안녕하세요. 클라우드모니터링플랫폼팀의 이연수입니다. 우아한형제들의 모니터링시스템 구축 및 관리, 운영을 하고 있습니다. 작년부터 올해 초까지 팀에서 전사 로그 시스템을 전환을 진행했던 계기와 전환 후 성과에 대해 이야기를 나누어보겠습니다.
로그 시스템은 항상 도전 과제를 안겨줍니다. 각 서비스에서 발생하는 대부분의 로그를 수집해야하기 때문에 종류가 많고 비용이 많이 발생하지 않는지, 시스템 운영을 효율적으로 하고 있는지, 데이터를 효율적으로 저장하고 있는지 등 항상 풀어야 하는 숙제가 있습니다. 특히 로그 시스템은 High-Write, Low-Read 패턴으로 많은 데이터를 수집하지만 그에 비해 조회는 수집된 모든 데이터를 대상으로 하지 않습니다. 그렇기 때문에 수집과 조회를 각각 세심하게 관리해야 합니다.
이 글에서는 ELK에서 Grafana Loki로 전환을 했던 과정을 통해 이런 고민들을 어떻게 해결했는지에 대해 소개하려 합니다. 그리고 변화된 환경에서 로그 시스템을 어떻게 새롭게 구축했는지 함께 살펴보겠습니다.

기존 로그 시스템 ELK
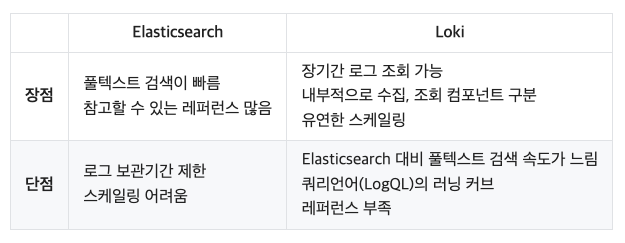
우아한형제들에서는 로그 시스템으로 ELK Stack을 사용하고 있었습니다. ELK Stack은 Elasticsearch, Logstash, Kibana의 앞글자를 딴 시스템으로 데이터를 수집, 처리, 조회하는 데 특화되어 있는 시스템이며 많은 회사에서 데이터 수집용도로 사용하고 있는 시스템입니다. 특히 Elasticsearch는 강력한 검색 및 쿼리 기능을 제공하여 다양한 조건으로 로그를 검색하고 원하는 데이터를 쉽게 추출할 수 있습니다. 또한 Logstash를 통해 다양한 데이터 형식을 수집하고 변환할 수 있습니다. 이는 다양한 종류의 로그 및 이벤트 데이터를 효과적으로 처리할 수 있는 장점을 제공합니다.
Elasticsearch에서는 단일 데이터 단위를 도큐먼트라고 하며 이 도큐먼트를 모아놓은 집합을 인덱스라고 합니다. 이 시스템을 운영할 당시 매일 수집되는 로그의 용량이 컸기 때문에 팀에서는 인덱스를 서비스별 구분을 했고 매일 배치를 통해 인덱스 롤오버를 하여 일자별로 신규로 생성하였습니다. 아래는 과거 구축했던 로그 시스템 아키텍처입니다.
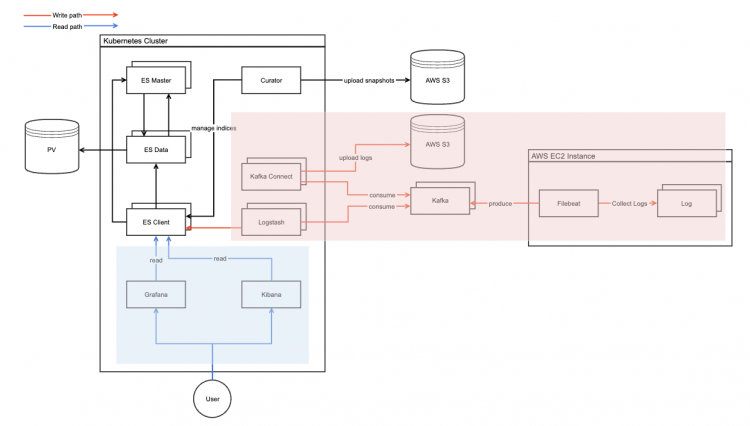
ELK 서비스에서 마주한 한계와 문제점
약 3년간 이슈없이 운영되던 로그 시스템이 시간이 지나면서 몇 가지 문제들이 발생하기 시작했습니다. 서비스 확장으로 인한 인덱스 부하가 발생했고 롤오버를 해도 인덱스 용량이 커지며 인덱스 내부의 샤드 수도 점점 늘어나 관리의 어려움으로 인해 많은 제약과 문제가 발생했습니다. 로그 수집량이 증가하는 만큼 데이터 노드들의 볼륨의 크기가 커져 운영 부담과 비용도 늘어났습니다. 스케일링을 위해 인덱스 및 샤드를 옮기는 작업을 할 때 볼륨이 커질 수록 소요되는 시간이 점점 길어졌습니다.
