배민광고리스팅 개발기(feat. 코프링과 DSL 그리고 코루틴)
안녕하세요. 배민상품시스템팀에서 배민광고리스팅을 만들어나가고 있는 박세종입니다.
배민광고리스팅 서비스는 배민앱의 큐레이션이나 배달탭의 한식과 같은 화면에 가게광고리스트를 제공하는 역할을 담당하고 있습니다. 사용자의 요청과 각 화면에 맞추어 최적화된 가게들의 리스트를 추출하고 반환하고 있습니다.
배민은 항상 변화하는 중입니다. 입사하자마자 마이크로 서비스로 일부 시스템들을 전환하는 경험을 했었고, 먼데이 프로젝트에선 전체적인 아키텍처에 대한 개선을 진행하였습니다. 최근에는 배민1과 같이 빠른 배달이 가능한 환경을 만들었습니다. 덩치에 비해서 변화의 폭이 적지 않기에 언제나 어매이징하고 다이내믹한 개발라이프가 이어지고 있네요.. 🙂
이러한 변화 과정에서 기존의 리스팅 시스템은 한계를 점점 드러내게 되었습니다. 기존 시스템은 광고를 기준으로 가게 데이터들을 역정규화하여 저장하고 이를 바탕으로 리스트를 만들어주었습니다. 최소 노출단위가 광고였기 때문에 당시로는 현명한 선택이었었습니다.
하지만 시간이 지날수록 점점 하나의 가게가 가지는 광고의 개수가 늘어났었고, 이벤트의 양이 늘어날수록 각 문서들의 업데이트 횟수도 기하급수적으로 증가하게 되었습니다. 만약 가게메뉴가 변경된다면 역정규화되어 구성된 N개의 데이터가 전부 변경이 되어야 합니다. 어느 순간 시스템이 처리 가능한 업데이트 수준을 넘어가는 순간이 찾아왔고, 요구사항에는 “하지 못한다”라는 이야기를 점점 더 많이 이야기하게 되었습니다.
다른 시스템의 도움을 얻어서 리스팅을 처리하는 경우가 많아졌습니다. 검색이 리스트 작업의 일부를 처리하게 되었고, 리스트의 결과에 재가공이 필요한다던지와 같이 도메인 본연의 역할을 오롯이 처리하지 못하게 되는 경우도 많아졌습니다. 덕분에 하나의 리스트를 만드는데 점점 더 많은 팀이 얽히는 상황이 발생하게 되었습니다. 구현하는데 걸리는 시간도 늘어나게 되었고, 각 시스템 간의 복잡도도 늘어날 수밖에 없었습니다. 어제의 현명한 선택이 오늘은 더이상 맞지 않게 된 상황이였습니다.
새로운 리스팅 시스템을 아랫단부터 만들고 개선하는 작업을 시작하였습니다. 앞서서 리스팅 시스템들을 운영하면서 느꼈던 경험들을 한가득 반영하고, 개발적인 사심(?)을 한가득 녹여내어서 기존의 도메인을 좀 더 깔끔하게 만들어나가게 되었습니다.
배민광고리스팅은..
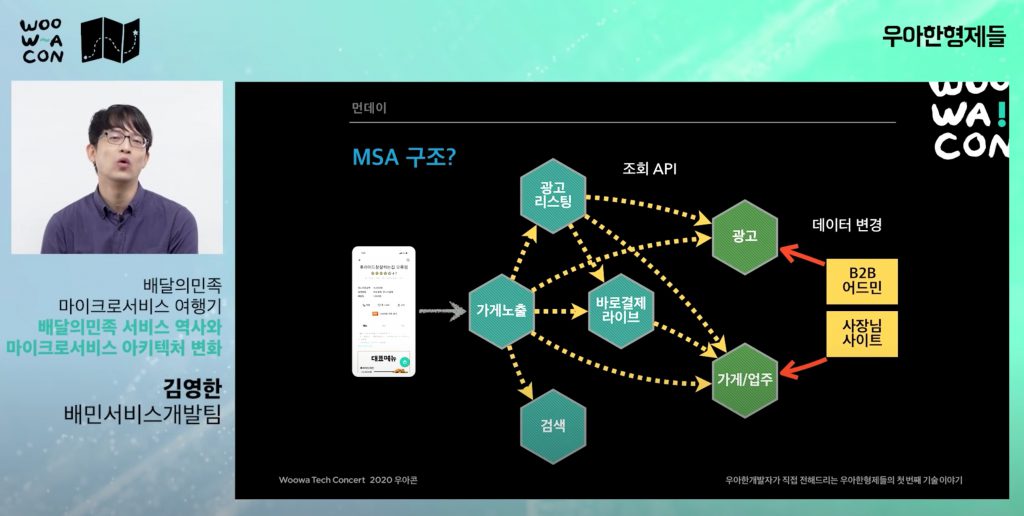
아마 다들 보셨을 이 발표영상 처럼 같이 배민은 거대한 CQRS 패턴의 마이크로 서비스로 구성되어있습니다. 배민광고리스팅은 사용자의 요청을 바탕으로 리스트를 만들고 이를 반환하는 책임을 가지고 있습니다. 모두가 배고픈 점심/저녁시간에서의 높은 요청량을 안정적이고 빠르게 처리할 수 있어야 하며, 뒷단의 커맨드성 서비스들로 요청이 가는걸 최대한 줄일 수 있어야 합니다.
쏟아지는 요청들을 처리하기 위해서 Elasticsearch를 이용하고 있습니다. Elasticsearch의 일반적인 목적인 전문검색을 활용하고 있지는 않지만 조건에 맞춘 빠른 조회가 가능하였고, 최근에 늘어나는 트래픽을 노드와 샤드를 활용한 분산처리로 안정적으로 처리해나가고 있습니다.
사용자향 서비스이기에 저희 시스템은 정책적인 복잡도가 높은 서비스 입니다. 하나의 요청을 처리하기 위해선 가게의 운영시간, 위치, 카테고리, 광고 여부, 메뉴 등 경우에 따라선 30개가 넘는 조건이 들어가기도 합니다. Elasticsearch로 안정성과 성능을 보장하더라도 이러한 복잡한 쿼리를 조립을 책임지는 코드는 어쩔수 없는 복잡도를 가질수 밖에 없습니다.
