절대적 Rule을 지켜 – Config Checker 개발기
들어가며
안녕하세요. 작년에 우아한테크코스 2기를 수료하고 시스템신뢰성개발팀(이하 SRE팀)에서 개발하고 있는 남윤서입니다.
SRE팀에선 다양한 활동을 통해서 장애를 탐지, 예방, 복구, 사후처리를 하고 있는데요,
그중 장애 예방을 위해 Spring Boot 애플리케이션의 설정값을 체크하는 시스템(Config Checker) 개발 경험을 공유하려고 합니다.
조금 길지만 재밌게 읽어주셨으면 좋겠습니다. 😄
SRE의 요구사항은 장애로부터
서비스의 요구사항이 고객(서비스 사용자)으로부터 오는 것처럼 SRE의 요구사항은 장애로부터 만들어집니다.
간략하게 우아한형제들의 장애 대응과 포스트모템(portmortem) 문화에 대해 설명해 드리면, 먼저 서비스에 장애가 발생하면 SRE팀은 개발팀과 함께 장애를 대응합니다. 그러다 장애가 해소되고 상황이 종료되면 장애보고서를 작성하는데요, 이 과정에서 장애를 항목별로 분류하고 장애의 근본 원인과 후속 대책을 도출해냅니다. SRE팀에서는 이렇게 작성된 장애보고서를 월, 연 단위로 회고하고 분석합니다. 어떤 유형의 장애가 많이 발생했는지, 이런 유형의 장애를 시스템적으로 어떻게 하면 막을 수 있을지, 막지 못한다면 어떻게 다운타임(downtime)을 줄일 수 있을지 고민합니다. (자세한 장애대응 프로세스는 우아~한 장애대응 글을 참고해 주세요.)
팀 내에선 위와 같은 과정을 통해 작년의 크고 작은 장애들을 분석했습니다. 그 결과 2020년 한 해 동안 스프링(Spring) 애플리케이션 설정값으로 인한 다운타임이 4시간 32분이었습니다. 대략적인 장애 원인은 다음과 같습니다.
- HikariCP connection pool size 부족
- DB connection에 SSL 사용
- Redis connection pool size 부족
- Redis connection timeout 미설정
- AWS Aurora failover 미동작
팀 내에선 회고를 통해 이런 유형의 장애를 막을 수 없을까 고민했고, 장애로 연결될 수 있는 다양한 설정값이 코드리뷰를 통해서만 체크되고 있다는 점을 개선해야겠다고 생각했습니다. 이렇게 장애 분석 및 회고를 통해 설정값을 통한 장애를 예방한다는 요구사항이 만들어졌습니다.
설정값을 통한 장애를 예방한다
설정값을 통한 장애를 예방하기 위해 먼저 가이드를 제공하기로 했습니다. 최소품질체크리스트라는 이름으로 서비스가 운영 환경에서 원활하게 동작하기 위해서 최소한 이 정도는 설정해야 한다는 가이드를 작성했습니다. 다음은 HikariCP 예시입니다.
- connection-timeout
- 추천값: 3000(3초)
- db pool에서 꺼내오기까지 기다리는 최대 시간
- maximum-pool-size
- 추천값: 50이내. 상황에 맞춰 조절
- 모든 서버가 떴고 최대 커넥션 개수에 도달한 상태일 때의 커넥션 개수는 RDS가 받아줄 수 있는 최대 개수의 50% 정도를 유지한다.
- API 등 실시간성 애플리케이션은 min/max 커넥션 수를 동일하게 가져가서 커넥션을 맺느라 성능이 저하되지 않게 한다.
- max-lifetime
- 추천값: 50000(50초)
- 커넥션 풀의 커넥션이 살이 있을 수 있는 최대 시간
- RDS 의 WAIT_TIMEOUT 속성보다 작게 설정
- 이 값이 작으면 Aurora Failover 시에 더 유연하게 작동한다.