이런 비용을 절감하기 위해 볼륨에 저장하는 로그 기간을 줄이기 시작했고 저장 기간별 단기(3일 이내, 디스크에 저장), 중기(60일 이내, 스냅샷 생성 및 필요시 복원 후 조회), 장기(S3)로 나누게 되었는데 이로인해 조회방법의 파편화가 발생했습니다. Elasticsearch의 높은 비용, 대규모 클러스터 확장의 어려움이 점점 많아졌습니다. 부하가 발생하면 비정기적으로 전체 클러스터에 대한 API 접근이 실패하여 로그 전송이 되지 않는 경우가 발생했고 그때마다 필요한 튜닝으로 통해 조치를 했지만 비슷한 이슈들이 반복되어 안정성에 대한 의문이 들었던 것도 다른 로그 시스템의 전환을 고민했던 계기가 되었습니다.
Grafana Loki를 도입한 이유

ELK Stack에서 느끼는 한계와 이유들로 Grafana Loki로의 전환을 검토하게 되었습니다. Loki는 Grafana의 생태계인 LGTM(Loki, Grafana, Tempo, Mirmir)의 L을 담당하며 Prometheus에서 영감을 받아 개발된 수평 확장이 가능하고 가용성 높은 다중 테넌트 로그 집계 시스템입니다. 다른 로그 시스템과 달리 Loki는 로그에 대한 메타데이터만 인덱싱한다는 아이디어, 즉 레이블을 기반으로 구축되었습니다. 로그 내용을 색인화하는 것이 아니라 각 로그 스트림에 대한 레이블 세트를 색인화하기 때문에 레이블 단위로 로그는 별도로 압축되어 청크 단위로 저장이 되고 압축률에 따라 데이터가 감소됩니다. 로그에 대한 메타데이터인 레이블을 인덱싱한다는 아이디어를 중심으로 구성이 되었고 로그를 조회하기 위해 먼저 레이블 기반으로만 조회를 하고 매칭되는 레이블들과 매칭된 압축 로그 데이터를 가져와서 사용자에게 보여줍니다.

또한 아래처럼 로그시스템을 구축할 때 Loki 내부적으로도 Write 컴포넌트(Distributor, Ingester)와 Read 컴포넌트(Query-Frontend, Query-Scheduler, Querier, Index-Gateway)를 나눌 수 있어 효율적인 운영이 가능하고 언제든 스케일링 가능한 유연성이 매력적으로 다가왔습니다.
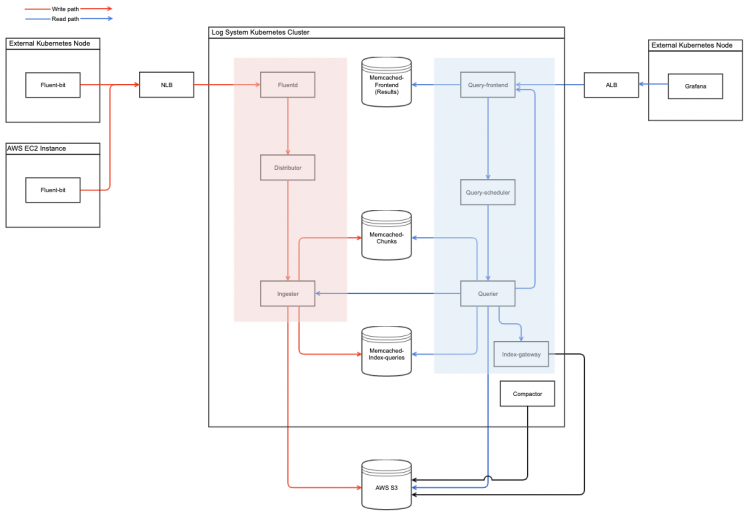
Loki는 단기간의 데이터만 메모리에 저장하고 나머지는 S3와 같은 오브젝트 스토리지에 저장하기 때문에 로그 수집량과 저장기간이 늘어날수록 리소스와 관리 비용이 늘어났던 Elasticsearch 대비 비용과 관리 측면에서 절감할 수 있을 것이라 기대했습니다. 또한 오브젝트 스토리지에 저장된 로그는 볼륨대비 비용이 적기때문에 제한기간을 두지 않고 조회를 할 수 부분이 장점이라고 생각했습니다. 그리고 수집, 조회 컴포넌트들이 구분되어 있어 이슈가 발생할 경우 특정 컴포넌트를 특정해서 조치할 수 있어 이슈 및 장애 조치도 쉬울 것이라 판단했습니다.