쿼리를 위한 기반 데이터를 적재하는 과정이 필요합니다. 광고, 메뉴, 가게 등 10여 개의 팀에서 발행한 이벤트들을 받고 있습니다. 이를 조회에 최적화된 형태로 변환하고, 불필요하거나 중복된 이벤트를 제거하는 등 Elasticsearch에 부하를 최소화하도록 튜닝하는 작업을 거쳐야 합니다. Elasticsearch의 업데이트는 상대적으로 낮은 성능을 가지기 때문에, 변환과 데이터 구조에 많은 신경을 쏟아야 합니다.
저희 서비스는 아래와 같은 비즈니스적인 골칫거리들과 싸우고 있습니다.
- 많은 요청량을 견뎌야 하며, 낮은 지연시간 확보 필요
- 복잡한 요구사항에 따른 어쩔수 없는 복잡한 쿼리와 구문들
- 메인저장소인 Elasticsearch에 최적화된 데이터 변환 및 적재
- 10여개팀에서 발행되는 기반데이터들에 대한 동기화
코틀린 도입
서비스가 성장해나가면서 함께 증가하는 복잡함은 피할 수 없습니다. 특히 사용자향 시스템이기에 정책적인 복잡함은 시간에 따라 늘어나고, 변경 역시 빈번하게 일어나고 있습니다. 복잡해져 가는 요구사항에 대해서 프로그래머가 대응할 수 있는 방법은 수단과 방법을 가리지 말고 코드를 최대한 단순하고 읽기 좋게 만들어내기 일것입니다.
요구사항에 맞추어 쿼리를 만들기 위한 코드나 데이터를 조립하는 부분에서 복잡도가 높았고, 이러한 코드의 복잡함을 코틀린을 도입하여 조금이나마 해결해보고자 했습니다. 자바와 비교해 문법적인 편의를 많이 제공하고 있었기 때문에 요구사항을 보다 날카롭게 표현할 수 있을 것이라고 판단하였습니다.
러닝커브가 낮다는것 역시 큰 장점이었습니다. 새롭게 프로젝트를 시작하는 입장에서 기존의 익숙하지 않은 기술을 사용하는 건 큰 부담일 것입니다. 특히 언어가 바뀌는 경우라면 문법은 어떻게든 익숙해지지만, 프레임워크를 비롯한 라이브러리와 툴까지 익숙해지는 과정이 필요하기에 비용은 더욱 높아지게 됩니다.
코틀린은 JVM으로 만들어져 있었기에 기존 자바에서 만들어진 라이브러리와 프레임워크를 전부 재사용할 수 있었습니다. 기존 자바에 익숙한 개발자라면 금방 적응하고 바로바로 코드를 만들어낼 수 있습니다. 저희 프로젝트에서 처음 코틀린을 사용하시는 분들의 경우에도 적응까지 일주일이면 충분했었습니다.
코틀린으로 읽기 좋은 코드 만들기
코틀린은 간결하게 코드를 만들 수 있는 문법적인 장치들을 한가득 제공해주고 있습니다. 이러한 장치들을 조합하여 앞서 이야기한 좀 더 읽기 좋은 코드를 만들어낼 수 있습니다. 아래는 request 조건에 맞는 가게를 찾은 다음 가게번호 리스트를 반환하는 코틀린 함수의 작성 예시입니다.
fun searchShopNumbers(apiRequest: SearchRequest): List<Long> {
val serviceRequest = SearchServiceRequest(
categories = apiRequest.categories,
serviceType = apiRequest.serviceType
)
val responseShops = shopSearchService.searchShops(serviceRequest)
return responseShops.map { it.shopNumber }
}
serviceRequest를 만들어내는 과정을 분리해낸다면 searchShopNumbers() 함수의 동작 흐름이 더 잘 보이도록 만들어낼 수 있을 것입니다.
fun searchShopNumbers(apiRequest: SearchRequest): List<Long> {
val serviceRequest = apiRequest.toSearchServiceRequest()
val responseShops = shopSearchService.searchShops(serviceRequest)
return responseShops.map { it.shopNumber }
}
// 확장함수로 추출
private fun SearchRequest.toSearchServiceRequest(): SearchServiceRequest {
return SearchServiceRequest(
categories = this.categories,
serviceType = this.serviceType
)
}
“클래스명.함수명”의 형태로 확장함수를 만들수 있으며 이를 바탕으로 추상화 수준이 낮은 부분을 분리하였습니다. 확장함수를 사용하는 경우 마치 SearchRequest 클래스에 이미 함수가 존재하는 것처럼 코드를 만들수 있습니다. 메서드 분리와 동일한 일을 하지만 읽는 관점에서는 apiRequest를 바탕으로 serviceRequest를 만들었다고 자연스럽게 읽을 수 있기에 좀 더 직관적인 코드가 됩니다.
let, apply와 같은 범위 지정 함수 역시 가독성을 늘릴 수 있도록 도와주는 문법입니다. 앞선 함수의 결과를 받아서 별도의 변수에 재할당하는 과정 없이 결과를 변환할 수 있습니다.
fun searchShopNumbers(searchRequest: SearchRequest): List<Long> {
val shops = searchRequest.toSearchServiceRequest()
.let { shopSearchService.searchShops(it) }
return shops.map { it.shopNumber }
}
가게를 조회한 뒤, 가게번호를 추려서 반환했다라는 플로우를 기존보다도 더 간결하게 표현해 낼 수 있습니다.
shops.map{ it.shopNumber } 역시 map 함수를 이용하여 줄일수 있을것 같네요.
fun searchShopNumbers(searchRequest: SearchRequest): List<Long> {
return searchRequest.toSearchServiceRequest()
.let { shopSearchService.searchShops(it) }
.map { it.shopNumber }
}
순수하게 로직의 흐름만을 드러내는 식으로 개선하였습니다. 함수의 반환 타입인 List 역시 생략이 가능하지만, 반환 타입을 확인할 수 있도록 만드는게 읽는 관점에서 좀 더 유리했기에 제거하지 않았습니다.