- HikariCP는 네트워크 지연과 어플리케이션의 성능지연을 고려하여 max-lifetime 를 데이터베이스의 wait_timeout 설정(현재 회사 공통 60초)보다 5초 정도 짧게 줄 것을 권고한다.전사에서 주로 사용하는 라이브러리와 CP(connection pool) 등 다양한 설정에 대해 주의사항을 명시하고, 특별한 경우가 아니라면 사용하길 권장하는 추천값을 명시했습니다. 최소품질체크리스트를 통해 새로 시작하는 프로젝트뿐만 아니라 기존의 프로젝트까지, 말 그대로 최소 품질을 보장할 수 있도록 제공했습니다. 이 과정에 운영 경험이 풍부한 개발자분들께서 많은 기여를 해주셨습니다. (가이드를 작성하는 과정에서 힘을 모아주신 개발자분들께 감사드립니다)
하지만 가이드는 가이드일 뿐, 저희가 최종적으로 지향하는 형태는 아니었습니다. 최소품질체크리스트를 제공했다 하더라도 사람이 직접 설정하는 과정이 필요했고 설정하는 과정에서 실수가 있으면 설정값이 잘못 적용됐는데도 적용했다고 착각할 수도 있는 상황이었습니다.
그래서 최소품질체크리스트를 자동으로 체크해 주는 시스템(이하 Config Checker)를 개발해서 사람의 실수를 방지하고 프로젝트에 설정값이 올바르게 적용됐는지 체크하기로 했습니다.
설정값을 자동으로 체크하자
Config Checker를 개발하는 과정에서 다양한 고민이 있었습니다. 개발이 완료되고 운영환경에 배포되기 전까지 수많은 단계 중 어떤 단계에서 체크하는 게 적절한지, 그리고 어떤 방식으로 체크하는 것이 적절할지 고민했습니다.
언제 체크할 것인가?
먼저, 배포되기 이전에 코드 레벨에서 properties 파일이나 yaml 파일을 읽어서 정적으로 분석할 수도 있습니다. 이 경우 master 브랜치에 merge된 이후 동작하는 CI 파이프라인에서 검증하게 될 것입니다. 하지만 다음과 같은 단점이 있었습니다.
Config Checker를 적용하는 팀이 각 프로젝트별로 CI 파이프라인을 수정해야 한다는 점properties파일이나yaml파일은 사용자의 입력값일 뿐 실제 적용된 값이 아니라는 점- 적용을 체크하려면 배포가 되어야 하는데 CI의 성격과 맞지 않는다는 점
따라서 배포 시점에 동적으로 분석하기로 했습니다.
어떻게 체크할 것인가?
먼저 고려한 방법은 배포 파이프라인에 녹이는 방식이었습니다. 기존에 사내 배포 시스템에서 제공한 배포 파이프라인에 새로운 배포 잡(job)을 추가하려고 했습니다. 스크립트를 수정해 새로운 잡을 추가하고, 배포가 진행되는 도중에 에이전트가 Config Checker의 API를 호출하는 방식으로 진행했습니다.
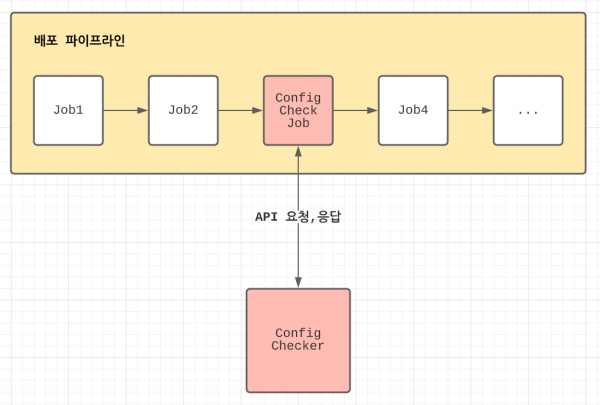
하지만 배포 파이프라인에 녹이는 방식 역시 단점이 존재했습니다.
- 배포 파이프라인 코드가 각 프로젝트에 포함되어 있기 때문에
Config Checker를 적용하는 프로젝트별로 배포 스크립트를 직접 수정해야 한다는 점 - 새로운 배포 잡이 추가된다는 점
배포 잡 추가는 프로젝트의 배포 시간을 증가시킵니다. 한 프로젝트의 배포만 생각했을 땐 큰 부담이 없을 수도 있지만, 전사의 모든 프로젝트에 새로운 배포 잡이 추가되는 것은 생각보다 큰 파급효과를 갖고 있습니다. 운영 환경과 베타 환경을 가리지 않고 많은 서비스가 배포 시스템을 통해 하루에도 수십 번에서 많게는 수백 번 배포가 이루어지는데, 배포 시간 증가는 곧 전사적인 생산성 감소로 이어집니다.
또한 배포 잡 추가는 장애 관점에서도 위험이 있습니다. 새로운 버전을 배포한 이후 문제가 생기면 빠르게 롤백(rollback)을 하거나 문제 되는 부분을 수정해서 핫픽스(hotfix)가 이루어지는데, 배포 잡이 추가된다면 위와 같은 긴급 상황에서도 배포 시간이 길어지고 이는 곧 다운타임의 증가로 이어집니다.