하지만 걱정되는 부분들도 있었습니다. 풀텍스트 검색은 Elasticsearch에 비해 느린 부분, 쿼리 언어(LogQL)를 엔지니어들이 학습해야하는 부분, 아직 사용하는 회사가 많지 않아 레퍼런스가 부족했습니다. 하지만 쿼리 속도는 특정 컴포넌트 튜닝을 통해 성능향상이 가능하고 LogQL은 당시 메트릭 조회를 위해 사용하고 있는 PromQL과 유사한 부분이 많아 적응하는데 오래 걸리지 않을 것이라고 생각했습니다. 그리고 부족한 레퍼런스의 경우도 필요하면 오픈소스의 코드를 보면서 분석하면 된다고 생각하여 여러 우려스러운 부분들은 충분히 극복할 수 있을 것이라고 판단했고 이런 고민들을 통해 Loki로 전환을 결정했습니다.
Grafana Loki 도입 후 변화와 실질적인 성과와 혜택
현재 우아한형제들의 로그 시스템은 Loki로 전환 완료되었습니다. 전환 후 기존 ELK Stack를 사용하며 불편함을 느꼈던 부분들 즉, 보관 기간에 관계 없이 장기간의 로그도 Grafana를 통해서 조회 가능하게 되었습니다. 피크 타임때도 로그 유입이 증가하더라도 유연하고 빠르게 확장이 가능해졌습니다. 주간에는 수집과 조회 컴포넌트에 각각 오토 스케일링을 적용하였고 야간에도 주간의 50% 이하로 기준을 설정하여 운영하고 있습니다. 로그 데이터는 약 65% 압축되어서 저장소에 저장되고 있습니다. 결과적으로 기존의 ELK Stack을 사용했던 과거에 비해 로그 수집량이 1.6배로 늘었지만 비용은 오히려 과거보다 약 23% 절감하여 운영하고 있습니다. 현재도 지속적으로 절감 포인트를 찾아 비용을 줄이고 있습니다.
Grafana Loki를 통해 얻은 새로운 기회와 가능성
Loki는 Grafana의 LGTM 생태계를 이용하여 확장성이 있게 구성이 가능하며 OpenTelemetry / Tempo와의 연동을 통해 Observability 시스템을 고도화할 수 있는 장점이 있습니다. Tempo는 OpenTelemetry에서 수집된 데이터를 처리하여 서비스의 가시성을 향상시키는 분산추적 시스템입니다. 로그에 TraceID를 추가하면 Loki와 Tempo의 연동이 가능해 Grafana를 통해서 특정 로그 이벤트와 분산 추적 데이터를 연결하여 조회가능합니다. 현재 팀에서도 OpenTelemetry / Tempo 파일럿을 진행하며 도입을 검토하고 있습니다. 고도화된 모니터링과 Observability 시스템을 통해 실시간 분석을 가능하게 하고 가시성이 향상된 시스템을 만들려고 합니다. 그리고 효율적인 운영 자동화를 통해 리소스 및 운영 비용 절감을 지속적으로 진행하고 웹서버, 어플리케이션 등의 로그, 메트릭, 분산추적을 연결하여 통합된 모니터링 시스템을 개발하고 이를 통해 복잡한 이슈를 손쉽게 추적하고 해결할 수 있도록 로드맵을 설정하여 모니터링 분야의 미래에 대한 가능성을 모색하고 있습니다.
다음 편 예고
다음에는 로그 시스템 전환 과정과 사내 문화를 중심으로 소개할 예정입니다. 사내 모든 엔지니어가 사용하는 시스템인 만큼 전환을 하기까지 쉽지 않은 과정과 시간들이 있었는데 이런 어려움들을 전사 엔지니어들과 어떻게 극복할 수 있는지에 대한 내용들도 정리해서 소개하겠습니다. 마지막으로 이 글을 읽으시고 궁금한 사항이 생기셨거나 논의하고 싶은 부분이 있으신 분은 댓글에 내용을 남겨주세요.