이와 같이 뼈대만을 드러내고 적정수준의 추상화를 가지도록 코드를 작성해나가고 있습니다. 자바에 비해서 간결한 코드를 구성해나갈 수 있었고, 단순하기에 요구사항의 변경이나 새로운 API를 구성하는 경우 더욱 빠르게 작업이 가능하게 되었습니다. 이외에도 불변을 보장하는 val이나 null safe 등의 기존 자바와 비교하여 코드의 실수를 줄일 수 있는 문법들을 제공하는 등 코틀린을 이용하는 경우 다양한 문법적인 장치로 단순한 코드를 만들어낼 수 있었습니다.
많은 문서들에서 이런 부분들을 찾을수 있기 때문에 보다 더 상세하게 기술하지는 않도록 하겠습니다.
DSL로 깔끔한 쿼리구문 만들기
저희 시스템은 메인 저장소로 Elasticsearch를 사용하고 있습니다. Elasticsearch는 빠른 조회 성능을 위해서 모든 데이터는 하나의 인덱스에 저장되어있어야 합니다.(Elasticsearch는 조인이 없어요..ㅠㅠ) 기준이 되는 가게라는 인덱스를 중심으로 저장 및 조회 과정이 진행됩니다. 해당 인덱스에는 가게 상세 + 메뉴 + 광고 + 통계.. 등을 아래와 같이 한꺼번에 저장하고 있습니다.
{
// 가게 핵심정보
"shop" : {
"status" : "OPEN",
"name" : "맛있는 치킨집",
"categories" : ["CHICKEN", "CAFE"]
},
// 가게 통계
"statistics" : {
"orderCount" : 200,
"favoriteCount" : 300,
},
// 메뉴
"menu" : {}
}
최상위 필드로는 각 외부 시스템들의 도메인들을 정의해 놓았습니다. 각 도메인들은 이벤트의 갱신에 맞추어 독립적으로 갱신되며 조회 시 해당 값들을 바탕으로 쿼리가 진행되며 결과가 반환됩니다.
가게상태는 OPEN, 주문수 통계정보가 존재하는 문서를 찾는 경우 Elasticsearch 쿼리는 다음과 같이 구성할 수 있습니다.
POST /shop/_search
{
"query" : {
"bool" : {
"filter" : [
{"term" : {"shop.status" : "OPEN"}},
{"exists" : {"field" : "statistics.orderCount"}}
]
}
}
}
해당 쿼리는 각 사용자의 요청에 맞추어 처리될 수 있어야 합니다. 즉 코드화가 필요합니다. 코틀린으로 위의 조회 쿼리는 다음과 같이 정의할 수 있습니다.
searchSource().query(
boolQuery()
.filter(termQuery("shop.status", "OPEN"))
.filter(existsQuery("statistics.orderCount"))
)
예제는 단순하지만 실제 코드에서는 “shop.status”와 같은 필드명을 쿼리 하나에만 수십여 개를 사용하게 됩니다. 이러한 필드명은 문자열로 정의되기 때문에 언제나 실수하지 않도록 주의를 기울여야 합니다.
만약 “shop”이라는 단어가 “store”로 바뀌면 하나씩 상수를 바꾸는 작업이 필요합니다. 혹여나 변경이 되어선 안될 “shopLocation” 필드명을 잘못 변경해버리면 장애로 이어질 수도 있습니다.
상수로 이를 빼낸다고 하더라도 1차원으로만 설정이 가능하기에 상수가 무한정 늘어나게 됩니다. “shop.status”와 코틀린의 문자열 보간을 통해서도 표현할 수 있지만 중간의 “.”을 누락하는 경우도 있었고, 길어지는 경우엔 역시나 가독성이 좋지 않았습니다.
저희는 코틀린의 object를 이용하여 개선하는 방법을 선택하였습니다. object로 선언된 클래스는 싱글톤 객체로 만들어지기 때문에 객체 초기화 과정없이 바로 호출이 가능합니다. 이 object들을 계층구조로 배치하고 필드들을 설정하였고 Elasticsearch의 필드 구조와 유사하게 작성할 수 있도록 만들었습니다.
object ShopFieldSet {
object shopNumber : Field<Long>("shopNumber")
object shop : Field<ShopDetail>("shop") {
object location : FieldAny("location", shop)
object status : FieldAny("status", shop)
object categories : FieldAny("categories", shop)
}
object statistics : Field<ShopStatistics>("statistics") {
object orderCount : FieldAny("orderCount", statistics)
object favoriteCount : FieldAny("favoriteCount", statistics)
}
}
open class Field<T>(
name: String = "",
private val parent: Field<*>? = null
) {
val _n = name
get() = nameWithParent(field, parent)
// ...
}
Field 인터페이스는 상위 필드 정보, 자기 자신의 필드명과 타입을 정의할 수 있도록 구성되어있습니다. 해당 인터페이스를 바탕으로 object들이 일관된 형식을 가지도록 만들 수 있었습니다. 그리고 각 필드 object는 아래 다시 필드 object를 설정하는 방식으로 Elasticsearch의 형태와 유사하도록 설정할 수 있습니다.
searchSource().query(
boolQuery()
// _n은 필드명 문자열 반환
.filter(termQuery(shop.status._n, "OPEN"))
.filter(termQuery(statistics.orderCount._n, "CAFE"))
)
앞선 조회 쿼리는 다음과 같이 변경할 수 있습니다. 이제는 문자열이 아니라 shop.status와 같이 필드 정보를 가져올 수 있게 되었습니다. 실수할 일도 적어지고 자동완성도 가능해졌습니다. 좀 더 편하게 필드명을 설정할 수 있게 된거죠.
업데이트하는 시점에서도 개선이 어떻게 되었는지 살짝 보여드리려고 합니다. 조회보다 좀 더 적극적으로 Field 객체를 사용하고 있습니다.
통계정보와 가게 상세정보가 업데이트되어야 한다면 아래와 같이 코드를 구현할 수 있습니다.