배포 잡을 스킵(skip) 할 수 있는 옵션을 추가로 제공할 수도 있지만 이는 곧 사용률 감소로 이어질 수 있었고 이 밖에도 Config Checker의 장애가 배포 실패로 이어지는 등의 문제가 있었습니다.
공통적인 단점
언제 적용할지, 어떻게 적용할지 고민하는 과정에서 공통된 단점이 있었습니다. 팀에서 각 프로젝트별로 적용을 해야 한다는 점인데요, 이런 에이전트(agent) 방식은 적용하는데 상당한 운영 비용이 발생합니다. 또한 변경사항이 있을 때도 적용된 프로젝트 수에 비례해서 운영 비용이 증가할 수 있습니다. 한정된 리소스에서 운영 비용 증가는 상당한 부담이기 때문에 다른 방식을 고려해야 했습니다.
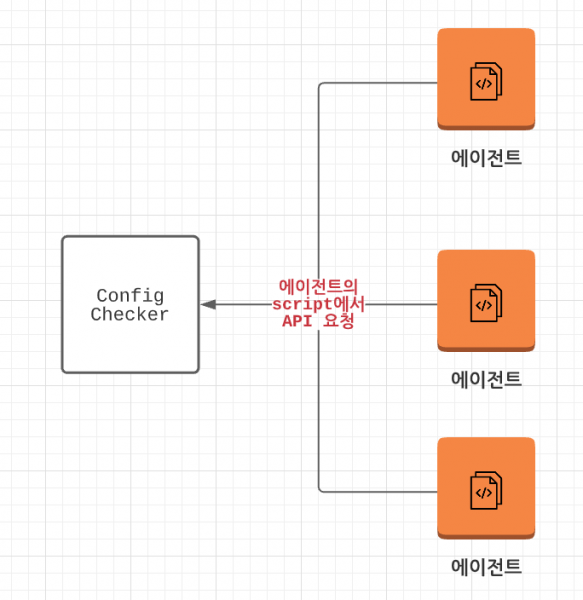
플랫폼 개발은 기본적으로 사일로(silo)를 해소하는 목적을 갖고 있습니다. 각 프로젝트별로 필요한 기능을 플랫폼을 통해 제공해서 전사적인 생산성을 올리는 것인데 각 프로젝트별로 작업이 필요하다는 것이 플랫폼의 장점을 퇴색한다고 생각했습니다. 완전히 프로젝트별 작업이 없을 순 없겠지만 최대한 NoOps를 지향해야 한다는 것을 느꼈습니다.
손 안 대고 코를 풀자
앞선 문제들을 해결하기 위해 고민하던 중 배포 이벤트를 트리거 받아서 동작하면 별다른 작업 없이 적용할 수 있다는 사실을 알게 되었습니다. 배포가 완료되면 DynamoDB에 배포 내역을 저장하고 이벤트를 트리거 받아서 Lambda 함수가 Kafka로 이벤트를 발생시키는데, 이 배포 이벤트를 소비해서 체크하면 배포 시스템을 사용하는 모든 프로젝트에 적용할 수 있었습니다. (의견 주신 클라우드플랫폼개발팀 감사합니다)
결과적으로 Config Checker는 다음과 같은 형태가 되었습니다.
- 배포 시점에 동적으로 분석
- 배포 잡에서 API 요청을 하는 방식이 아니라 배포 이벤트를 받아서 분석

설정값 가져오기
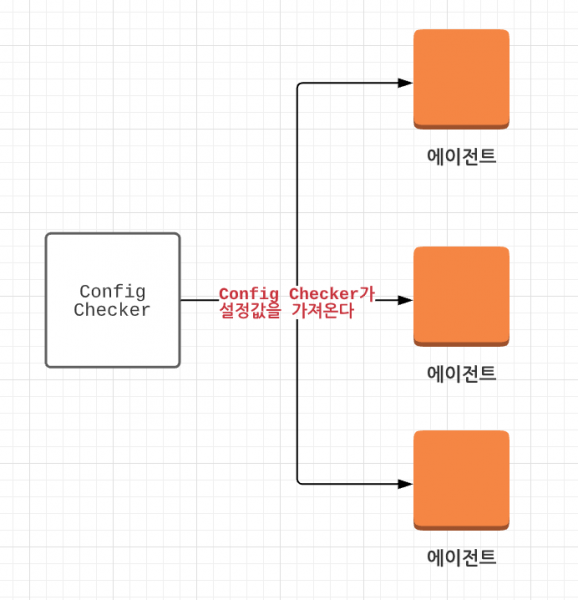
Config Checker는 배포 이벤트 데이터를 통해 배포된 인스턴스의 정보를 가져옵니다. 인스턴스 정보를 통해 웹서버로 API 요청을 보내서 적용된 설정값을 가져오는데, 이때 Spring Boot Actuator를 사용합니다.
