByNaturalId(PRODUCT_KEY1).get();
productWithNaturalIdRepository.findByNaturalId(PRODUCT_KEY2).get();
productWithNaturalIdRepository.findByNaturalId(PRODUCT_KEY2).get();
productWithNaturalIdRepository.findByNaturalId(PRODUCT_KEY3).get();
productWithNaturalIdRepository.findByNaturalId(PRODUCT_KEY3).get();
}쿼리 로그
INFO [Test worker] MySQL : [QUERY] select pwni1_0.id,pwni1_0.product_key,pwni1_0.name,pwni1_0.price from product_with_natural_id pwni1_0어떻게 된 걸까요?
열심히 조회하는 로직들을 따라가다 보니 BaseNaturalIdLoadAccessImpl.doLoad()에서 엔티티를 조회한다는 것을 알 수 있었습니다.
그리고 BaseNaturalIdLoadAccessImpl.doLoad() 내부를 보면 아래와 같은 부분을 발견할 수 있습니다.

위의 로직 중 persistenceContext.getNaturalIdResolutions().findCachedIdByNaturalId()를 따라 들어가 보니 아래와 같이 naturalIdToPkMap 이라는 곳에서 naturalId에 해당하는 id 값을 찾아서 반환받는 것을 알 수 있습니다.

위에서 반환된 아이디 값을 가지고 PersistenceContext에서 엔티티를 조회하고 있기 때문에, 동일 트랜잭션에서 PersistenceContext에 존재하는 엔티티를 여러 번 조회하더라도 findById()처럼 쿼리가 추가로 발생하고 있지 않게 되는 것이었습니다.
마무리
운영환경과 베타환경의 자동증가하는 아이디 값이 달라서 고통받고 계신다면 유니크키 컬럼 추가와 함께 @NaturalId를 선언하여 사용해 보면 어떨까요?
직접 입력 가능한 유니크키 컬럼을 통해 운영환경과 테스트환경의 식별값을 통일할 수 있고, 자동증가값을 사용한 PK 컬럼의 장점도 함께 사용할 수 있습니다.
그리고 @NaturalId를 선언한 필드로 조회 시 JpaRepository에서 제공하는 findById() 와도 동일하게 동작을 하기 때문에 findById()를 호출하는 부분을 대체 가능합니다.
주의사항
Java 챔피언인 Vlad Mihalcea의 글, The best way to map a @NaturalId business key with JPA and Hibernate를 보면 하이버네이트 5.5 버전 미만 사용 시에는 불필요하게 쿼리가 한 번 더 발생하기 때문에 하이버네이트 버전이 5.5 미만일 경우에는 사용하지 않는 걸 추천드립니다.
참고
@NaturalId – A good way to persist natural IDs with Hibernate?
The best way to map a @NaturalId business key with JPA and Hibernate
Hibernate Natural IDs in Spring Boot