// {"statistics":{"orderCount": 14, "favoriteCount": 28"}, "shop": {...}}
val updateMap = mapOf(
"statistics" to statistics,
"shop" to shop
)
val updateDoc = objectMapper.writeValueAsString(updateMap)
val reuqest = UpdateRequest()
.id("100")
.doc(updateDoc, JSON)
.index("shop")
client.update(request, DEFAULT)
Elasticsearch의 문서 구조에 맞추어 JSON 형태로 값을 변환한 뒤 업데이트 하여야 합니다. objectMapper를 이용하여 변환 과정을 거친 다음 RestClient의 UpdateRequest 객체를 만들어주고 그다음 최종적으로 업데이트를 진행하게 됩니다.
코틀린이 업데이트 코드를 조금 단순하게 만들어주었지만, Map을 사용하였기에 실수할 수 있는 여지도 많아 보입니다. 만약 통계 객체의 자리에 쿠폰 객체를 넣는다던지와 같은 엉뚱한 업데이트가 발생할 수도 있습니다. 여러 필드에 대한 정보를 한꺼번에 업데이트하여야 하는 경우라면 코드는 더욱 복잡해지게 될 것입니다.
업데이트 구문을 좀 더 간결하게 설정할 수 있도록 DSL을 구성하였습니다.
val partialUpdateDoc = "100" withBody {
it[shop] = ShopDetail("맛있는 치킨집", OPEN)
it[statistics] = ShopStatistics(orderCount = 14, favoriteCount = 28)
}
shopRepository.upsertPartial(partialUpdateDoc)
앞선 예제보다 더 깔끔해졌네요. 기존 Map으로 설정하던 구문은 ID withBody { 문서 }형태로 설정하였고, “100”이라는 ID를 가진 문서에 각각의 필드들은 it[statistics] = value 와 같이 정의한다라는걸 코드 레벨에서 바로 드러나도록 하였습니다.
이때 “shop”은 앞서서 만든 Field 인터페이스를 구현한 object입니다. 해당 Field object가 가지고 있는 Type 속성과 매칭 되는 객체만을 넣을 수 있도록 제약을 걸어두어서, 실수를 미연에 방지할 수 있도록 방어해 두었습니다.
위의 DSL 함수는 아래 함수와 클래스를 바탕으로 구현하였습니다.
infix fun <ID> ID.withBody(partialDocumentBodySetter: (PartialDocumentBody) -> Unit): PartialDocument<ID> {
return PartialDocument(this, partialDocumentBody(partialDocumentBodySetter))
}
class PartialDocumentBody(
private val fieldWithValues: MutableList<FieldWithValue<*>> = mutableListOf()
) : List<FieldWithValue<*>> by fieldWithValues {
constructor(vararg fieldWithValues: FieldWithValue<*>) : this(fieldWithValues.toMutableList())
operator fun <T> set(field: Field<T>, value: T?) {
fieldWithValues.add(field.with(value))
}
companion object {
fun partialDocumentBody(partialDocumentBodySetter: (PartialDocumentBody) -> Unit) =
PartialDocumentBody().apply(partialDocumentBodySetter)
}
}
infix fun ID.withBody(bodySetter: (PartialDocumentBody) -> Unit)withBody(..)함수는 확장함수입니다. ID타입에서만 사용할 수 있습니다.- infix 함수로 설정하였습니다. “.”과 “()”없이 띄워쓰기로 함수를 호출할 수 있습니다.
100 withBody {..}는100.withBody({...})와 동일하게 해석됩니다.
- 인자으로
(PartialDocumentBody) -> Unit를 받도록 하였습니다.PartialDocumentBody객체는 사용자가 정의한 함수 내부에서it으로 참조할 수 있습니다.
- 함수의 바디에서는
PartialDocumentBody의 객체를 만들고, 사용자정의함수에 인자로 다시 전달합니다.- 최종적으로 사용자가 정의한 함수에서
PartialDocumentBody완성됩니다.
- 최종적으로 사용자가 정의한 함수에서
class PartialDocumentBody- 해당 클래스는 업데이트 필드와 값을 보관할 수 있으며, 최종적으로 업데이트시 해당 정보를 넘겨주게 됩니다.
- 아래의 set 함수를 이용하여 필드명과 해당 값을 설정할 수 있습니다.
operator fun set(field: Field, value: T?)– operator 함수를 이용하면 연산자를 오버로딩할 수 있습니다. https://kotlinlang.org/docs/operator-overloading.html
–it[shop] = ShopDetail(...)와 같은 형태는 oeprator set 함수로 정의할 수 있습니다.
– T 타입을 받아 필드의 타입과 value의 타입이 일치하도록 제한했습니다.앞선 업데이트 코드를 DSL 설정 코드와 연결시켜본다면 이렇게 정리될 수 있을 것 같네요.
// infix 확장함수 사용. 띄워쓰기로 함수 실행. // withBody의 인자로 비어있는 partialBody 전달받음 it으로 함수 바디에서 참조가능 "100" withBody { // partialBody는 set operator를 가짐 key = value형태에서 해당 함수 호출 it[shop] = ShopDetail("맛있는 치킨집", OPEN) // statistics 필드는 Field<ShopStatistics>로 선언됨. // ShopStatistics 타입의 객체 또는 null을 값으로 받을 수 있음 it[statistics] = ShopStatistics(orderCount = 14, favoriteCount = 28) }더 나아가 바디 부분의 경우 함수를 인자로 받기 때문에, 조건에 따라 업데이트 문이 달라져야 하는 경우에도 자연스럽게 표현이 가능합니다.
"200" withBody { it[shop] = ShopDetail("개발자 치킨집", OPEN) // 포장만 사용하는 가게는 불필요한 정보를 색인하지 않도록 한다. if(isTakeoutOnly) { it[deliveryTip] = DeliveryTip(500) it[deliveryTime] = DeliveryTime(10, 30) } else { it[deliveryTip] = null it[deliveryTime] = null } }저희 서비스는 연동되는 필드들이 많아지고 복잡함도 늘어나고 있지만, 위와같은 DSL을 활용하여 구현이나 변경에 빠르고 실수없이 처리해나갈 수 있게 되었습니다. 코틀린을 활용한 DSL은 구현난이도가 낮으며 얻을수 있는 이점이 많기에 저희처럼 반복되는 부분이 보인다면, DSL을 직접 만들고 도입해보면 좋은 효과를 보실수 있을 것 같네요.
webflux에 Coroutine 얹어보기
저희 시스템은 사용자의 요청에 직접적으로 응답값을 만들고 처리할 수 있어야 합니다. 배민이기에 특정 시간에 쏟아져 들어오는 요청량에도 안정적이고 적은 비용으로 서비스가 가능하여야 하며, 이를 위해서 reactive stack인 webflux + Reactor를 활용하고 있습니다.