배포되는 서비스별로 Spring Boot Actuator의 env, configprops 엔드포인트(end-point)를 열어주면 체크하는 시점에 Config Checker가 설정값을 가져와서 체크를 진행합니다. 기존에 에이전트가 직접 Config Checker로 API 요청을 하던 방식에 비해 Config Checker가 설정값을 가져오는 pull 방식은 운영 비용이 적어 관리가 수월했습니다.
/actuator/env를 통해 체크하기
최초엔 /actuator/env 엔드포인트를 통해 설정값을 가져와 체크했습니다. /actuator/env 엔드포인트에는 환경 변수, JVM 정보뿐만 아니라 application.properties 파일 또는 application.yaml 파일로 지정한 설정값 정보가 담겨있습니다.
{
// 활성화 된 profile
activeProfiles: ["prod"],
propertySources: [
{
// 실행중인 웹서버 포트 정보
name: "server.ports",
properties: {}
},
{
// Servlet init-param
name: "servletContextInitParams",
properties: {}
},
{
// 시스템의 속성값
name: "systemProperties",
properties: {}
},
{
// 시스템의 환경 변수
name: "systemEnvironment",
properties: {}
},
{
// 사용자가 properties 파일 또는 yaml 파일로 지정한 설정값
name: "applicationConfig: [classpath:/application.yml]",
properties: {}
}
]
}/actuator/env에 노출된 설정값 중 사용자가 지정한 설정값 부분을 좀 더 자세히 살펴보면 다음과 같습니다.
{
name: "applicationConfig: [classpath:/application-service.yml] (document #0)",
properties: {
spring.datasource.hikari.connection-timeout: {
value: 12345,
origin: "class path resource [application-service.yml]:17:27"
},
spring.datasource.hikari.maximum-pool-size: {
value: 12,
origin: "class path resource [application-service.yml]:18:26"
},
spring.datasource.hikari.max-lifetime: {
value: 12345,
origin: "class path resource [application-service.yml]:19:21"
}
}
}다음과 같이 애플리케이션 소스에서 application.yaml 파일로 설정한 내용이 그대로 출력되는 것을 확인할 수 있습니다.
spring:
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:~/test;
hikari:
connection-timeout: 12345
maximum-pool-size: 123
max-lifetime: 12345그렇기 때문에 /actuator/env 경로에서 JSON 데이터를 가져와 파싱 한 뒤에 해당 경로에 있는 값을 체크하면 끝이라고 생각했습니다. 하지만 끝이 아니었습니다. Spring은 설정값을 지정하는 다양한 방식을 제공하기 때문입니다.
예를 들어 @ConfigurationProperties를 통해 설정한 다음과 같은 코드도 위와 동일하게 설정이 적용됩니다.
ysnam:
begaonnuri:
custom:
driver-class-name: org.h2.Driver
jdbc-url: jdbc:h2:~/test;
connection-timeout: 12345
maximum-pool-size: 123
max-lifetime: 12345@Configuration
class DatasourceConfig {
@Bean
@ConfigurationProperties("ysnam.begaonnuri.custom")
fun dataSource(): DataSource {
return DataSourceBuilder.create().type(HikariDataSource::class.java).build()
}
}첫 번째 예제에선 spring.datasource.hikari.connection-timeout 경로를 통해 체크하면 됐지만, 두 번째 예제에선 전혀 상관없는 ysnam.begaonnuri.custom.connection-timeout 경로를 통해 체크해야 했습니다. 즉, 같은 설정이라도 프로젝트마다 다른 방식으로 설정될 수 있다는 것입니다.
결국 프로젝트마다 다른 경로를 체크해야 했고 이러한 방법으로는 모든 프로젝트를 체크하는 데 한계가 있다고 판단했습니다. 따라서 사용자가 설정하는 방식에 상관없이 Spring에서 설정이 최종적으로 적용되는 곳을 체크하기로 했습니다.