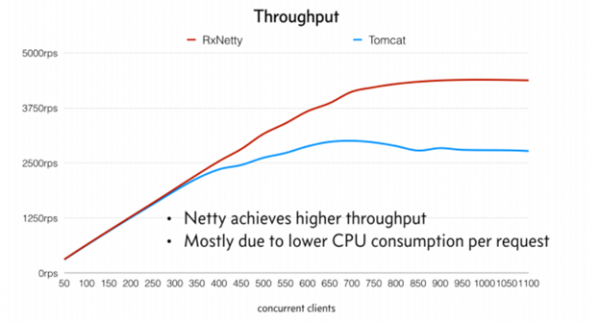
reactive stack을 이용하는 경우 대량의 트래픽들을 적은 스레드를 바탕으로 처리할 수 있으며, 높은 부하에서도 적은 하드웨어자원으로 안정적인 처리가 가능토록 만들어 줍니다. Reactor는 리모트콜을 병렬적으로 처리할 수 있는 일관적인 방법을 제공해주기 때문에 전체적인 API의 응답시간을 낮추기도 좋습니다.
@GetMapping("/search-shops") fun searchShopNumbers(@RequestParam request: SearchRequest): Mono<List<Long>> { // 휴무일여부 + 배달가능센터 동시 조회 return Mono.zip( // 해당 메서드의 반환값은 Mono holidayService.isHoliday(request.currentDate), // 해당 메서드의 반환값은 Mono deliverableCenterService.findDeliverableCenter(request.location) ) // zip의 결과로 tuple반환. 이를 풀어서 request로 전환 .map { tuple -> toServiceRequest(tuple.t1, tuple.t2, request) } // findShopNumbers(it)은 Mono로 반환.. flatmap으로 비동기 처리 필요 .flatMap { findShopNumbers(it) } // 가게번호 반환! .map {shops -> shops.map { it.shopNumber } } } private fun findShopNumbers(request: ServiceSearchRequest): Mono<List<Shop>> { // ... }두 API를 조회한 다음 메인 저장소를 조회하고 결과를 반환하는 코드는 Reactor를 이용하면 다음과 같이 작성할 수 있습니다. 모든 함수는 Mono, 즉 비동기로 동작하도록 설정되어있습니다. 앞서서 두 API를 호출하는 부분은 병렬로 처리되기에 전체적인 응답속도를 올릴 수 있습니다.
많은 장점을 가지지만, 난해함을 함께 가져가게 되었습니다. Reactor에서 모든 함수의 결과는 Mono나 Flux 타입으로 반환하여야 합니다. 체이닝된 메서드가 이어지는 과정에서 비어있는 값을 하위에 잘못 전달되는 경우 결과가 나오지 않는 경우도 있으며, 언제 터질지 모르는 NPE에 언제나 대비하고 방어하여야 합니다. 마지막으로 비동기로 동작하기 때문에 에러가 발생하는 경우 스택트래이스는 실제 로직과 매끄럽게 매칭이 되지 않기도 합니다. 어디에서 에러가 발생했는지를 찾기가 쉽지 않았습니다.
Reactor를 처음 접했을 당시 이질적인 코드 스타일에 많이 당황했었습니다. 직관적으로 이해도 힘들었고 각 연산자들마다 어떠한 메커니즘으로 움직이는지 역시 쉽게 와닿지 않았었습니다. 지금도 Reactor 코드와는 많이 친해지지 못한 상태입니다.
코드는 단순하여야 합니다. 특히나 요구사항이 다양하고 복잡해지는 사용자향 시스템이면 더욱 그렇게 되어야 한다고 생각합니다. 요청량이 많은 상황에서는 Reactor는 좋은 선택이었지만 그로 인해서 잃어버리는 단순함에 대한 비용은 높다고 많이 느끼게 되었습니다. 막말로 서버님이 좀 더 효율적으로 일하는 대신 개발자가 고생하게 된 상황인 거죠.
좀 더 나은 방법을 고민하던 중 코틀린에서 제공해주는 비동기 프레임워크인 Coroutine을 접하게 되었습니다. Coroutine은 무엇보다도 기존의 익숙한 코드스타일로 비동기를 처리할 수 있다는 큰 장점을 가지고 있습니다.
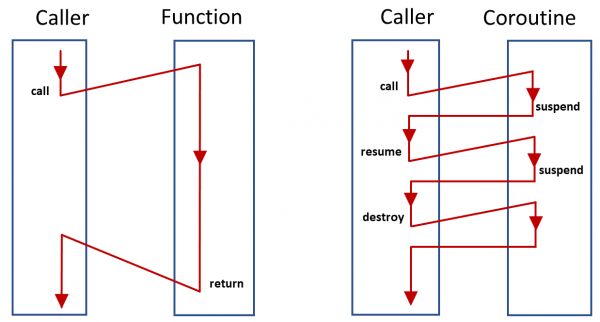
Coroutine은 로직(루틴)을 수행하는 도중에 작업을 일시정지하고 다른 로직을 수행할 수 있도록 만들어줍니다. 중간의 일시정지된 로직은 재시작이 가능한 경우에 이어서 실행됩니다. Coroutine으로 구성된 코드는 컴파일 과정에서 콜백을 사용하는 형식으로 변환되고 실행됩니다. 이러한 방식으로 Coroutine은 로직을 비동기로 수행할 수 있으며 넌블러킹하게 함수 호출이 가능하도록 만들어줍니다.
fun main() = runBlocking { // (1) launch { // (2) printWorld() // (3) } println("Hello") // (6) } suspend fun printWorld() { // (4) delay(1000L) // (5) println("World!") // (7) }“Hello”가 출력된 다음 약 1000ms가 흐르고 “World”가 출력됩니다.
- (1) Coroutine 빌더로 Coroutine을 시작할 수 있습니다. runBlocking은 하위 Coroutine 블록이 끝날때까지 대기하는 특별한 Coroutine 빌더입니다.
- (2) 새로운 코루틴을 시작합니다. launch는 반환값이 없는 경우에 사용하는 코루틴 빌더입니다. (반환값이 있는경우 async 사용)
- (3) printWorld 함수를 호출합니다.
- (4) suspend는 코루틴에서 호출이 가능한 함수입니다. 해당 함수는 중간에 일시정지한뒤 다른 작업을 할 수 있습니다.
- (5) 1초간 delay를 가집니다. delay는 Coroutine이 제공하는 함수로 블로킹되지 않습니다.
- (6) launch블럭은 비동기로 로직이 실행되며, delay는 넌블로킹이기 때문에 다음 작업인 “Hello”가 출력됩니다.
- (7) 1초가 흐른다음 다시 함수내부 로직이 재시작되며 “World”가 출력됩니다.
일련의 과정은 하나의 스레드에서 수행됩니다. Coroutine 로직을 적절히 조합하는 경우 스레드를 넘나들면서 잃는 비용도 최소화시킬 수 있습니다. Coroutine의 흑마술스러운 내부 구조에 대해 자세히 알고 싶으신 분들에게 아래의 영상을 추천드립니다.
KotlinConf 2017 – Introduction to Coroutines by Roman Elizaro
스프링 webflux에서는 Coroutine을 함께 사용할 수 있도록 지원(Going Reactive with Spring, Coroutines and Kotlin Flow)하고 있습니다. 여러 가지 테스트를 해보면서 Coroutine 적용에 대한 확신을 점점 얻게 되었고, 앞서서 불만을 이야기했던 Reactor 대신 좀 더 간단하게 코드를 만들어나갈 수 있는 Coroutine을 사용하여 프로젝트를 만들어나가기 시작하였습니다.

앞서서 Reactor을 활용하여 작성했던 핸들러메서드는 Coroutine을 사용하는 경우 아래와 같이 변경할 수 있습니다.
@GetMapping("/search-shops") suspend fun searchShopNumbers(@RequestParam request: SearchRequest): List<Long> { val isHolidayDeferred = async{ holidayService.isHoliday(request.currentDate) } // (1) val deliverableCenterDeferred = async{ deliverableCenterService.findDeliverableCenter(request.location) } // (2) val request = toServiceRequest(isHolidayDeferred.await(), deliverableCenterDeferred.await(), request ) // (3) return findShopNumbers(request).map { it.shopNumber} // (4) } // Mono가 사라졌어요.(대신 suspend가 생겼네요..) private suspend fun findShopNumbers(request: ServiceSearchRequest): List<Shop> { // ... }- (1) async는 비동기로 내부 블럭이 처리됩니다. isHoliday suspend function으로 넌블로킹 작업입니다.
- (2) 해당 블럭 역시 비동기로 처리되기 때문에 (1) 호출 직후에 함께 실행됩니다. findDeliverableCenter 역시 suspend function으로 넌블로킹으로 진행됩니다.
- (3) await()는 비동기로 호출한 함수이 전부 완료될때까지 기다릴 수 있습니다
- 이 시점에서 앞서 호출된 두 함수의 결과가 나올때까지 대기합니다.
- (4) findShopNumbers는 비동기로 처리될 필요는 없기 때문에 코루틴 블럭없이 호출합니다.
- 해당 함수는 suspend로 설정되어있습니다. 해당 함수를 호출하는 관점에서는 넌블로킹으로 동작합니다.
해당 챕터 처음에 보여드렸던 Reactor와 비교하여 단순한 코드가 만들어졌습니다. Reactor에서 연산자를 어떻게 조합하여야 하는지와 같은 고민없이도 직관적으로 코드 작성이 가능하게 되었으며, 빠르게 작성하고 읽는 관점에서도 간결한 코드가 되었습니다. Coroutine으로 만들어진 코드들은 넌블로킹하게 구성이 가능하므로, webflux에서도 블로킹없이 처리될 수 있습니다.
Coroutine의 경우 try/catch를 사용하여 오류처리가 가능합니다.
fun main() = runBlocking { try { checkPositive(-3) } catch (e: Exception) { throw RuntimeException(e) } } suspend fun checkPositive(number: Int) { if (number < 0) { throw IllegalArgumentException("error") } } /* Exception in thread "main" java.lang.RuntimeException: java.lang.IllegalArgumentException: error at learning.test.SampleKt$main$1.invokeSuspend(Sample.kt:9) .... at learning.test.SampleKt.main(Sample.kt:5) at learning.test.SampleKt.main(Sample.kt) Caused by: java.lang.IllegalArgumentException: error at learning.test.SampleKt.checkPositive(Sample.kt:15) at learning.test.SampleKt$main$1.invokeSuspend(Sample.kt:7) ... 10 more */익숙했던 try/catch 로 오류가 가능하기 때문에 간단한 코드가 만들어집니다. (상위나 전체 Coroutine으로 에러를 전파하는 것은 조금 더 많은 이해가 필요하긴 합니다.) 스택트레이스에서도 Reactor와 달리 구체적인 오류를 확인할 수 있기에 오류 추적도 단순해집니다.
Coroutine 테스트는
kotest와mockk를 활용하여 작성하고 있습니다.class CoroutineCarTest : FunSpec({ // test 블럭은 Coroutine 스코프를 가지고 있습니다. test("간단한 Coroutine 테스트") { // given val car = mockk<Car>() // when // when::suspend function은 coEvery를 이용하여 mock으로 처리 할 수 있습니다. coEvery { car.drive(Direction.NORTH) } returns Outcome.OK // then car.drive(Direction.NORTH) // returns OK // then::suspend function이 호출되었는지 여부는 coVerify로 확인할 수 있습니다. coVerify { car.drive(Direction.NORTH) } } })“k”가 들어가 있는 두 라이브러리들은 코틀린의 테스트 라이브러리로, 기존의 테스트코드 스타일과 유사하므로 Coroutine에 대한 기능테스트 역시 어렵지 않게 작성이 가능합니다. kotest와 관련된 이야기는 앞선 기술블로그에서 찾아볼 수 있습니다.
https://techblog.woowahan.com/5825
만약 저희처럼 Coroutine 적용을 고려하신다면 연계되는 코드들이 모두 넌블로킹하게 동작할 수 있음이 보장되어야 합니다. 스레드를 여러 요청이 함께 나누어 사용하기 때문에 자그마한 블로킹 코드가 들어가는 경우 전체 서비스가 멈추게 만들수도 있을 것입니다. 이러한 블러킹되는 로직들은 개발환경과 같이 요청량이 적을 경우에 발견되지 않으므로 꼼꼼한 코드작성과 함께 작업하는 구성원들의 주의와 이해도를 필요로 합니다.