/actuator/configprops를 통해 체크하기
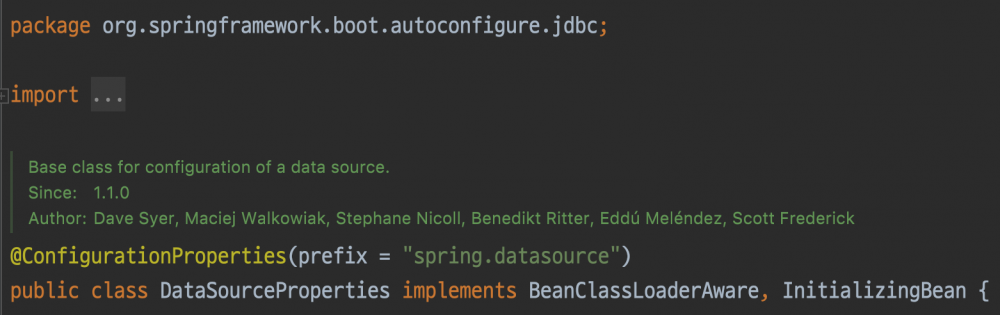
/actuator/configprops 엔드포인트에는 @ConfigurationProperties가 적용된 모든 빈(bean) 정보가 담겨있습니다. Spring Boot에선 spring-boot-autoconfigure 모듈을 통해 AutoConfiguration을 지원하는데요, 각 라이브러리의 설정들이 이 모듈을 통해 Spring Boot에 적용됩니다.
이때 Spring Boot에선 @ConfigurationProperties를 사용해 properties 또는 yaml 파일에 작성된 설정을 적용합니다. 예를 들어 DataSourceProperties 클래스는 다음과 같습니다.
즉, configprops에 담겨있는 내용은 입력값인 env와 달리 최종적으로 애플리케이션에 적용된 값이기 때문에 env에서 문제가 되었던 설정 방식에 관계없이 체크가 가능해졌습니다.
env에서 다르게 표시되었던 두 경로는 configprops에서 prefix 항목만 다를 뿐, 다음과 같이 동일하게 dataSource 하위 항목으로 노출됩니다.
dataSource: {
prefix: "begaonnuri.custom",
properties: {
// properties 생략
}
}dataSource: {
prefix: "spring.datasource.hikari",
properties: {
// properties 생략
}
}Rule 지정하기
가져온 설정값을 체크하려면 기준(이하 Rule)이 있어야 합니다. Config Checker는 최소품질체크리스트에서 시작한 만큼 대부분 최소품질체크리스트의 항목을 Rule로 지정했습니다.
하지만 최소품질체크리스트는 말 그대로 최소일 뿐, 서비스마다 설정값에 대한 체크 기준값은 다를 수밖에 없었습니다. 따라서 기본적으로는 최소품질체크리스트를 기준으로 체크하고 서비스별로 Rule값과 체크 조건을 변경할 수 있도록 해야 했습니다.
먼저 전사 플랫폼의 Key-Value 저장소에 JSON 형태로 Rule을 저장해두고 런타임(runtime)에 저장소에서 Rule을 가져와서 체크 조건에 따라 체크했습니다. 런타임에 가져오기 때문에 Rule이 추가되더라도 서비스 배포 없이 JSON 항목만 추가해 주면 적용이 가능했습니다.
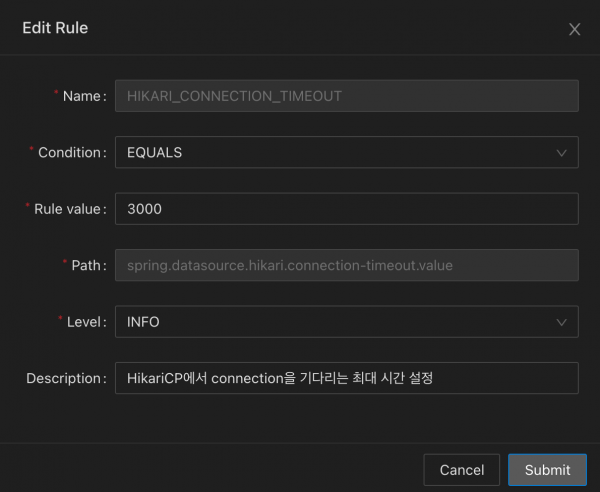
가져온 Rule의 형태는 다음과 같습니다.