기존 코틀린으로 구성된 프로젝트에서도 일부 영역을 코루틴으로 전환하는 작업 역시 어렵지 않습니다. 이전 프로젝트에서 해당 방법으로 API의 전체적인 레이턴시를 크게 낮출수 있었기에 이를 공유드리고자 합니다. “runBlocking” Couroutine 빌더는 비동기 Coroutine 블록을 동기로 동작할 수 있도록 만들어주는 다리역할을 합니다. 이를 이용하면 동기 코드 중간에 Coroutine을 사용할 수 있습니다.
N개의 독립적인 API를 호출한 뒤 그 결과를 조합하여 반환하는 함수 예시입니다.
// 영화 상세정보를 조회합니다. fun getMovieDetail(movieName: Long) : List<Movies> { val movieId = movieRepository.findMovieId(movieName) // 포스터 정보 반환 val posters = posterClient.fetchPosters(movieId) // 리뷰 반환 val reviews = reviewClient.fetchReviews(movieId) // 유저 평가정보 반환 val userRating = userRatingClient.fetchUserRatings(movieId) return Movie(posters, reviews, userRating) }위의 함수에서 API를 호출하는 코드는 독립적으로, 병렬로 실행이 가능합니다. 각 API 호출을 한꺼번에 진행할 수 있다면 전체적인 함수의 수행 시간을 줄일 수 있을 것 입니다.
fun getMovieDetail(movieName: Long) : List<Movies> { val movieId = movieRepository.findMovieId(movieName) // Coroutine 시작 return runBlocking { val postersDeferred = async(Dispatchers.IO){posterClient.fetchPosters(movieId)} val reviewsDeferred = async(Dispatchers.IO){reviewClient.fetchReviews(movieId)} val userRatingDeferred = async(Dispatchers.IO){userRatingClient.fetchUserRatings(movieId)} // 세개의 API는 넌블로킹으로 실행. 여기에서 병합후 반환된다. Movie(postersDeferred.await(), reviewsDeferred.await(), userRatingDeferred.await()) } }API를 조회하는 부분은 async 빌더와 Coroutine의 IO 디스패쳐를 이용하여 감싸주었습니다. API 호출은 블로킹하게 동작하기 때문에, IO 스레드로 처리를 위임하여 넌블로킹하도록 만들어 동시에 실행이 가능하도록 만들었습니다. 만약 각 API들의 속도가 유사하다면 3개의 API가 처리되는 시간을 1/3으로 줄일 수 있을 것입니다.
Coroutine으로 비동기 스타일 통일시키기
비동기를 지원하는 방식들이 자바에선 여럿 존재합니다. 전통적인 thread부터 completableFuture, Reactor등의 여러가지 비동기 라이브러리들을 자바에서 찾아볼 수 있습니다. 저희가 프로젝트에 사용하는 라이브러리들은 각각 다른 비동기 방식으로 처리되어 있습니다. 이러한 라이브러리들을 일관된 스타일로 읽을 수 있도록 변환하는 작업을 진행하였습니다.
Elasticsearch는 future의 콜백을 바탕으로 비동기 API가 제공됩니다. suspendCoroutine은 콜백을 이용하여 Coroutine의 형태로 변환할 수 있습니다.
open suspend fun upsertAsync(document: T, index: String = this.index): UpdateResponse { val request = UpdateRequest() .docAsUpsert(true) .id(document.documentId()) .doc(esObjectMapper.writeValueAsString(document), JSON) .index(index) // suspendCoroutine은 callback을 Coroutine으로 변환할 수 있습니다. return suspendCoroutine { continuation -> esClient.updateAsync( request, DEFAULT, // Elasticsearch의 비동기 처리 후 ActionListener가 콜백으로 호출됩니다. object : ActionListener<UpdateResponse> { // 업데이트 성공시 호출 override fun onResponse(response: UpdateResponse) { continuation.resume(response) } // 업데이트 실패시 호출 override fun onFailure(e: Exception) { continuation.resumeWithException(e) } } ) } }webflux의 webClient는 mono를 반환합니다. Reactor-kotlin에서는 mono를 Coroutine으로 변환할 수 있는 확장 함수를 제공하고 있으며 이를 이용하면 간단하게 suspend function으로 전환이 가능합니다.
suspend fun fetchShops(): List<ShopInfoResponse> { return shopWebClient.get() .uri { it.path("/v4/shops").build()} .retrieve() .bodyToMono<ShopPageResponse>() .map { it.contents } // Mono -> Coroutine으로 변환 .awaitSingle() }블로킹이 기본인 경우들도 존재할 것입니다. Coroutine에서는 이러한 동기식 코드들을 IO dispatcher를 사용하면 비동기로 처리할 수 있습니다. 저희 프로젝트는 RDB사용량이 많지 않기에 R2DBC에 대한 검증과정을 거치는 대신 기존 방식을 사용하여 DB 호출 과정을 처리하고 있습니다.
suspend fun shopRankings(shopNumbers: List<Long>): Map<Long, RankingScores> = CoroutineScope { val popularScoresDeferred = async(Dispatchers.IO) { popularScoreService.findPopularScores(shopNumbers) } val soloScoresDeferred = async(Dispatchers.IO) { soloScoreService.findSoloScores(shopNumbers) } val popularScores: Map<Long, PopularScore> = popularScoresDeferred.await().associateBy { it.shopNumber } val soloScores: Map<Long, SoloScore> = soloScoresDeferred.await().associateBy { it.shopNumber } shopNumbers.associateWith { RankingScores( soloRankingScore = soloScores[it]?.rankingScore ?: 0.0, popularRankingScore = popularScores[it]?.rankingScore ?: 0.0 ) } }이처럼 비동기 코드, 혹은 동기 코드들을 모두 일관되게 만들어낸다면 상위 함수의 관점에서 일관된 스타일의 비동기 코드를 만들어낼 수 있습니다.