[
{
"name": "HIKARI_CONNECTION_TIMEOUT",
"ruleValue": 3000,
"condition": "EQUALS",
"path": "spring.datasource.hikari.connection-timeout.value",
"level": "INFO",
"description": "HikariCP에서 connection을 기다리는 최대 시간 설정",
// 이하 항목 생략
}
// 추가적인 Rule
]condition 필드에 명시한 조건으로 설정값을 ruleValue 필드와 비교해 체크를 진행했습니다. 이때 condition은 다양한 설정값의 Rule을 지정하는데 제약이 없도록 Enum 클래스를 활용했습니다. Predicate 형식의 람다 함수를 사용했고, 이후 추가적인 조건이 필요한 경우에도 boolean 타입을 반환하는 람다 함수 작성을 통해 제공할 수 있도록 했습니다.
enum class CheckCondition(val check: (value: String, rule: String) -> Boolean) {
VALUE_CONTAIN_RULE({ value, rule -> value.contains(rule) }),
VALUE_CONTAIN_NOT_RULE({ value, rule -> !value.contains(rule) }),
RULE_CONTAIN_VALUE({ value, rule -> rule.contains(value) }),
RULE_CONTAIN_NOT_VALUE({ value, rule -> !rule.contains(value) }),
EMPTY({ value, _ -> value.isEmpty() }),
EMPTY_NOT({ value, _ -> value.isNotEmpty() }),
REGEX_MATCH({ value, rule -> rule.toRegex().matches(value) }),
STARTS_WITH({ value, rule -> value.startsWith(rule) }),
ENDS_WITH({ value, rule -> value.endsWith(rule) }),
EQUALS({ value, rule -> value == rule }),
EQUALS_NOT({ value, rule -> value != rule }),
LESS({ value, rule -> value.toLong() < rule.toLong() }),
LESS_OR_EQUAL({ value, rule -> value.toLong() <= rule.toLong() }),
MORE({ value, rule -> value.toLong() > rule.toLong() }),
MORE_OR_EQUAL({ value, rule -> value.toLong() >= rule.toLong() }),
ALWAYS_PASS({ _, _ -> true }),
ALWAYS_FAIL({ _, _ -> false }),
}그 결과 전사 플랫폼 포탈에서 다음과 같이 서비스별로 Rule값을 지정할 수 있게 되었습니다.
체크가 완료되면 다음과 같이 슬랙 알람을 통해 결과를 리포팅했고 각 팀에선 배포 직후 알람을 통해 결과를 확인할 수 있었습니다.
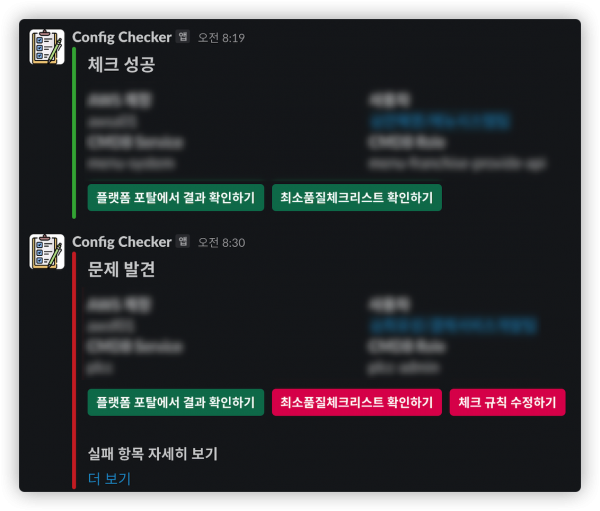
Config Checker의 가치
이후 설정값으로 인한 장애가 발생하면 장애 원인이 Rule로 추가되고 자연스레 Config Checker가 적용된 서비스들은 동일한 이슈로 인한 장애 재발이 방지됩니다. 이러한 선순환으로 점차 Rule을 보강해나가는 것이 앞으로의 과제입니다.
서두에 Spring 애플리케이션 설정값으로 인한 다운타임이 작년 기준으로 4시간 32분이라고 말씀드렸었는데, Config Checker 배포 이후 아직 설정값으로 인한 장애가 발생하고 있지 않습니다. 물론 각 팀에서 잘해주신 덕분이지만 Config Checker를 통해서 설정값이 더블체크 된 영향도 있다고 생각합니다.
마치며
앞으로 AWS의 각 서비스 설정값 체크, k8s 기반의 배포 플랫폼에 적용 등 다양한 도전과제가 기다리고 있습니다. 또한 SRE팀에선 Config Checker뿐만 아니라 CMDB 등 신뢰성을 높이는 플랫폼을 개발하고 있으니 SRE 개발자 모집 공고에 많은 관심 부탁드립니다.