Webflux Coroutine에 MDC 적용하기
reactive stack은 하나의 스레드를 여러 요청이 공유하게 됩니다. 각 요청들의 플로우를 기록하기 위한 traceId를 MDC에 넣어도 스레드가 변경되기 때문에 제대로 추적할수 없습니다. Reactor 역시 동일한 문제가 있으며 아래의 가게노출시스템 소갯글에서 어떻게 대응하는지에 대해서 확인할 수 있습니다.
배달의민족 최전방 시스템! ‘가게노출 시스템’을 소개합니다. (#Reactor With MDC 를 참고해주세요.)
Coroutine 은 이러한 상황에 대응할 수 있는
MDCContext를 제공하고 있습니다. 각 Coroutine 블록이 시작될 때마다 앞서서 저장되어있던 MDC를 매번 재설정하는 과정이 진행됩니다. 이를 이용해 여러 스레드에서 진행되더라도 동일한 MDC를 가지는 것처럼 만들어줍니다. 앞선 Reactor 에서 처리되던 것과 동일한 방식으로 움직입니다.이제 우리는 모든 요청마다 MDCContext를 추가해주기만 하면 됩니다. 아쉽게도 Coroutine으로 핸들러를 실행하는 과정에서는 확장 포인트가 제공되고 있지 않기 때문에, 저희는 컨트롤러 메서드에 AOP를 이용하여 MDCContext를 감싸고 MDC에 저희의 추적값인 traceId를 추가하는 방식으로 설정할 수 있었습니다.
@Around("@annotation(RequestMapping)") fun addCoroutineMdc(joinPoint: ProceedingJoinPoint): Any? { val signature = joinPoint.signature as MethodSignature val method = signature.method // 스프링의 KotlinUtil을 사용 return if (KotlinDetector.isSuspendingFunction(method)) { @Suppress("UNCHECKED_CAST") val continuation = joinPoint.args.last() as Continuation<Any?> MDC.put("traceId", findOrGenerateTraceId()) val newContext = continuation.context.plus(MDCContext()) val newContinuation = Continuation<Any?>(newContext) { continuation.resumeWith(it) } val newArgs = joinPoint.args.dropLast(1).plus(newContinuation) joinPoint.proceed(newArgs.toTypedArray()) } else { joinPoint.proceed() } }Coroutine은 JVM 코드로 컨버전되는 단계에서 콜백 스타일의 메서드로 변환됩니다. 그리고 이 변환된 메서드의 가장 마지막 인자는 콜백을 위한
Continuation이 설정됩니다. 해당 객체를MDCContext를 감싸주는 방식으로 설정하였고, 저희에게 필요한 traceId 역시 함께 추가하는 식으로 MDC 관련하여 불편했던 부분을 해결할 수 있었습니다.Reactor??
앞서서 Reactor의 단점만을 부각하여 이야기를 진행했지만, 저희는 여전히 Reactor를 사용하고 있으며 앞으로도 쭈욱 사용할 예정입니다. 🙂
Coroutine은 Flow라는 Reactor 유사하게 시그널을 전달하고 처리할 수 있는 기능을 제공합니다. 하지만 Reactor와는 달리 단순 푸시 방식을 사용하고 있기에 배압과 같은 기능을 사용할 수 없습니다. 만약 배압이 필수적이라면 Corotine보다는 Reactor가 더욱 좋은 선택일 것입니다.
또한 Flow와 비교하여 Reactor는 풍부하고 검증된 연산자들을(특히 시간과 관련된) 가지고 있습니다. 이러한 풍부한 연산자들이 필요하다면 Reactor를 선택하는게 유리합니다. 예를들어 일정 시간 동안 신호를 모은 다음 한꺼번에 다음 스트림으로 전달한다던지와 같은 작업은 리액터를 이용하는 게 Coroutine보다 유리하였습니다.
현재 저희 시스템에서는 Coroutine을 단일 요청에 단일 결과를 반환하는 API에서 사용하고, 리액터는 대량의 이벤트를 수신하고 이를 업데이트하는 데 사용하는 식으로 처리하고 있습니다.
리스팅을 처리하기 위한 많은 이벤트를 받고 처리하고 있습니다. 개별 이벤트들이 수신될 때마다 매번 업데이트하기보단 10초 동안 혹은 1000개 정도의 이벤트가 모였을때 이를 한번에 업데이트하는 방식(bufferTimeout)으로 처리하고 있습니다. 또한 지나치게 많은 요청이 elastcisearch로 흘러가들어가지 않도록 배압도 함께 설정되어있습니다. 이러한 일련의 과정에 리액터를 사용하고 있습니다.
위와 같이 대량의 이벤트를 처리하는 과정에서 시간 요소나 배압이 필수적으로 들어가야 하는 경우라면 Reactor가 더욱 나았지만, 이외의 일반적인 경우라면 Coroutine이 조금 더 나은 선택이라고 조심스럽게 이야기드리고 싶습니다.
마치며

배민광고리스팅은 기존 시스템을 따라잡는 암흑기를 지나 새로운 가치를 만들어나가는 단계에 조금씩 접어들고 있습니다. 기반이 어느 정도 갖추어졌기에 더욱 좋은 리스팅 시스템을 만들어나가는 다음 여정을 준비하고 있습니다.저희들과 같이 함께 고민하고 같이 만들어나갈 귀한분들을 애타게 찾고 있습니다.배달의민족 광고시스템 서버 개발자 모집에 많은 지원을 부탁드립니다.
함께해주시는 모든분들께 야매 Coroutine 특강과 저희집 고양이 미공개컷 300장을 공유해드리고 있습니다.저희가 나아가고 있는 여정들은 앞선분들의 고민들과 과정이 있었기 때문에 가능하였습니다. 함께 고민하고 정제하고 공유하고 알려주셨었던 모든 분들에게 무한한 감사를 전하고 싶습니다.